

Leistungsübersicht und Validierung mit AFF A900 vor Ort
 Änderungen vorschlagen
Änderungen vorschlagen
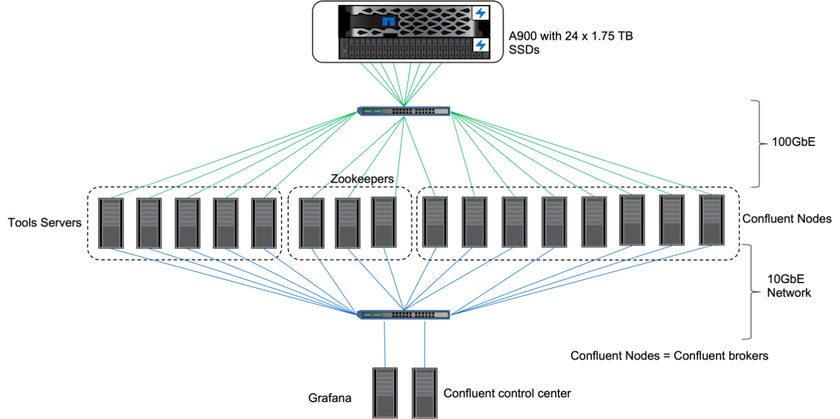
Vor Ort haben wir den NetApp AFF A900 Speichercontroller mit ONTAP 9.12.1RC1 verwendet, um die Leistung und Skalierung eines Kafka-Clusters zu validieren. Wir haben dasselbe Testbed wie bei unseren vorherigen Best Practices für Tiered Storage mit ONTAP und AFF verwendet.
Zur Evaluierung des AFF A900 haben wir Confluent Kafka 6.2.0 verwendet. Der Cluster verfügt über acht Broker-Knoten und drei Zookeeper-Knoten. Für Leistungstests haben wir fünf OMB-Workerknoten verwendet.
Storage-Konfiguration
Wir haben NetApp FlexGroups-Instanzen verwendet, um einen einzigen Namespace für Protokollverzeichnisse bereitzustellen und so die Wiederherstellung und Konfiguration zu vereinfachen. Wir haben NFSv4.1 und pNFS verwendet, um einen direkten Pfadzugriff auf die Daten des Protokollsegments zu ermöglichen.
Client-Tuning
Jeder Client hat die FlexGroup -Instanz mit dem folgenden Befehl gemountet.
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
Darüber hinaus erhöhten wir die max_session_slots` von der Standardeinstellung 64 Zu 180 . Dies entspricht dem Standardlimit für Sitzungsslots in ONTAP.
Kafka-Broker-Tuning
Um den Durchsatz im Testsystem zu maximieren, haben wir die Standardparameter für bestimmte wichtige Thread-Pools deutlich erhöht. Wir empfehlen, für die meisten Konfigurationen die Best Practices von Confluent Kafka zu befolgen. Diese Optimierung wurde verwendet, um die Parallelität ausstehender E/A-Vorgänge zum Speicher zu maximieren. Diese Parameter können angepasst werden, um den Rechenressourcen und Speicherattributen Ihres Brokers zu entsprechen.
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
Testmethodik für Workload-Generatoren
Wir haben für den Durchsatztreiber und die Themenkonfiguration dieselben OMB-Konfigurationen wie für Cloud-Tests verwendet.
-
Eine FlexGroup -Instanz wurde mit Ansible auf einem AFF Cluster bereitgestellt.
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
pNFS wurde auf dem ONTAP SVM aktiviert.
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
Die Arbeitslast wurde mit dem Throughput-Treiber ausgelöst, wobei dieselbe Arbeitslastkonfiguration wie für Cloud Volumes ONTAP verwendet wurde. Siehe Abschnitt "Steady-State-Leistung " unten. Die Arbeitslast verwendete einen Replikationsfaktor von 3, was bedeutet, dass drei Kopien der Protokollsegmente in NFS verwaltet wurden.
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Abschließend haben wir Messungen mithilfe eines Rückstands durchgeführt, um die Fähigkeit der Verbraucher zu messen, die neuesten Nachrichten nachzuholen. OMB baut einen Rückstand auf, indem es Verbraucher zu Beginn einer Messung anhält. Dadurch entstehen drei verschiedene Phasen: die Erstellung eines Rückstands (Verkehr nur für Produzenten), der Abbau des Rückstands (eine Phase mit vielen Konsumenten, in der Konsumenten verpasste Ereignisse zu einem Thema nachholen) und der stationäre Zustand. Siehe Abschnitt "Extreme Leistung und Ausloten der Speichergrenzen " für weitere Informationen.
Steady-State-Leistung
Wir haben die AFF A900 mithilfe des OpenMessaging Benchmarks bewertet, um einen ähnlichen Vergleich wie für Cloud Volumes ONTAP in AWS und DAS in AWS zu ermöglichen. Alle Leistungswerte stellen den Durchsatz des Kafka-Clusters auf Produzenten- und Verbraucherebene dar.
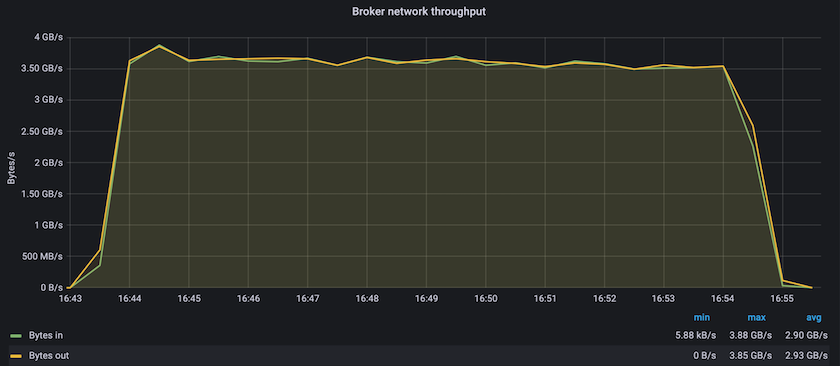
Die konstante Leistung mit Confluent Kafka und dem AFF A900 erreichte einen durchschnittlichen Durchsatz von über 3,4 GBps für Produzenten und Verbraucher. Das sind über 3,4 Millionen Nachrichten im gesamten Kafka-Cluster. Durch die Visualisierung des anhaltenden Durchsatzes in Bytes pro Sekunde für BrokerTopicMetrics sehen wir die hervorragende Dauerleistung und den Datenverkehr, die vom AFF A900 unterstützt werden.
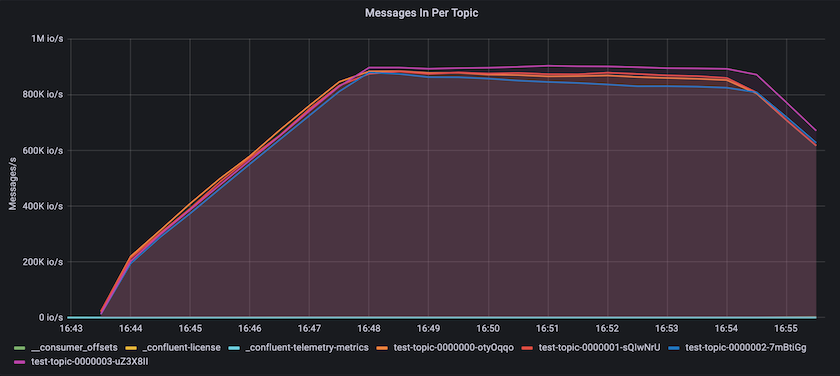
Dies passt gut zur Ansicht der pro Thema übermittelten Nachrichten. Das folgende Diagramm bietet eine Aufschlüsselung nach Themen. In der getesteten Konfiguration haben wir fast 900.000 Nachrichten pro Thema in vier Themenbereichen gesehen.
Extreme Leistung und Ausloten der Speichergrenzen
Für AFF haben wir auch mit OMB unter Verwendung der Backlog-Funktion getestet. Die Backlog-Funktion pausiert Verbraucherabonnements, während sich im Kafka-Cluster ein Rückstand an Ereignissen aufbaut. Während dieser Phase tritt nur Produzentenverkehr auf, der Ereignisse generiert, die in Protokollen festgehalten werden. Dies emuliert am ehesten die Stapelverarbeitung oder Offline-Analyse-Workflows. In diesen Workflows werden Verbraucherabonnements gestartet und müssen historische Daten lesen, die bereits aus dem Broker-Cache entfernt wurden.
Um die Speicherbeschränkungen für den Verbraucherdurchsatz in dieser Konfiguration zu verstehen, haben wir die reine Produzentenphase gemessen, um zu verstehen, wie viel Schreibverkehr der A900 aufnehmen kann. Siehe den nächsten Abschnitt "Größenberatung ", um zu verstehen, wie diese Daten genutzt werden können.
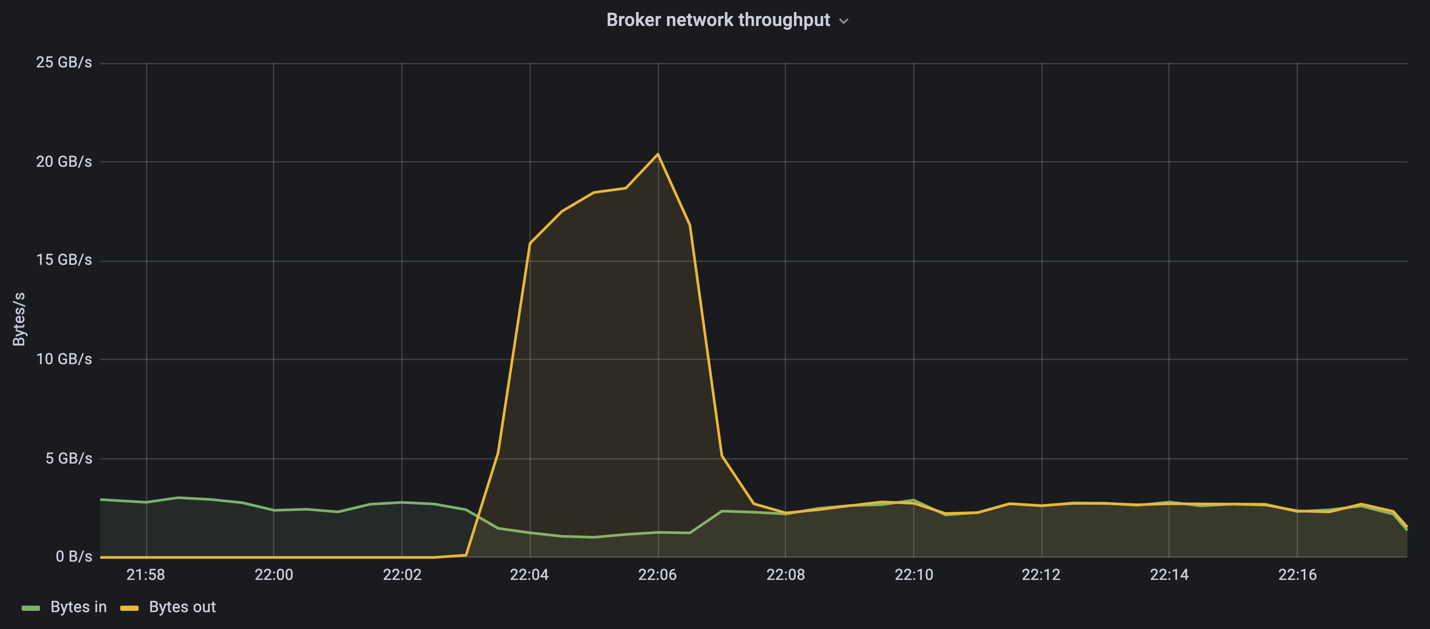
Während des Nur-Produzenten-Teils dieser Messung sahen wir einen hohen Spitzendurchsatz, der die Grenzen der A900-Leistung ausreizte (wenn andere Broker-Ressourcen nicht durch die Bedienung des Produzenten- und Verbraucherverkehrs ausgelastet waren).

|
Wir haben die Nachrichtengröße für diese Messung auf 16 KB erhöht, um den Overhead pro Nachricht zu begrenzen und den Speicherdurchsatz zu NFS-Mountpunkten zu maximieren. |
messageSize: 16384 consumerBacklogSizeGB: 4096
Der Confluent Kafka-Cluster erreichte einen Spitzenproduzentendurchsatz von 4,03 GBps.
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
Nachdem OMB das Auffüllen des Eventbacklogs abgeschlossen hatte, wurde der Verbraucherverkehr neu gestartet. Bei Messungen mit Backlog-Drainage konnten wir einen Spitzendurchsatz der Verbraucher von über 20 GBits/s bei allen Themen feststellen. Der kombinierte Durchsatz zum NFS-Volume, auf dem die OMB-Protokolldaten gespeichert sind, lag bei etwa 30 GBits/s.
Größenberatung
Amazon Web Services bietet eine "Größentabelle" zur Größenbestimmung und Skalierung von Kafka-Clustern.
Diese Größenbestimmung bietet eine nützliche Formel zur Bestimmung des Speicherdurchsatzbedarfs für Ihren Kafka-Cluster:
Bei einem aggregierten Durchsatz, der mit einem Replikationsfaktor von r in den Cluster von tcluster erzeugt wird, beträgt der vom Broker-Speicher empfangene Durchsatz:
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
Dies lässt sich noch weiter vereinfachen:
max(t[cluster]) <= max(t[storage]) * #brokers/r
Mithilfe dieser Formel können Sie die geeignete ONTAP Plattform für Ihre Kafka-Hot-Tier-Anforderungen auswählen.
Die folgende Tabelle erläutert den erwarteten Herstellerdurchsatz für den A900 mit unterschiedlichen Replikationsfaktoren:
| Replikationsfaktor | Produzentendurchsatz (GPps) |
|---|---|
3 (gemessen) |
3,4 |
2 |
5,1 |
1 |
10,2 |