

Best Practice-Richtlinien
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt werden die Erkenntnisse aus dieser Zertifizierung vorgestellt.
-
Basierend auf unserer Validierung ist der S3-Objektspeicher für Confluent am besten geeignet, um Daten aufzubewahren.
-
Wir können ein Hochdurchsatz-SAN (insbesondere FC) verwenden, um die Hot Data des Brokers oder die lokale Festplatte aufzubewahren, da in der mehrstufigen Speicherkonfiguration von Confluent die Größe der im Datenverzeichnis des Brokers gespeicherten Daten auf der Segmentgröße und der Aufbewahrungszeit basiert, wenn die Daten in den Objektspeicher verschoben werden.
-
Objektspeicher bieten eine bessere Leistung, wenn segment.bytes höher ist; wir haben 512 MB getestet.
-
In Kafka wird die Länge des Schlüssels oder Wertes (in Bytes) für jeden zum Thema erstellten Datensatz durch die
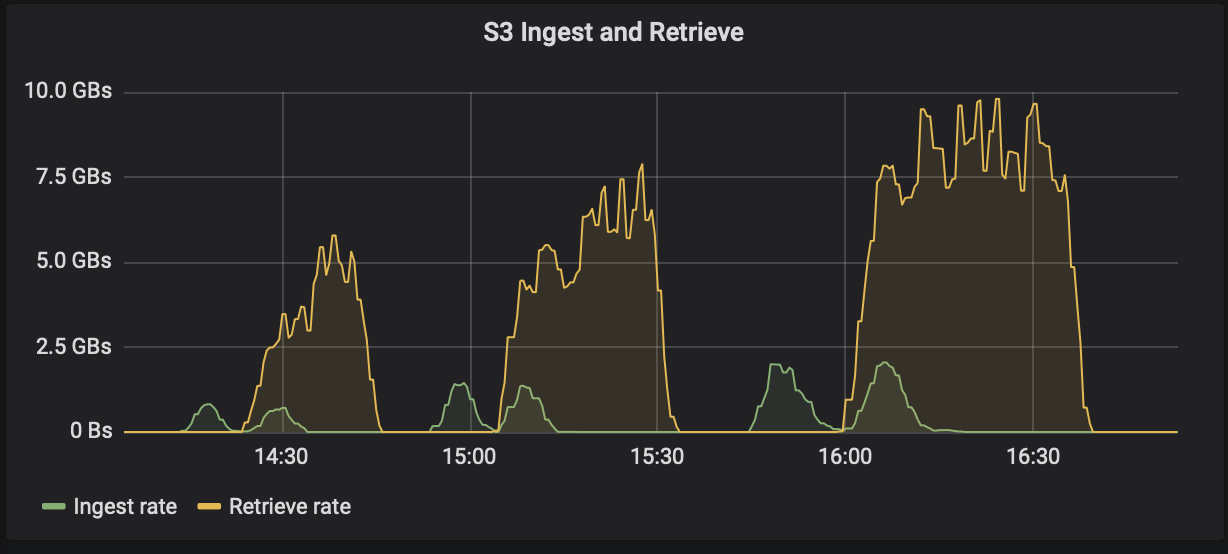
length.key.valueParameter. Für StorageGRID wurde die Leistung beim Aufnehmen und Abrufen von S3-Objekten auf höhere Werte erhöht. Beispielsweise ermöglichten 512 Bytes einen Abruf von 5,8 GBps, 1024 Bytes einen S3-Abruf von 7,5 GBps und 2048 Bytes fast 10 GBps.
Die folgende Abbildung zeigt die Aufnahme und den Abruf von S3-Objekten basierend auf length.key.value .
-
Kafka-Tuning. Um die Leistung des mehrstufigen Speichers zu verbessern, können Sie TierFetcherNumThreads und TierArchiverNumThreads erhöhen. Als allgemeine Richtlinie sollten Sie TierFetcherNumThreads erhöhen, um es an die Anzahl der physischen CPU-Kerne anzupassen, und TierArchiverNumThreads auf die Hälfte der Anzahl der CPU-Kerne erhöhen. Wenn Sie beispielsweise über eine Maschine mit acht physischen Kernen verfügen, legen Sie in den Servereigenschaften confluent.tier.fetcher.num.threads = 8 und confluent.tier.archiver.num.threads = 4 fest.
-
Zeitintervall für Themenlöschungen. Wenn ein Thema gelöscht wird, beginnt das Löschen der Protokollsegmentdateien im Objektspeicher nicht sofort. Vielmehr gibt es ein Zeitintervall mit einem Standardwert von 3 Stunden, bevor die Löschung dieser Dateien erfolgt. Sie können die Konfiguration confluent.tier.topic.delete.check.interval.ms ändern, um den Wert dieses Intervalls zu ändern. Wenn Sie ein Thema oder einen Cluster löschen, können Sie die Objekte im jeweiligen Bucket auch manuell löschen.
-
ACLs zu internen Themen des Tiered Storage. Eine empfohlene Best Practice für lokale Bereitstellungen besteht darin, einen ACL-Autorisierer für die internen Themen zu aktivieren, die für mehrstufigen Speicher verwendet werden. Legen Sie ACL-Regeln fest, um den Zugriff auf diese Daten auf den Broker-Benutzer zu beschränken. Dies sichert die internen Themen und verhindert den unbefugten Zugriff auf Tiered-Storage-Daten und Metadaten.
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \ --add --allow-principal User:<kafka> --operation All --topic "_confluent-tier-state"

|
Ersetzen Sie den Benutzer <kafka> mit dem tatsächlichen Broker-Prinzipal in Ihrer Bereitstellung.
|
Beispielsweise der Befehl confluent-tier-state legt ACLs für das interne Thema für mehrstufigen Speicher fest. Derzeit gibt es nur ein einziges internes Thema zum Thema Tiered Storage. Das Beispiel erstellt eine ACL, die dem Kafka-Prinzip die Berechtigung für alle Vorgänge am internen Thema erteilt.