

Übersicht über die NetApp Spark-Lösungen
 Änderungen vorschlagen
Änderungen vorschlagen
NetApp verfügt über drei Speicherportfolios: FAS/ AFF, E-Serie und Cloud Volumes ONTAP. Wir haben AFF und die E-Serie mit ONTAP Speichersystem für Hadoop-Lösungen mit Apache Spark validiert.
Das von NetApp betriebene Datengewebe integriert Datenverwaltungsdienste und Anwendungen (Bausteine) für Datenzugriff, -kontrolle, -schutz und -sicherheit, wie in der folgenden Abbildung dargestellt.
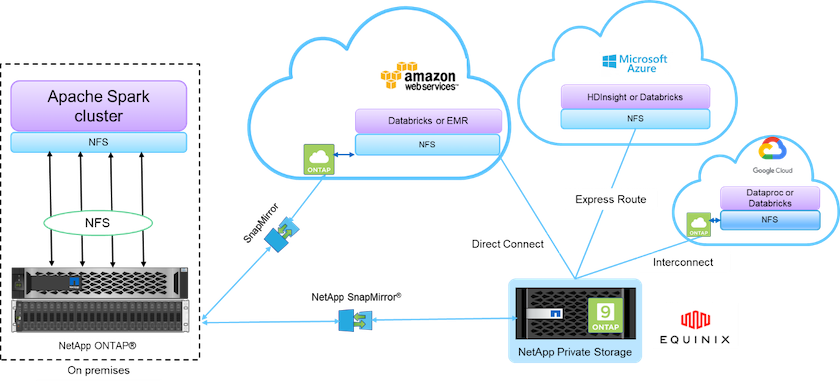
Zu den Bausteinen in der obigen Abbildung gehören:
-
* NetApp NFS-Direktzugriff.* Bietet den neuesten Hadoop- und Spark-Clustern direkten Zugriff auf NetApp NFS-Volumes ohne zusätzliche Software- oder Treiberanforderungen.
-
* NetApp Cloud Volumes ONTAP und Google Cloud NetApp Volumes.* Softwaredefinierter verbundener Speicher basierend auf ONTAP , der in Amazon Web Services (AWS) oder Azure NetApp Files (ANF) in Microsoft Azure-Clouddiensten ausgeführt wird.
-
* NetApp SnapMirror Technologie.* Bietet Datenschutzfunktionen zwischen lokalen und ONTAP Cloud- oder NPS-Instanzen.
-
Cloud-Dienstanbieter. Zu diesen Anbietern gehören AWS, Microsoft Azure, Google Cloud und IBM Cloud.
-
PaaS. Cloudbasierte Analysedienste wie Amazon Elastic MapReduce (EMR) und Databricks in AWS sowie Microsoft Azure HDInsight und Azure Databricks.
Die folgende Abbildung zeigt die Spark-Lösung mit NetApp Speicher.
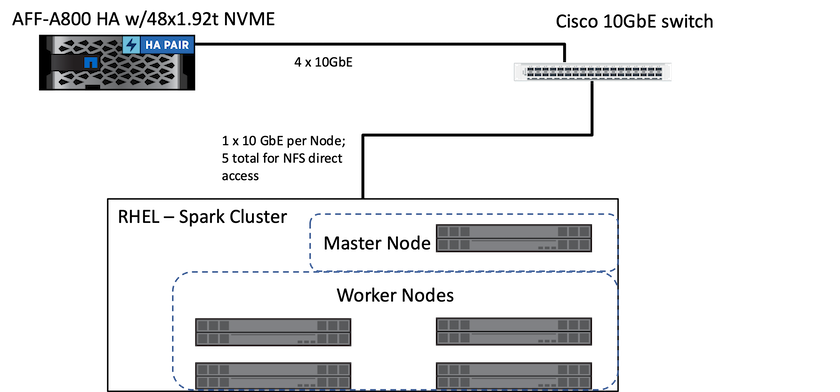
Die ONTAP Spark-Lösung verwendet das NetApp NFS-Direktzugriffsprotokoll für In-Place-Analysen und KI-, ML- und DL-Workflows unter Zugriff auf vorhandene Produktionsdaten. Für Hadoop-Knoten verfügbare Produktionsdaten werden exportiert, um vor Ort analytische sowie KI-, ML- und DL-Jobs auszuführen. Sie können auf die zu verarbeitenden Daten in Hadoop-Knoten entweder mit oder ohne direkten NetApp NFS-Zugriff zugreifen. In Spark mit dem Standalone- oder yarn Cluster-Manager können Sie ein NFS-Volume konfigurieren, indem Sie file://<target_volume> . Wir haben drei Anwendungsfälle mit unterschiedlichen Datensätzen validiert. Die Einzelheiten dieser Validierungen werden im Abschnitt „Testergebnisse“ vorgestellt. (xref)
Die folgende Abbildung zeigt die Speicherpositionierung von NetApp Apache Spark/Hadoop.
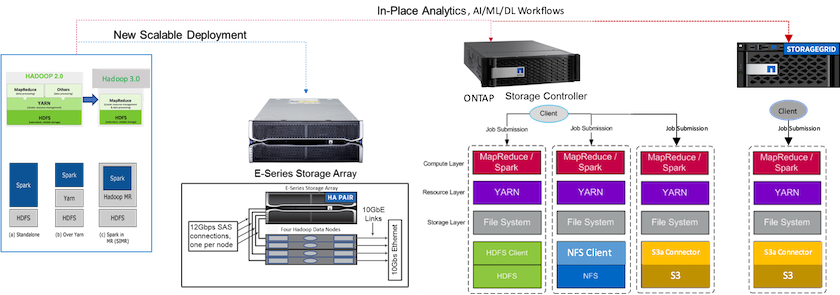
Wir haben die einzigartigen Funktionen der E-Series Spark-Lösung, der AFF/ FAS ONTAP Spark-Lösung und der StorageGRID Spark-Lösung identifiziert und detaillierte Validierungen und Tests durchgeführt. Basierend auf unseren Beobachtungen empfiehlt NetApp die E-Series-Lösung für Greenfield-Installationen und neue skalierbare Bereitstellungen sowie die AFF/ FAS -Lösung für In-Place-Analysen, KI-, ML- und DL-Workloads unter Verwendung vorhandener NFS-Daten und StorageGRID für KI-, ML- und DL- und moderne Datenanalysen, wenn Objektspeicher erforderlich ist.
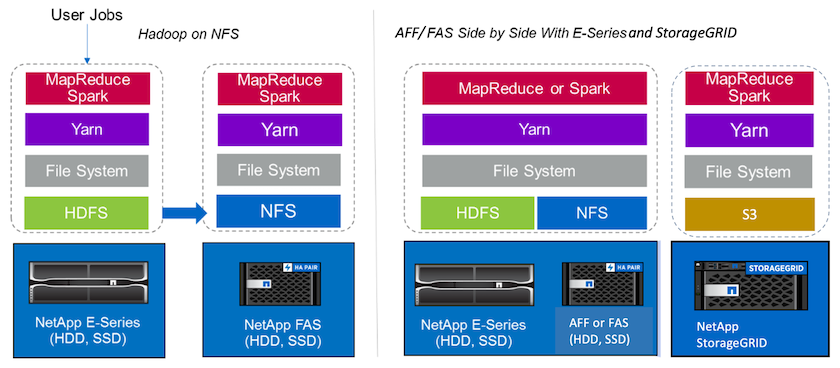
Ein Data Lake ist ein Speicherrepository für große Datensätze in nativer Form, das für Analyse-, KI-, ML- und DL-Aufgaben verwendet werden kann. Wir haben ein Data Lake-Repository für die Spark-Lösungen E-Series, AFF/ FAS und StorageGRID SG6060 erstellt. Das E-Series-System bietet HDFS-Zugriff auf den Hadoop Spark-Cluster, während auf vorhandene Produktionsdaten über das NFS-Direktzugriffsprotokoll auf den Hadoop-Cluster zugegriffen wird. Für Datensätze, die sich im Objektspeicher befinden, bietet NetApp StorageGRID sicheren S3- und S3a-Zugriff.