TR-4912: Best Practice-Richtlinien für Confluent Kafka Tiered Storage mit NetApp
 Änderungen vorschlagen
Änderungen vorschlagen
Karthikeyan Nagalingam, Joseph Kandatilparambil, NetApp Rankesh Kumar, Confluent
Apache Kafka ist eine von der Community verteilte Event-Streaming-Plattform, die Billionen von Ereignissen pro Tag verarbeiten kann. Kafka wurde ursprünglich als Nachrichtenwarteschlange konzipiert und basiert auf der Abstraktion eines verteilten Commit-Protokolls. Seit seiner Erstellung und Open-Source-Veröffentlichung durch LinkedIn im Jahr 2011 hat sich Kafka von einer Nachrichtenwarteschlange zu einer vollwertigen Event-Streaming-Plattform entwickelt. Confluent liefert die Distribution von Apache Kafka mit der Confluent-Plattform. Die Confluent-Plattform ergänzt Kafka um zusätzliche Community- und kommerzielle Funktionen, die das Streaming-Erlebnis von Betreibern und Entwicklern in der Produktion in großem Maßstab verbessern sollen.
Dieses Dokument beschreibt die Best-Practice-Richtlinien für die Verwendung von Confluent Tiered Storage auf einem Object Storage-Angebot von NetApp und stellt die folgenden Inhalte bereit:
-
Konfluente Verifizierung mit NetApp Object Storage – NetApp StorageGRID
-
Leistungstests für mehrstufigen Speicher
-
Best-Practice-Richtlinien für Confluent auf NetApp -Speichersystemen
Warum Confluent Tiered Storage?
Confluent hat sich zur Standard-Echtzeit-Streaming-Plattform für viele Anwendungen entwickelt, insbesondere für Big Data-, Analyse- und Streaming-Workloads. Mit Tiered Storage können Benutzer in der Confluent-Plattform Rechenleistung und Speicher trennen. Es macht die Datenspeicherung kostengünstiger, ermöglicht Ihnen die Speicherung nahezu unbegrenzter Datenmengen und die Skalierung von Arbeitslasten nach Bedarf nach oben (oder unten) und vereinfacht Verwaltungsaufgaben wie die Neuverteilung von Daten und Mandanten. S3-kompatible Speichersysteme können alle diese Funktionen nutzen, um Daten mit allen Ereignissen an einem Ort zu demokratisieren, wodurch die Notwendigkeit einer komplexen Datentechnik entfällt. Weitere Informationen dazu, warum Sie Tiered Storage für Kafka verwenden sollten, finden Sie unter"dieser Artikel von Confluent" .
NetApp instaclustr unterstützt Kafka ab Version 3.8.1 auch mit Tiered Storage. Weitere Details finden Sie hier. "Instaclust nutzt Kafka-Tiered Storage"
Warum NetApp StorageGRID für Tiered Storage?
StorageGRID ist eine branchenführende Objektspeicherplattform von NetApp. StorageGRID ist eine softwaredefinierte, objektbasierte Speicherlösung, die branchenübliche Objekt-APIs unterstützt, einschließlich der Amazon Simple Storage Service (S3)-API. StorageGRID speichert und verwaltet unstrukturierte Daten in großem Umfang, um einen sicheren, dauerhaften Objektspeicher bereitzustellen. Inhalte werden zur richtigen Zeit am richtigen Ort und auf der richtigen Speicherebene platziert, wodurch Arbeitsabläufe optimiert und die Kosten für global verteilte Rich Media gesenkt werden.
Das größte Unterscheidungsmerkmal von StorageGRID ist die Policy-Engine für Information Lifecycle Management (ILM), die ein richtliniengesteuertes Datenlebenszyklusmanagement ermöglicht. Die Richtlinien-Engine kann Metadaten verwenden, um zu verwalten, wie Daten während ihrer gesamten Lebensdauer gespeichert werden, um zunächst die Leistung zu optimieren und mit zunehmendem Alter der Daten automatisch die Kosten und Haltbarkeit zu optimieren.
Aktivieren von Confluent Tiered Storage
Die Grundidee des Tiered Storage besteht darin, die Aufgaben der Datenspeicherung von denen der Datenverarbeitung zu trennen. Durch diese Trennung wird es für die Datenspeicherungsebene und die Datenverarbeitungsebene wesentlich einfacher, unabhängig voneinander zu skalieren.
Eine mehrstufige Speicherlösung für Confluent muss zwei Faktoren berücksichtigen. Erstens müssen allgemeine Konsistenz- und Verfügbarkeitseigenschaften von Objektspeichern, wie etwa Inkonsistenzen bei LIST-Operationen und gelegentliche Nichtverfügbarkeit von Objekten, umgangen oder vermieden werden. Zweitens muss die Interaktion zwischen mehrstufigem Speicher und dem Replikations- und Fehlertoleranzmodell von Kafka korrekt gehandhabt werden, einschließlich der Möglichkeit, dass Zombie-Leader weiterhin Offset-Bereiche stufen. NetApp Object Storage bietet sowohl die konsistente Objektverfügbarkeit als auch das HA-Modell und stellt den erschöpften Speicher für Tier-Offset-Bereiche zur Verfügung. NetApp Objektspeicher bietet konsistente Objektverfügbarkeit und ein HA-Modell, um den erschöpften Speicher für Tier-Offset-Bereiche verfügbar zu machen.
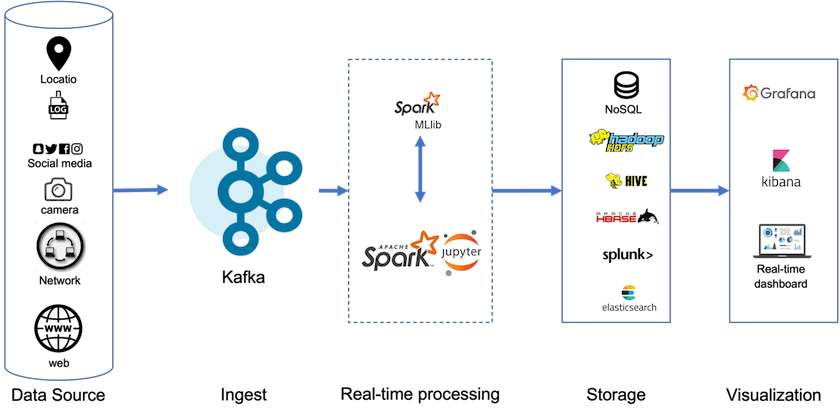
Mit Tiered Storage können Sie Hochleistungsplattformen für Lese- und Schreibvorgänge mit geringer Latenz am Ende Ihrer Streaming-Daten verwenden. Außerdem können Sie günstigere, skalierbare Objektspeicher wie NetApp StorageGRID für historische Lesevorgänge mit hohem Durchsatz nutzen. Wir haben auch eine technische Lösung für Spark mit NetApp-Speichercontroller. Einzelheiten finden Sie hier. Die folgende Abbildung zeigt, wie Kafka in eine Echtzeit-Analyse-Pipeline passt.
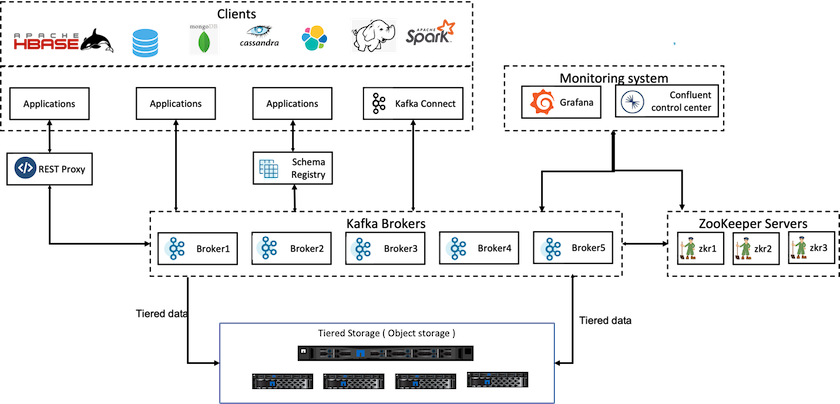
Die folgende Abbildung zeigt, wie NetApp StorageGRID als Objektspeicherebene von Confluent Kafka passt.