

Anwendungsfälle für Vektordatenbanken
 Änderungen vorschlagen
Änderungen vorschlagen
Dieser Abschnitt bietet einen Überblick über die Anwendungsfälle für die NetApp Vector-Datenbanklösung.
Anwendungsfälle für Vektordatenbanken
In diesem Abschnitt besprechen wir zwei Anwendungsfälle, nämlich Retrieval Augmented Generation mit großen Sprachmodellen und NetApp IT-Chatbot.
Retrieval Augmented Generation (RAG) mit großen Sprachmodellen (LLMs)
Retrieval-augmented generation, or RAG, is a technique for enhancing the accuracy and reliability of Large Language Models, or LLMs, by augmenting prompts with facts fetched from external sources. In a traditional RAG deployment, vector embeddings are generated from an existing dataset and then stored in a vector database, often referred to as a knowledgebase. Whenever a user submits a prompt to the LLM, a vector embedding representation of the prompt is generated, and the vector database is searched using that embedding as the search query. This search operation returns similar vectors from the knowledgebase, which are then fed to the LLM as context alongside the original user prompt. In this way, an LLM can be augmented with additional information that was not part of its original training dataset.
Der NVIDIA Enterprise RAG LLM Operator ist ein nützliches Tool zur Implementierung von RAG im Unternehmen. Mit diesem Operator kann eine vollständige RAG-Pipeline bereitgestellt werden. Die RAG-Pipeline kann angepasst werden, um entweder Milvus oder pgvecto als Vektordatenbank zum Speichern von Wissensdatenbank-Einbettungen zu verwenden. Weitere Einzelheiten finden Sie in der Dokumentation.
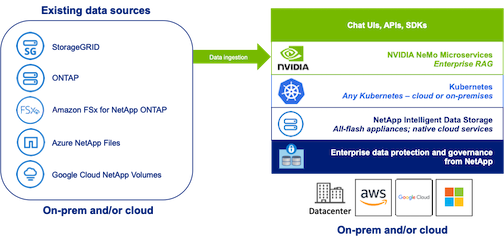
NetApp has validated an enterprise RAG architecture powered by the NVIDIA Enterprise RAG LLM Operator alongside NetApp storage. Refer to our blog post for more information and to see a demo. Figure 1 provides an overview of this architecture.
Abbildung 1) Enterprise RAG mit NVIDIA NeMo Microservices und NetApp
Anwendungsfall für den NetApp IT-Chatbot
Der Chatbot von NetApp dient als weiterer Echtzeit-Anwendungsfall für die Vektordatenbank. In diesem Fall bietet die NetApp Private OpenAI Sandbox eine effektive, sichere und effiziente Plattform für die Verwaltung von Abfragen interner NetApp-Benutzer. Durch die Integration strenger Sicherheitsprotokolle, effizienter Datenverwaltungssysteme und ausgefeilter KI-Verarbeitungsfunktionen werden den Benutzern über die SSO-Authentifizierung qualitativ hochwertige und präzise Antworten basierend auf ihren Rollen und Verantwortlichkeiten in der Organisation garantiert. Diese Architektur unterstreicht das Potenzial der Zusammenführung fortschrittlicher Technologien zur Schaffung benutzerorientierter, intelligenter Systeme.
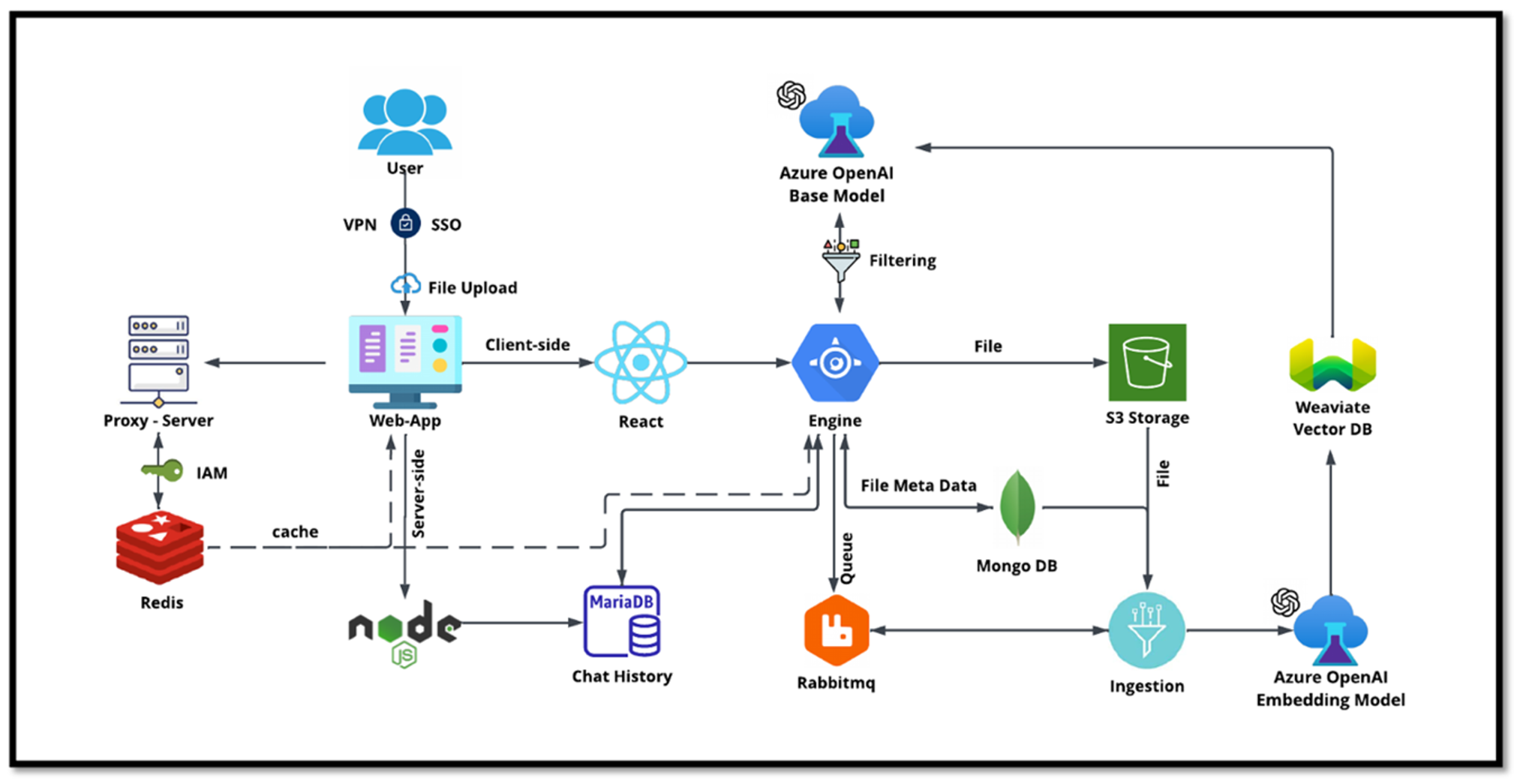
Der Anwendungsfall kann in vier Hauptabschnitte unterteilt werden.
Benutzerauthentifizierung und -verifizierung:
-
Benutzeranfragen durchlaufen zunächst den NetApp Single Sign-On (SSO)-Prozess, um die Identität des Benutzers zu bestätigen.
-
Nach erfolgreicher Authentifizierung prüft das System die VPN-Verbindung, um eine sichere Datenübertragung zu gewährleisten.
Datenübertragung und -verarbeitung:
-
Sobald das VPN validiert ist, werden die Daten über die Webanwendungen NetAIChat oder NetAICreate an MariaDB gesendet. MariaDB ist ein schnelles und effizientes Datenbanksystem zum Verwalten und Speichern von Benutzerdaten.
-
MariaDB sendet die Informationen dann an die NetApp Azure-Instanz, die die Benutzerdaten mit der KI-Verarbeitungseinheit verbindet.
Interaktion mit OpenAI und Inhaltsfilterung:
-
Die Azure-Instanz sendet die Fragen des Benutzers an ein Inhaltsfiltersystem. Dieses System bereinigt die Abfrage und bereitet sie für die Verarbeitung vor.
-
Die bereinigte Eingabe wird dann an das Azure OpenAI-Basismodell gesendet, das basierend auf der Eingabe eine Antwort generiert.
Antwortgenerierung und -moderation:
-
Die Antwort des Basismodells wird zunächst überprüft, um sicherzustellen, dass sie korrekt ist und den Inhaltsstandards entspricht.
-
Nach bestandener Prüfung wird die Antwort an den Benutzer zurückgesendet. Dieser Prozess stellt sicher, dass der Benutzer eine klare, genaue und angemessene Antwort auf seine Anfrage erhält.