Leistungsübersicht und -validierung in AWS
 Änderungen vorschlagen
Änderungen vorschlagen
Ein Kafka-Cluster mit der auf NetApp NFS montierten Speicherschicht wurde hinsichtlich seiner Leistung in der AWS-Cloud getestet. Die Benchmarking-Beispiele werden in den folgenden Abschnitten beschrieben.
Kafka in der AWS-Cloud mit NetApp Cloud Volumes ONTAP (Hochverfügbarkeitspaar und Einzelknoten)
Ein Kafka-Cluster mit NetApp Cloud Volumes ONTAP (HA-Paar) wurde hinsichtlich seiner Leistung in der AWS-Cloud getestet. Dieses Benchmarking wird in den folgenden Abschnitten beschrieben.
Architektonischer Aufbau
Die folgende Tabelle zeigt die Umgebungskonfiguration für einen Kafka-Cluster mit NAS.
| Plattformkomponente | Umgebungskonfiguration |
|---|---|
Kafka 3.2.3 |
|
Betriebssystem auf allen Knoten |
RHEL8.6 |
NetApp Cloud Volumes ONTAP Instanz |
HA-Paarinstanz – m5dn.12xLarge x 2 Knoten Einzelknoteninstanz – m5dn.12xLarge x 1 Knoten |
NetApp Cluster Volume ONTAP Setup
-
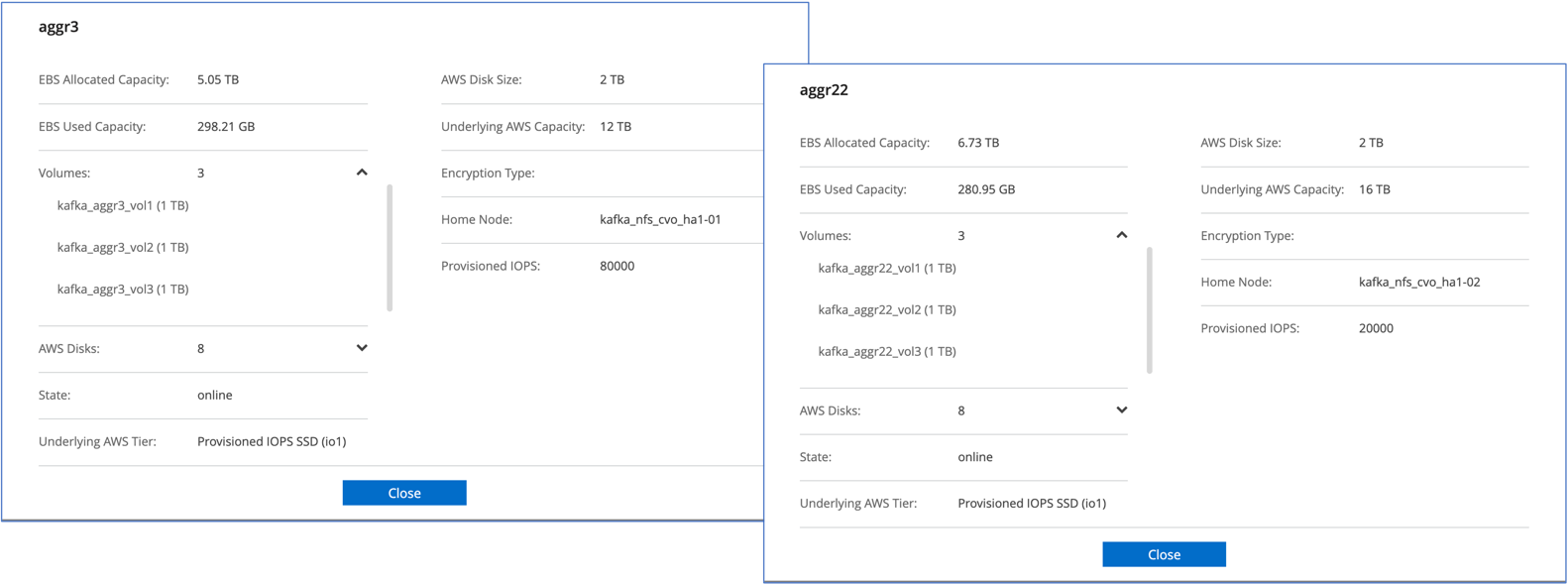
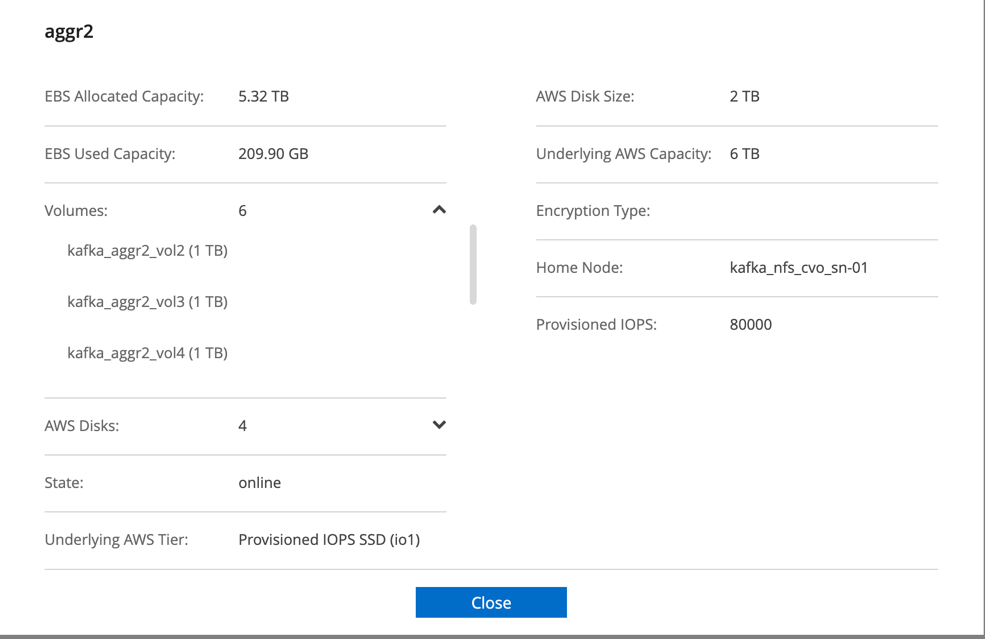
Für das Cloud Volumes ONTAP HA-Paar haben wir zwei Aggregate mit jeweils drei Volumes auf jedem Aggregat auf jedem Speichercontroller erstellt. Für den einzelnen Cloud Volumes ONTAP -Knoten erstellen wir sechs Volumes in einem Aggregat.
-
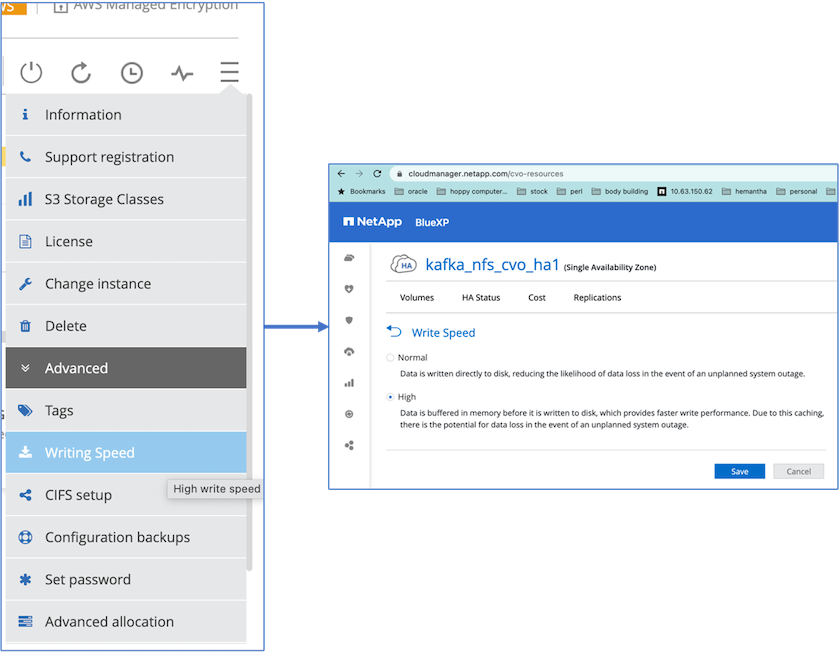
Um eine bessere Netzwerkleistung zu erzielen, haben wir Hochgeschwindigkeitsnetzwerke sowohl für das HA-Paar als auch für den einzelnen Knoten aktiviert.
-
Wir haben festgestellt, dass der ONTAP NVRAM mehr IOPS hatte, also haben wir die IOPS für das Cloud Volumes ONTAP Stammvolume auf 2350 geändert. Die Root-Volume-Festplatte in Cloud Volumes ONTAP hatte eine Größe von 47 GB. Der folgende ONTAP -Befehl gilt für das HA-Paar und der gleiche Schritt ist für den einzelnen Knoten anwendbar.
statistics start -object vnvram -instance vnvram -counter backing_store_iops -sample-id sample_555 kafka_nfs_cvo_ha1::*> statistics show -sample-id sample_555 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-01 Counter Value -------------------------------- -------------------------------- backing_store_iops 1479 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-02 Counter Value -------------------------------- -------------------------------- backing_store_iops 1210 2 entries were displayed. kafka_nfs_cvo_ha1::*>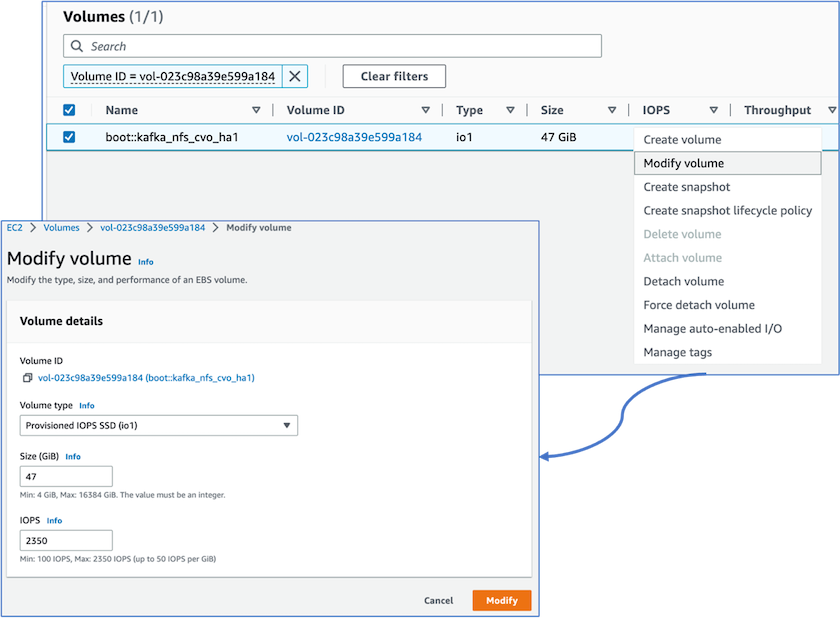
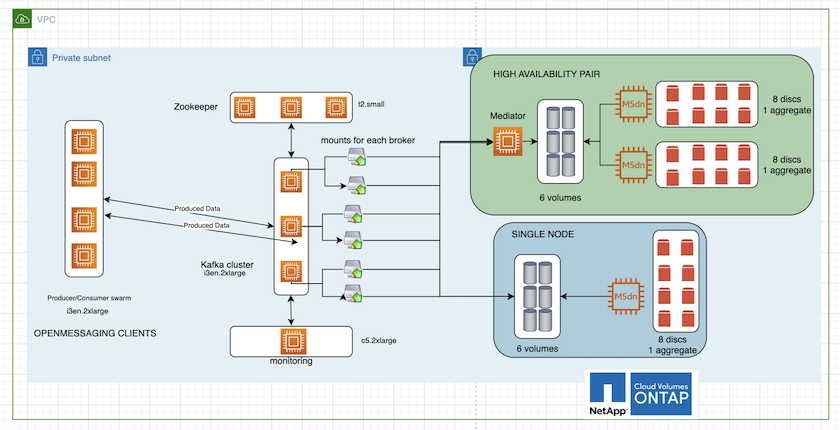
Die folgende Abbildung zeigt die Architektur eines NAS-basierten Kafka-Clusters.
-
Berechnen. Wir haben einen Kafka-Cluster mit drei Knoten und einem Zookeeper-Ensemble mit drei Knoten verwendet, das auf dedizierten Servern ausgeführt wird. Jeder Broker verfügte über zwei NFS-Mount-Punkte zu einem einzelnen Volume auf der Cloud Volumes ONTAP Instanz über ein dediziertes LIF.
-
Überwachung. Wir haben zwei Knoten für eine Prometheus-Grafana-Kombination verwendet. Zum Generieren von Workloads haben wir einen separaten Cluster mit drei Knoten verwendet, der für diesen Kafka-Cluster produzieren und konsumieren konnte.
-
Lagerung. Wir haben eine HA-Pair-Cloud-Volumes ONTAP Instanz mit einem auf der Instanz gemounteten 6-TB-GP3-AWS-EBS-Volume verwendet. Anschließend wurde das Volume mit einem NFS-Mount zum Kafka-Broker exportiert.
OpenMessage Benchmarking-Konfigurationen
-
Für eine bessere NFS-Leistung benötigen wir mehr Netzwerkverbindungen zwischen dem NFS-Server und dem NFS-Client, die mit nconnect erstellt werden können. Mounten Sie die NFS-Volumes auf den Broker-Knoten mit der Option „nconnect“, indem Sie den folgenden Befehl ausführen:
[root@ip-172-30-0-121 ~]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38/xfsdefaults00 /dev/nvme1n1 /mnt/data-1 xfs defaults,noatime,nodiscard 0 0 /dev/nvme2n1 /mnt/data-2 xfs defaults,noatime,nodiscard 0 0 172.30.0.233:/kafka_aggr3_vol1 /kafka_aggr3_vol1 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol2 /kafka_aggr3_vol2 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol3 /kafka_aggr3_vol3 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol1 /kafka_aggr22_vol1 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol2 /kafka_aggr22_vol2 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol3 /kafka_aggr22_vol3 nfs defaults,nconnect=16 0 0 [root@ip-172-30-0-121 ~]# mount -a [root@ip-172-30-0-121 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 31G 0 31G 0% /dev tmpfs 31G 249M 31G 1% /run tmpfs 31G 0 31G 0% /sys/fs/cgroup /dev/nvme0n1p2 10G 2.8G 7.2G 28% / /dev/nvme1n1 2.3T 248G 2.1T 11% /mnt/data-1 /dev/nvme2n1 2.3T 245G 2.1T 11% /mnt/data-2 172.30.0.233:/kafka_aggr3_vol1 1.0T 12G 1013G 2% /kafka_aggr3_vol1 172.30.0.233:/kafka_aggr3_vol2 1.0T 5.5G 1019G 1% /kafka_aggr3_vol2 172.30.0.233:/kafka_aggr3_vol3 1.0T 8.9G 1016G 1% /kafka_aggr3_vol3 172.30.0.242:/kafka_aggr22_vol1 1.0T 7.3G 1017G 1% /kafka_aggr22_vol1 172.30.0.242:/kafka_aggr22_vol2 1.0T 6.9G 1018G 1% /kafka_aggr22_vol2 172.30.0.242:/kafka_aggr22_vol3 1.0T 5.9G 1019G 1% /kafka_aggr22_vol3 tmpfs 6.2G 0 6.2G 0% /run/user/1000 [root@ip-172-30-0-121 ~]#
-
Überprüfen Sie die Netzwerkverbindungen in Cloud Volumes ONTAP. Der folgende ONTAP -Befehl wird vom einzelnen Cloud Volumes ONTAP Knoten verwendet. Derselbe Schritt gilt für das Cloud Volumes ONTAP HA-Paar.
Last login time: 1/20/2023 00:16:29 kafka_nfs_cvo_sn::> network connections active show -service nfs* -fields remote-host node cid vserver remote-host ------------------- ---------- -------------------- ------------ kafka_nfs_cvo_sn-01 2315762628 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762629 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762630 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762631 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762632 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762633 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762634 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762635 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762636 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762637 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762639 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762640 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762641 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762642 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762643 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762644 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762645 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762646 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762647 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762648 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762649 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762650 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762651 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762652 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762653 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762656 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762657 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762658 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762659 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762660 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762661 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762662 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762663 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762664 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762665 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762666 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762667 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762668 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762669 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762670 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762671 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762672 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762673 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762674 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762676 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762677 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762678 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762679 svm_kafka_nfs_cvo_sn 172.30.0.223 48 entries were displayed. kafka_nfs_cvo_sn::>
-
Wir verwenden folgende Kafka
server.propertiesin allen Kafka-Brokern für das Cloud Volumes ONTAP HA-Paar. Derlog.dirsDie Eigenschaft ist für jeden Broker unterschiedlich und die übrigen Eigenschaften sind für alle Broker gleich. Für Broker1 ist dielog.dirsDer Wert lautet wie folgt:[root@ip-172-30-0-121 ~]# cat /opt/kafka/config/server.properties broker.id=0 advertised.listeners=PLAINTEXT://172.30.0.121:9092 #log.dirs=/mnt/data-1/d1,/mnt/data-1/d2,/mnt/data-1/d3,/mnt/data-2/d1,/mnt/data-2/d2,/mnt/data-2/d3 log.dirs=/kafka_aggr3_vol1/broker1,/kafka_aggr3_vol2/broker1,/kafka_aggr3_vol3/broker1,/kafka_aggr22_vol1/broker1,/kafka_aggr22_vol2/broker1,/kafka_aggr22_vol3/broker1 zookeeper.connect=172.30.0.12:2181,172.30.0.30:2181,172.30.0.178:2181 num.network.threads=64 num.io.threads=64 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 replica.fetch.max.bytes=524288000 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 [root@ip-172-30-0-121 ~]#
-
Für Broker2 ist die
log.dirsDer Eigenschaftswert lautet wie folgt:log.dirs=/kafka_aggr3_vol1/broker2,/kafka_aggr3_vol2/broker2,/kafka_aggr3_vol3/broker2,/kafka_aggr22_vol1/broker2,/kafka_aggr22_vol2/broker2,/kafka_aggr22_vol3/broker2
-
Für Broker3 ist die
log.dirsDer Eigenschaftswert lautet wie folgt:log.dirs=/kafka_aggr3_vol1/broker3,/kafka_aggr3_vol2/broker3,/kafka_aggr3_vol3/broker3,/kafka_aggr22_vol1/broker3,/kafka_aggr22_vol2/broker3,/kafka_aggr22_vol3/broker3
-
-
Für den einzelnen Cloud Volumes ONTAP -Knoten: Der Kafka
servers.propertiesist das gleiche wie für das Cloud Volumes ONTAP HA-Paar, außer derlog.dirsEigentum.-
Für Broker1 ist die
log.dirsDer Wert lautet wie folgt:log.dirs=/kafka_aggr2_vol1/broker1,/kafka_aggr2_vol2/broker1,/kafka_aggr2_vol3/broker1,/kafka_aggr2_vol4/broker1,/kafka_aggr2_vol5/broker1,/kafka_aggr2_vol6/broker1
-
Für Broker2 ist die
log.dirsDer Wert lautet wie folgt:log.dirs=/kafka_aggr2_vol1/broker2,/kafka_aggr2_vol2/broker2,/kafka_aggr2_vol3/broker2,/kafka_aggr2_vol4/broker2,/kafka_aggr2_vol5/broker2,/kafka_aggr2_vol6/broker2
-
Für Broker3 ist die
log.dirsDer Eigenschaftswert lautet wie folgt:log.dirs=/kafka_aggr2_vol1/broker3,/kafka_aggr2_vol2/broker3,/kafka_aggr2_vol3/broker3,/kafka_aggr2_vol4/broker3,/kafka_aggr2_vol5/broker3,/kafka_aggr2_vol6/broker3
-
-
Die Arbeitslast im OMB ist mit den folgenden Eigenschaften konfiguriert:
(/opt/benchmark/workloads/1-topic-100-partitions-1kb.yaml).topics: 4 partitionsPerTopic: 100 messageSize: 32768 useRandomizedPayloads: true randomBytesRatio: 0.5 randomizedPayloadPoolSize: 100 subscriptionsPerTopic: 1 consumerPerSubscription: 80 producersPerTopic: 40 producerRate: 1000000 consumerBacklogSizeGB: 0 testDurationMinutes: 5
Der
messageSizekann je nach Anwendungsfall unterschiedlich sein. In unserem Leistungstest haben wir 3K verwendet.Wir haben zwei verschiedene Treiber, Sync oder Throughput, von OMB verwendet, um die Arbeitslast auf dem Kafka-Cluster zu generieren.
-
Die für die Sync-Treibereigenschaften verwendete YAML-Datei lautet wie folgt
(/opt/benchmark/driver- kafka/kafka-sync.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 flush.messages=1 flush.ms=0 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Die für die Durchsatztreibereigenschaften verwendete YAML-Datei lautet wie folgt
(/opt/benchmark/driver- kafka/kafka-throughput.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 default.api.timeout.ms=1200000 request.timeout.ms=1200000 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Testmethodik
-
Ein Kafka-Cluster wurde gemäß der oben beschriebenen Spezifikation mit Terraform und Ansible bereitgestellt. Terraform wird verwendet, um die Infrastruktur mithilfe von AWS-Instanzen für den Kafka-Cluster aufzubauen, und Ansible baut den Kafka-Cluster darauf auf.
-
Mit der oben beschriebenen Workload-Konfiguration und dem Sync-Treiber wurde eine OMB-Workload ausgelöst.
Sudo bin/benchmark –drivers driver-kafka/kafka- sync.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Mit dem Throughput-Treiber wurde eine weitere Workload mit derselben Workload-Konfiguration ausgelöst.
sudo bin/benchmark –drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
Beobachtung
Zum Generieren von Workloads wurden zwei verschiedene Treibertypen verwendet, um die Leistung einer auf NFS laufenden Kafka-Instanz zu vergleichen. Der Unterschied zwischen den Treibern liegt in der Log-Flush-Eigenschaft.
Für ein Cloud Volumes ONTAP HA-Paar:
-
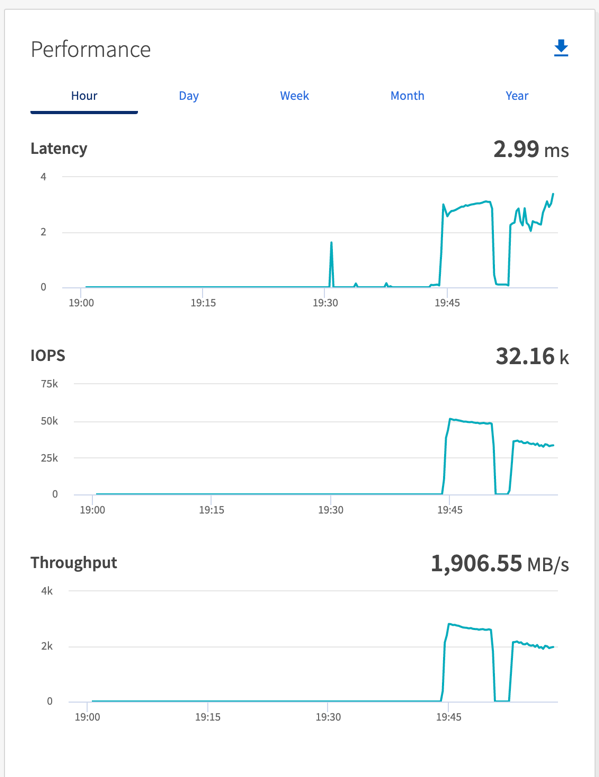
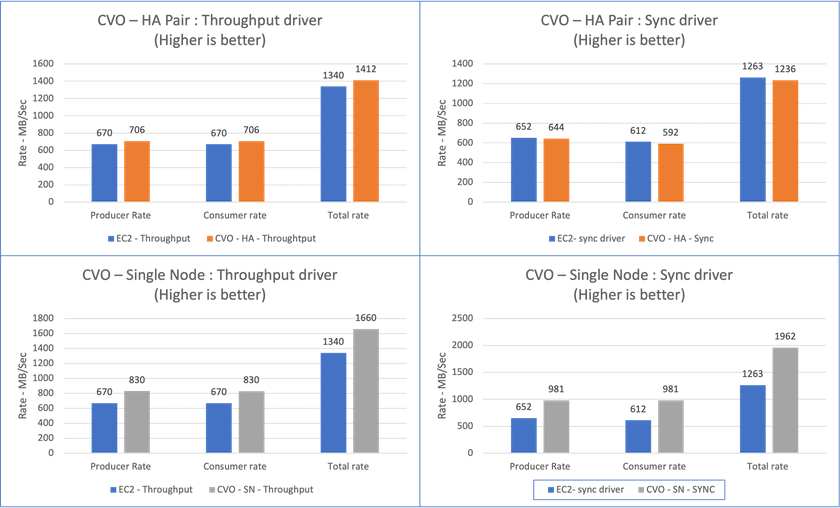
Gesamtdurchsatz, der durchgängig vom Sync-Treiber generiert wird: ~1236 MBps.
-
Gesamtdurchsatz, der für den Durchsatztreiber generiert wurde: Spitze ~1412 MBps.
Für einen einzelnen Cloud Volumes ONTAP Knoten:
-
Gesamtdurchsatz, der durchgängig vom Sync-Treiber generiert wird: ~ 1962 MBps.
-
Gesamtdurchsatz, der vom Durchsatztreiber generiert wird: Spitze ~1660 MBps
Der Sync-Treiber kann einen konsistenten Durchsatz generieren, da Protokolle sofort auf die Festplatte geschrieben werden, während der Throughput-Treiber Durchsatzschübe generiert, da Protokolle in großen Mengen auf die Festplatte geschrieben werden.
Diese Durchsatzzahlen werden für die jeweilige AWS-Konfiguration generiert. Bei höheren Leistungsanforderungen können die Instanztypen hochskaliert und für bessere Durchsatzzahlen weiter optimiert werden. Der Gesamtdurchsatz oder die Gesamtrate ist die Kombination aus Produzenten- und Verbraucherrate.
Überprüfen Sie unbedingt den Speicherdurchsatz, wenn Sie ein Durchsatz- oder Synchronisierungstreiber-Benchmarking durchführen.