Schrittweise Oracle-Bereitstellungsverfahren auf AWS EC2 und FSx
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt werden die Bereitstellungsverfahren für die Bereitstellung einer benutzerdefinierten Oracle RDS-Datenbank mit FSx-Speicher beschrieben.
Stellen Sie eine EC2-Linux-Instance für Oracle über die EC2-Konsole bereit
Wenn Sie neu bei AWS sind, müssen Sie zunächst eine AWS-Umgebung einrichten. Die Registerkarte „Dokumentation“ auf der Zielseite der AWS-Website bietet Links zu EC2-Anweisungen zum Bereitstellen einer Linux EC2-Instanz, die zum Hosten Ihrer Oracle-Datenbank über die AWS EC2-Konsole verwendet werden kann. Der folgende Abschnitt ist eine Zusammenfassung dieser Schritte. Einzelheiten finden Sie in der verlinkten AWS EC2-spezifischen Dokumentation.
Einrichten Ihrer AWS EC2-Umgebung
Sie müssen ein AWS-Konto erstellen, um die erforderlichen Ressourcen zum Ausführen Ihrer Oracle-Umgebung auf dem EC2- und FSx-Dienst bereitzustellen. Die folgende AWS-Dokumentation liefert die notwendigen Details:
Schlüsselthemen:
-
Registrieren Sie sich bei AWS.
-
Erstellen Sie ein Schlüsselpaar.
-
Erstellen Sie eine Sicherheitsgruppe.
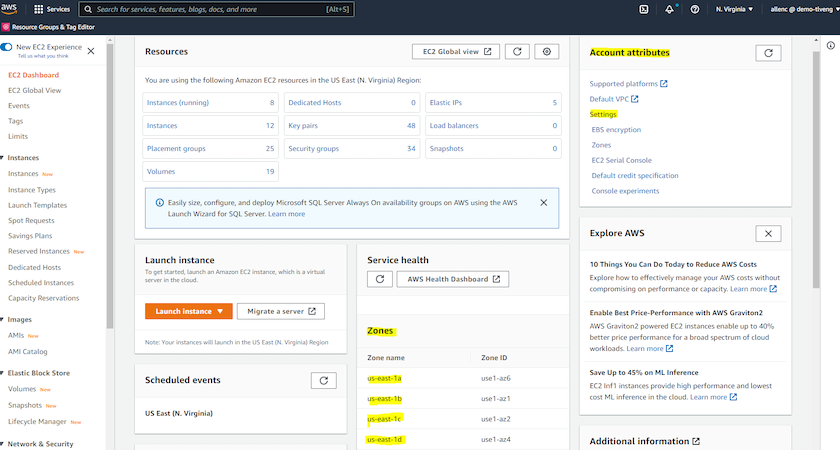
Aktivieren mehrerer Verfügbarkeitszonen in AWS-Kontoattributen
Für eine Oracle-Hochverfügbarkeitskonfiguration, wie im Architekturdiagramm dargestellt, müssen Sie mindestens vier Verfügbarkeitszonen in einer Region aktivieren. Die mehreren Verfügbarkeitszonen können auch in verschiedenen Regionen liegen, um die erforderlichen Entfernungen für die Notfallwiederherstellung einzuhalten.
Erstellen und Verbinden mit einer EC2-Instance zum Hosten einer Oracle-Datenbank
Sehen Sie sich das Tutorial an"Erste Schritte mit Amazon EC2 Linux-Instances" für schrittweise Bereitstellungsverfahren und Best Practices.
Schlüsselthemen:
-
Überblick.
-
Voraussetzungen.
-
Schritt 1: Starten Sie eine Instanz.
-
Schritt 2: Stellen Sie eine Verbindung zu Ihrer Instanz her.
-
Schritt 3: Bereinigen Sie Ihre Instanz.
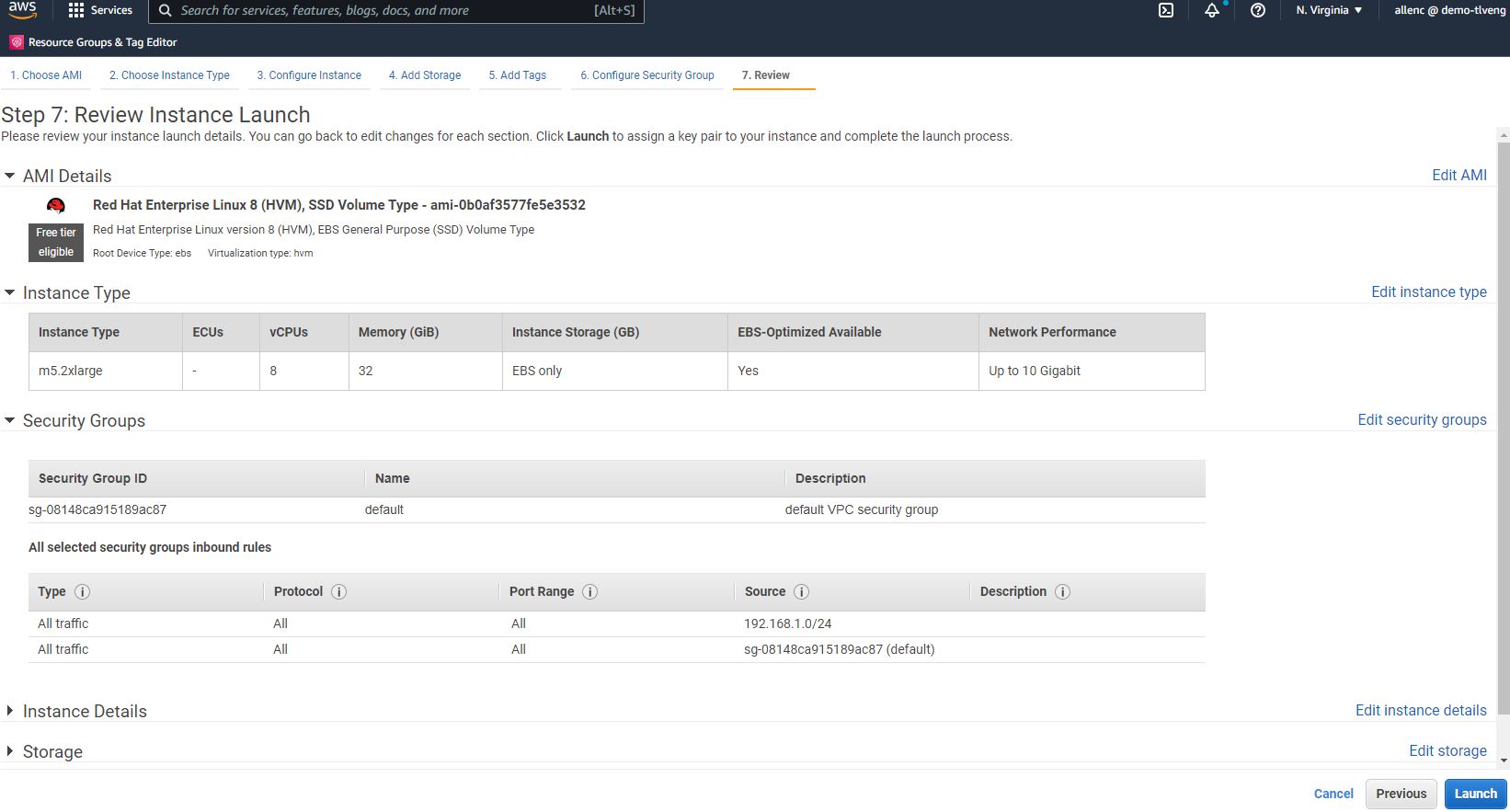
Die folgenden Screenshots zeigen die Bereitstellung einer Linux-Instance vom Typ m5 mit der EC2-Konsole zum Ausführen von Oracle.
-
Klicken Sie im EC2-Dashboard auf die gelbe Schaltfläche „Instanz starten“, um den Bereitstellungsworkflow der EC2-Instanz zu starten.

-
Wählen Sie in Schritt 1 „Red Hat Enterprise Linux 8 (HVM), SSD-Volume-Typ – ami-0b0af3577fe5e3532 (64-Bit x86) / ami-01fc429821bf1f4b4 (64-Bit Arm)“ aus.

-
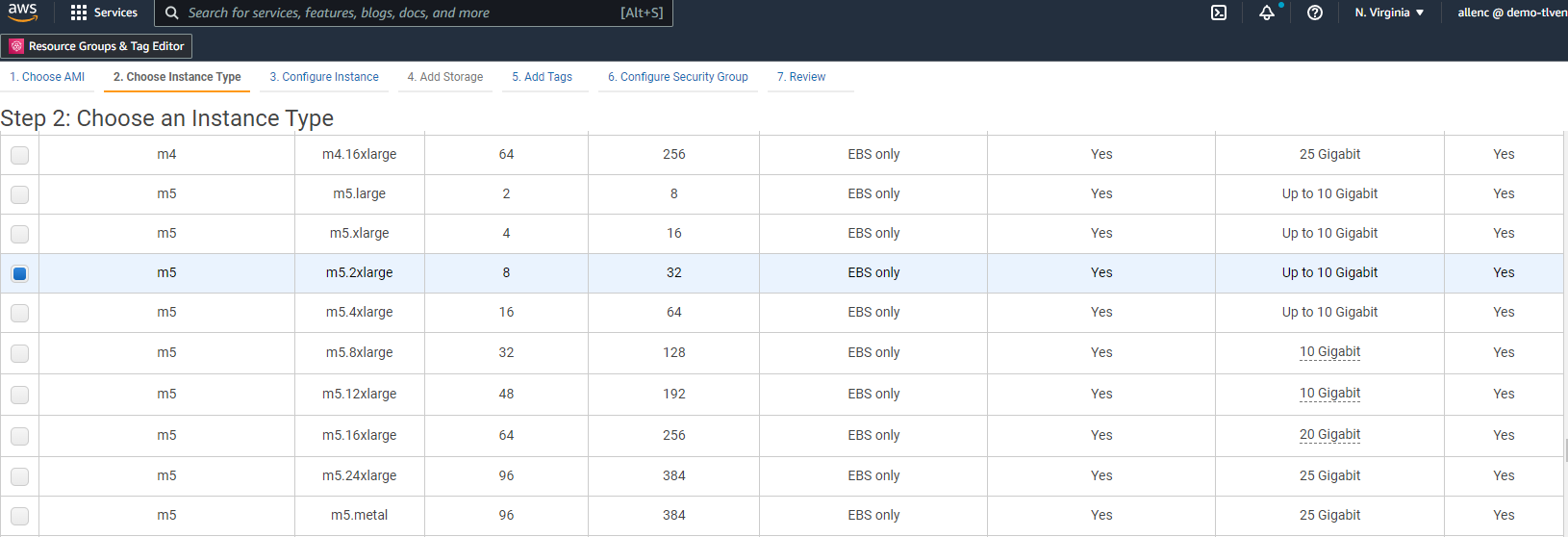
Wählen Sie in Schritt 2 einen m5-Instanztyp mit der entsprechenden CPU- und Speicherzuweisung basierend auf Ihrer Oracle-Datenbank-Workload aus. Klicken Sie auf „Weiter: Instanzdetails konfigurieren“.
-
Wählen Sie in Schritt 3 die VPC und das Subnetz aus, in dem die Instanz platziert werden soll, und aktivieren Sie die öffentliche IP-Zuweisung. Klicken Sie auf „Weiter: Speicher hinzufügen“.

-
Weisen Sie in Schritt 4 genügend Speicherplatz für die Root-Festplatte zu. Möglicherweise benötigen Sie den Speicherplatz, um einen Swap hinzuzufügen. Standardmäßig wird der EC2-Instanz kein Swap-Speicher zugewiesen, was für die Ausführung von Oracle nicht optimal ist.

-
Fügen Sie in Schritt 5 bei Bedarf ein Tag zur Instanzidentifizierung hinzu.
-
Wählen Sie in Schritt 6 eine vorhandene Sicherheitsgruppe aus oder erstellen Sie eine neue mit der gewünschten eingehenden und ausgehenden Richtlinie für die Instanz.

-
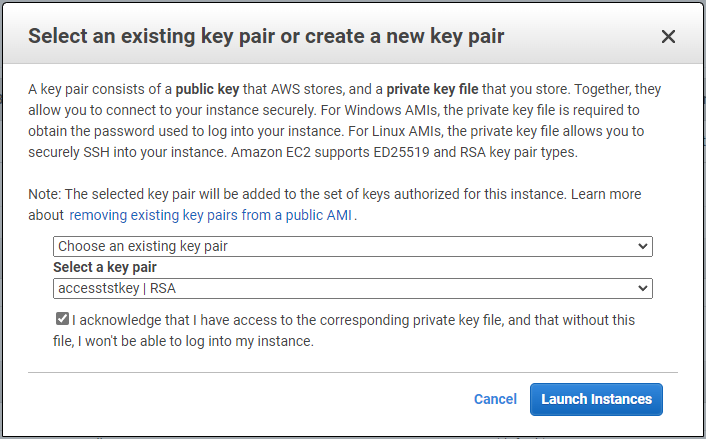
Überprüfen Sie in Schritt 7 die Zusammenfassung der Instanzkonfiguration und klicken Sie auf „Starten“, um die Instanzbereitstellung zu starten. Sie werden aufgefordert, ein Schlüsselpaar zu erstellen oder ein Schlüsselpaar für den Zugriff auf die Instanz auszuwählen.
-
Melden Sie sich mit einem SSH-Schlüsselpaar bei der EC2-Instanz an. Nehmen Sie gegebenenfalls Änderungen an Ihrem Schlüsselnamen und der IP-Adresse der Instanz vor.
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
Sie müssen zwei EC2-Instanzen als primäre und Standby-Oracle-Server in ihrer vorgesehenen Verfügbarkeitszone erstellen, wie im Architekturdiagramm dargestellt.
Bereitstellen von FSx ONTAP -Dateisystemen für Oracle-Datenbankspeicher
Bei der Bereitstellung einer EC2-Instanz wird ein EBS-Stammvolume für das Betriebssystem zugewiesen. FSx ONTAP Dateisysteme bieten Oracle-Datenbankspeichervolumes, einschließlich der Oracle-Binär-, Daten- und Protokollvolumes. Die FSx-Speicher-NFS-Volumes können entweder über die AWS FSx-Konsole oder über die Oracle-Installation bereitgestellt werden. Außerdem gibt es eine Konfigurationsautomatisierung, die die Volumes gemäß der Konfiguration des Benutzers in einer Automatisierungsparameterdatei zuweist.
Erstellen von FSx ONTAP Dateisystemen
Auf diese Dokumentation verwiesen "Verwalten von FSx ONTAP Dateisystemen" zum Erstellen von FSx ONTAP Dateisystemen.
Wichtige Überlegungen:
-
SSD-Speicherkapazität. Mindestens 1024 GiB, maximal 192 TiB.
-
Bereitgestellte SSD-IOPS. Basierend auf den Workload-Anforderungen maximal 80.000 SSD-IOPS pro Dateisystem.
-
Durchsatzkapazität.
-
Legen Sie das Administratorkennwort fsxadmin/vsadmin fest. Erforderlich für die FSx-Konfigurationsautomatisierung.
-
Sicherung und Wartung. Deaktivieren Sie automatische tägliche Sicherungen. Die Sicherung des Datenbankspeichers wird über die SnapCenter -Planung ausgeführt.
-
Rufen Sie die SVM-Verwaltungs-IP-Adresse sowie protokollspezifische Zugriffsadressen von der SVM-Detailseite ab. Erforderlich für die FSx-Konfigurationsautomatisierung.
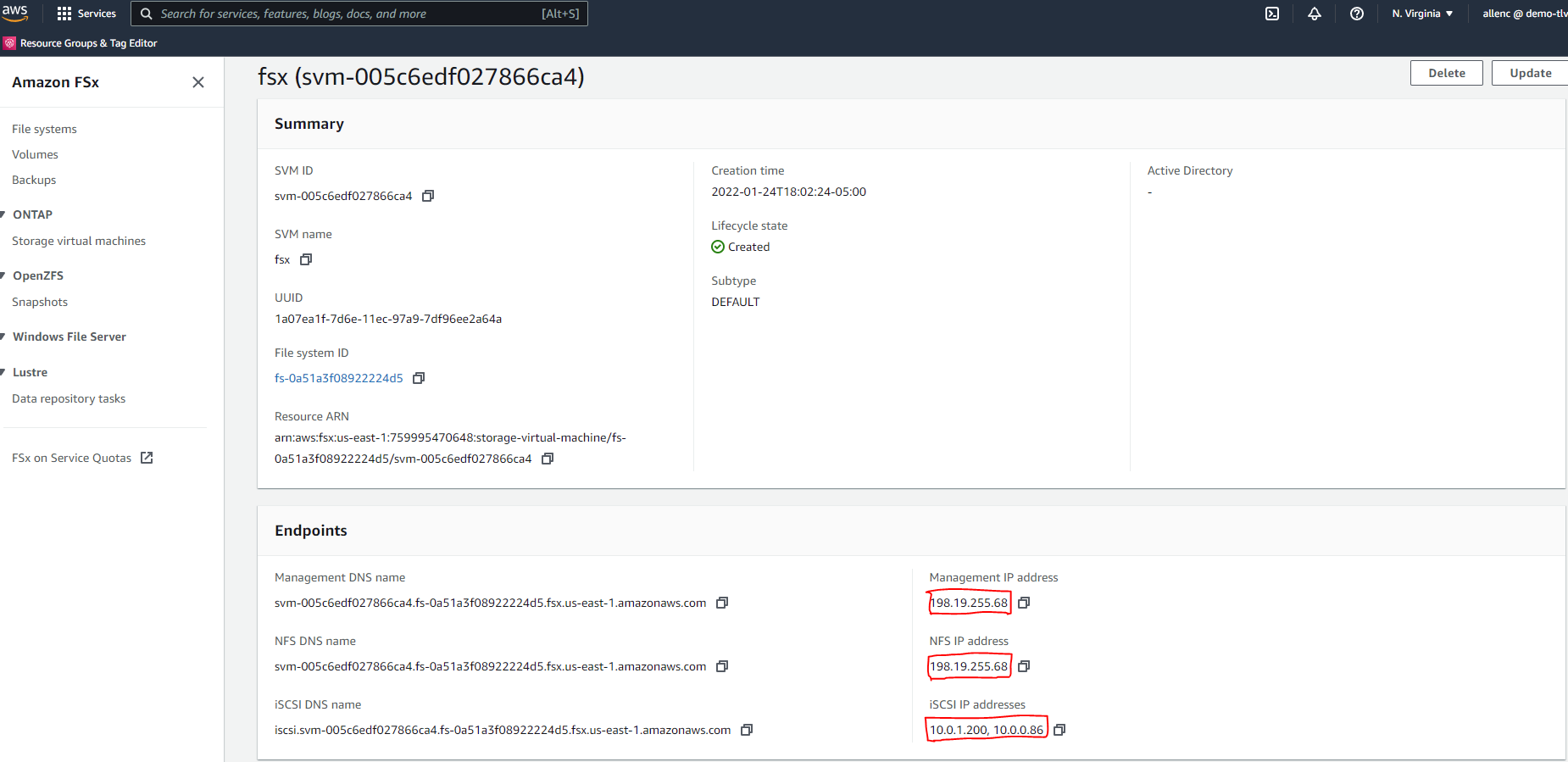
Sehen Sie sich die folgenden Schritt-für-Schritt-Anleitungen zum Einrichten eines primären oder Standby-HA-FSx-Clusters an.
-
Klicken Sie in der FSx-Konsole auf „Dateisystem erstellen“, um den FSx-Bereitstellungsworkflow zu starten.
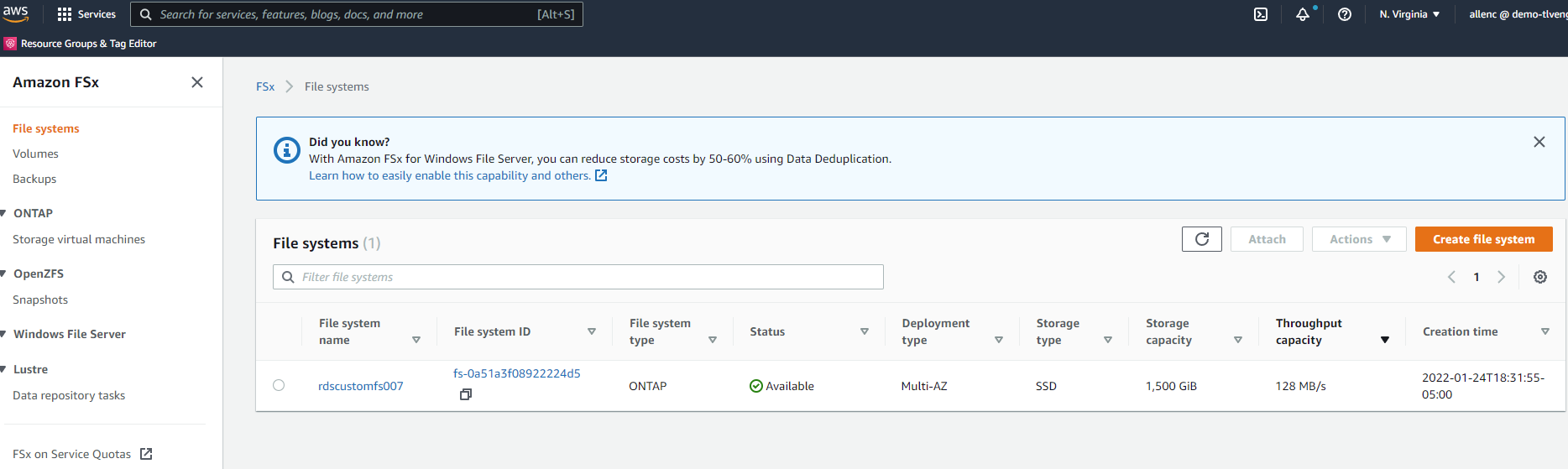
-
Wählen Sie Amazon FSx ONTAP aus. Klicken Sie dann auf Weiter.
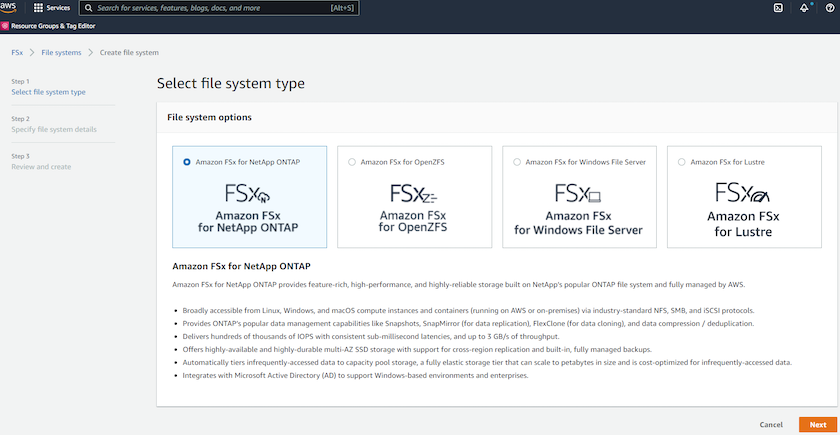
-
Wählen Sie „Standarderstellung“ und geben Sie Ihrem Dateisystem in den Dateisystemdetails den Namen „Multi-AZ HA“. Wählen Sie basierend auf Ihrer Datenbankarbeitslast entweder automatische oder vom Benutzer bereitgestellte IOPS mit bis zu 80.000 SSD-IOPS. Der FSx-Speicher verfügt über bis zu 2 TiB NVMe-Caching im Backend, das noch höhere gemessene IOPS liefern kann.
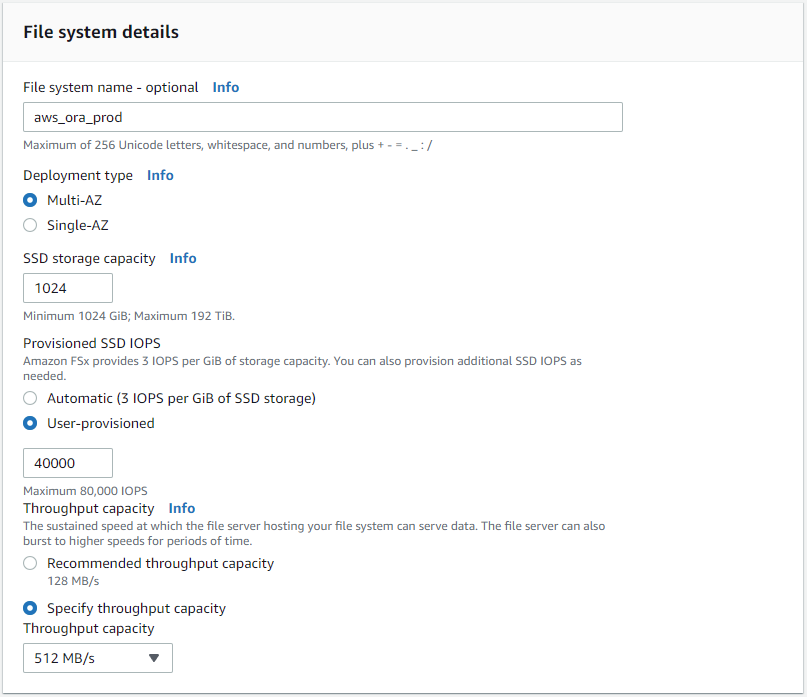
-
Wählen Sie im Abschnitt „Netzwerk und Sicherheit“ die VPC, die Sicherheitsgruppe und die Subnetze aus. Diese sollten vor der FSx-Bereitstellung erstellt werden. Platzieren Sie die FSx-Speicherknoten basierend auf der Rolle des FSx-Clusters (primär oder Standby) in den entsprechenden Zonen.
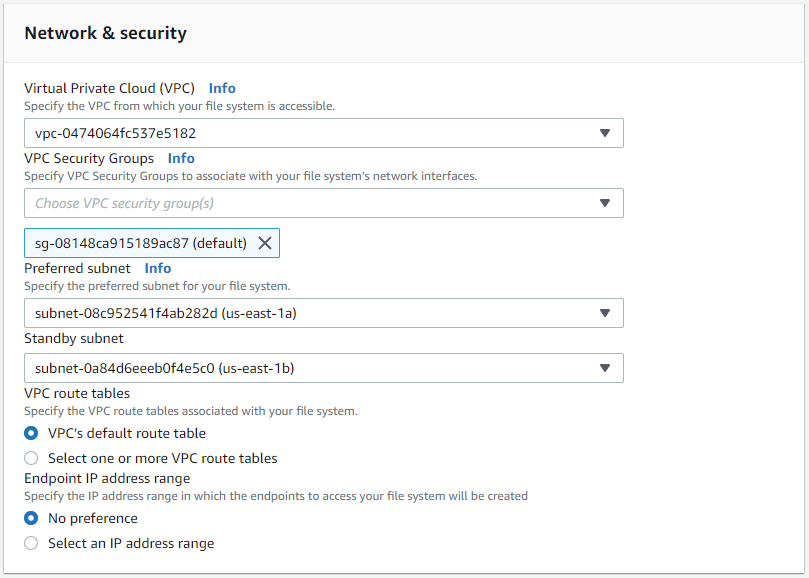
-
Akzeptieren Sie im Abschnitt „Sicherheit und Verschlüsselung“ die Standardeinstellung und geben Sie das fsxadmin-Passwort ein.
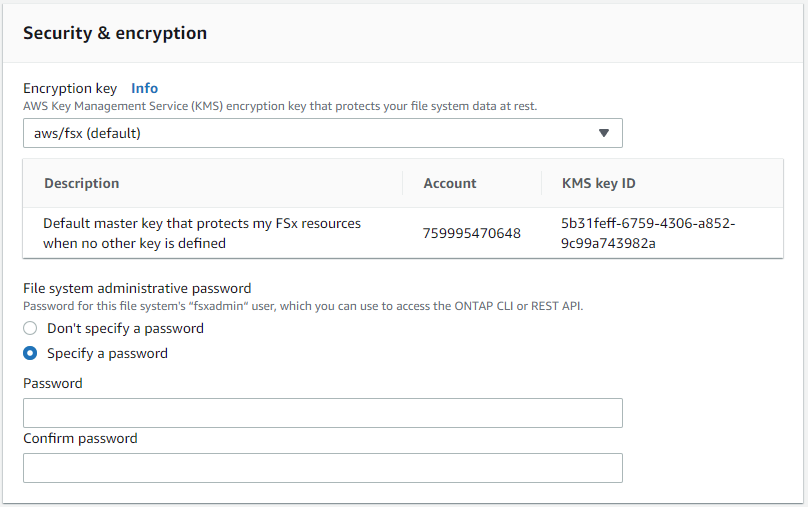
-
Geben Sie den SVM-Namen und das vsadmin-Passwort ein.
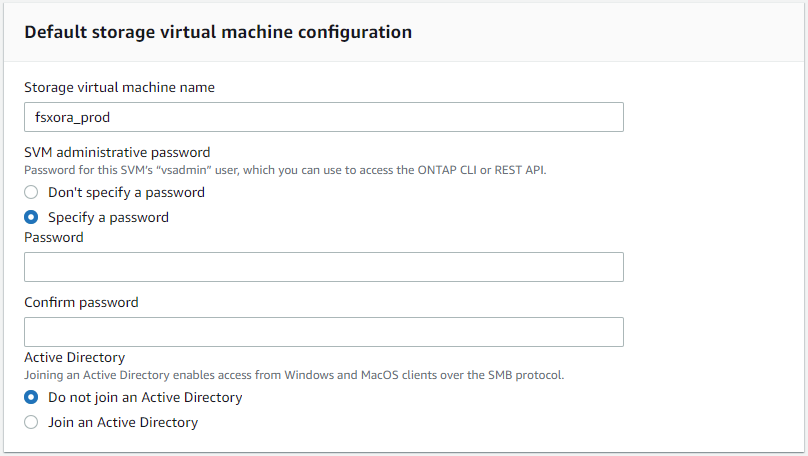
-
Lassen Sie die Volume-Konfiguration leer. Sie müssen an dieser Stelle kein Volume erstellen.
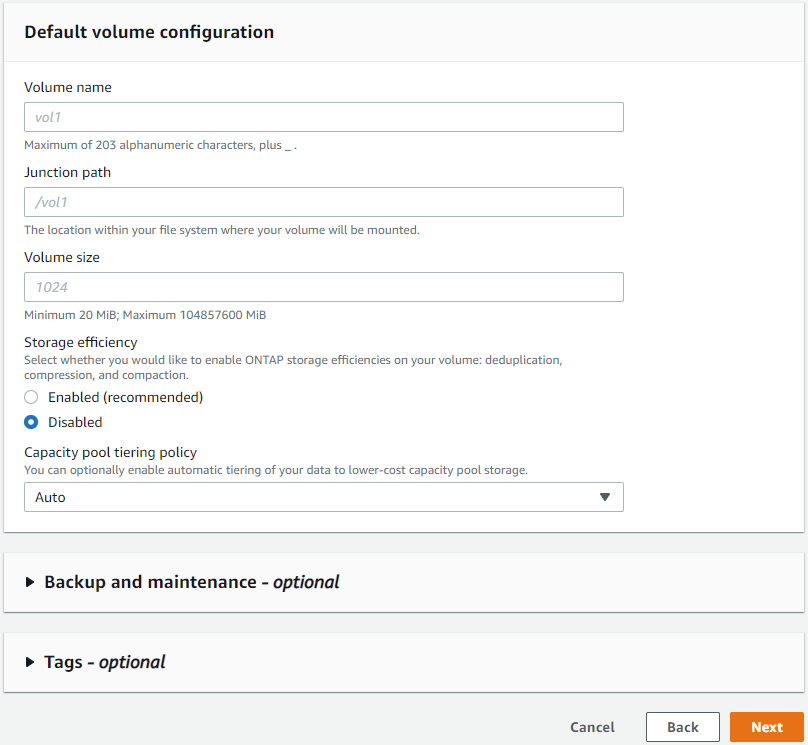
-
Überprüfen Sie die Seite „Zusammenfassung“ und klicken Sie auf „Dateisystem erstellen“, um die Bereitstellung des FSx-Dateisystems abzuschließen.
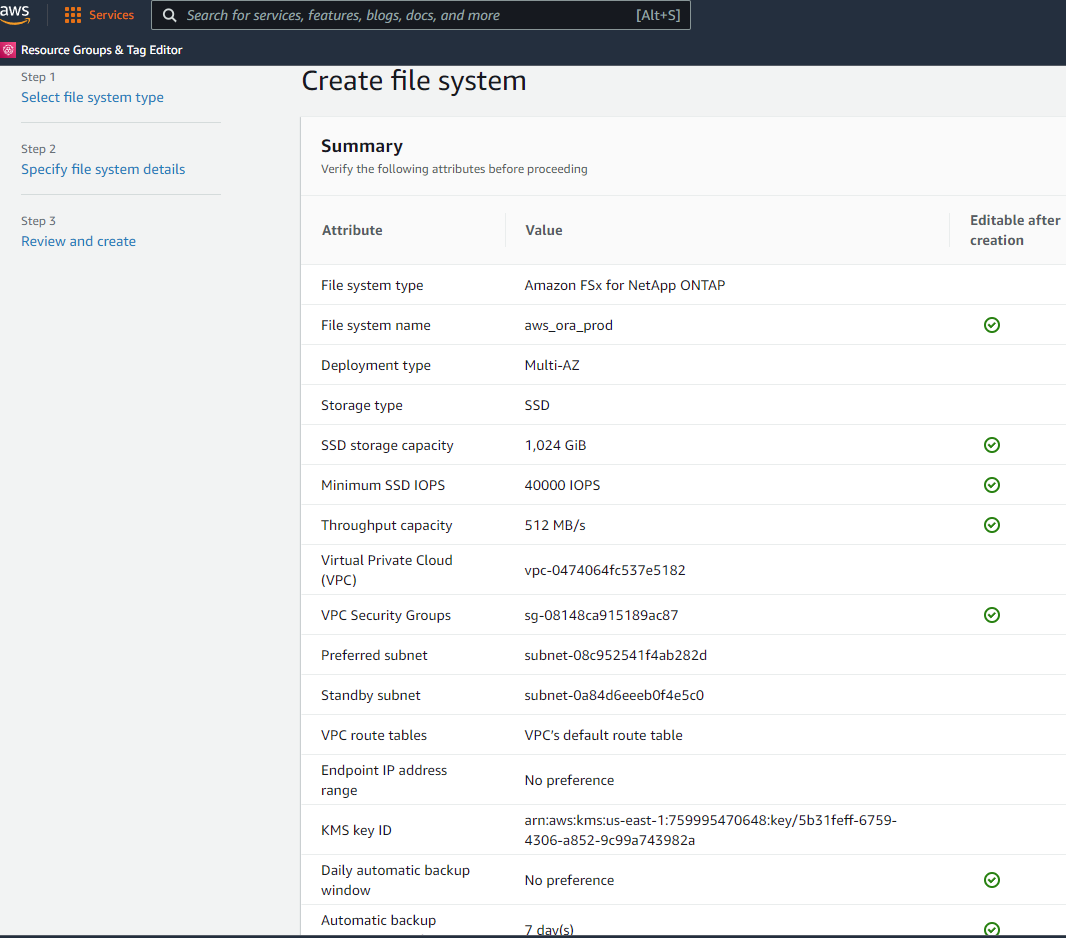
Bereitstellung von Datenbankvolumes für Oracle-Datenbanken
Sehen"Verwalten von FSx ONTAP -Volumes – Erstellen eines Volumes" für Details.
Wichtige Überlegungen:
-
Angemessene Dimensionierung der Datenbankvolumes.
-
Deaktivieren der Kapazitätspool-Tiering-Richtlinie für die Leistungskonfiguration.
-
Aktivieren von Oracle dNFS für NFS-Speichervolumes.
-
Einrichten von Multipath für iSCSI-Speichervolumes.
Erstellen Sie ein Datenbankvolume über die FSx-Konsole
Über die AWS FSx-Konsole können Sie drei Volumes für die Oracle-Datenbankdateispeicherung erstellen: eines für die Oracle-Binärdatei, eines für die Oracle-Daten und eines für das Oracle-Protokoll. Stellen Sie zur ordnungsgemäßen Identifizierung sicher, dass die Volume-Benennung mit dem Oracle-Hostnamen (definiert in der Hosts-Datei im Automatisierungs-Toolkit) übereinstimmt. In diesem Beispiel verwenden wir db1 als EC2-Oracle-Hostnamen anstelle eines typischen IP-adressbasierten Hostnamens für eine EC2-Instanz.
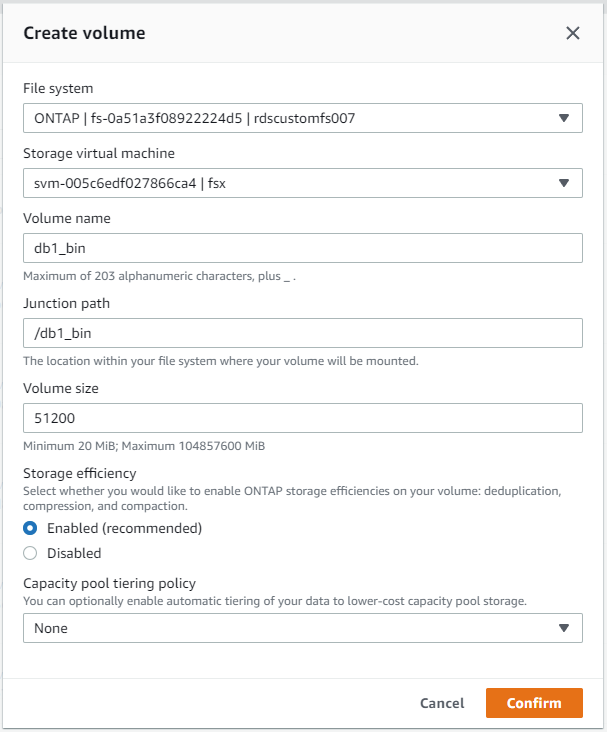
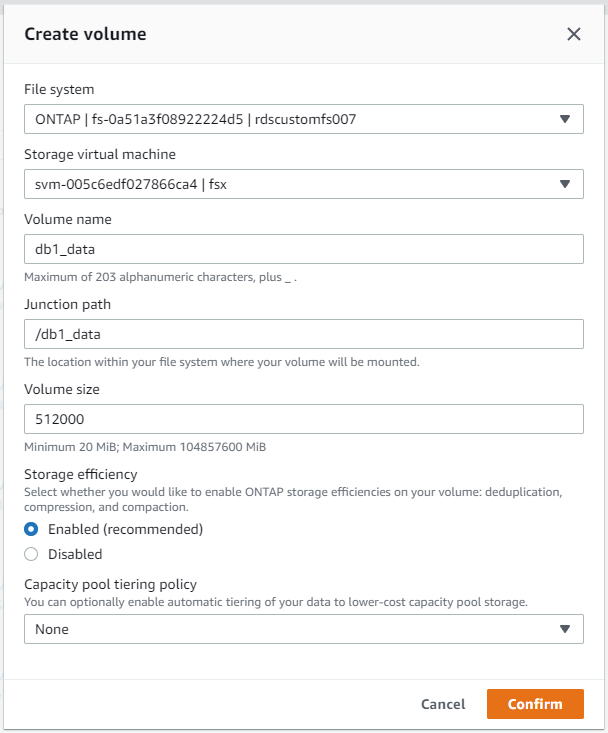
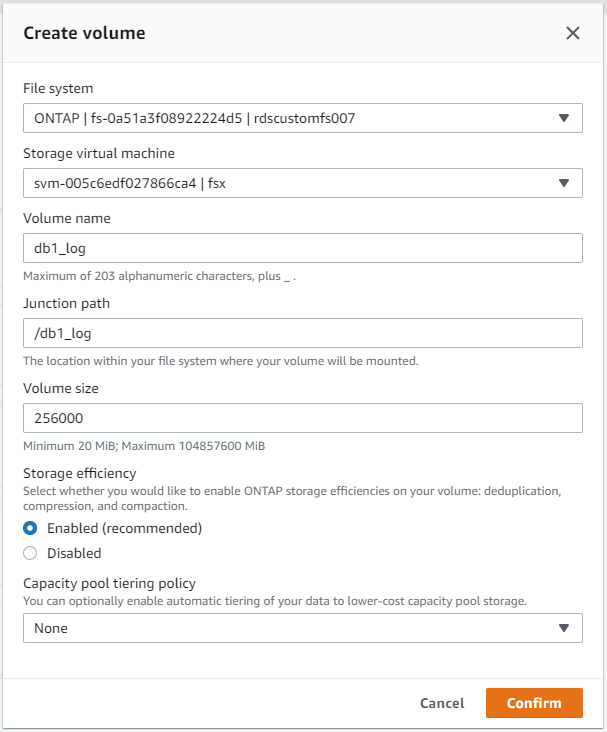

|
Das Erstellen von iSCSI-LUNs wird derzeit von der FSx-Konsole nicht unterstützt. Für die Bereitstellung von iSCSI-LUNs für Oracle können die Volumes und LUNs mithilfe der Automatisierung für ONTAP mit dem NetApp Automation Toolkit erstellt werden. |
Installieren und konfigurieren Sie Oracle auf einer EC2-Instance mit FSx-Datenbankvolumes
Das NetApp Automatisierungsteam stellt ein Automatisierungskit bereit, um die Oracle-Installation und -Konfiguration auf EC2-Instanzen gemäß Best Practices auszuführen. Die aktuelle Version des Automatisierungskits unterstützt Oracle 19c auf NFS mit dem Standard-RU-Patch 19.8. Das Automatisierungskit kann bei Bedarf problemlos für andere RU-Patches angepasst werden.
Bereiten Sie einen Ansible-Controller zum Ausführen der Automatisierung vor
Folgen Sie den Anweisungen im Abschnitt "Erstellen und Verbinden mit einer EC2-Instance zum Hosten einer Oracle-Datenbank ", um eine kleine EC2-Linux-Instanz bereitzustellen, um den Ansible-Controller auszuführen. Anstatt RedHat zu verwenden, sollte Amazon Linux t2.large mit 2vCPU und 8G RAM ausreichen.
Abrufen des NetApp Oracle Deployment Automation Toolkits
Melden Sie sich bei der in Schritt 1 bereitgestellten EC2 Ansible-Controller-Instanz als ec2-user an und führen Sie im Stammverzeichnis von ec2-user den folgenden Befehl aus: git clone Befehl zum Klonen einer Kopie des Automatisierungscodes.
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.gitFühren Sie eine automatisierte Oracle 19c-Bereitstellung mit dem Automatisierungs-Toolkit durch
Sehen Sie sich diese detaillierten Anweisungen an"CLI-Bereitstellung Oracle 19c-Datenbank" um Oracle 19c mit CLI-Automatisierung bereitzustellen. Es gibt eine kleine Änderung in der Befehlssyntax für die Playbook-Ausführung, da Sie für die Host-Zugriffsauthentifizierung ein SSH-Schlüsselpaar anstelle eines Kennworts verwenden. Die folgende Liste ist eine Zusammenfassung auf hoher Ebene:
-
Standardmäßig verwendet eine EC2-Instance ein SSH-Schlüsselpaar zur Zugriffsauthentifizierung. Aus den Stammverzeichnissen der Ansible-Controller-Automatisierung
/home/ec2-user/na_oracle19c_deploy, Und/home/ec2-user/na_rds_fsx_oranfs_config, erstellen Sie eine Kopie des SSH-Schlüsselsaccesststkey.pemfür den im Schritt "Erstellen und Verbinden mit einer EC2-Instance zum Hosten einer Oracle-Datenbank ." -
Melden Sie sich als EC2-Benutzer beim DB-Host der EC2-Instanz an und installieren Sie die Python3-Bibliothek.
sudo yum install python3 -
Erstellen Sie einen 16-GB-Auslagerungsbereich vom Root-Laufwerk. Standardmäßig erstellt eine EC2-Instance keinen Swap-Speicher. Befolgen Sie diese AWS-Dokumentation:"Wie ordne ich mithilfe einer Auslagerungsdatei Speicher zu, der als Auslagerungsspeicher in einer Amazon EC2-Instanz fungiert?" .
-
Zurück zum Ansible-Controller(
cd /home/ec2-user/na_rds_fsx_oranfs_config), und führen Sie das Preclone-Playbook mit den entsprechenden Anforderungen aus undlinux_configTags.ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
Wechseln Sie zum
/home/ec2-user/na_oracle19c_deploy-masterVerzeichnis, lesen Sie die README-Datei und füllen Sie die globalevars.ymlDatei mit den relevanten globalen Parametern. -
Füllen Sie die
host_name.ymlDatei mit den entsprechenden Parametern imhost_varsVerzeichnis. -
Führen Sie das Playbook für Linux aus und drücken Sie die Eingabetaste, wenn Sie zur Eingabe des vsadmin-Passworts aufgefordert werden.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Führen Sie das Playbook für Oracle aus und drücken Sie die Eingabetaste, wenn Sie zur Eingabe des vsadmin-Passworts aufgefordert werden.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
Ändern Sie bei Bedarf das Berechtigungsbit in der SSH-Schlüsseldatei auf 400. Ändern des Oracle-Hosts(ansible_host im host_vars Datei) IP-Adresse an die öffentliche Adresse Ihrer EC2-Instanz.
Einrichten von SnapMirror zwischen primärem und Standby-FSx-HA-Cluster
Für hohe Verfügbarkeit und Notfallwiederherstellung können Sie die SnapMirror Replikation zwischen dem primären und dem Standby-FSx-Speichercluster einrichten. Im Gegensatz zu anderen Cloud-Speicherdiensten ermöglicht FSx einem Benutzer, die Speicherreplikation mit der gewünschten Frequenz und dem gewünschten Replikationsdurchsatz zu steuern und zu verwalten. Darüber hinaus können Benutzer HA/DR testen, ohne dass dies Auswirkungen auf die Verfügbarkeit hat.
Die folgenden Schritte zeigen, wie Sie die Replikation zwischen einem primären und einem Standby-FSx-Speichercluster einrichten.
-
Richten Sie das Peering des primären und Standby-Clusters ein. Melden Sie sich als Benutzer fsxadmin beim primären Cluster an und führen Sie den folgenden Befehl aus. Dieser wechselseitige Erstellungsprozess führt den Erstellungsbefehl sowohl auf dem primären Cluster als auch auf dem Standby-Cluster aus. Ersetzen
standby_cluster_namedurch den passenden Namen für Ihre Umgebung.cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
Richten Sie vServer-Peering zwischen dem primären und dem Standby-Cluster ein. Melden Sie sich als vsadmin-Benutzer beim primären Cluster an und führen Sie den folgenden Befehl aus. Ersetzen
primary_vserver_name,standby_vserver_name,standby_cluster_namemit den entsprechenden Namen für Ihre Umgebung.vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
Überprüfen Sie, ob die Cluster- und VServer-Peerings richtig eingerichtet sind.
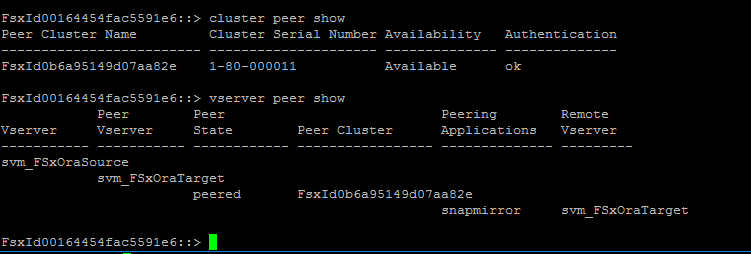
-
Erstellen Sie Ziel-NFS-Volumes im Standby-FSx-Cluster für jedes Quell-Volume im primären FSx-Cluster. Ersetzen Sie den Datenträgernamen entsprechend Ihrer Umgebung.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
Sie können auch iSCSI-Volumes und LUNs für die Oracle-Binärdatei, Oracle-Daten und das Oracle-Protokoll erstellen, wenn das iSCSI-Protokoll für den Datenzugriff verwendet wird. Lassen Sie in den Volumes etwa 10 % freien Speicherplatz für Snapshots.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxvol erstellen -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -unix-permissions ---rwxr-xr-x -type RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
Erstellen Sie für iSCSI-LUNs eine Zuordnung für den Oracle-Hostinitiator für jede LUN, wobei Sie die binäre LUN als Beispiel verwenden. Ersetzen Sie die Igroup durch einen passenden Namen für Ihre Umgebung und erhöhen Sie die LUN-ID für jede zusätzliche LUN.
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
Erstellen Sie eine SnapMirror -Beziehung zwischen den primären und Standby-Datenbankvolumes. Ersetzen Sie den entsprechenden SVM-Namen für Ihre Umgebung.
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
Dieses SnapMirror Setup kann mit einem NetApp Automation Toolkit für NFS-Datenbankvolumes automatisiert werden. Das Toolkit steht auf der öffentlichen GitHub-Site von NetApp zum Download bereit.
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLesen Sie die README-Anweisungen sorgfältig durch, bevor Sie mit der Einrichtung und dem Failover-Test beginnen.
|
|
Das Replizieren der Oracle-Binärdatei vom primären auf einen Standby-Cluster kann Auswirkungen auf die Oracle-Lizenz haben. Wenden Sie sich zur Klärung an Ihren Oracle-Lizenzvertreter. Die Alternative besteht darin, Oracle zum Zeitpunkt der Wiederherstellung und des Failovers zu installieren und zu konfigurieren. |
SnapCenter -Bereitstellung
SnapCenter -Installation
Folgen"Installieren des SnapCenter -Servers" um den SnapCenter -Server zu installieren. In dieser Dokumentation wird die Installation eines eigenständigen SnapCenter -Servers beschrieben. Eine SaaS-Version von SnapCenter befindet sich im Beta-Test und könnte in Kürze verfügbar sein. Erkundigen Sie sich bei Bedarf bei Ihrem NetApp -Vertreter nach der Verfügbarkeit.
Konfigurieren Sie das SnapCenter -Plugin für den EC2 Oracle-Host
-
Melden Sie sich nach der automatisierten SnapCenter -Installation als Administratorbenutzer bei SnapCenter für den Windows-Host an, auf dem der SnapCenter -Server installiert ist.

-
Klicken Sie im Menü auf der linken Seite auf „Einstellungen“ und dann auf „Anmeldeinformationen“ und „Neu“, um EC2-Benutzeranmeldeinformationen für die Installation des SnapCenter -Plugins hinzuzufügen.
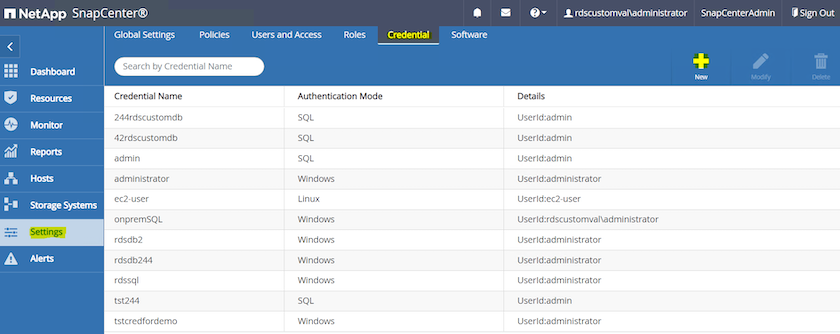
-
Setzen Sie das EC2-Benutzerkennwort zurück und aktivieren Sie die Kennwort-SSH-Authentifizierung, indem Sie das
/etc/ssh/sshd_configDatei auf dem EC2-Instance-Host. -
Stellen Sie sicher, dass das Kontrollkästchen „Sudo-Berechtigungen verwenden“ aktiviert ist. Sie haben im vorherigen Schritt einfach das EC2-Benutzerkennwort zurückgesetzt.
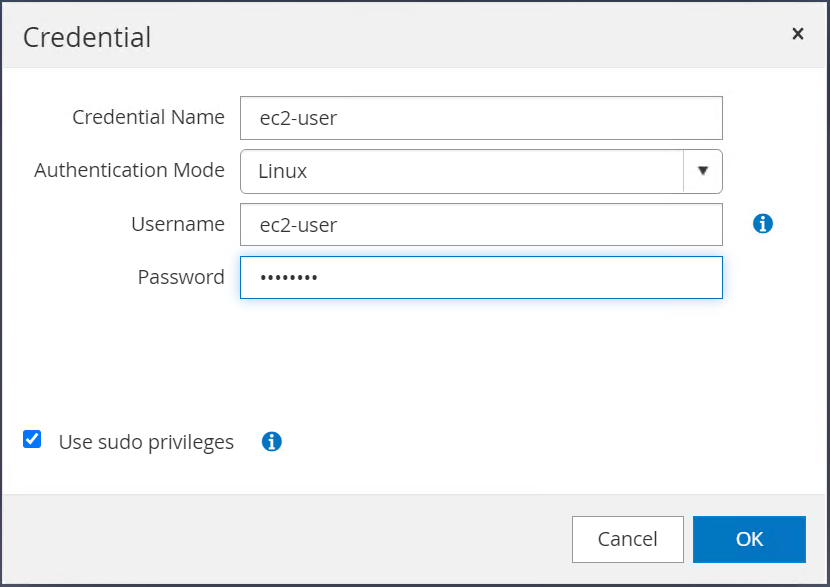
-
Fügen Sie den SnapCenter -Servernamen und die IP-Adresse zur Hostdatei der EC2-Instanz zur Namensauflösung hinzu.
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
Fügen Sie auf dem Windows-Host des SnapCenter -Servers die IP-Adresse des EC2-Instance-Hosts zur Windows-Hostdatei hinzu
C:\Windows\System32\drivers\etc\hosts.10.0.0.151 ip-10-0-0-151.ec2.internal
-
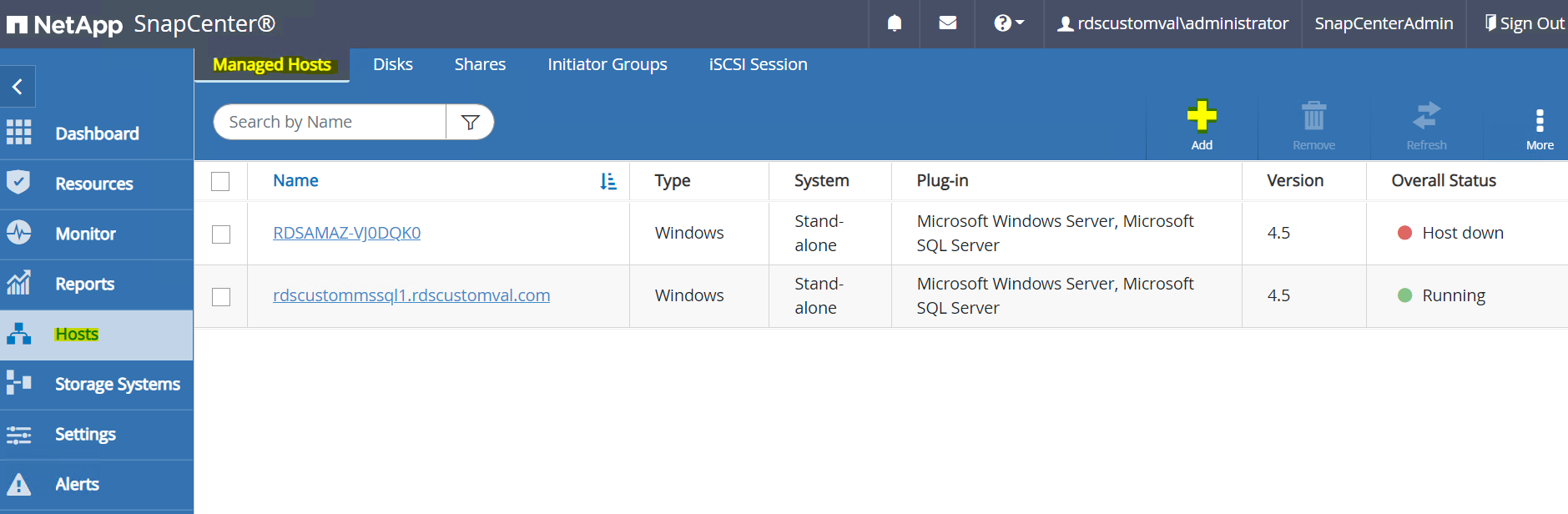
Wählen Sie im Menü auf der linken Seite „Hosts > Managed Hosts“ und klicken Sie dann auf „Hinzufügen“, um den EC2-Instance-Host zu SnapCenter hinzuzufügen.
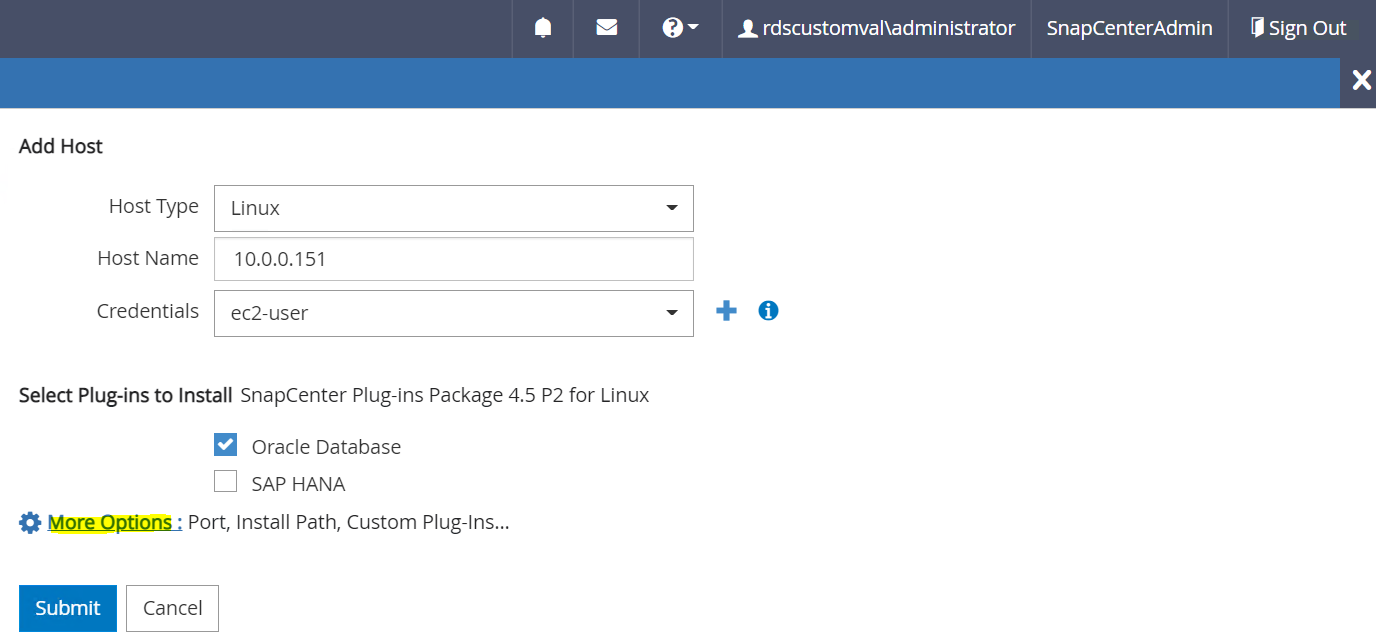
Aktivieren Sie die Oracle-Datenbank und klicken Sie vor dem Absenden auf „Weitere Optionen“.
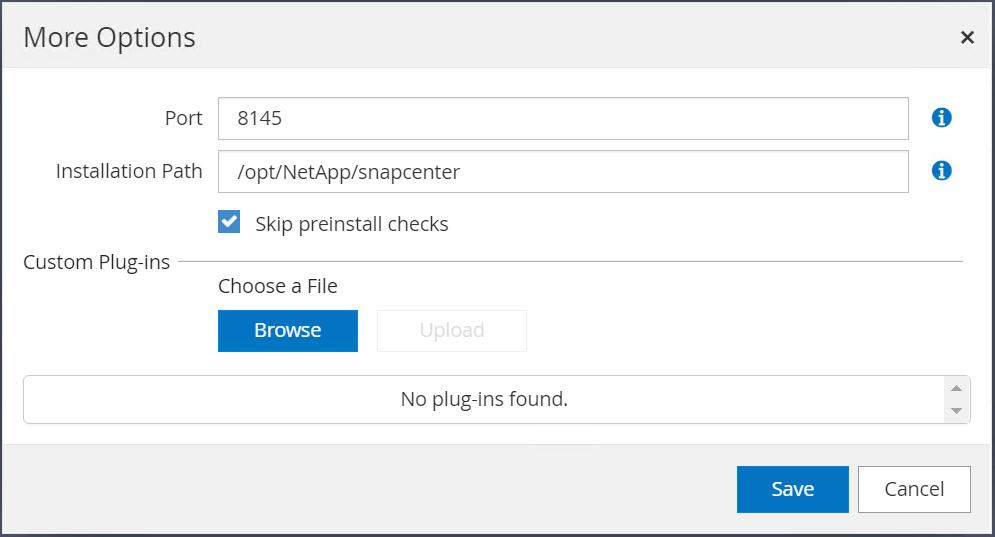
Aktivieren Sie „Vorinstallationsprüfungen überspringen“. Bestätigen Sie das Überspringen der Vorinstallationsprüfungen und klicken Sie dann auf „Nach dem Speichern senden“.
Sie werden aufgefordert, den Fingerabdruck zu bestätigen. Klicken Sie dann auf „Bestätigen und senden“.
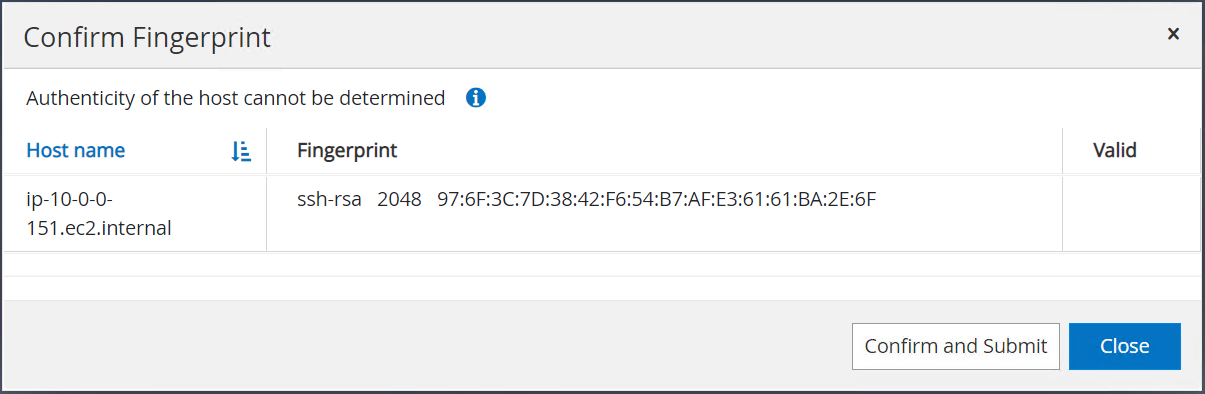
Nach erfolgreicher Plugin-Konfiguration wird der Gesamtstatus des verwalteten Hosts als „Wird ausgeführt“ angezeigt.

Konfigurieren der Sicherungsrichtlinie für die Oracle-Datenbank
Siehe diesen Abschnitt"Richten Sie die Datenbanksicherungsrichtlinie in SnapCenter ein" Einzelheiten zum Konfigurieren der Oracle-Datenbank-Sicherungsrichtlinie.
Im Allgemeinen müssen Sie eine Richtlinie für die vollständige Snapshot-Sicherung der Oracle-Datenbank und eine Richtlinie für die Snapshot-Sicherung nur des Oracle-Archivprotokolls erstellen.
|
|
Sie können die Bereinigung des Oracle-Archivprotokolls in der Sicherungsrichtlinie aktivieren, um den Protokollarchivspeicherplatz zu steuern. Aktivieren Sie „ SnapMirror nach dem Erstellen einer lokalen Snapshot-Kopie aktualisieren“ unter „Sekundäre Replikationsoption auswählen“, da Sie für HA oder DR an einen Standby-Speicherort replizieren müssen. |
Konfigurieren der Sicherung und Planung von Oracle-Datenbanken
Die Datenbanksicherung in SnapCenter ist benutzerkonfigurierbar und kann entweder einzeln oder als Gruppe in einer Ressourcengruppe eingerichtet werden. Das Sicherungsintervall hängt von den RTO- und RPO-Zielen ab. NetApp empfiehlt, alle paar Stunden eine vollständige Datenbanksicherung durchzuführen und die Protokollsicherung für eine schnelle Wiederherstellung häufiger, beispielsweise alle 10–15 Minuten, zu archivieren.
Weitere Informationen finden Sie im Oracle-Abschnitt von"Implementieren Sie eine Sicherungsrichtlinie zum Schutz der Datenbank" für eine detaillierte Schritt-für-Schritt-Anleitung zur Implementierung der im Abschnitt erstellten SicherungsrichtlinieKonfigurieren der Sicherungsrichtlinie für die Oracle-Datenbank und für die Planung von Sicherungsaufträgen.
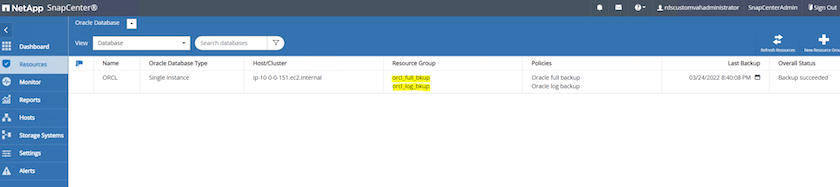
Das folgende Bild zeigt ein Beispiel für die Ressourcengruppen, die zum Sichern einer Oracle-Datenbank eingerichtet werden.