Funktionale Validierung – Dumme Umbenennungskorrektur
 Änderungen vorschlagen
Änderungen vorschlagen
Zur Funktionsvalidierung haben wir gezeigt, dass ein Kafka-Cluster mit einer NFSv3-Einbindung für den Speicher keine Kafka-Operationen wie die Partitionsumverteilung durchführen kann, während ein anderer, mit dem Fix auf NFSv4 eingebundener Cluster dieselben Operationen ohne Unterbrechungen durchführen kann.
Validierungs-Setup
Das Setup wird auf AWS ausgeführt. Die folgende Tabelle zeigt die verschiedenen Plattformkomponenten und Umgebungskonfigurationen, die für die Validierung verwendet wurden.
| Plattformkomponente | Umgebungskonfiguration |
|---|---|
Confluent Platform Version 7.2.1 |
|
Betriebssystem auf allen Knoten |
RHEL8.7 oder höher |
NetApp Cloud Volumes ONTAP Instanz |
Einzelknoteninstanz – M5.2xLarge |
Die folgende Abbildung zeigt die Architekturkonfiguration für diese Lösung.
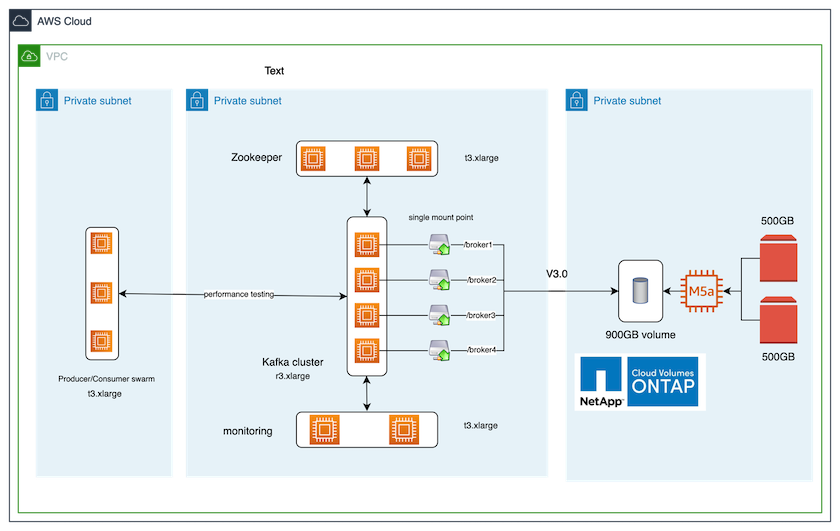
Architektonischer Fluss
-
Berechnen. Wir haben einen Kafka-Cluster mit vier Knoten und einem Zookeeper-Ensemble mit drei Knoten verwendet, das auf dedizierten Servern ausgeführt wird.
-
Überwachung. Wir haben zwei Knoten für eine Prometheus-Grafana-Kombination verwendet.
-
Arbeitsbelastung. Zum Generieren von Workloads haben wir einen separaten Cluster mit drei Knoten verwendet, der für diesen Kafka-Cluster produzieren und von diesem konsumieren kann.
-
Lagerung. Wir haben eine NetApp Cloud Volumes ONTAP Instanz mit einem Knoten verwendet, an die zwei 500 GB große GP2 AWS-EBS-Volumes angeschlossen waren. Diese Volumes wurden dann über ein LIF als einzelnes NFSv4.1-Volume dem Kafka-Cluster zugänglich gemacht.
Für alle Server wurden die Standardeigenschaften von Kafka gewählt. Dasselbe wurde für den Zoowärterschwarm getan.
Testmethodik
-
Aktualisieren
-is-preserve-unlink-enabled truezum Kafka-Band, wie folgt:aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
Es wurden zwei ähnliche Kafka-Cluster mit folgendem Unterschied erstellt:
-
Cluster 1. Der Backend-NFS v4.1-Server mit der produktionsbereiten ONTAP Version 9.12.1 wurde von einer NetApp CVO-Instanz gehostet. Auf den Brokern wurden RHEL 8.7/RHEL 9.1 installiert.
-
Cluster 2. Der Backend-NFS-Server war ein manuell erstellter generischer Linux-NFSv3-Server.
-
-
Auf beiden Kafka-Clustern wurde ein Demothema erstellt.
Cluster 1:

Cluster 2:

-
In diese neu erstellten Themen wurden für beide Cluster Daten geladen. Dies wurde mithilfe des Producer-Perf-Test-Toolkits durchgeführt, das im Standardpaket von Kafka enthalten ist:
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
Für Broker-1 wurde für jeden der Cluster per Telnet eine Integritätsprüfung durchgeführt:
-
Telnet
172.30.0.160 9092 -
Telnet
172.30.0.198 9092Eine erfolgreiche Integritätsprüfung für Broker auf beiden Clustern wird im nächsten Screenshot angezeigt:
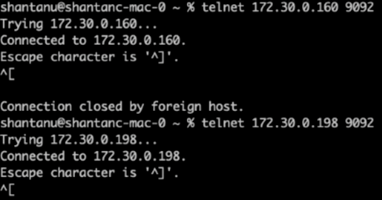
-
-
Um den Fehlerzustand auszulösen, der zum Absturz von Kafka-Clustern mit NFSv3-Speichervolumes führt, haben wir den Prozess zur Neuzuweisung der Partitionen auf beiden Clustern eingeleitet. Die Neuzuweisung der Partitionen erfolgte mit
kafka-reassign-partitions.sh. Der detaillierte Ablauf ist wie folgt:-
Um die Partitionen für ein Thema in einem Kafka-Cluster neu zuzuweisen, haben wir die vorgeschlagene JSON-Konfiguration für die Neuzuweisung generiert (dies wurde für beide Cluster durchgeführt).
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
Das generierte Neuzuweisungs-JSON wurde dann gespeichert in
/tmp/reassignment- file.json. -
Der eigentliche Partitionsneuzuweisungsprozess wurde durch den folgenden Befehl ausgelöst:
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
Einige Minuten nach Abschluss der Neuzuweisung zeigte eine weitere Integritätsprüfung der Broker, dass bei Clustern mit NFSv3-Speichervolumes ein dummes Umbenennungsproblem aufgetreten war und diese abgestürzt waren, während Cluster 1 mit NetApp ONTAP NFSv4.1-Speichervolumes und dem Fix den Betrieb ohne Unterbrechungen fortsetzte.
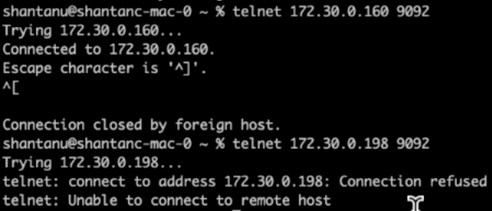
-
Cluster1-Broker-1 ist aktiv.
-
Cluster2-Broker-1 ist tot.
-
-
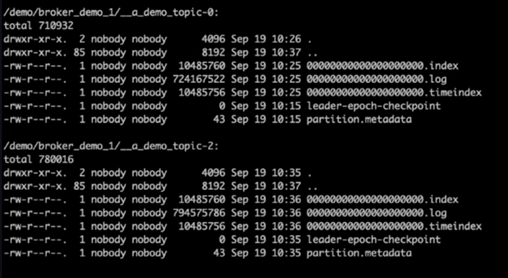
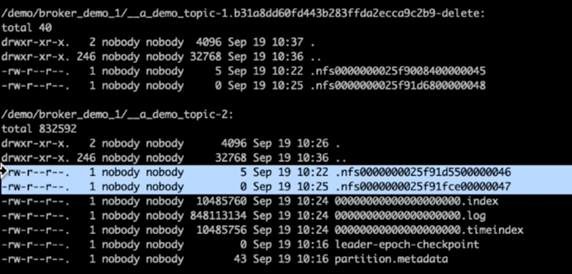
Beim Überprüfen der Kafka-Protokollverzeichnisse war klar, dass Cluster 1, der NetApp ONTAP NFSv4.1-Speichervolumes mit dem Fix verwendet, über eine saubere Partitionszuweisung verfügte, während dies bei Cluster 2, der generischen NFSv3-Speicher verwendet, aufgrund von dummen Umbenennungsproblemen, die zum Absturz führten, nicht der Fall war. Das folgende Bild zeigt die Neuverteilung der Partitionen von Cluster 2, die zu einem dummen Umbenennungsproblem im NFSv3-Speicher führte.
Das folgende Bild zeigt eine saubere Neuverteilung der Partitionen von Cluster 1 unter Verwendung von NetApp NFSv4.1-Speicher.