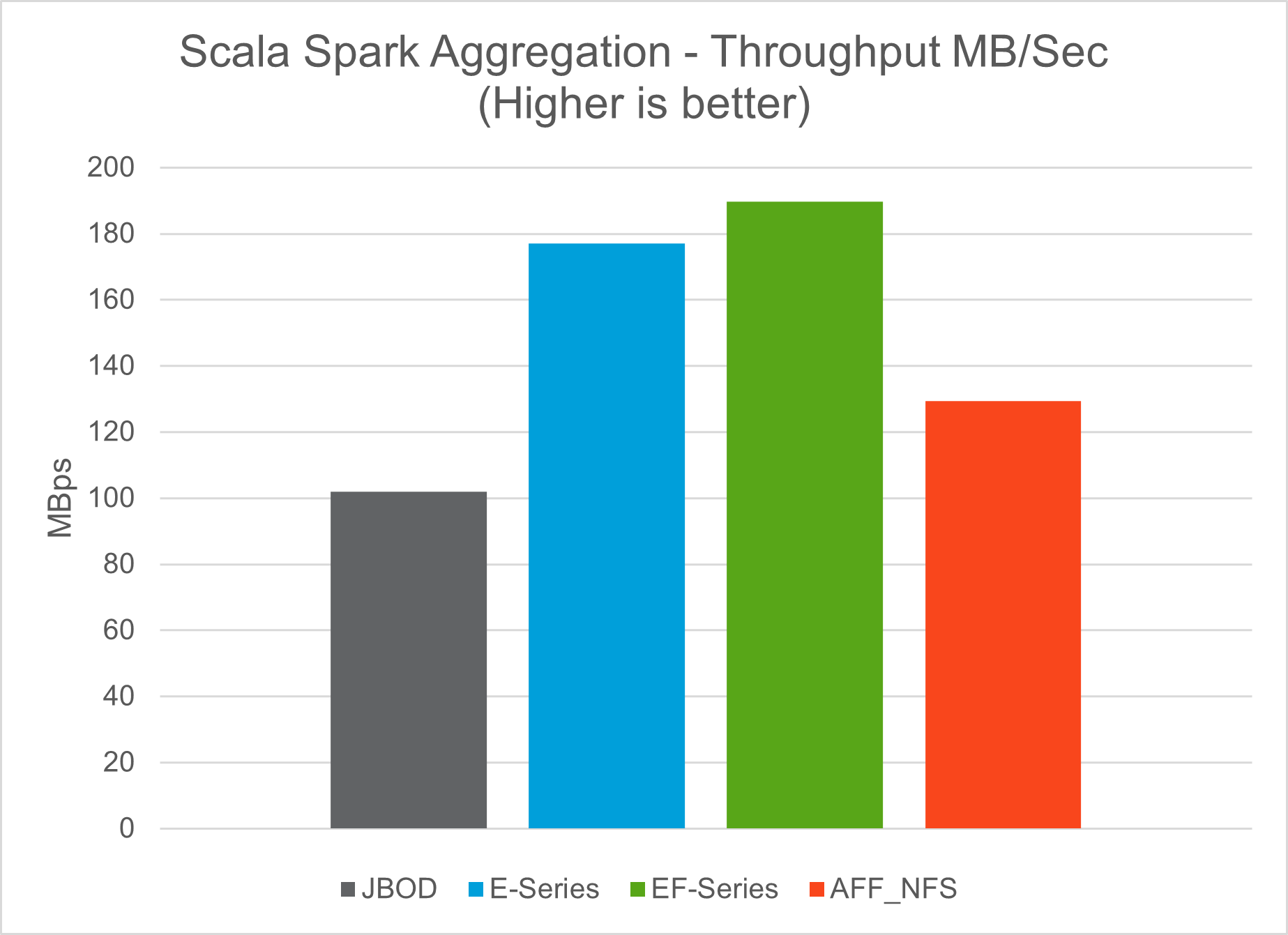
Testergebnisse
 Änderungen vorschlagen
Änderungen vorschlagen
Wir haben die Skripte TeraSort und TeraValidate im Benchmarking-Tool TeraGen verwendet, um die Spark-Leistungsvalidierung mit den Konfigurationen E5760, E5724 und AFF-A800 zu messen. Darüber hinaus wurden drei wichtige Anwendungsfälle getestet: Spark NLP-Pipelines und verteiltes TensorFlow-Training, verteiltes Horovod-Training und Multi-Worker-Deep-Learning mit Keras zur CTR-Vorhersage mit DeepFM.
Für die Validierung sowohl der E-Serie als auch der StorageGRID haben wir den Hadoop-Replikationsfaktor 2 verwendet. Für die AFF Validierung haben wir nur eine Datenquelle verwendet.
In der folgenden Tabelle ist die Hardwarekonfiguration für die Spark-Leistungsvalidierung aufgeführt.
| Typ | Hadoop-Workerknoten | Antriebstyp | Laufwerke pro Knoten | Speichercontroller |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
Einzelnes Hochverfügbarkeitspaar (HA) |
E5760 |
4 |
SAS |
60 |
Einzelnes HA-Paar |
E5724 |
4 |
SAS |
24 |
Einzelnes HA-Paar |
AFF800 |
4 |
SSD |
6 |
Einzelnes HA-Paar |
In der folgenden Tabelle sind die Softwareanforderungen aufgeführt.
| Software | Version |
|---|---|
RHEL |
7,9 |
OpenJDK-Laufzeitumgebung |
1.8.0 |
OpenJDK 64-Bit-Server-VM |
25,302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
Funke |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
TensorFlow |
2.9.0 |
Keras |
2.9.0 |
Horovod |
0.24.3 |
Finanzstimmungsanalyse
Wir veröffentlichten"TR-4910: Stimmungsanalyse aus der Kundenkommunikation mit NetApp AI" , in dem eine End-to-End-Konversations-KI-Pipeline mithilfe der "NetApp DataOps Toolkit" , AFF -Speicher und NVIDIA DGX-System. Die Pipeline führt Batch-Audiosignalverarbeitung, automatische Spracherkennung (ASR), Transferlernen und Stimmungsanalyse durch und nutzt dabei das DataOps Toolkit. "NVIDIA Riva SDK" und die "Tao-Rahmen" . Wir haben den Anwendungsfall der Stimmungsanalyse auf die Finanzdienstleistungsbranche ausgeweitet, einen SparkNLP-Workflow erstellt, drei BERT-Modelle für verschiedene NLP-Aufgaben wie die Erkennung benannter Entitäten geladen und die Stimmung auf Satzebene für die vierteljährlichen Gewinnaufrufe der Top 10-Unternehmen des NASDAQ ermittelt.
Das folgende Skript sentiment_analysis_spark. py verwendet das FinBERT-Modell, um Transkripte in HDFS zu verarbeiten und positive, neutrale und negative Stimmungszahlen zu erzeugen, wie in der folgenden Tabelle gezeigt:
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
In der folgenden Tabelle ist die Stimmungsanalyse auf Satzebene zu den Gewinnaufrufen der Top 10-Unternehmen des NASDAQ von 2016 bis 2020 aufgeführt.
| Stimmungszählung und Prozentsatz | Alle 10 Unternehmen | AAPL | AMD | AMZN | CSCO | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Positive Zählungen |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
Neutrale Zählungen |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
Negative Zählungen |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
Nicht kategorisierte Zählungen |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(Gesamtzahl) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
Prozentual gesehen sind die meisten Sätze der CEOs und CFOs sachlich und daher neutral. Während einer Telefonkonferenz zu den Quartalsergebnissen stellen Analysten Fragen, die eine positive oder negative Stimmung zum Ausdruck bringen können. Es lohnt sich, quantitativ weiter zu untersuchen, wie sich eine negative oder positive Stimmung auf die Aktienkurse am selben oder am nächsten Handelstag auswirkt.
In der folgenden Tabelle ist die Stimmungsanalyse auf Satzebene für die Top 10-Unternehmen des NASDAQ in Prozent aufgeführt.
| Stimmungsprozentsatz | Alle 10 Unternehmen | AAPL | AMD | AMZN | CSCO | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Positiv |
10,13 % |
18,06 % |
8,69 % |
5,24 % |
9,07 % |
12,08 % |
11,44 % |
13,25 % |
6,23 % |
Neutral |
87,17 % |
79,02 % |
88,82 % |
91,87 % |
88,42 % |
86,50 % |
84,65 % |
83,77 % |
92,44 % |
Negativ |
2,43 % |
2,92 % |
2,49 % |
1,52 % |
2,51 % |
1,42 % |
3,91 % |
2,96 % |
1,33 % |
Unkategorisiert |
0,27 % |
0 % |
0 % |
1,37 % |
0 % |
0 % |
0 % |
0,01 % |
0 % |
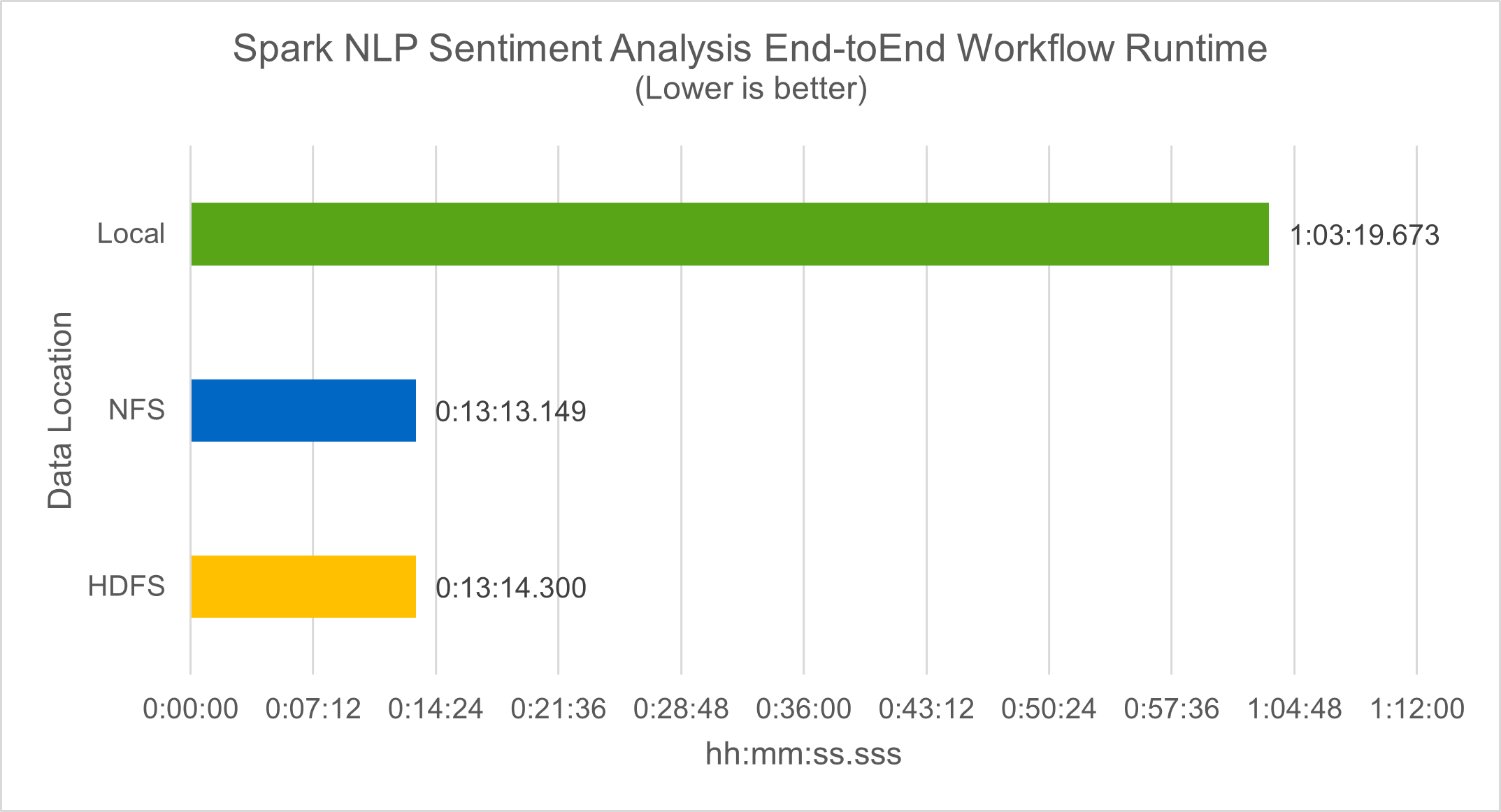
In Bezug auf die Workflow-Laufzeit konnten wir eine signifikante Verbesserung um das 4,78-fache gegenüber local Modus zu einer verteilten Umgebung in HDFS und eine weitere Verbesserung von 0,14 % durch Nutzung von NFS.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
Wie die folgende Abbildung zeigt, verbesserte die Daten- und Modellparallelität die Geschwindigkeit der Datenverarbeitung und der verteilten TensorFlow-Modellinferenz. Die Datenspeicherung in NFS führte zu einer etwas besseren Laufzeit, da der Engpass im Workflow das Herunterladen vortrainierter Modelle ist. Wenn wir die Größe des Transkriptdatensatzes erhöhen, wird der Vorteil von NFS deutlicher.
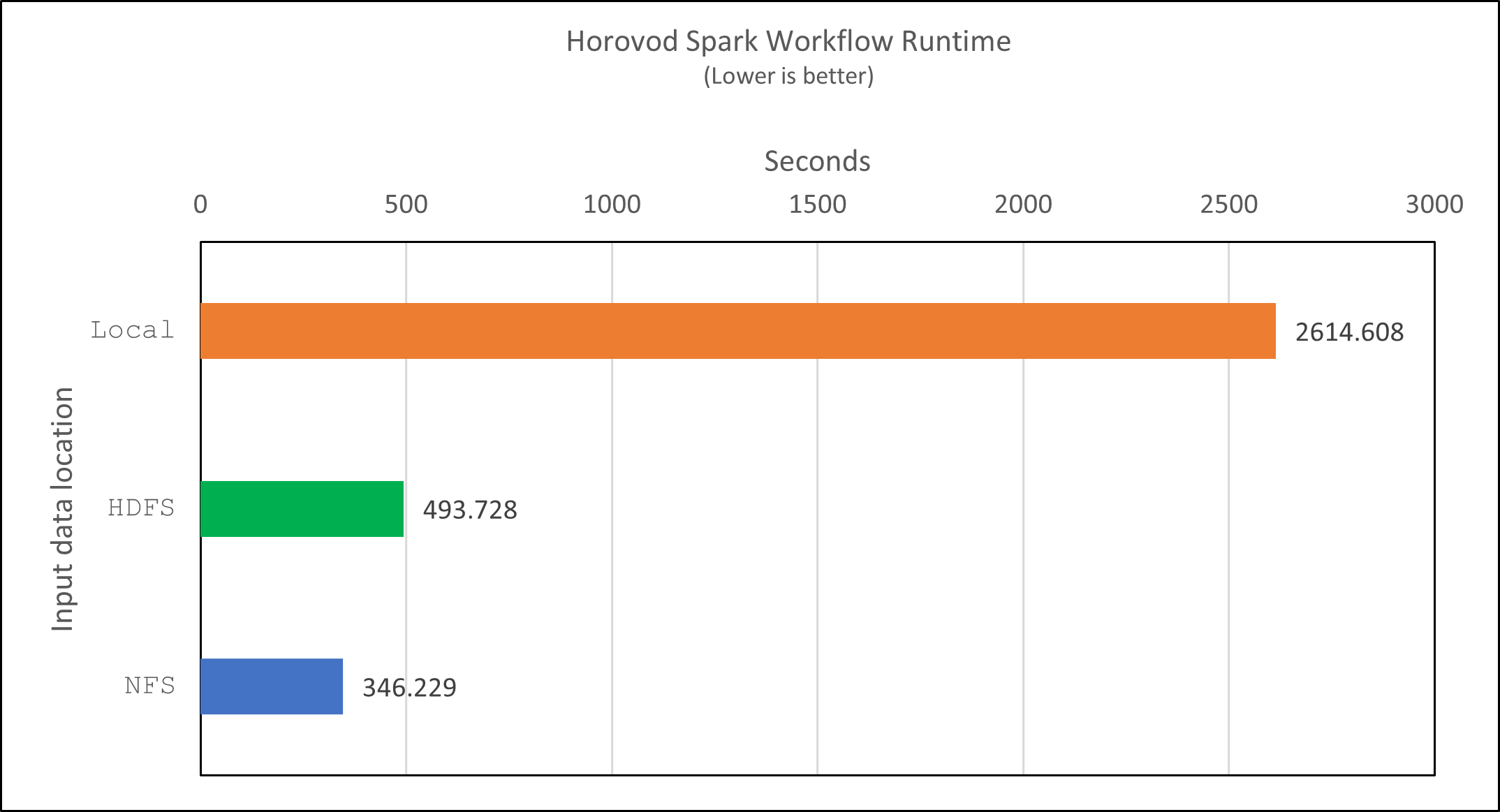
Verteiltes Training mit Horovod-Leistung
Der folgende Befehl erzeugte Laufzeitinformationen und eine Protokolldatei in unserem Spark-Cluster unter Verwendung eines einzigen master Knoten mit 160 Executoren mit jeweils einem Kern. Der Executor-Speicher wurde auf 5 GB begrenzt, um Speicherfehler zu vermeiden. Siehe den Abschnitt"Python-Skripte für jeden wichtigen Anwendungsfall" Weitere Einzelheiten zur Datenverarbeitung, zum Modelltraining und zur Berechnung der Modellgenauigkeit in keras_spark_horovod_rossmann_estimator.py .
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
Die resultierende Laufzeit mit zehn Trainingsepochen war wie folgt:
real43m34.608s user12m22.057s sys2m30.127s
Es dauerte mehr als 43 Minuten, um Eingabedaten zu verarbeiten, ein DNN-Modell zu trainieren, die Genauigkeit zu berechnen und TensorFlow-Checkpoints und eine CSV-Datei für Vorhersageergebnisse zu erstellen. Wir haben die Anzahl der Trainingsepochen auf 10 begrenzt, in der Praxis wird sie jedoch oft auf 100 gesetzt, um eine zufriedenstellende Modellgenauigkeit zu gewährleisten. Die Trainingszeit skaliert normalerweise linear mit der Anzahl der Epochen.
Als nächstes nutzten wir die vier im Cluster verfügbaren Worker-Knoten und führten das gleiche Skript in yarn Modus mit Daten in HDFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
Die resultierende Laufzeit wurde wie folgt verbessert:
real8m13.728s user7m48.421s sys1m26.063s
Mit Horovods Modell- und Datenparallelität in Spark konnten wir eine 5,29-fache Laufzeitbeschleunigung von yarn gegen local Modus mit zehn Trainingsepochen. Dies wird in der folgenden Abbildung mit den Legenden dargestellt HDFS Und Local . Das Training des zugrunde liegenden TensorFlow-DNN-Modells kann mit GPUs, sofern verfügbar, weiter beschleunigt werden. Wir planen, diese Tests durchzuführen und die Ergebnisse in einem zukünftigen technischen Bericht zu veröffentlichen.
Unser nächster Test verglich die Laufzeiten mit Eingabedaten in NFS und HDFS. Das NFS-Volume auf der AFF A800 wurde gemountet auf /sparkdemo/horovod über die fünf Knoten (ein Master, vier Worker) in unserem Spark-Cluster. Wir haben einen ähnlichen Befehl wie bei den vorherigen Tests ausgeführt, mit dem --data- dir Parameter, der jetzt auf die NFS-Einbindung zeigt:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
Die resultierende Laufzeit mit NFS war wie folgt:
real 5m46.229s user 5m35.693s sys 1m5.615s
Es kam zu einer weiteren Beschleunigung um das 1,43-Fache, wie in der folgenden Abbildung gezeigt. Daher profitieren Kunden mit einem an ihren Cluster angeschlossenen NetApp All-Flash-Speicher von den Vorteilen einer schnellen Datenübertragung und -verteilung für Horovod Spark-Workflows und erreichen eine 7,55-fache Beschleunigung im Vergleich zur Ausführung auf einem einzelnen Knoten.
Deep-Learning-Modelle für die CTR-Vorhersageleistung
Für Empfehlungssysteme, die auf die Maximierung der Klickrate ausgelegt sind, müssen Sie die komplexen Funktionsinteraktionen hinter dem Benutzerverhalten erlernen, die sich mathematisch von der niedrigsten bis zur höchsten Ordnung berechnen lassen. Für ein gutes Deep-Learning-Modell sollten sowohl Merkmalsinteraktionen niedriger als auch höherer Ordnung gleichermaßen wichtig sein, ohne dass das eine oder das andere bevorzugt wird. Deep Factorization Machine (DeepFM), ein auf Faktorisierungsmaschinen basierendes neuronales Netzwerk, kombiniert Faktorisierungsmaschinen für Empfehlungen und Deep Learning für das Merkmalslernen in einer neuen neuronalen Netzwerkarchitektur.
Obwohl herkömmliche Faktorisierungsmaschinen paarweise Merkmalsinteraktionen als inneres Produkt latenter Vektoren zwischen Merkmalen modellieren und theoretisch Informationen höherer Ordnung erfassen können, verwenden Anwender des maschinellen Lernens in der Praxis aufgrund der hohen Rechen- und Speicherkomplexität normalerweise nur Merkmalsinteraktionen zweiter Ordnung. Varianten tiefer neuronaler Netzwerke wie die von Google "Breite und tiefe Modelle" lernt andererseits anspruchsvolle Merkmalsinteraktionen in einer hybriden Netzwerkstruktur durch die Kombination eines linearen breiten Modells und eines tiefen Modells.
Es gibt zwei Eingaben für dieses Wide & Deep-Modell, eine für das zugrunde liegende Wide-Modell und die andere für das Deep-Modell. Letzterer Teil erfordert noch immer eine fachmännische Feature-Entwicklung und macht die Technik daher weniger auf andere Domänen übertragbar. Anders als das Wide & Deep-Modell kann DeepFM effizient mit Rohmerkmalen trainiert werden, ohne dass ein Feature-Engineering erforderlich ist, da der breite und der tiefe Teil denselben Input und Einbettungsvektor verwenden.
Wir haben zunächst die Criteo train.txt (11 GB) in eine CSV-Datei mit dem Namen ctr_train.csv in einem NFS-Mount gespeichert /sparkdemo/tr-4570-data mit run_classification_criteo_spark.py aus dem Abschnitt"Python-Skripte für jeden wichtigen Anwendungsfall." Innerhalb dieses Skripts wird die Funktion process_input_file führt mehrere String-Methoden aus, um Tabs zu entfernen und einzufügen ',' als Trennzeichen und '\n' als Zeilenumbruch. Beachten Sie, dass Sie nur das Original verarbeiten müssen train.txt einmal, sodass der Codeblock als Kommentar angezeigt wird.
Für die folgenden Tests verschiedener DL-Modelle verwendeten wir ctr_train.csv als Eingabedatei. In nachfolgenden Testläufen wurde die CSV-Eingabedatei in einen Spark DataFrame mit Schema eingelesen, das ein Feld von 'label' , ganzzahlige dichte Merkmale ['I1', 'I2', 'I3', …, 'I13'] und spärliche Merkmale ['C1', 'C2', 'C3', …, 'C26'] . Die folgende spark-submit Der Befehl nimmt eine CSV-Eingabe entgegen, trainiert DeepFM-Modelle mit 20 % Aufteilung für die Kreuzvalidierung und wählt nach zehn Trainingsepochen das beste Modell aus, um die Vorhersagegenauigkeit im Testsatz zu berechnen:
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
Beachten Sie, dass die Datendatei ctr_train.csv über 11 GB liegt, müssen Sie eine ausreichende spark.driver.maxResultSize größer als die Datensatzgröße, um Fehler zu vermeiden.
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
Im obigen SparkSession.builder Konfiguration haben wir auch aktiviert "Apache-Pfeil" , das einen Spark DataFrame in einen Pandas DataFrame mit dem df.toPandas() Verfahren.
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
Nach der zufälligen Aufteilung gibt es über 36 Millionen Zeilen im Trainingsdatensatz und 9 Millionen Stichproben im Testdatensatz:
Training dataset size = 36672493 Testing dataset size = 9168124
Da sich dieser technische Bericht auf CPU-Tests ohne Verwendung von GPUs konzentriert, ist es zwingend erforderlich, dass Sie TensorFlow mit entsprechenden Compiler-Flags erstellen. Dieser Schritt vermeidet den Aufruf von GPU-beschleunigten Bibliotheken und nutzt die Advanced Vector Extensions (AVX) und AVX2-Anweisungen von TensorFlow voll aus. Diese Funktionen sind für lineare algebraische Berechnungen wie vektorisierte Addition, Matrixmultiplikationen innerhalb eines Feedforward- oder Backpropagation-DNN-Trainings konzipiert. Der mit AVX2 verfügbare Fused Multiply Add (FMA)-Befehl mit 256-Bit-Gleitkommaregistern (FP) ist ideal für ganzzahligen Code und Datentypen und führt zu einer bis zu zweifachen Beschleunigung. Bei FP-Code und Datentypen erreicht AVX2 eine um 8 % höhere Geschwindigkeit als AVX.
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Um TensorFlow aus dem Quellcode zu erstellen, empfiehlt NetApp die Verwendung "Bazel" . Für unsere Umgebung haben wir die folgenden Befehle in der Shell-Eingabeaufforderung ausgeführt, um zu installieren dnf , dnf-plugins und Bazel.
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
Sie müssen GCC 5 oder neuer aktivieren, um während des Build-Prozesses C++17-Funktionen zu verwenden, die von RHEL mit der Software Collections Library (SCL) bereitgestellt werden. Die folgenden Befehle installieren devtoolset und GCC 11.2.1 auf unserem RHEL 7.9-Cluster:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
Beachten Sie, dass die letzten beiden Befehle devtoolset-11 , das verwendet /opt/rh/devtoolset-11/root/usr/bin/gcc (GCC 11.2.1). Stellen Sie außerdem sicher, dass Ihre git Version ist höher als 1.8.3 (diese wird mit RHEL 7.9 geliefert). Siehe hierzu "Artikel" zur Aktualisierung git bis 2.24.1.
Wir gehen davon aus, dass Sie das neueste TensorFlow-Master-Repo bereits geklont haben. Erstellen Sie dann eine workspace Verzeichnis mit einem WORKSPACE Datei zum Erstellen von TensorFlow aus dem Quellcode mit AVX, AVX2 und FMA. Führen Sie den configure Datei und geben Sie den richtigen Python-Binärspeicherort an. "CUDA" ist für unsere Tests deaktiviert, da wir keine GPU verwendet haben. A .bazelrc Die Datei wird entsprechend Ihren Einstellungen generiert. Weiter haben wir die Datei bearbeitet und eingestellt build --define=no_hdfs_support=false um die HDFS-Unterstützung zu aktivieren. Siehe .bazelrc im Abschnitt"Python-Skripte für jeden wichtigen Anwendungsfall," für eine vollständige Liste der Einstellungen und Flags.
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
Nachdem Sie TensorFlow mit den richtigen Flags erstellt haben, führen Sie das folgende Skript aus, um den Criteo Display Ads-Datensatz zu verarbeiten, ein DeepFM-Modell zu trainieren und die Fläche unter der Receiver Operating Characteristic Curve (ROC AUC) aus den Vorhersagewerten zu berechnen.
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
Nach zehn Trainingsepochen haben wir den AUC-Score für den Testdatensatz erhalten:
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
Ähnlich wie bei früheren Anwendungsfällen haben wir die Spark-Workflow-Laufzeit mit Daten verglichen, die an verschiedenen Standorten gespeichert sind. Die folgende Abbildung zeigt einen Vergleich der Deep-Learning-CTR-Vorhersage für eine Spark-Workflow-Laufzeit.