

Leistungsvalidierung der Vektordatenbank
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt wird die Leistungsvalidierung hervorgehoben, die an der Vektordatenbank durchgeführt wurde.
Leistungsvalidierung
Die Leistungsvalidierung spielt sowohl bei Vektordatenbanken als auch bei Speichersystemen eine entscheidende Rolle und ist ein Schlüsselfaktor für die Gewährleistung eines optimalen Betriebs und einer effizienten Ressourcennutzung. Vektordatenbanken, die für die Verarbeitung hochdimensionaler Daten und die Durchführung von Ähnlichkeitssuchen bekannt sind, müssen ein hohes Leistungsniveau aufrechterhalten, um komplexe Abfragen schnell und genau verarbeiten zu können. Mithilfe der Leistungsvalidierung können Engpässe identifiziert und Konfigurationen optimiert werden. Außerdem wird sichergestellt, dass das System die erwartete Belastung ohne Leistungseinbußen bewältigen kann. Ebenso ist bei Speichersystemen eine Leistungsvalidierung unerlässlich, um sicherzustellen, dass Daten effizient gespeichert und abgerufen werden, ohne dass es zu Latenzproblemen oder Engpässen kommt, die die Gesamtleistung des Systems beeinträchtigen könnten. Es hilft auch dabei, fundierte Entscheidungen über notwendige Upgrades oder Änderungen der Speicherinfrastruktur zu treffen. Daher ist die Leistungsvalidierung ein entscheidender Aspekt des Systemmanagements und trägt erheblich zur Aufrechterhaltung einer hohen Servicequalität, Betriebseffizienz und allgemeinen Systemzuverlässigkeit bei.
In diesem Abschnitt möchten wir uns eingehend mit der Leistungsvalidierung von Vektordatenbanken wie Milvus und pgvecto.rs befassen und uns dabei auf ihre Speicherleistungsmerkmale wie E/A-Profil und Verhalten des NetApp-Speichercontrollers zur Unterstützung von RAG- und Inferenz-Workloads innerhalb des LLM-Lebenszyklus konzentrieren. Wir werden alle Leistungsunterschiede bewerten und identifizieren, wenn diese Datenbanken mit der ONTAP Speicherlösung kombiniert werden. Unsere Analyse basiert auf wichtigen Leistungsindikatoren, beispielsweise der Anzahl der pro Sekunde verarbeiteten Abfragen (QPS).
Bitte überprüfen Sie unten die für Milvus und den Fortschritt verwendete Methodik.
Details |
Milvus (Standalone und Cluster) |
Postgres(pgvecto.rs) # |
Version |
2.3.2 |
0.2.0 |
Dateisystem |
XFS auf iSCSI-LUNs |
|
Arbeitslastgenerator |
"VectorDB-Bench"– Version 0.0.5 |
|
Datensätze |
LAION-Datensatz * 10 Millionen Einbettungen * 768 Dimensionen * ~300 GB Datensatzgröße |
|
Speichercontroller |
AFF 800 * Version – 9.14.1 * 4 x 100GbE – für Milvus und 2x 100GbE für Postgres * iscsi |
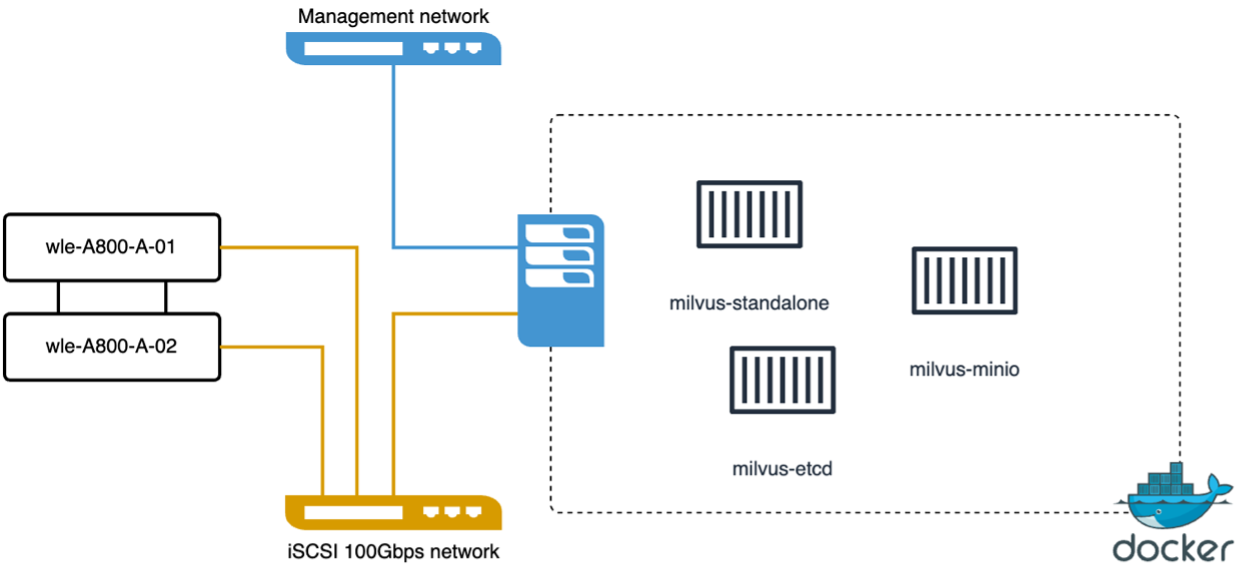
VectorDB-Bench mit Milvus-Standalone-Cluster
Wir haben die folgende Leistungsvalidierung auf dem eigenständigen Milvus-Cluster mit VectorDB-Bench durchgeführt. Die Netzwerk- und Serverkonnektivität des eigenständigen Milvus-Clusters ist unten aufgeführt.
In diesem Abschnitt teilen wir unsere Beobachtungen und Ergebnisse aus dem Testen der eigenständigen Milvus-Datenbank. . Für diese Tests haben wir DiskANN als Indextyp ausgewählt. . Das Aufnehmen, Optimieren und Erstellen von Indizes für einen Datensatz von etwa 100 GB dauerte etwa 5 Stunden. Während des größten Teils dieser Dauer lief der mit 20 Kernen ausgestattete Milvus-Server (was bei aktiviertem Hyper-Threading 40 vcpus entspricht) mit seiner maximalen CPU-Kapazität von 100 %. Wir haben festgestellt, dass DiskANN besonders wichtig für große Datensätze ist, die die Größe des Systemspeichers überschreiten. . In der Abfragephase beobachteten wir eine Abfragerate pro Sekunde (QPS) von 10,93 mit einem Rückruf von 0,9987. Die Latenzzeit für Abfragen im 99. Perzentil wurde mit 708,2 Millisekunden gemessen.
Aus Speichersicht gab die Datenbank während der Aufnahme-, Post-Insert-Optimierungs- und Indexerstellungsphasen etwa 1.000 Operationen/Sekunde aus. In der Abfragephase waren 32.000 Operationen/Sek. erforderlich.
Der folgende Abschnitt stellt die Speicherleistungsmetriken vor.
| Arbeitslastphase | Metrisch | Wert |
|---|---|---|
Datenaufnahme und Optimierung nach dem Einfügen |
IOPS |
< 1.000 |
Latenz |
< 400 µs |
|
Arbeitsbelastung |
Lese-/Schreib-Mix, hauptsächlich Schreibvorgänge |
|
IO-Größe |
64 KB |
|
Abfrage |
IOPS |
Höchststand bei 32.000 |
Latenz |
< 400 µs |
|
Arbeitsbelastung |
100 % zwischengespeicherte Lesevorgänge |
|
IO-Größe |
Hauptsächlich 8 KB |
Das VectorDB-Bench-Ergebnis ist unten.
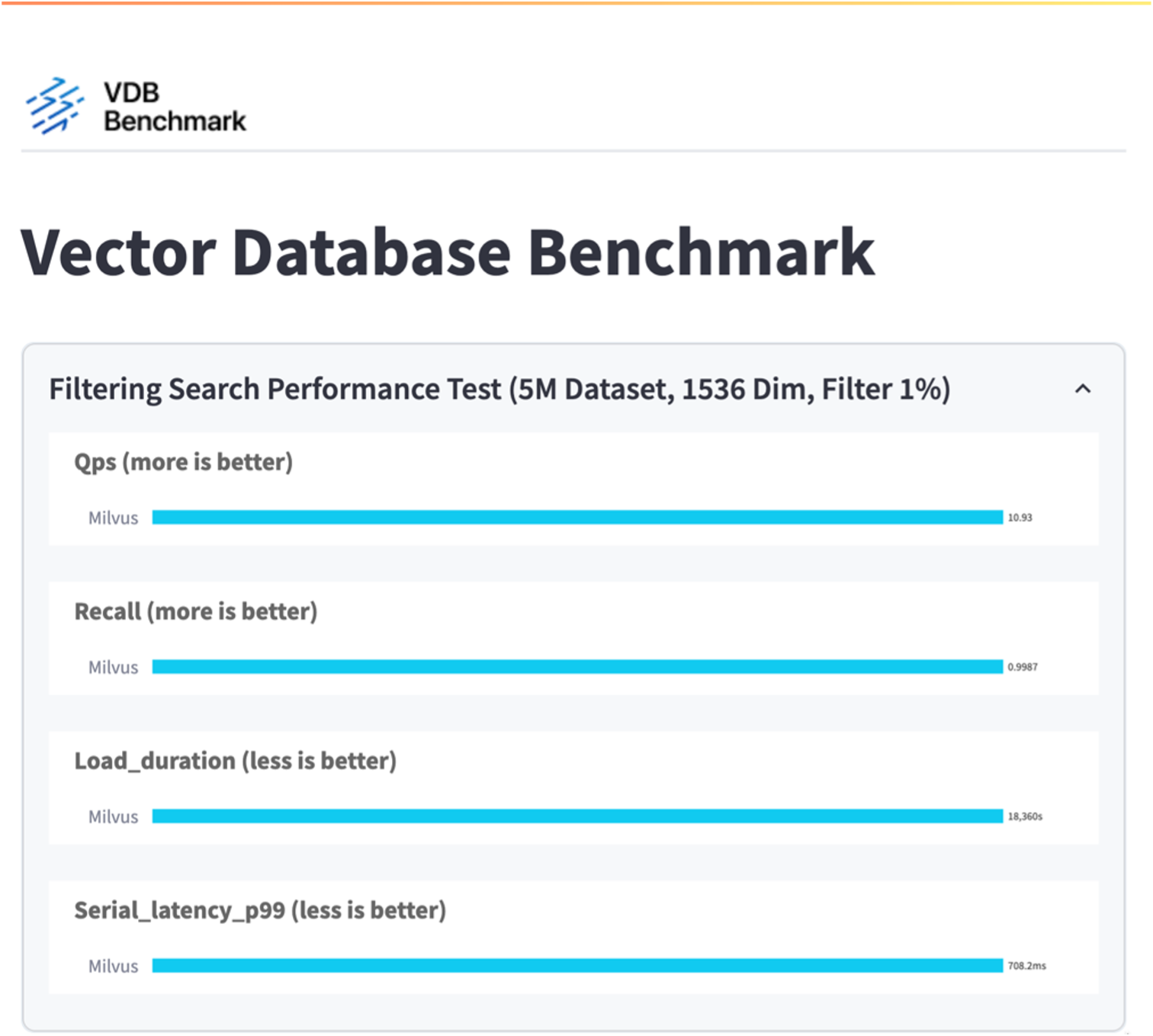
Aus der Leistungsvalidierung der eigenständigen Milvus-Instanz geht hervor, dass die aktuelle Konfiguration nicht ausreicht, um einen Datensatz von 5 Millionen Vektoren mit einer Dimensionalität von 1536 zu unterstützen. Wir haben festgestellt, dass der Speicher über ausreichende Ressourcen verfügt und keinen Engpass im System darstellt.
VectorDB-Bench mit Milvus-Cluster
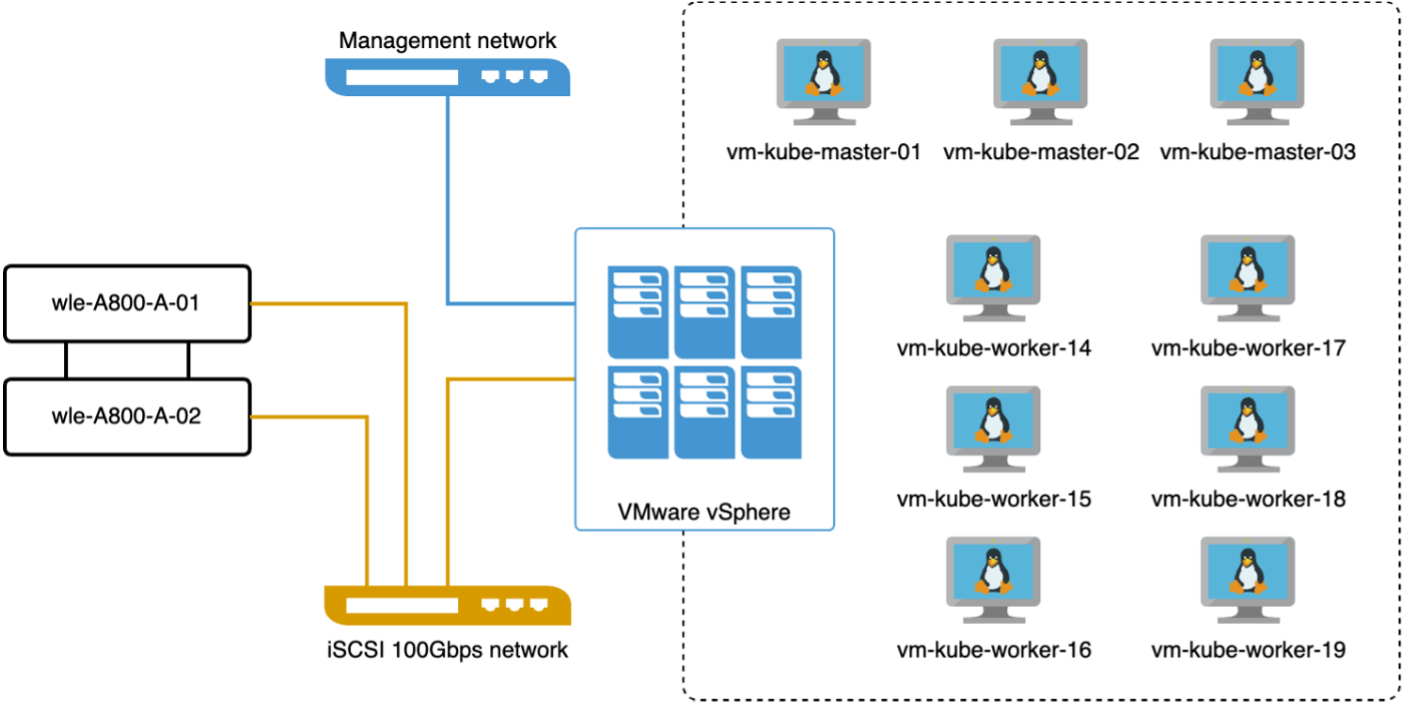
In diesem Abschnitt besprechen wir die Bereitstellung eines Milvus-Clusters in einer Kubernetes-Umgebung. Dieses Kubernetes-Setup wurde auf einer VMware vSphere-Bereitstellung erstellt, die die Kubernetes-Master- und Worker-Knoten hostete.
Die Details der VMware vSphere- und Kubernetes-Bereitstellungen werden in den folgenden Abschnitten vorgestellt.
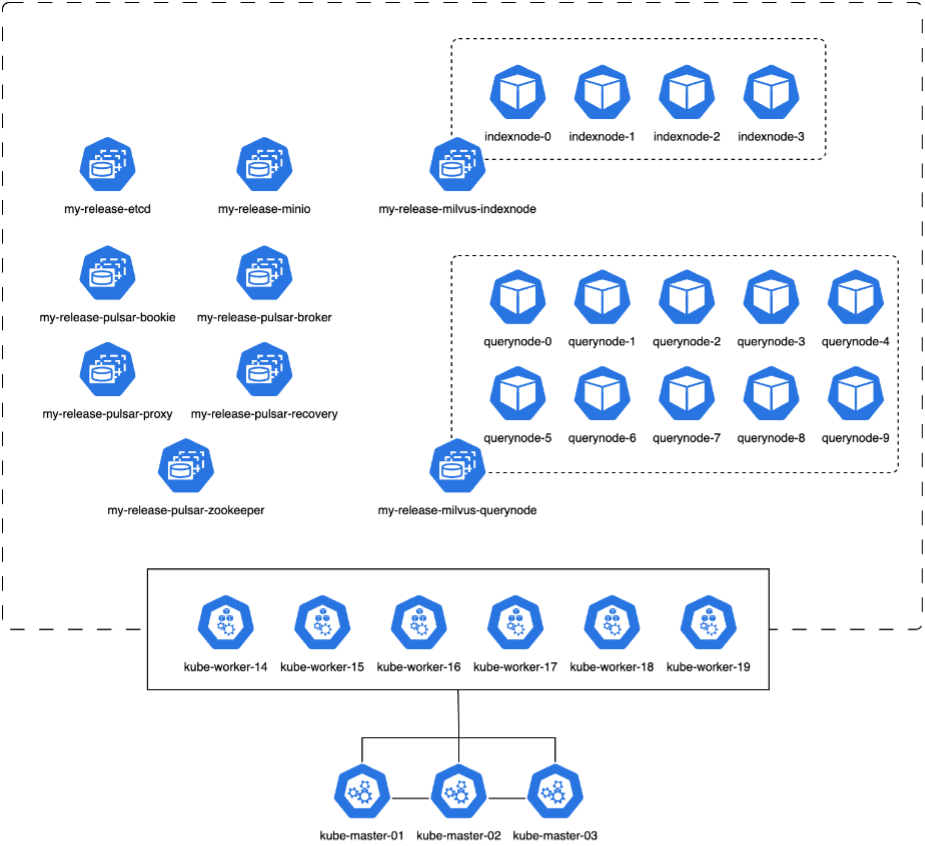
In diesem Abschnitt stellen wir unsere Beobachtungen und Ergebnisse aus dem Testen der Milvus-Datenbank vor. * Der verwendete Indextyp war DiskANN. * Die folgende Tabelle bietet einen Vergleich zwischen den Standalone- und Cluster-Bereitstellungen bei der Arbeit mit 5 Millionen Vektoren bei einer Dimensionalität von 1536. Wir haben festgestellt, dass die für die Datenaufnahme und die Optimierung nach dem Einfügen benötigte Zeit bei der Clusterbereitstellung kürzer war. Die Latenzzeit für Abfragen im 99. Perzentil wurde im Cluster-Einsatz im Vergleich zum Standalone-Setup um das Sechsfache reduziert. * Obwohl die Abfragerate pro Sekunde (QPS) bei der Clusterbereitstellung höher war, lag sie nicht auf dem gewünschten Niveau.

Die folgenden Bilder bieten eine Ansicht verschiedener Speichermetriken, einschließlich der Speicherclusterlatenz und der gesamten IOPS (Input/Output Operations Per Second).
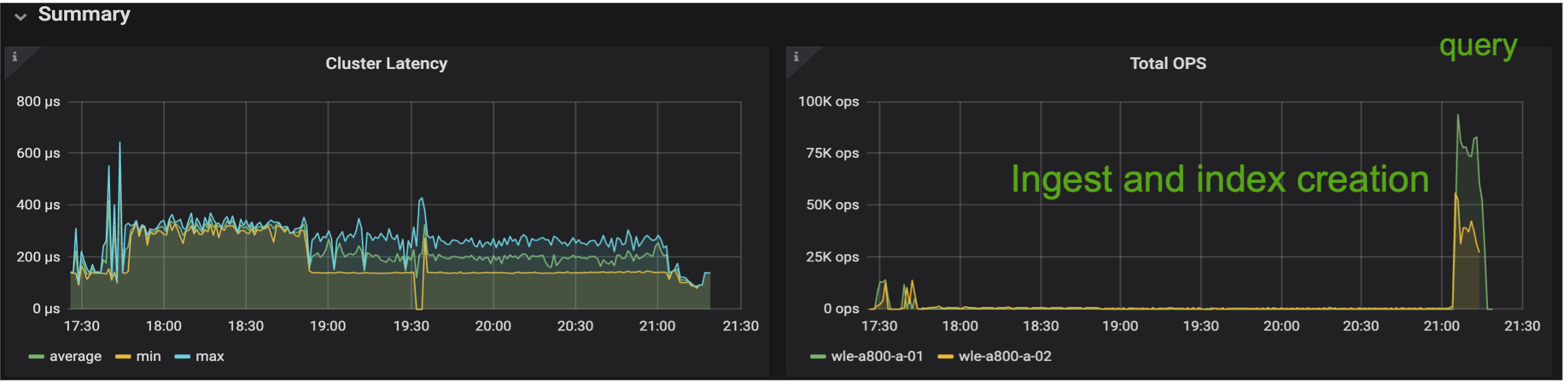
Der folgende Abschnitt stellt die wichtigsten Leistungskennzahlen für den Speicher vor.
| Arbeitslastphase | Metrisch | Wert |
|---|---|---|
Datenaufnahme und Optimierung nach dem Einfügen |
IOPS |
< 1.000 |
Latenz |
< 400 µs |
|
Arbeitsbelastung |
Lese-/Schreib-Mix, hauptsächlich Schreibvorgänge |
|
IO-Größe |
64 KB |
|
Abfrage |
IOPS |
Höchststand bei 147.000 |
Latenz |
< 400 µs |
|
Arbeitsbelastung |
100 % zwischengespeicherte Lesevorgänge |
|
IO-Größe |
Hauptsächlich 8 KB |
Basierend auf der Leistungsvalidierung sowohl des eigenständigen Milvus als auch des Milvus-Clusters präsentieren wir die Details des Speicher-E/A-Profils. * Wir haben festgestellt, dass das E/A-Profil sowohl bei eigenständigen als auch bei Cluster-Bereitstellungen konsistent bleibt. * Der beobachtete Unterschied bei den Spitzen-IOPS kann auf die größere Anzahl von Clients in der Clusterbereitstellung zurückgeführt werden.
vectorDB-Bench mit Postgres (pgvecto.rs)
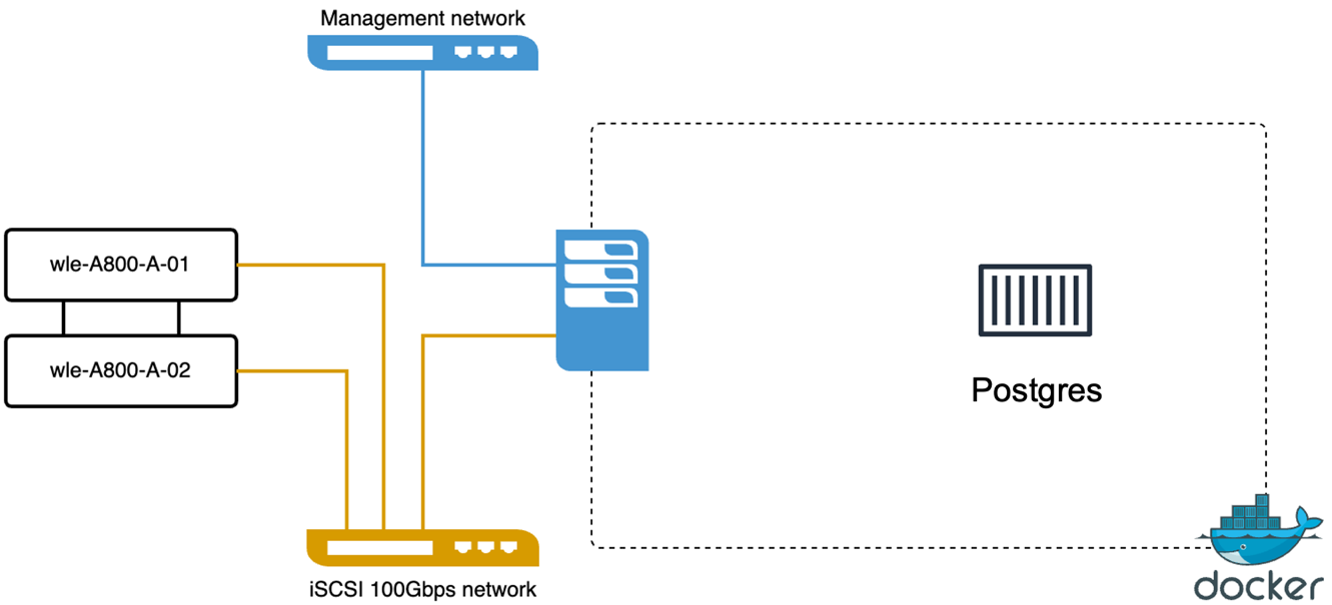
Wir haben die folgenden Aktionen mit VectorDB-Bench an PostgreSQL (pgvecto.rs) durchgeführt: Die Details zur Netzwerk- und Serverkonnektivität von PostgreSQL (insbesondere pgvecto.rs) lauten wie folgt:
In diesem Abschnitt teilen wir unsere Beobachtungen und Ergebnisse aus dem Testen der PostgreSQL-Datenbank, insbesondere mit pgvecto.rs. * Wir haben HNSW als Indextyp für diese Tests ausgewählt, da DiskANN zum Zeitpunkt des Tests für pgvecto.rs nicht verfügbar war. * Während der Datenaufnahmephase haben wir den Cohere-Datensatz geladen, der aus 10 Millionen Vektoren mit einer Dimensionalität von 768 besteht. Dieser Vorgang dauerte ungefähr 4,5 Stunden. * In der Abfragephase haben wir eine Abfragerate pro Sekunde (QPS) von 1.068 mit einem Rückruf von 0,6344 beobachtet. Die Latenzzeit für Abfragen im 99. Perzentil wurde mit 20 Millisekunden gemessen. Während des größten Teils der Laufzeit war die CPU des Clients zu 100 % ausgelastet.
Die folgenden Bilder bieten eine Ansicht verschiedener Speichermetriken, einschließlich der Gesamt-IOPS (Input/Output Operations Per Second) der Speicherclusterlatenz.

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["Abbildung, die einen Eingabe-/Ausgabedialog zeigt oder schriftlichen Inhalt darstellt"]
Leistungsvergleich zwischen Milvus und Postgres auf Vector DB Bench
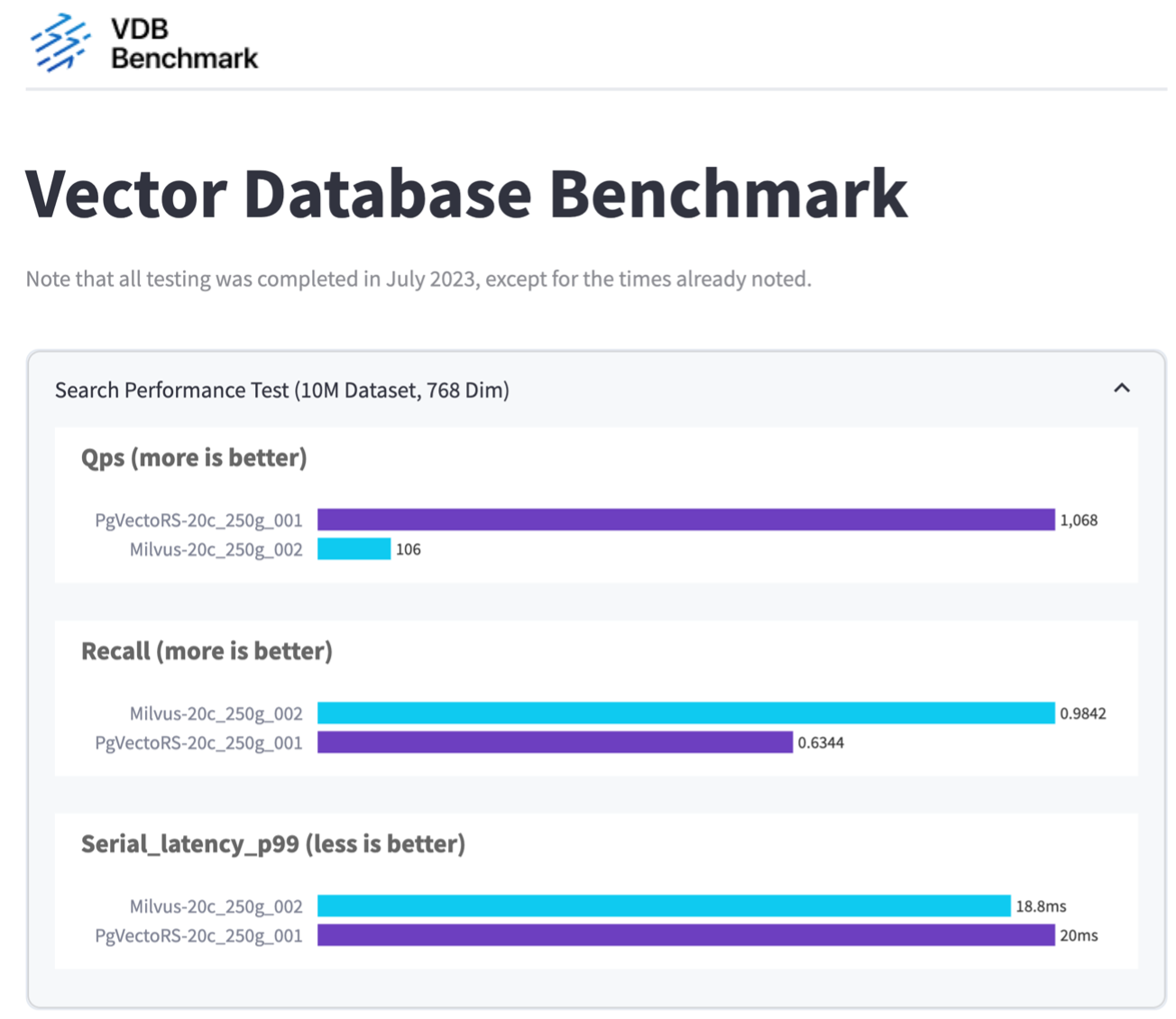
Basierend auf unserer Leistungsvalidierung von Milvus und PostgreSQL mit VectorDBBench haben wir Folgendes beobachtet:
-
Indextyp: HNSW
-
Datensatz: Cohere mit 10 Millionen Vektoren in 768 Dimensionen
Wir haben festgestellt, dass pgvecto.rs eine Abfragen-pro-Sekunde-Rate (QPS) von 1.068 mit einem Recall von 0,6344 erreichte, während Milvus eine QPS-Rate von 106 mit einem Recall von 0,9842 erreichte.
Wenn hohe Präzision bei Ihren Abfragen Priorität hat, ist Milvus besser als pgvecto.rs, da es einen höheren Anteil relevanter Elemente pro Abfrage abruft. Wenn jedoch die Anzahl der Abfragen pro Sekunde ein entscheidenderer Faktor ist, übertrifft pgvecto.rs Milvus. Es ist jedoch wichtig zu beachten, dass die Qualität der über pgvecto.rs abgerufenen Daten geringer ist, da etwa 37 % der Suchergebnisse irrelevante Elemente sind.
Beobachtung basierend auf unseren Leistungsvalidierungen:
Basierend auf unseren Leistungsvalidierungen haben wir folgende Beobachtungen gemacht:
In Milvus ähnelt das E/A-Profil stark einer OLTP-Workload, wie sie beispielsweise bei Oracle SLOB auftritt. Der Benchmark besteht aus drei Phasen: Datenaufnahme, Nachoptimierung und Abfrage. Die Anfangsphasen sind hauptsächlich durch 64-KB-Schreibvorgänge gekennzeichnet, während die Abfragephase überwiegend 8-KB-Lesevorgänge umfasst. Wir erwarten, dass ONTAP die Milvus-E/A-Last effizient bewältigt.
Das PostgreSQL-E/A-Profil stellt keine anspruchsvolle Speicherarbeitslast dar. Angesichts der derzeit laufenden In-Memory-Implementierung konnten wir während der Abfragephase keine Festplatten-E/A beobachten.
DiskANN erweist sich als entscheidende Technologie zur Speicherdifferenzierung. Es ermöglicht die effiziente Skalierung der Vektor-DB-Suche über die Systemspeichergrenze hinaus. Es ist jedoch unwahrscheinlich, dass mit In-Memory-Vektor-DB-Indizes wie HNSW eine Differenzierung der Speicherleistung erreicht wird.
Es ist auch erwähnenswert, dass der Speicher während der Abfragephase keine kritische Rolle spielt, wenn der Indextyp HSNW ist. Dies ist die wichtigste Betriebsphase für Vektordatenbanken, die RAG-Anwendungen unterstützen. Dies bedeutet, dass die Speicherleistung keinen signifikanten Einfluss auf die Gesamtleistung dieser Anwendungen hat.