Warum NetApp NFS für Kafka-Workloads?
 Änderungen vorschlagen
Änderungen vorschlagen
Da es jetzt eine Lösung für das alberne Umbenennungsproblem im NFS-Speicher mit Kafka gibt, können Sie robuste Bereitstellungen erstellen, die NetApp ONTAP -Speicher für Ihre Kafka-Workload nutzen. Dies reduziert nicht nur den Betriebsaufwand erheblich, sondern bringt Ihren Kafka-Clustern auch die folgenden Vorteile:
-
Reduzierte CPU-Auslastung bei Kafka-Brokern. Durch die Verwendung disaggregierter NetApp ONTAP -Speicher werden Festplatten-E/A-Vorgänge vom Broker getrennt und so dessen CPU-Bedarf reduziert.
-
Schnellere Wiederherstellungszeit des Brokers. Da der disaggregierte NetApp ONTAP Speicher über alle Kafka-Broker-Knoten hinweg gemeinsam genutzt wird, kann eine neue Compute-Instanz einen fehlerhaften Broker jederzeit in einem Bruchteil der Zeit ersetzen, die bei herkömmlichen Kafka-Bereitstellungen benötigt wird, ohne dass die Daten neu erstellt werden müssen.
-
Speichereffizienz. Da die Speicherebene der Anwendung jetzt über NetApp ONTAP bereitgestellt wird, können Kunden alle Vorteile der Speichereffizienz von ONTAP nutzen, wie beispielsweise Inline-Datenkomprimierung, Deduplizierung und Kompaktierung.
Diese Vorteile wurden in Testfällen getestet und validiert, die wir in diesem Abschnitt ausführlich besprechen.
Reduzierte CPU-Auslastung auf dem Kafka-Broker
Wir haben festgestellt, dass die allgemeine CPU-Auslastung niedriger ist als beim DAS-Gegenstück, als wir ähnliche Workloads auf zwei separaten Kafka-Clustern ausführten, die in ihren technischen Spezifikationen identisch waren, sich aber in ihren Speichertechnologien unterschieden. Wenn der Kafka-Cluster ONTAP Speicher verwendet, ist nicht nur die allgemeine CPU-Auslastung geringer, sondern auch der Anstieg der CPU-Auslastung weist einen sanfteren Verlauf auf als in einem DAS-basierten Kafka-Cluster.
Architektonischer Aufbau
Die folgende Tabelle zeigt die Umgebungskonfiguration, die verwendet wurde, um eine reduzierte CPU-Auslastung zu demonstrieren.
| Plattformkomponente | Umgebungskonfiguration |
|---|---|
Kafka 3.2.3 Benchmarking-Tool: OpenMessaging |
|
Betriebssystem auf allen Knoten |
RHEL 8.7 oder höher |
NetApp Cloud Volumes ONTAP Instanz |
Einzelknoteninstanz – M5.2xLarge |
Benchmarking-Tool
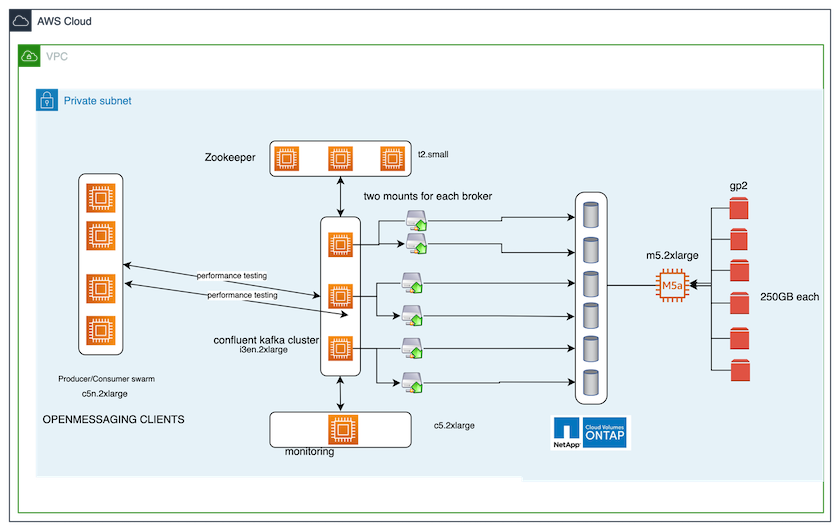
Das in diesem Testfall verwendete Benchmarking-Tool ist das "OpenMessaging" Rahmen. OpenMessaging ist anbieter- und sprachunabhängig; es bietet Branchenrichtlinien für Finanzen, E-Commerce, IoT und Big Data und unterstützt die Entwicklung von Messaging- und Streaming-Anwendungen über heterogene Systeme und Plattformen hinweg. Die folgende Abbildung zeigt die Interaktion von OpenMessaging-Clients mit einem Kafka-Cluster.
-
Berechnen. Wir haben einen Kafka-Cluster mit drei Knoten und einem Zookeeper-Ensemble mit drei Knoten verwendet, das auf dedizierten Servern ausgeführt wird. Jeder Broker verfügte über zwei NFSv4.1-Mount-Punkte zu einem einzelnen Volume auf der NetApp CVO-Instanz über ein dediziertes LIF.
-
Überwachung. Wir haben zwei Knoten für eine Prometheus-Grafana-Kombination verwendet. Zum Generieren von Workloads verfügen wir über einen separaten Cluster mit drei Knoten, der für diesen Kafka-Cluster produzieren und von diesem konsumieren kann.
-
Lagerung. Wir haben eine NetApp Cloud Volumes ONTAP Instanz mit einem Knoten und sechs auf der Instanz gemounteten 250 GB GP2 AWS-EBS-Volumes verwendet. Diese Volumes wurden dann dem Kafka-Cluster als sechs NFSv4.1-Volumes über dedizierte LIFs zugänglich gemacht.
-
Konfiguration. Die beiden konfigurierbaren Elemente in diesem Testfall waren Kafka-Broker und OpenMessaging-Workloads.
-
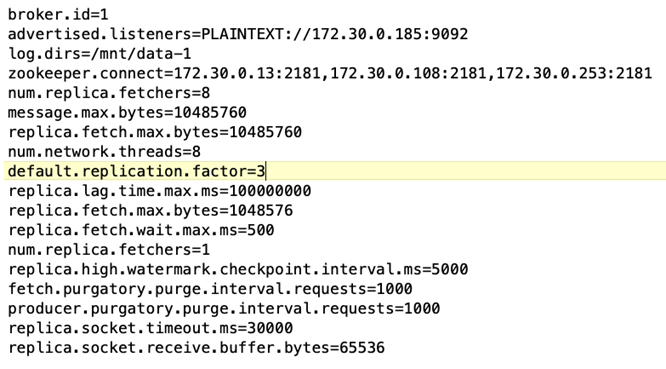
Broker-Konfiguration. Für die Kafka-Broker wurden folgende Spezifikationen gewählt. Wir haben für alle Messungen einen Replikationsfaktor von 3 verwendet, wie unten hervorgehoben.
-
-
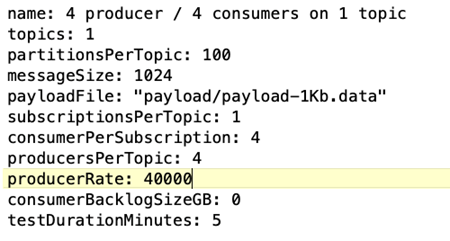
OpenMessaging-Benchmark (OMB)-Workload-Konfiguration. Die folgenden Spezifikationen wurden bereitgestellt. Wir haben eine Zielproduzentenrate festgelegt, die unten hervorgehoben ist.
Testmethodik
-
Es wurden zwei ähnliche Cluster erstellt, die jeweils über einen eigenen Satz von Benchmarking-Cluster-Schwärmen verfügten.
-
Cluster 1. NFS-basierter Kafka-Cluster.
-
Cluster 2. DAS-basierter Kafka-Cluster.
-
-
Mithilfe eines OpenMessaging-Befehls wurden auf jedem Cluster ähnliche Workloads ausgelöst.
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Die Produktionsratenkonfiguration wurde in vier Iterationen erhöht und die CPU-Auslastung mit Grafana aufgezeichnet. Die Produktionsrate wurde auf folgende Stufen festgelegt:
-
10.000
-
40.000
-
80.000
-
100.000
-
Beobachtung
Die Verwendung von NetApp NFS-Speicher mit Kafka bietet zwei Hauptvorteile:
-
Sie können die CPU-Auslastung um fast ein Drittel reduzieren. Die allgemeine CPU-Auslastung war bei ähnlichen Arbeitslasten bei NFS niedriger als bei DAS-SSDs; die Einsparungen reichen von 5 % bei niedrigeren Produktionsraten bis zu 32 % bei höheren Produktionsraten.
-
Eine dreifache Reduzierung der CPU-Auslastungsabweichung bei höheren Produktionsraten. Wie erwartet gab es mit der Erhöhung der Produktionsraten einen Aufwärtstrend bei der Erhöhung der CPU-Auslastung. Allerdings stieg die CPU-Auslastung bei Kafka-Brokern, die DAS verwenden, von 31 % bei der niedrigeren Produktionsrate auf 70 % bei der höheren Produktionsrate, also um 39 %. Mit einem NFS-Speicher-Backend stieg die CPU-Auslastung jedoch von 26 % auf 38 %, eine Steigerung um 12 %.
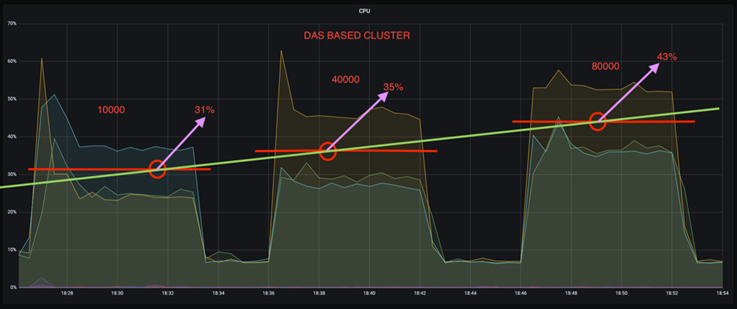
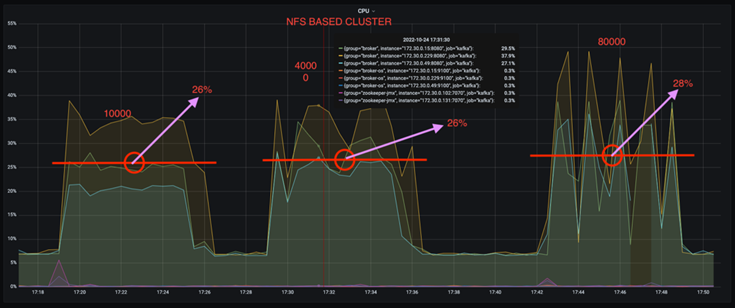
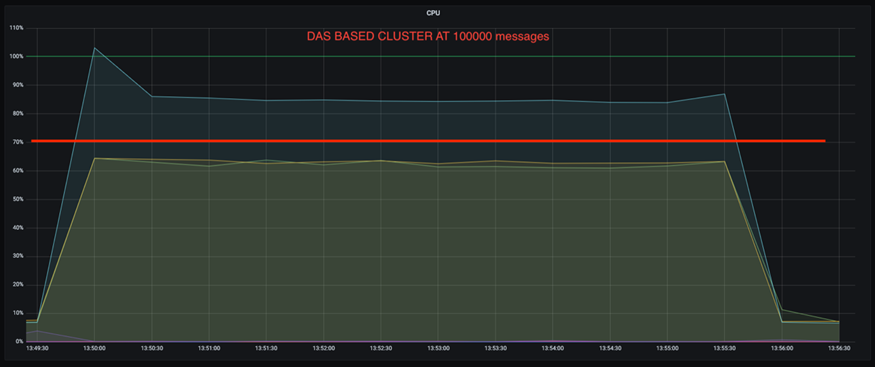
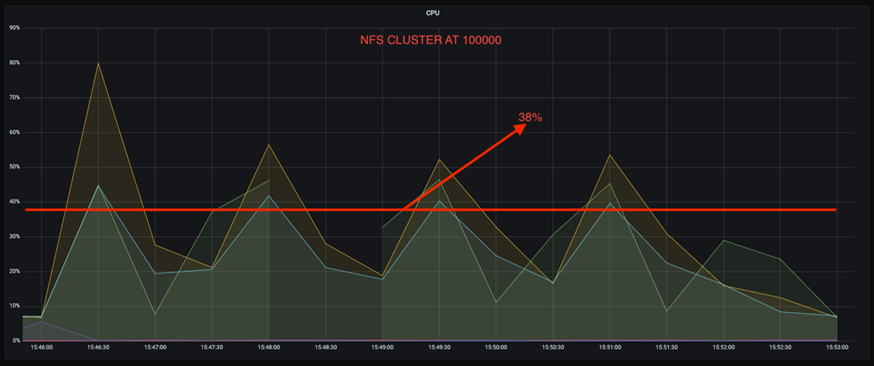
Außerdem weist DAS bei 100.000 Nachrichten eine höhere CPU-Auslastung auf als ein NFS-Cluster.
Schnellere Broker-Wiederherstellung
Wir haben festgestellt, dass Kafka-Broker schneller wiederhergestellt werden, wenn sie gemeinsam genutzten NetApp NFS-Speicher verwenden. Wenn ein Broker in einem Kafka-Cluster abstürzt, kann dieser Broker durch einen fehlerfreien Broker mit derselben Broker-ID ersetzt werden. Bei der Durchführung dieses Testfalls stellten wir fest, dass im Fall eines DAS-basierten Kafka-Clusters der Cluster die Daten auf einem neu hinzugefügten, fehlerfreien Broker neu aufbaut, was zeitaufwändig ist. Im Fall eines NetApp NFS-basierten Kafka-Clusters liest der ersetzende Broker weiterhin Daten aus dem vorherigen Protokollverzeichnis und stellt die Daten viel schneller wieder her.
Architektonischer Aufbau
Die folgende Tabelle zeigt die Umgebungskonfiguration für einen Kafka-Cluster mit NAS.
| Plattformkomponente | Umgebungskonfiguration |
|---|---|
Kafka 3.2.3 |
|
Betriebssystem auf allen Knoten |
RHEL8.7 oder höher |
NetApp Cloud Volumes ONTAP Instanz |
Einzelknoteninstanz – M5.2xLarge |
Die folgende Abbildung zeigt die Architektur eines NAS-basierten Kafka-Clusters.
-
Berechnen. Ein Kafka-Cluster mit drei Knoten und einem Zookeeper-Ensemble mit drei Knoten, das auf dedizierten Servern ausgeführt wird. Jeder Broker verfügt über zwei NFS-Mount-Punkte zu einem einzelnen Volume auf der NetApp CVO-Instanz über ein dediziertes LIF.
-
Überwachung. Zwei Knoten für eine Prometheus-Grafana-Kombination. Zum Generieren von Workloads verwenden wir einen separaten Cluster mit drei Knoten, der für diesen Kafka-Cluster produzieren und konsumieren kann.
-
Lagerung. Eine NetApp Cloud Volumes ONTAP Instanz mit einem Knoten und sechs auf der Instanz gemounteten 250 GB GP2 AWS-EBS-Volumes. Diese Volumes werden dann dem Kafka-Cluster über dedizierte LIFs als sechs NFS-Volumes zur Verfügung gestellt.
-
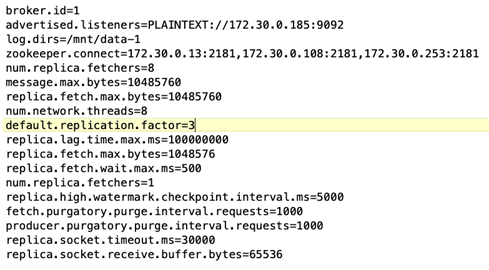
Broker-Konfiguration. Das einzige konfigurierbare Element in diesem Testfall sind Kafka-Broker. Für die Kafka-Broker wurden folgende Spezifikationen gewählt. Der
replica.lag.time.mx.mswird auf einen hohen Wert eingestellt, da dieser bestimmt, wie schnell ein bestimmter Knoten aus der ISR-Liste entfernt wird. Wenn Sie zwischen fehlerhaften und fehlerfreien Knoten wechseln, möchten Sie nicht, dass diese Broker-ID von der ISR-Liste ausgeschlossen wird.
Testmethodik
-
Es wurden zwei ähnliche Cluster erstellt:
-
Ein EC2-basierter konfluenter Cluster.
-
Ein NetApp NFS-basierter Confluent-Cluster.
-
-
Es wurde ein Standby-Kafka-Knoten mit einer Konfiguration erstellt, die mit den Knoten des ursprünglichen Kafka-Clusters identisch ist.
-
Auf jedem der Cluster wurde ein Beispielthema erstellt und auf jedem der Broker wurden ungefähr 110 GB Daten gespeichert.
-
EC2-basierter Cluster. Ein Kafka-Broker-Datenverzeichnis ist abgebildet auf
/mnt/data-2(In der folgenden Abbildung Broker-1 von Cluster1 [linkes Terminal]). -
* NetApp NFS-basierter Cluster.* Ein Kafka-Broker-Datenverzeichnis ist auf einem NFS-Punkt gemountet
/mnt/data(In der folgenden Abbildung Broker-1 von Cluster2 [rechtes Terminal]).
-
-
In jedem der Cluster wurde Broker-1 beendet, um einen fehlgeschlagenen Broker-Wiederherstellungsprozess auszulösen.
-
Nachdem der Broker beendet wurde, wurde die Broker-IP-Adresse dem Standby-Broker als sekundäre IP zugewiesen. Dies war notwendig, da ein Broker in einem Kafka-Cluster durch Folgendes identifiziert wird:
-
IP-Adresse. Zugewiesen durch Neuzuweisung der ausgefallenen Broker-IP an den Standby-Broker.
-
Broker-ID. Dies wurde im Standby-Broker konfiguriert
server.properties.
-
-
Bei der IP-Zuweisung wurde der Kafka-Dienst auf dem Standby-Broker gestartet.
-
Nach einer Weile wurden die Serverprotokolle abgerufen, um die zum Erstellen der Daten auf dem Ersatzknoten im Cluster benötigte Zeit zu überprüfen.
Beobachtung
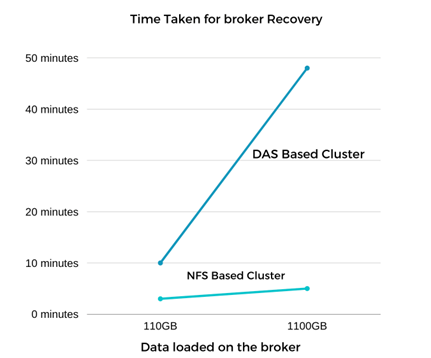
Die Wiederherstellung des Kafka-Brokers war fast neunmal schneller. Die zur Wiederherstellung eines ausgefallenen Broker-Knotens benötigte Zeit war bei Verwendung des gemeinsam genutzten NetApp NFS-Speichers deutlich kürzer als bei Verwendung von DAS-SSDs in einem Kafka-Cluster. Bei 1 TB Themendaten betrug die Wiederherstellungszeit für einen DAS-basierten Cluster 48 Minuten, verglichen mit weniger als 5 Minuten für einen NetApp-NFS-basierten Kafka-Cluster.
Wir haben festgestellt, dass der EC2-basierte Cluster 10 Minuten benötigte, um die 110 GB Daten auf dem neuen Broker-Knoten wiederherzustellen, während der NFS-basierte Cluster die Wiederherstellung in 3 Minuten abschloss. Wir haben in den Protokollen auch festgestellt, dass die Consumer-Offsets für die Partitionen für EC2 0 waren, während im NFS-Cluster die Consumer-Offsets vom vorherigen Broker übernommen wurden.
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
DAS-basierter Cluster
-
Der Sicherungsknoten wurde um 08:55:53.730 gestartet.

-
Der Datenwiederherstellungsprozess endete um 09:05:24.860. Die Verarbeitung von 110 GB Daten dauerte ungefähr 10 Minuten.

NFS-basierter Cluster
-
Der Backup-Knoten wurde um 09:39:17,213 gestartet. Der Startprotokolleintrag ist unten hervorgehoben.

-
Der Datenwiederherstellungsprozess endete um 09:42:29,115. Die Verarbeitung von 110 GB Daten dauerte ungefähr 3 Minuten.

Der Test wurde für Broker mit etwa 1 TB Daten wiederholt, was für das DAS ungefähr 48 Minuten und für NFS 3 Minuten dauerte. Die Ergebnisse sind in der folgenden Grafik dargestellt.
Speichereffizienz
Da die Speicherschicht des Kafka-Clusters über NetApp ONTAP bereitgestellt wurde, konnten wir alle Speichereffizienzfunktionen von ONTAP nutzen. Dies wurde getestet, indem eine erhebliche Datenmenge auf einem Kafka-Cluster mit NFS-Speicher generiert wurde, der auf Cloud Volumes ONTAP bereitgestellt wurde. Wir konnten feststellen, dass es aufgrund der ONTAP -Funktionen zu einer erheblichen Platzreduzierung kam.
Architektonischer Aufbau
Die folgende Tabelle zeigt die Umgebungskonfiguration für einen Kafka-Cluster mit NAS.
| Plattformkomponente | Umgebungskonfiguration |
|---|---|
Kafka 3.2.3 |
|
Betriebssystem auf allen Knoten |
RHEL8.7 oder höher |
NetApp Cloud Volumes ONTAP Instanz |
Einzelknoteninstanz – M5.2xLarge |
Die folgende Abbildung zeigt die Architektur eines NAS-basierten Kafka-Clusters.
-
Berechnen. Wir haben einen Kafka-Cluster mit drei Knoten und einem Zookeeper-Ensemble mit drei Knoten verwendet, das auf dedizierten Servern ausgeführt wird. Jeder Broker verfügte über zwei NFS-Mount-Punkte zu einem einzelnen Volume auf der NetApp CVO-Instanz über ein dediziertes LIF.
-
Überwachung. Wir haben zwei Knoten für eine Prometheus-Grafana-Kombination verwendet. Zum Generieren von Workloads haben wir einen separaten Cluster mit drei Knoten verwendet, der für diesen Kafka-Cluster produzieren und konsumieren konnte.
-
Lagerung. Wir haben eine NetApp Cloud Volumes ONTAP Instanz mit einem Knoten und sechs auf der Instanz gemounteten 250 GB GP2 AWS-EBS-Volumes verwendet. Diese Volumes wurden dann über dedizierte LIFs als sechs NFS-Volumes dem Kafka-Cluster zugänglich gemacht.
-
Konfiguration. Die konfigurierbaren Elemente in diesem Testfall waren die Kafka-Broker.
Die Komprimierung wurde auf der Produzentenseite abgeschaltet, wodurch die Produzenten einen hohen Durchsatz erzielen konnten. Die Speichereffizienz wurde stattdessen von der Rechenschicht übernommen.
Testmethodik
-
Ein Kafka-Cluster wurde mit den oben genannten Spezifikationen bereitgestellt.
-
Auf dem Cluster wurden mithilfe des OpenMessaging Benchmarking-Tools etwa 350 GB Daten erstellt.
-
Nachdem die Arbeitslast abgeschlossen war, wurden die Statistiken zur Speichereffizienz mithilfe von ONTAP System Manager und der CLI erfasst.
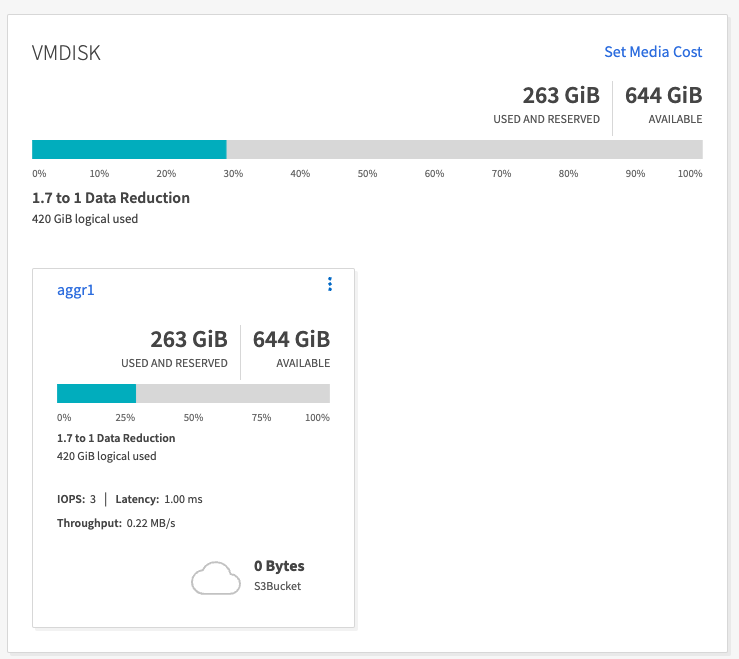
Beobachtung
Bei Daten, die mit dem OMB-Tool generiert wurden, konnten wir eine Platzersparnis von ca. 33 % bei einem Speichereffizienzverhältnis von 1,70:1 feststellen. Wie aus den folgenden Abbildungen hervorgeht, betrug der von den erzeugten Daten verwendete logische Speicherplatz 420,3 GB und der zum Speichern der Daten verwendete physische Speicherplatz 281,7 GB.