

Technologieübersicht
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt wird die in dieser Lösung verwendete Technologie beschrieben.
NetApp StorageGRID
NetApp StorageGRID ist eine leistungsstarke und kostengünstige Objektspeicherplattform. Durch die Verwendung von mehrstufigem Speicher werden die meisten Daten auf Confluent Kafka, die im lokalen Speicher oder im SAN-Speicher des Brokers gespeichert sind, in den Remote-Objektspeicher ausgelagert. Diese Konfiguration führt zu erheblichen Betriebsverbesserungen, da Zeit und Kosten für die Neuausrichtung, Erweiterung oder Verkleinerung von Clustern oder den Austausch eines ausgefallenen Brokers reduziert werden. Der Objektspeicher spielt eine wichtige Rolle bei der Verwaltung von Daten, die sich auf der Objektspeicherebene befinden. Deshalb ist die Auswahl des richtigen Objektspeichers wichtig.
StorageGRID bietet intelligentes, richtliniengesteuertes globales Datenmanagement mithilfe einer verteilten, knotenbasierten Grid-Architektur. Es vereinfacht die Verwaltung von Petabytes unstrukturierter Daten und Milliarden von Objekten durch seinen allgegenwärtigen globalen Objekt-Namespace in Kombination mit ausgefeilten Datenverwaltungsfunktionen. Der Objektzugriff per Einzelaufruf erstreckt sich über mehrere Standorte und vereinfacht Hochverfügbarkeitsarchitekturen, während gleichzeitig ein kontinuierlicher Objektzugriff unabhängig von Standort- oder Infrastrukturausfällen gewährleistet wird.
Durch die Mandantenfähigkeit können mehrere unstrukturierte Cloud- und Unternehmensdatenanwendungen sicher im selben Grid verwaltet werden, wodurch sich der ROI und die Anwendungsfälle für NetApp StorageGRID erhöhen. Sie können mehrere Service-Levels mit metadatengesteuerten Objekt-Lebenszyklusrichtlinien erstellen und so Haltbarkeit, Schutz, Leistung und Lokalität über mehrere geografische Regionen hinweg optimieren. Benutzer können Datenverwaltungsrichtlinien anpassen und Verkehrsbeschränkungen überwachen und anwenden, um sich unterbrechungsfrei an die Datenlandschaft anzupassen, wenn sich ihre Anforderungen in sich ständig verändernden IT-Umgebungen ändern.
Einfache Verwaltung mit Grid Manager
Der StorageGRID Grid Manager ist eine browserbasierte grafische Benutzeroberfläche, mit der Sie Ihr StorageGRID -System an weltweit verteilten Standorten in einer einzigen Fensteransicht konfigurieren, verwalten und überwachen können.
Mit der StorageGRID Grid Manager-Schnittstelle können Sie die folgenden Aufgaben ausführen:
-
Verwalten Sie global verteilte Repositories im Petabyte-Bereich mit Objekten wie Bildern, Videos und Aufzeichnungen.
-
Überwachen Sie Grid-Knoten und -Dienste, um die Objektverfügbarkeit sicherzustellen.
-
Verwalten Sie die Platzierung von Objektdaten im Laufe der Zeit mithilfe von Regeln für das Information Lifecycle Management (ILM). Diese Regeln legen fest, was mit den Daten eines Objekts nach der Aufnahme geschieht, wie sie vor Verlust geschützt werden, wo und wie lange die Objektdaten gespeichert werden.
-
Überwachen Sie Transaktionen, Leistung und Vorgänge innerhalb des Systems.
Richtlinien für das Information Lifecycle Management
StorageGRID verfügt über flexible Datenverwaltungsrichtlinien, die das Aufbewahren von Replikatkopien Ihrer Objekte und die Verwendung von EC-Schemata (Erasure Coding) wie 2+1 und 4+2 (unter anderem) zum Speichern Ihrer Objekte umfassen, abhängig von spezifischen Leistungs- und Datenschutzanforderungen. Da sich Arbeitslasten und Anforderungen im Laufe der Zeit ändern, ist es üblich, dass sich auch die ILM-Richtlinien im Laufe der Zeit ändern müssen. Das Ändern von ILM-Richtlinien ist eine Kernfunktion, die es StorageGRID Kunden ermöglicht, sich schnell und einfach an ihre sich ständig ändernde Umgebung anzupassen.
Performance
StorageGRID skaliert die Leistung durch Hinzufügen weiterer Speicherknoten, die VMs, Bare Metal oder speziell entwickelte Geräte wie die"SG5712, SG5760, SG6060 oder SGF6024" . In unseren Tests haben wir die wichtigsten Leistungsanforderungen von Apache Kafka mit einem Drei-Knoten-Raster der Mindestgröße unter Verwendung des SGF6024-Geräts übertroffen. Wenn Kunden ihren Kafka-Cluster mit zusätzlichen Brokern skalieren, können sie weitere Speicherknoten hinzufügen, um Leistung und Kapazität zu erhöhen.
Load Balancer und Endpunktkonfiguration
Admin-Knoten in StorageGRID bieten die Grid Manager-Benutzeroberfläche (Benutzeroberfläche) und den REST-API-Endpunkt zum Anzeigen, Konfigurieren und Verwalten Ihres StorageGRID -Systems sowie Prüfprotokolle zum Verfolgen der Systemaktivität. Um einen hochverfügbaren S3-Endpunkt für den mehrstufigen Confluent Kafka-Speicher bereitzustellen, haben wir den StorageGRID Load Balancer implementiert, der als Dienst auf Admin-Knoten und Gateway-Knoten ausgeführt wird. Darüber hinaus verwaltet der Load Balancer auch den lokalen Datenverkehr und kommuniziert mit dem GSLB (Global Server Load Balancing), um bei der Notfallwiederherstellung zu helfen.
Um die Endpunktkonfiguration weiter zu verbessern, bietet StorageGRID im Admin-Knoten integrierte Richtlinien zur Verkehrsklassifizierung, ermöglicht Ihnen die Überwachung Ihres Workload-Verkehrs und wendet verschiedene Quality-of-Service-Grenzwerte (QoS) auf Ihre Workloads an. Richtlinien zur Verkehrsklassifizierung werden auf Endpunkte des StorageGRID Load Balancer-Dienstes für Gateway-Knoten und Admin-Knoten angewendet. Diese Richtlinien können bei der Verkehrsgestaltung und -überwachung helfen.
Verkehrsklassifizierung in StorageGRID
StorageGRID verfügt über eine integrierte QoS-Funktionalität. Richtlinien zur Verkehrsklassifizierung können dabei helfen, verschiedene Arten von S3-Verkehr zu überwachen, der von einer Clientanwendung kommt. Sie können dann Richtlinien erstellen und anwenden, um diesen Datenverkehr basierend auf der Eingangs-/Ausgangsbandbreite, der Anzahl gleichzeitiger Lese-/Schreibanforderungen oder der Lese-/Schreibanforderungsrate zu begrenzen.
Apache Kafka
Apache Kafka ist eine Framework-Implementierung eines Softwarebusses mit Stream-Verarbeitung, geschrieben in Java und Scala. Ziel ist es, eine einheitliche Plattform mit hohem Durchsatz und geringer Latenz für die Verarbeitung von Echtzeit-Datenfeeds bereitzustellen. Kafka kann über Kafka Connect eine Verbindung zu einem externen System zum Datenexport und -import herstellen und bietet Kafka Streams, eine Java-Stream-Verarbeitungsbibliothek. Kafka verwendet ein binäres, TCP-basiertes Protokoll, das auf Effizienz optimiert ist und auf einer „Nachrichtensatz“-Abstraktion basiert, die Nachrichten auf natürliche Weise gruppiert, um den Overhead des Netzwerk-Roundtrips zu reduzieren. Dies ermöglicht größere sequenzielle Festplattenvorgänge, größere Netzwerkpakete und zusammenhängende Speicherblöcke, wodurch Kafka einen stoßweisen Strom zufälliger Nachrichtenschreibvorgänge in lineare Schreibvorgänge umwandeln kann. Die folgende Abbildung zeigt den grundlegenden Datenfluss von Apache Kafka.
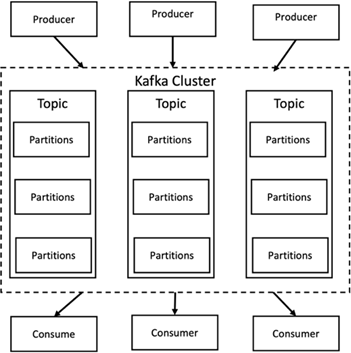
Kafka speichert Schlüssel-Wert-Nachrichten, die von einer beliebigen Anzahl von Prozessen, sogenannten Produzenten, stammen. Die Daten können innerhalb verschiedener Themen in verschiedene Partitionen aufgeteilt werden. Innerhalb einer Partition werden Nachrichten streng nach ihren Offsets (der Position einer Nachricht innerhalb einer Partition) geordnet und zusammen mit einem Zeitstempel indiziert und gespeichert. Andere Prozesse, sogenannte Verbraucher, können Nachrichten aus Partitionen lesen. Für die Stream-Verarbeitung bietet Kafka die Streams-API, die das Schreiben von Java-Anwendungen ermöglicht, die Daten von Kafka nutzen und Ergebnisse zurück an Kafka schreiben. Apache Kafka funktioniert auch mit externen Stream-Verarbeitungssystemen wie Apache Apex, Apache Flink, Apache Spark, Apache Storm und Apache NiFi.
Kafka läuft auf einem Cluster aus einem oder mehreren Servern (Brokern genannt) und die Partitionen aller Themen werden auf die Clusterknoten verteilt. Darüber hinaus werden Partitionen auf mehrere Broker repliziert. Diese Architektur ermöglicht es Kafka, riesige Nachrichtenströme fehlertolerant zu übermitteln und einige der herkömmlichen Nachrichtensysteme wie Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP) usw. zu ersetzen. Seit der Version 0.11.0.0 bietet Kafka transaktionale Schreibvorgänge, die mithilfe der Streams-API eine exakt einmalige Stream-Verarbeitung ermöglichen.
Kafka unterstützt zwei Arten von Themen: regulär und kompakt. Reguläre Themen können mit einer Aufbewahrungsdauer oder einer Platzbegrenzung konfiguriert werden. Wenn Datensätze vorhanden sind, die älter als die angegebene Aufbewahrungszeit sind, oder wenn die Speicherplatzgrenze für eine Partition überschritten wird, darf Kafka alte Daten löschen, um Speicherplatz freizugeben. Standardmäßig sind Themen mit einer Aufbewahrungszeit von 7 Tagen konfiguriert, es ist jedoch auch möglich, Daten unbegrenzt zu speichern. Bei komprimierten Themen verfallen Datensätze nicht aufgrund von Zeit- oder Speicherplatzbeschränkungen. Stattdessen behandelt Kafka spätere Nachrichten als Aktualisierungen älterer Nachrichten mit demselben Schlüssel und garantiert, dass die neueste Nachricht pro Schlüssel niemals gelöscht wird. Benutzer können Nachrichten vollständig löschen, indem sie eine sogenannte Tombstone-Nachricht mit dem Nullwert für einen bestimmten Schlüssel schreiben.
Es gibt fünf wichtige APIs in Kafka:
-
Produzenten-API. Ermöglicht einer Anwendung, Datensatzströme zu veröffentlichen.
-
Consumer-API. Ermöglicht einer Anwendung, Themen zu abonnieren und Datensatzströme zu verarbeiten.
-
Connector-API. Führt die wiederverwendbaren Producer- und Consumer-APIs aus, die die Themen mit den vorhandenen Anwendungen verknüpfen können.
-
Streams-API. Diese API konvertiert die Eingabeströme in Ausgaben und erzeugt das Ergebnis.
-
Admin-API. Wird zum Verwalten von Kafka-Themen, Brokern und anderen Kafka-Objekten verwendet.
Die Consumer- und Producer-APIs bauen auf dem Kafka-Messaging-Protokoll auf und bieten eine Referenzimplementierung für Kafka-Consumer- und Producer-Clients in Java. Das zugrunde liegende Nachrichtenprotokoll ist ein Binärprotokoll, das Entwickler verwenden können, um ihre eigenen Consumer- oder Producer-Clients in jeder beliebigen Programmiersprache zu schreiben. Dadurch wird Kafka aus dem Ökosystem der Java Virtual Machine (JVM) entsperrt. Eine Liste der verfügbaren Nicht-Java-Clients wird im Apache Kafka-Wiki verwaltet.
Apache Kafka-Anwendungsfälle
Apache Kafka wird am häufigsten für Messaging, Website-Aktivitätsverfolgung, Metriken, Protokollaggregation, Stream-Verarbeitung, Event Sourcing und Commit-Protokollierung verwendet.
-
Kafka verfügt über einen verbesserten Durchsatz, integrierte Partitionierung, Replikation und Fehlertoleranz, was es zu einer guten Lösung für groß angelegte Nachrichtenverarbeitungsanwendungen macht.
-
Kafka kann die Aktivitäten eines Benutzers (Seitenaufrufe, Suchvorgänge) in einer Tracking-Pipeline als eine Reihe von Publish-Subscribe-Feeds in Echtzeit wiederherstellen.
-
Kafka wird häufig für Betriebsüberwachungsdaten verwendet. Dabei werden Statistiken aus verteilten Anwendungen aggregiert, um zentralisierte Feeds mit Betriebsdaten zu erstellen.
-
Viele Leute verwenden Kafka als Ersatz für eine Protokollaggregationslösung. Bei der Protokollaggregation werden in der Regel physische Protokolldateien von Servern gesammelt und zur Verarbeitung an einem zentralen Ort (z. B. einem Dateiserver oder HDFS) abgelegt. Kafka abstrahiert Dateidetails und bietet eine sauberere Abstraktion von Protokoll- oder Ereignisdaten als Nachrichtenstrom. Dies ermöglicht eine Verarbeitung mit geringerer Latenz und eine einfachere Unterstützung mehrerer Datenquellen und einer verteilten Datennutzung.
-
Viele Kafka-Benutzer verarbeiten Daten in Verarbeitungspipelines, die aus mehreren Phasen bestehen, in denen Roheingabedaten aus Kafka-Themen verwendet und dann aggregiert, angereichert oder anderweitig in neue Themen zur weiteren Verwendung oder Weiterverarbeitung umgewandelt werden. Beispielsweise könnte eine Verarbeitungspipeline zum Empfehlen von Nachrichtenartikeln Artikelinhalte aus RSS-Feeds crawlen und in einem „Artikel“-Thema veröffentlichen. Bei der weiteren Verarbeitung kann dieser Inhalt normalisiert oder dedupliziert und der bereinigte Artikelinhalt in einem neuen Thema veröffentlicht werden. In einer letzten Verarbeitungsphase kann versucht werden, den Benutzern diesen Inhalt zu empfehlen. Solche Verarbeitungspipelines erstellen Diagramme von Echtzeit-Datenflüssen basierend auf den einzelnen Themen.
-
Event Sourcing ist ein Anwendungsdesignstil, bei dem Statusänderungen als zeitlich geordnete Abfolge von Datensätzen protokolliert werden. Die Unterstützung von Kafka für sehr große gespeicherte Protokolldaten macht es zu einem hervorragenden Backend für eine in diesem Stil erstellte Anwendung.
-
Kafka kann als eine Art externes Commit-Log für ein verteiltes System dienen. Das Protokoll hilft bei der Replikation von Daten zwischen Knoten und fungiert als Neusynchronisierungsmechanismus für ausgefallene Knoten, um ihre Daten wiederherzustellen. Die Protokollkomprimierungsfunktion in Kafka unterstützt diesen Anwendungsfall.
Zusammenfließend
Confluent Platform ist eine unternehmensreife Plattform, die Kafka um erweiterte Funktionen ergänzt, die die Anwendungsentwicklung und Konnektivität beschleunigen, Transformationen durch Stream-Verarbeitung ermöglichen, Unternehmensabläufe im großen Maßstab vereinfachen und strenge Architekturanforderungen erfüllen sollen. Confluent wurde von den ursprünglichen Entwicklern von Apache Kafka entwickelt und erweitert die Vorteile von Kafka um Funktionen auf Unternehmensniveau, während es gleichzeitig den Aufwand für die Verwaltung oder Überwachung von Kafka verringert. Heute nutzen über 80 % der Fortune 100-Unternehmen Datenstreaming-Technologie – und die meisten von ihnen verwenden Confluent.
Warum Confluent?
Durch die Integration historischer und Echtzeitdaten in eine einzige, zentrale Quelle der Wahrheit erleichtert Confluent den Aufbau einer völlig neuen Kategorie moderner, ereignisgesteuerter Anwendungen, den Aufbau einer universellen Datenpipeline und die Erschließung leistungsstarker neuer Anwendungsfälle mit voller Skalierbarkeit, Leistung und Zuverlässigkeit.
Wofür wird Confluent verwendet?
Mit der Confluent Platform können Sie sich darauf konzentrieren, wie Sie aus Ihren Daten geschäftlichen Nutzen ziehen, anstatt sich um die zugrunde liegenden Mechanismen zu kümmern, beispielsweise darum, wie Daten zwischen unterschiedlichen Systemen transportiert oder integriert werden. Insbesondere vereinfacht die Confluent Platform die Verbindung von Datenquellen mit Kafka, die Erstellung von Streaming-Anwendungen sowie die Sicherung, Überwachung und Verwaltung Ihrer Kafka-Infrastruktur. Heute wird die Confluent Platform für eine breite Palette von Anwendungsfällen in zahlreichen Branchen eingesetzt, von Finanzdienstleistungen, Omnichannel-Einzelhandel und autonomen Autos bis hin zu Betrugserkennung, Microservices und IoT.
Die folgende Abbildung zeigt die Komponenten der Confluent Kafka-Plattform.
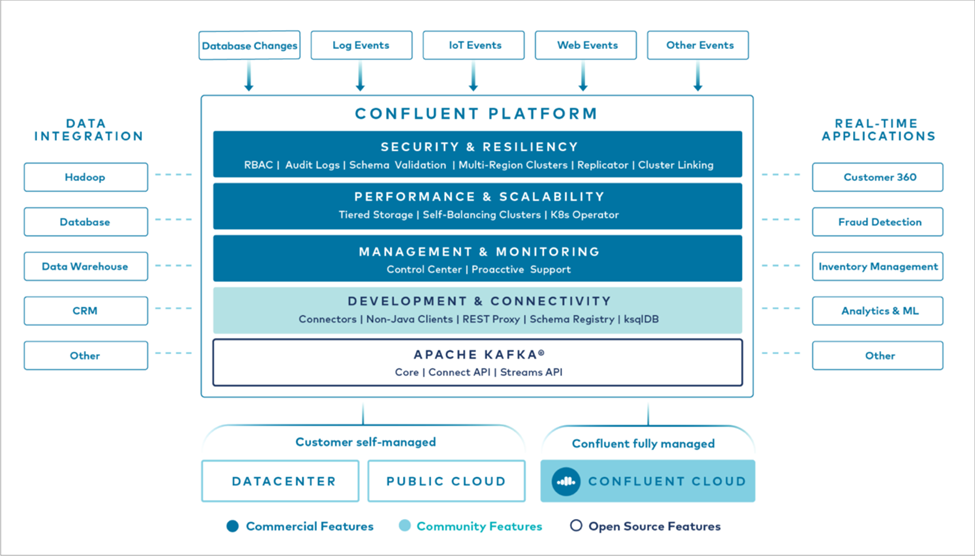
Überblick über die Event-Streaming-Technologie von Confluent
Der Kern der Confluent Platform ist "Apache Kafka" , die beliebteste Open-Source-Plattform für verteiltes Streaming. Die wichtigsten Funktionen von Kafka sind:
-
Veröffentlichen und abonnieren Sie Datensatz-Streams.
-
Speichern Sie Datensatzströme fehlertolerant.
-
Verarbeiten Sie Datensatzströme.
Die Confluent Platform umfasst standardmäßig auch Schema Registry, REST Proxy, insgesamt über 100 vorgefertigte Kafka-Konnektoren und ksqlDB.
Übersicht über die Enterprise-Funktionen der Confluent-Plattform
-
Confluent-Kontrollzentrum. Ein GUI-basiertes System zur Verwaltung und Überwachung von Kafka. Es ermöglicht Ihnen die einfache Verwaltung von Kafka Connect und das Erstellen, Bearbeiten und Verwalten von Verbindungen zu anderen Systemen.
-
Confluent für Kubernetes. Confluent für Kubernetes ist ein Kubernetes-Operator. Kubernetes-Operatoren erweitern die Orchestrierungsfunktionen von Kubernetes, indem sie die einzigartigen Funktionen und Anforderungen für eine bestimmte Plattformanwendung bereitstellen. Für die Confluent Platform bedeutet dies eine erhebliche Vereinfachung des Bereitstellungsprozesses von Kafka auf Kubernetes und die Automatisierung typischer Aufgaben im Lebenszyklus der Infrastruktur.
-
Konfluente Konnektoren zu Kafka. Konnektoren verwenden die Kafka Connect-API, um Kafka mit anderen Systemen wie Datenbanken, Schlüssel-Wert-Speichern, Suchindizes und Dateisystemen zu verbinden. Confluent Hub verfügt über herunterladbare Konnektoren für die gängigsten Datenquellen und -senken, einschließlich vollständig getesteter und unterstützter Versionen dieser Konnektoren mit Confluent Platform. Weitere Details finden Sie "hier," .
-
Selbstausgleichende Cluster. Bietet automatisierten Lastausgleich, Fehlererkennung und Selbstheilung. Es bietet Unterstützung für das Hinzufügen oder Außerbetriebnehmen von Brokern nach Bedarf, ohne dass eine manuelle Anpassung erforderlich ist.
-
Konfluente Clusterverknüpfung. Verbindet Cluster direkt miteinander und spiegelt Themen von einem Cluster zum anderen über eine Linkbrücke. Die Clusterverknüpfung vereinfacht die Einrichtung von Multi-Datacenter-, Multi-Cluster- und Hybrid-Cloud-Bereitstellungen.
-
Confluent automatischer Datenausgleich. Überwacht Ihren Cluster hinsichtlich der Anzahl der Broker, der Größe der Partitionen, der Anzahl der Partitionen und der Anzahl der Leader innerhalb des Clusters. Sie können Daten verschieben, um eine gleichmäßige Arbeitslast in Ihrem Cluster zu erreichen, und gleichzeitig den Datenverkehr drosseln, um die Auswirkungen auf die Produktionsarbeitslasten während der Neuverteilung zu minimieren.
-
Konfluenter Replikator. Macht es einfacher als je zuvor, mehrere Kafka-Cluster in mehreren Rechenzentren zu verwalten.
-
Stufenspeicher. Bietet Optionen zum Speichern großer Mengen von Kafka-Daten bei Ihrem bevorzugten Cloud-Anbieter und reduziert so den Betriebsaufwand und die Kosten. Mit Tiered Storage können Sie Daten auf kostengünstigem Objektspeicher aufbewahren und Broker nur dann skalieren, wenn Sie mehr Rechenressourcen benötigen.
-
Confluent JMS-Client. Confluent Platform enthält einen JMS-kompatiblen Client für Kafka. Dieser Kafka-Client implementiert die JMS 1.1-Standard-API und verwendet Kafka-Broker als Backend. Dies ist nützlich, wenn Sie über ältere Anwendungen verfügen, die JMS verwenden, und Sie den vorhandenen JMS-Nachrichtenbroker durch Kafka ersetzen möchten.
-
Confluent MQTT-Proxy. Bietet eine Möglichkeit, Daten von MQTT-Geräten und -Gateways direkt an Kafka zu veröffentlichen, ohne dass ein MQTT-Broker dazwischengeschaltet werden muss.
-
Confluent-Sicherheits-Plugins. Confluent-Sicherheits-Plugins werden verwendet, um verschiedenen Tools und Produkten der Confluent-Plattform Sicherheitsfunktionen hinzuzufügen. Derzeit ist ein Plug-In für den Confluent REST-Proxy verfügbar, das bei der Authentifizierung eingehender Anfragen hilft und den authentifizierten Auftraggeber an Anfragen an Kafka weitergibt. Dadurch können Confluent REST-Proxy-Clients die Multitenant-Sicherheitsfunktionen des Kafka-Brokers nutzen.