

Konfigurieren Sie die MetroCluster FC-Software in ONTAP
 Änderungen vorschlagen
Änderungen vorschlagen
Sie müssen jeden Knoten in der MetroCluster FC-Konfiguration in ONTAP einrichten, einschließlich der Konfigurationen auf Knotenebene und der Konfiguration der Knoten zu zwei Standorten. Sie müssen außerdem die MetroCluster-Beziehung zwischen den beiden Standorten implementieren.
Sammeln der erforderlichen Informationen
Sie müssen die erforderlichen IP-Adressen für die Controller-Module erfassen, bevor Sie mit dem Konfigurationsprozess beginnen.
Arbeitsblatt für IP-Netzwerkinformationen für Standort A
Vor dem Konfigurieren des Systems müssen Sie IP-Adressen und andere Netzwerkinformationen für den ersten MetroCluster-Standort (Standort A) vom Netzwerkadministrator beziehen.
Switch-Informationen Standort A (Switch-Cluster)
Wenn Sie das System verkabeln, benötigen Sie für jeden Cluster-Switch einen Host-Namen und eine Management-IP-Adresse. Diese Informationen sind nicht erforderlich, wenn Sie ein 2-Node-Cluster ohne Switches oder eine MetroCluster Konfiguration mit zwei Nodes (ein Node an jedem Standort) verwenden.
Cluster-Switch |
Host-Name |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
Verbindung 1 |
||||
Verbindung 2 |
||||
Management 1 |
||||
Management 2 |
Informationen zur Cluster-Erstellung von Standort A
Wenn Sie zum ersten Mal das Cluster erstellen, benötigen Sie die folgenden Informationen:
Informationstyp |
Ihre Werte |
Cluster-Name Beispiel für dieses Verfahren: Site_A |
|
DNS-Domäne |
|
DNS-Name-Server |
|
Standort |
|
Administratorpasswort |
Node-Informationen zu Standort A
Für jeden Node im Cluster benötigen Sie eine Management-IP-Adresse, eine Netzwerkmaske und ein Standard-Gateway.
Knoten |
Port |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
Knoten 1 Beispiel für dieses Verfahren: Controller_A_1 |
||||
Knoten 2 Nicht erforderlich, wenn eine MetroCluster Konfiguration mit zwei Nodes verwendet wird (ein Node an jedem Standort). Beispiel für dieses Verfahren: Controller_A_2 |
Standort A LIFs und Ports für Cluster-Peering
Sie benötigen für jeden Node im Cluster die IP-Adressen zweier Intercluster-LIFs, einschließlich einer Netzwerkmaske und eines Standard-Gateway. Die Intercluster-LIFs werden verwendet, um die Cluster miteinander zu begleichen.
Knoten |
Port |
IP-Adresse von Intercluster LIF |
Netzwerkmaske |
Standard-Gateway |
Knoten 1 IC LIF 1 |
||||
Knoten 1 IC LIF 2 |
||||
Knoten 2 IC LIF 1 Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) |
||||
Node 2 IC LIF 2 Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) |
Informationen zum Zeitserver an Standort A
Sie müssen die Zeit synchronisieren, die einen oder mehrere NTP-Zeitserver erfordert.
Knoten |
Host-Name |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
NTP-Server 1 |
||||
NTP-Server 2 |
Standort A nbsp; AutoSupport-Informationen
Sie müssen AutoSupport für jeden Node konfigurieren. Dazu sind folgende Informationen erforderlich:
Informationstyp |
Ihre Werte |
|
Von E-Mail-Adresse |
Mail-Hosts |
|
IP-Adressen oder Namen |
Transportprotokoll |
|
HTTP, HTTPS ODER SMTP |
Proxy-Server |
|
E-Mail-Adressen oder Verteilerlisten des Empfängers |
Mitteilungen in voller Länge |
|
Präzise Nachrichten |
||
Standort A nbsp; SP-Informationen
Sie müssen den Zugriff auf den Service-Prozessor (SP) jedes Node für die Fehlerbehebung und Wartung aktivieren. Hierfür sind die folgenden Netzwerkinformationen für jeden Node erforderlich:
Knoten |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
Knoten 1 |
|||
Knoten 2 Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) |
Arbeitsblatt für IP-Netzwerkinformationen für Standort B
Vor dem Konfigurieren des Systems müssen Sie IP-Adressen und andere Netzwerkinformationen für den zweiten MetroCluster-Standort (Standort B) vom Netzwerkadministrator beziehen.
Switch-Informationen an Standort B (Switch-Cluster)
Wenn Sie das System verkabeln, benötigen Sie für jeden Cluster-Switch einen Host-Namen und eine Management-IP-Adresse. Diese Informationen sind nicht erforderlich, wenn Sie ein 2-Node-Cluster ohne Switches oder eine MetroCluster Konfiguration mit zwei Nodes (ein Node an jedem Standort) verwenden.
Cluster-Switch |
Host-Name |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
Verbindung 1 |
||||
Verbindung 2 |
||||
Management 1 |
||||
Management 2 |
Informationen zur Cluster-Erstellung von Standort B
Wenn Sie zum ersten Mal das Cluster erstellen, benötigen Sie die folgenden Informationen:
Informationstyp |
Ihre Werte |
Cluster-Name Beispiel, das in diesem Verfahren verwendet wird: site_B |
|
DNS-Domäne |
|
DNS-Name-Server |
|
Standort |
|
Administratorpasswort |
Node-Informationen zu Standort B
Für jeden Node im Cluster benötigen Sie eine Management-IP-Adresse, eine Netzwerkmaske und ein Standard-Gateway.
Knoten |
Port |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
Knoten 1 Beispiel, das in diesem Verfahren verwendet wird: controller_B_1 |
||||
Knoten 2 Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) Beispiel, das in diesem Verfahren verwendet wird: controller_B_2 |
Standort B LIFs und Ports für Cluster-Peering
Sie benötigen für jeden Node im Cluster die IP-Adressen zweier Intercluster-LIFs, einschließlich einer Netzwerkmaske und eines Standard-Gateway. Die Intercluster-LIFs werden verwendet, um die Cluster miteinander zu begleichen.
Knoten |
Port |
IP-Adresse von Intercluster LIF |
Netzwerkmaske |
Standard-Gateway |
Knoten 1 IC LIF 1 |
||||
Knoten 1 IC LIF 2 |
||||
Knoten 2 IC LIF 1 Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) |
||||
Node 2 IC LIF 2 Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) |
Standort B Informationen zum Zeitserver
Sie müssen die Zeit synchronisieren, die einen oder mehrere NTP-Zeitserver erfordert.
Knoten |
Host-Name |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
NTP-Server 1 |
||||
NTP-Server 2 |
Standort B nbsp;AutoSupport Informationen
Sie müssen AutoSupport für jeden Node konfigurieren. Dazu sind folgende Informationen erforderlich:
Informationstyp |
Ihre Werte |
|
Von E-Mail-Adresse |
||
Mail-Hosts |
IP-Adressen oder Namen |
|
Transportprotokoll |
HTTP, HTTPS ODER SMTP |
|
Proxy-Server |
E-Mail-Adressen oder Verteilerlisten des Empfängers |
|
Mitteilungen in voller Länge |
Präzise Nachrichten |
|
Partner |
||
Standort B nbsp;SP-Informationen
Sie müssen den Zugriff auf den Service-Prozessor (SP) jedes Node für die Fehlerbehebung und Wartung aktivieren. Hierfür sind die folgenden Netzwerkinformationen für jeden Node erforderlich:
Knoten |
IP-Adresse |
Netzwerkmaske |
Standard-Gateway |
Knoten 1 (Controller_B_1) |
|||
Knoten 2 (Controller_B_2) Nicht erforderlich für MetroCluster Konfigurationen mit zwei Nodes (ein Node an jedem Standort) |
Ähnlichkeiten und Unterschiede zwischen Standard-Cluster und MetroCluster Konfigurationen
Die Konfiguration der Nodes in jedem Cluster in einer MetroCluster-Konfiguration ist ähnlich wie bei den Nodes in einem Standard-Cluster.
Die MetroCluster-Konfiguration basiert auf zwei Standard-Clustern. Physisch muss die Konfiguration symmetrisch sein, wobei jeder Node über dieselbe Hardware-Konfiguration verfügt. Außerdem müssen alle MetroCluster Komponenten verkabelt und konfiguriert werden. Die grundlegende Softwarekonfiguration für Nodes in einer MetroCluster-Konfiguration ist jedoch dieselbe wie für Nodes in einem Standard-Cluster.
Konfigurationsschritt |
Standardmäßige Cluster-Konfiguration |
MetroCluster-Konfiguration |
Konfiguration von Management-, Cluster- und Daten-LIFs auf jedem Node |
Gleiches gilt für beide Cluster-Typen |
|
Konfigurieren Sie das Root-Aggregat. |
Gleiches gilt für beide Cluster-Typen |
|
Konfigurieren Sie Nodes im Cluster als HA-Paare |
Gleiches gilt für beide Cluster-Typen |
|
Richten Sie das Cluster auf einem Node im Cluster ein. |
Gleiches gilt für beide Cluster-Typen |
|
Fügen Sie den anderen Node zum Cluster hinzu. |
Gleiches gilt für beide Cluster-Typen |
|
Erstellen Sie ein gespiegeltes Root-Aggregat. |
Optional |
Erforderlich |
Peer-to-Peer-Cluster |
Optional |
Erforderlich |
Aktivieren der MetroCluster-Konfiguration |
Nicht zutreffend |
Erforderlich |
Überprüfen und Konfigurieren des HA-Status von Komponenten im Wartungsmodus
Wenn Sie ein Speichersystem in einer MetroCluster FC-Konfiguration konfigurieren, müssen Sie sicherstellen, dass der Hochverfügbarkeitsstatus (HA) des Controller-Moduls und der Gehäusekomponenten mcc oder mcc-2n ist, damit diese Komponenten ordnungsgemäß booten. Obwohl dieser Wert auf werkseitig empfangene Systeme vorkonfiguriert sein sollte, sollten Sie die Einstellung dennoch überprüfen, bevor Sie fortfahren.

|
Wenn der HA-Status des Controller-Moduls und des Chassis falsch ist, können Sie die MetroCluster nicht konfigurieren, ohne den Node neu zu initialisieren. Sie müssen die Einstellung mit diesem Verfahren korrigieren und dann das System mit einem der folgenden Verfahren initialisieren:
|
Vergewissern Sie sich, dass sich das System im Wartungsmodus befindet.
-
Zeigen Sie im Wartungsmodus den HA-Status des Controller-Moduls und des Chassis an:
ha-config showDer richtige HA-Status hängt von Ihrer MetroCluster-Konfiguration ab.
MetroCluster-Konfigurationstyp
HA-Status für alle Komponenten…
MetroCluster FC-Konfiguration mit acht oder vier Nodes
mcc
MetroCluster FC-Konfiguration mit zwei Nodes
mcc-2n
MetroCluster IP-Konfiguration mit acht oder vier Nodes
Mccip
-
Wenn der angezeigte Systemstatus des Controllers nicht korrekt ist, legen Sie den korrekten HA-Status für Ihre Konfiguration auf dem Controller-Modul fest:
MetroCluster-Konfigurationstyp
Befehl
MetroCluster FC-Konfiguration mit acht oder vier Nodes
ha-config modify controller mccMetroCluster FC-Konfiguration mit zwei Nodes
ha-config modify controller mcc-2nMetroCluster IP-Konfiguration mit acht oder vier Nodes
ha-config modify controller mccip -
Wenn der angezeigte Systemstatus des Chassis nicht korrekt ist, legen Sie den korrekten HA-Status für Ihre Konfiguration auf dem Chassis fest:
MetroCluster-Konfigurationstyp
Befehl
MetroCluster FC-Konfiguration mit acht oder vier Nodes
ha-config modify chassis mccMetroCluster FC-Konfiguration mit zwei Nodes
ha-config modify chassis mcc-2nMetroCluster IP-Konfiguration mit acht oder vier Nodes
ha-config modify chassis mccip -
Booten des Node zu ONTAP:
boot_ontap -
Wiederholen Sie dieses gesamte Verfahren, um den HA-Status auf jedem Node in der MetroCluster-Konfiguration zu überprüfen.
Wiederherstellung der Systemstandards und Konfiguration des HBA-Typs auf einem Controller-Modul
Um eine erfolgreiche MetroCluster-Installation zu gewährleisten, setzen Sie die Standardeinstellungen auf den Controller-Modulen zurück und stellen sie wieder her.
Dies ist nur für Stretch-Konfigurationen mit FC-to-SAS-Bridges erforderlich.
-
Geben Sie an der LOADER-Eingabeaufforderung die Umgebungsvariablen auf ihre Standardeinstellung zurück:
set-defaults -
Starten Sie den Knoten im Wartungsmodus, und konfigurieren Sie dann die Einstellungen für alle HBAs im System:
-
Booten in den Wartungsmodus:
boot_ontap maint -
Überprüfen Sie die aktuellen Einstellungen der Ports:
ucadmin show -
Aktualisieren Sie die Porteinstellungen nach Bedarf.
Wenn Sie über diese Art von HBA und den gewünschten Modus verfügen…
Befehl
CNA FC
ucadmin modify -m fc -t initiator adapter_nameCNA-Ethernet
ucadmin modify -mode cna adapter_nameFC-Ziel
fcadmin config -t target adapter_nameFC-Initiator
fcadmin config -t initiator adapter_name -
-
Beenden des Wartungsmodus:
haltWarten Sie, bis der Node an der LOADER-Eingabeaufforderung angehalten wird, nachdem Sie den Befehl ausgeführt haben.
-
Starten Sie den Node wieder in den Wartungsmodus, damit die Konfigurationsänderungen wirksam werden:
boot_ontap maint -
Überprüfen Sie die vorgenommenen Änderungen:
Wenn Sie über diese Art von HBA verfügen…
Befehl
CNA
ucadmin showFC
fcadmin show -
Beenden des Wartungsmodus:
haltWarten Sie, bis der Node an der LOADER-Eingabeaufforderung angehalten wird, nachdem Sie den Befehl ausgeführt haben.
-
Starten Sie den Knoten im Startmenü:
boot_ontap menuWarten Sie, bis das Boot-Menü angezeigt wird, nachdem Sie den Befehl ausgeführt haben.
-
Löschen Sie die Knotenkonfiguration, indem Sie in der Eingabeaufforderung des Startmenüs „
wipeconfig“ eingeben und dann die Eingabetaste drücken.Auf dem folgenden Bildschirm wird die Eingabeaufforderung des Startmenüs angezeigt:
Please choose one of the following:
(1) Normal Boot.
(2) Boot without /etc/rc.
(3) Change password.
(4) Clean configuration and initialize all disks.
(5) Maintenance mode boot.
(6) Update flash from backup config.
(7) Install new software first.
(8) Reboot node.
(9) Configure Advanced Drive Partitioning.
Selection (1-9)? wipeconfig
This option deletes critical system configuration, including cluster membership.
Warning: do not run this option on a HA node that has been taken over.
Are you sure you want to continue?: yes
Rebooting to finish wipeconfig request.
Konfigurieren von FC-VI-Ports auf einer X1132A-R6 Quad-Port-Karte auf FAS8020 Systemen
Wenn Sie die Quad-Port-Karte X1132A-R6 auf einem FAS8020 System verwenden, können Sie in den Wartungsmodus wechseln, um die 1a- und 1b-Ports für die FC-VI- und Initiatorverwendung zu konfigurieren. Dies ist für MetroCluster Systeme, die vom Werk empfangen werden, in denen die Ports für Ihre Konfiguration entsprechend eingestellt sind, nicht erforderlich.
Diese Aufgabe muss im Wartungsmodus ausgeführt werden.

|
Die Konvertierung eines FC-Ports in einen FC-VI-Port mit dem Befehl ucadmin wird nur auf den Systemen FAS8020 und AFF 8020 unterstützt. Das Konvertieren von FC-Ports in FCVI-Ports wird auf keiner anderen Plattform unterstützt. |
-
Deaktivieren Sie die Ports:
storage disable adapter 1astorage disable adapter 1b*> storage disable adapter 1a Jun 03 02:17:57 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1a. Host adapter 1a disable succeeded Jun 03 02:17:57 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1a is now offline. *> storage disable adapter 1b Jun 03 02:18:43 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1b. Host adapter 1b disable succeeded Jun 03 02:18:43 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1b is now offline. *>
-
Vergewissern Sie sich, dass die Ports deaktiviert sind:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - - offline 1b fc initiator - - offline 1c fc initiator - - online 1d fc initiator - - online -
Setzen Sie die A- und b-Ports auf den FC-VI-Modus:
ucadmin modify -adapter 1a -type fcviDer Befehl setzt den Modus auf beiden Ports im Port-Paar 1a und 1b (auch wenn im Befehl nur 1a angegeben ist).
*> ucadmin modify -t fcvi 1a Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1a. Reboot the controller for the changes to take effect. Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1b. Reboot the controller for the changes to take effect.
-
Bestätigen Sie, dass die Änderung aussteht:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - fcvi offline 1b fc initiator - fcvi offline 1c fc initiator - - online 1d fc initiator - - online -
Fahren Sie den Controller herunter, und starten Sie dann im Wartungsmodus neu.
-
Bestätigen Sie die Konfigurationsänderung:
ucadmin show localNode Adapter Mode Type Mode Type Status ------------ ------- ------- --------- ------- --------- ----------- ... controller_B_1 1a fc fcvi - - online controller_B_1 1b fc fcvi - - online controller_B_1 1c fc initiator - - online controller_B_1 1d fc initiator - - online 6 entries were displayed.
Überprüfen der Festplattenzuweisung im Wartungsmodus in einer Konfiguration mit acht oder vier Nodes
Vor dem vollständigen Booten des Systems zu ONTAP können Sie optional im Wartungsmodus booten und die Festplattenzuordnung auf den Nodes überprüfen. Die Laufwerke sollten einer vollständig symmetrischen aktiv/aktiv-Konfiguration zugewiesen werden, wobei jeder Pool eine gleiche Anzahl von Laufwerken zugewiesen hat.
Neue MetroCluster Systeme haben vor dem Versand eine Festplattenzuordnung abgeschlossen.
In der folgenden Tabelle sind Beispiele für Pool-Zuweisungen für eine MetroCluster-Konfiguration aufgeführt. Festplatten werden Pools nach Shelf-Basis zugewiesen.
Platten-Shelves an Standort A
Festplatten-Shelf (sample_Shelf_Name)… |
Gehört zu… |
Und ist diesem Node zugewiesen… |
Festplatten-Shelf 1 (Shelf_A_1_1) |
Knoten A 1 |
Pool 0 |
Festplatten-Shelf 2 (Shelf_A_1_3) |
||
Festplatten-Shelf 3 (Shelf_B_1_1) |
Knoten B 1 |
Pool 1 |
Festplatten-Shelf 4 (Shelf_B_1_3) |
||
Platten-Shelf 5 (Shelf_A_2_1) |
Knoten A 2 |
Pool 0 |
Platten-Shelf 6 (Shelf_A_2_3) |
||
Festplatten-Shelf 7 (Shelf_B_2_1) |
Knoten B 2 |
Pool 1 |
Festplatten-Shelf 8 (Shelf_B_2_3) |
||
Platten-Shelf 1 (Shelf_A_3_1) |
Knoten A 3 |
Pool 0 |
Festplatten-Shelf 2 (Shelf_A_3_3) |
||
Festplatten-Shelf 3 (Shelf_B_3_1) |
Knoten B 3 |
Pool 1 |
Festplatten-Shelf 4 (Shelf_B_3_3) |
||
Platten-Shelf 5 (Shelf_A_4_1) |
Knoten A 4 |
Pool 0 |
Platten-Shelf 6 (Shelf_A_4_3) |
||
Festplatten-Shelf 7 (Shelf_B_4_1) |
Knoten B 4 |
Pool 1 |
Festplatten-Shelf 8 (Shelf_B_4_3) |
Platten-Shelves an Standort B
Festplatten-Shelf (sample_Shelf_Name)… |
Gehört zu… |
Und ist diesem Node zugewiesen… |
Festplatten-Shelf 9 (Shelf_B_1_2) |
Knoten B 1 |
Pool 0 |
Festplatten-Shelf 10 (Shelf_B_1_4) |
Platten-Shelf 11 (Shelf_A_1_2) |
Knoten A 1 |
Pool 1 |
Platten-Shelf 12 (Shelf_A_1_4) |
Festplatten-Shelf 13 (Shelf_B_2_2) |
Knoten B 2 |
Pool 0 |
Festplatten-Shelf 14 (Shelf_B_2_4) |
Platten-Shelf 15 (Shelf_A_2_2) |
Knoten A 2 |
Pool 1 |
Platten-Shelf 16 (Shelf_A_2_4) |
Festplatten-Shelf 1 (Shelf_B_3_2) |
Knoten A 3 |
Pool 0 |
Festplatten-Shelf 2 (Shelf_B_3_4) |
Platten-Shelf 3 (Shelf_A_3_2) |
Knoten B 3 |
Pool 1 |
Platten-Shelf 4 (Shelf_A_3_4) |
Festplatten-Shelf 5 (Shelf_B_4_2) |
Knoten A 4 |
Pool 0 |
Festplatten-Shelf 6 (Shelf_B_4_4) |
Platten-Shelf 7 (Shelf_A_4_2) |
Knoten B 4 |
-
Bestätigen Sie die Shelf-Zuweisungen:
disk show –v -
Weisen Sie bei Bedarf explizit Festplatten auf den angeschlossenen Platten-Shelfs dem entsprechenden Pool zu:
disk assignWenn Sie im Befehl Platzhalter verwenden, können Sie alle Festplatten in einem Festplatten-Shelf mit einem Befehl zuweisen. Sie können die Festplatten-Shelf-IDs und Einschübe für jede Festplatte mit identifizieren
storage show disk -xBefehl.
Zuweisung der Festplatteneigentümer in anderen Systemen außerhalb von All Flash FAS
Wenn auf den MetroCluster Nodes die Festplatten nicht korrekt zugewiesen sind oder wenn Sie in Ihrer Konfiguration DS460C Platten-Shelfs verwenden, müssen Sie jedem der Nodes der MetroCluster Konfiguration Shelf-einzeln Festplatten zuweisen. Sie erstellen eine Konfiguration, in der jeder Knoten die gleiche Anzahl von Festplatten in seinen lokalen und Remote-Laufwerk-Pools hat.
Die Storage Controller müssen sich im Wartungsmodus befinden.
Wenn Ihre Konfiguration DS460C Festplatten-Shelfs nicht umfasst, ist diese Aufgabe nicht erforderlich, wenn die Festplatten bereits im Werk korrekt zugewiesen wurden.
|
|
Pool 0 enthält immer die Laufwerke, die sich an demselben Standort wie das Speichersystem befinden, zu dem sie gehören. Pool 1 enthält immer die Festplatten, die sich dem Speichersystem, zu dem sie gehören, fernhalten. |
Wenn Ihre Konfiguration DS460C Festplatten-Shelfs umfasst, sollten Sie die Festplatten anhand der folgenden Richtlinien für jedes Laufwerk mit 12 Festplatten manuell zuweisen:
Diese Festplatten in der Schublade zuweisen… |
Zu diesem Knoten und Pool… |
0-2 |
Pool des lokalen Node 0 |
3 - 5 |
Pool 0 des HA-Partner-Node |
6 - 8 |
DR-Partner des lokalen Knotens Pool 1 |
9 - 11 |
DR-Partner des HA-Partners Pool 1 |
Mit diesem Zuweisungsmuster wird sichergestellt, dass ein Aggregat minimal beeinträchtigt wird, wenn ein Einschub offline geht.
-
Wenn Sie dies noch nicht getan haben, starten Sie jedes System in den Wartungsmodus.
-
Weisen Sie die Platten-Shelfs den Nodes des ersten Standorts (Standort A) zu:
Festplatten-Shelfs an demselben Standort wie der Node werden Pool 0 zugewiesen, und Festplatten-Shelfs, die sich am Standort des Partners befinden, werden Pool 1 zugewiesen.
Sie sollten jedem Pool die gleiche Anzahl von Shelfs zuweisen.
-
Weisen Sie beim ersten Knoten systematisch die lokalen Festplatten-Shelfs dem Pool 0 und den Remote-Festplatten-Shelfs zu, und Pool 1:
disk assign -shelf local-switch-name:shelf-name.port -p poolWenn der Storage Controller Controller_A_1 vier Shelves hat, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1
-
Wiederholen Sie den Vorgang für den zweiten Node am lokalen Standort, indem Sie den Pool 0 und die Remote-Festplatten-Shelfs systematisch den Pool 1 zuweisen:
disk assign -shelf local-switch-name:shelf-name.port -p poolWenn der Storage Controller Controller_A_2 vier Shelves hat, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1
-
-
Weisen Sie die Platten-Shelfs den Nodes am zweiten Standort (Standort B) zu:
Festplatten-Shelfs an demselben Standort wie der Node werden Pool 0 zugewiesen, und Festplatten-Shelfs, die sich am Standort des Partners befinden, werden Pool 1 zugewiesen.
Sie sollten jedem Pool die gleiche Anzahl von Shelfs zuweisen.
-
Weisen Sie beim ersten Knoten am Remote-Standort systematisch seine lokalen Festplatten-Shelfs dem Pool 0 und seinen Remote-Festplatten-Shelfs zu 1:
disk assign -shelf local-switch-nameshelf-name -p poolWenn der Storage Controller_B_1 vier Shelves hat, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1
-
Wiederholen Sie den Vorgang für den zweiten Node am Remote-Standort, indem Sie seine lokalen Festplatten-Shelfs systematisch dem Pool 0 und den Remote-Festplatten-Shelfs Pool 1 zuordnen:
disk assign -shelf shelf-name -p poolWenn der Storage Controller_B_2 vier Shelves hat, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1
-
-
Bestätigen Sie die Shelf-Zuweisungen:
storage show shelf -
Beenden des Wartungsmodus:
halt -
Anzeigen des Startmenüs:
boot_ontap menu -
Wählen Sie auf jedem Knoten die Option 4, um alle Festplatten zu initialisieren.
Zuweisung der Festplatteneigentümer für AFF Systeme
Wenn Sie in einer Konfiguration mit AFF Systemen und gespiegelten Aggregaten einsetzen und die Nodes die Festplatten (SSDs) nicht korrekt zugewiesen sind, sollten Sie den HA-Partner-Node jeweils halb so viele Festplatten an jedem Shelf einem lokalen Node und der anderen Hälfte der Festplatten zuweisen. Sie sollten eine Konfiguration erstellen, in der jeder Knoten die gleiche Anzahl von Festplatten in seinen lokalen und Remote-Laufwerk-Pools hat.
Die Storage Controller müssen sich im Wartungsmodus befinden.
Dies gilt nicht für Konfigurationen mit nicht gespiegelten Aggregaten, einer aktiv/Passiv-Konfiguration oder einer ungleichen Anzahl von Festplatten in lokalen und Remote-Pools.
Dieser Task ist nicht erforderlich, wenn Festplatten beim Empfang vom Werk korrekt zugewiesen wurden.
|
|
Pool 0 enthält immer die Laufwerke, die sich an demselben Standort wie das Speichersystem befinden, zu dem sie gehören. Pool 1 enthält immer die Festplatten, die sich dem Speichersystem, zu dem sie gehören, fernhalten. |
-
Wenn Sie dies noch nicht getan haben, starten Sie jedes System in den Wartungsmodus.
-
Weisen Sie die Festplatten den Nodes des ersten Standorts (Standort A) zu:
Jedem Pool sollte eine gleiche Anzahl an Festplatten zugewiesen werden.
-
Weisen Sie beim ersten Knoten systematisch die Hälfte der Disks jedem Shelf zu, um 0 und die andere Hälfte dem Pool des HA-Partners 0 zu bündeln:
disk assign -shelf <shelf-name> -p <pool> -n <number-of-disks>Wenn der Storage Controller Controller_A_1 vier Shelves mit jeweils 8 SSDs aufweist, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1 -n 4
-
Wiederholen Sie den Vorgang für den zweiten Node am lokalen Standort, indem Sie systematisch die Hälfte der Festplatten in jedem Shelf den Pool 1 und die andere Hälfte dem Pool des HA-Partners 1 zuweisen:
disk assign -disk disk-name -p poolWenn der Storage Controller Controller_A_1 vier Shelves mit jeweils 8 SSDs aufweist, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4
-
-
Weisen Sie die Festplatten den Nodes des zweiten Standorts (Standort B) zu:
Jedem Pool sollte eine gleiche Anzahl an Festplatten zugewiesen werden.
-
Weisen Sie auf dem ersten Knoten am Remote-Standort systematisch die Hälfte der Festplatten auf jedem Shelf zu, um den Pool 0 und die andere Hälfte dem Pool des HA-Partners 0 zu bündeln:
disk assign -disk disk-name -p poolWenn der Storage Controller Controller_B_1 vier Shelves mit jeweils 8 SSDs hat, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1 -n 4
-
Wiederholen Sie diesen Vorgang für den zweiten Node am Remote-Standort, indem Sie in jedem Shelf systematisch die Hälfte der Festplatten dem Pool 1 und der anderen Hälfte dem Pool des HA-Partners 1 zuweisen:
disk assign -disk disk-name -p poolWenn der Storage Controller Controller_B_2 vier Shelfs mit jeweils 8 SSDs aufweist, geben Sie die folgenden Befehle ein:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1 -n 4
-
-
Bestätigen Sie die Festplattenzuordnungen:
storage show disk -
Beenden des Wartungsmodus:
halt -
Anzeigen des Startmenüs:
boot_ontap menu -
Wählen Sie auf jedem Knoten die Option 4, um alle Festplatten zu initialisieren.
Überprüfen der Festplattenzuweisung im Wartungsmodus in einer Konfiguration mit zwei Nodes
Vor dem vollständigen Booten des Systems zu ONTAP können Sie optional das System im Wartungsmodus booten und die Festplattenzuordnung auf den Nodes überprüfen. Die Festplatten sollten eine vollständig symmetrische Konfiguration erstellen, bei der beide Standorte ihre eigenen Platten-Shelves besitzen und Daten bereitstellen, wobei jedem Knoten und jedem Pool die gleiche Anzahl von gespiegelten Festplatten zugewiesen ist.
Das System muss sich im Wartungsmodus befinden.
Neue MetroCluster Systeme haben vor dem Versand eine Festplattenzuordnung abgeschlossen.
In der folgenden Tabelle sind Beispiele für Pool-Zuweisungen für eine MetroCluster-Konfiguration aufgeführt. Festplatten werden Pools nach Shelf-Basis zugewiesen.
Festplatten-Shelf (Beispielname)… |
An Standort… |
Gehört zu… |
Und ist diesem Node zugewiesen… |
Festplatten-Shelf 1 (Shelf_A_1_1) |
Standort A |
Knoten A 1 |
Pool 0 |
Festplatten-Shelf 2 (Shelf_A_1_3) |
|||
Festplatten-Shelf 3 (Shelf_B_1_1) |
Knoten B 1 |
Pool 1 |
|
Festplatten-Shelf 4 (Shelf_B_1_3) |
|||
Festplatten-Shelf 9 (Shelf_B_1_2) |
Standort B |
Knoten B 1 |
Pool 0 |
Festplatten-Shelf 10 (Shelf_B_1_4) |
|||
Platten-Shelf 11 (Shelf_A_1_2) |
Knoten A 1 |
Pool 1 |
|
Platten-Shelf 12 (Shelf_A_1_4) |
Wenn Ihre Konfiguration DS460C Festplatten-Shelfs umfasst, sollten Sie die Festplatten anhand der folgenden Richtlinien für jedes Laufwerk mit 12 Festplatten manuell zuweisen:
Diese Festplatten in der Schublade zuweisen… |
Zu diesem Knoten und Pool… |
1 - 6 |
Pool des lokalen Node 0 |
7 - 12 |
Pool 1 DES DR-Partners |
Dieses Muster der Festplattenzuordnung minimiert die Auswirkungen auf ein Aggregat, wenn ein Einschub offline geht.
-
Wenn Ihr System vom Werk empfangen wurde, bestätigen Sie die Regalzuordnungen:
disk show –v -
Bei Bedarf können Sie mithilfe des Befehls Disk assign Festplatten in den angeschlossenen Platten-Shelfs dem entsprechenden Pool zuweisen.
Festplatten-Shelfs an demselben Standort wie der Node werden Pool 0 zugewiesen, und Festplatten-Shelfs, die sich am Standort des Partners befinden, werden Pool 1 zugewiesen. Sie sollten jedem Pool die gleiche Anzahl von Shelfs zuweisen.
-
Wenn Sie dies noch nicht getan haben, starten Sie jedes System in den Wartungsmodus.
-
Weisen Sie auf dem Knoten vor Ort A systematisch die lokalen Festplatten-Shelfs dem Pool 0 und den Remote-Festplatten-Shelfs zu 1:
disk assign -shelf disk_shelf_name -p poolWenn der Storage Controller Node_A_1 vier Shelfs aufweist, geben Sie die folgenden Befehle ein:
*> disk assign -shelf shelf_A_1_1 -p 0 *> disk assign -shelf shelf_A_1_3 -p 0 *> disk assign -shelf shelf_A_1_2 -p 1 *> disk assign -shelf shelf_A_1_4 -p 1
-
Weisen Sie auf dem Knoten am Remote-Standort (Standort B) systematisch seine lokalen Festplatten-Shelfs dem Pool 0 und seinen Remote-Festplatten-Shelfs zu, um Pool 1 zu bündeln:
disk assign -shelf disk_shelf_name -p poolWenn der Storage Controller Node_B_1 vier Shelfs hat, geben Sie die folgenden Befehle ein:
*> disk assign -shelf shelf_B_1_2 -p 0 *> disk assign -shelf shelf_B_1_4 -p 0 *> disk assign -shelf shelf_B_1_1 -p 1 *> disk assign -shelf shelf_B_1_3 -p 1
-
Zeigt die Festplatten-Shelf-IDs und Einschübe für jede Festplatte an:
disk show –v
-
Einrichtung von ONTAP
Sie müssen ONTAP auf jedem Controller-Modul einrichten.
Wenn Sie die neuen Controller als Netzboot ausführen müssen, finden Sie unter "Netbootting der neuen Controller-Module" Im MetroCluster Upgrade, Transition and Expansion Guide.
Einrichten von ONTAP in einer MetroCluster Konfiguration mit zwei Nodes
In einer MetroCluster-Konfiguration mit zwei Nodes müssen Sie auf jedem Cluster den Node booten, den Setup-Assistenten für den Cluster beenden und den Cluster-Setup-Befehl verwenden, um den Node als Single Node Cluster zu konfigurieren.
Sie dürfen den Service Processor nicht konfiguriert haben.
Diese Aufgabe gilt für MetroCluster-Konfigurationen mit zwei Nodes, die nativen NetApp Storage verwenden.
Diese Aufgabe muss auf beiden Clustern in der MetroCluster Konfiguration ausgeführt werden.
Weitere allgemeine Informationen zum Einrichten von ONTAP finden Sie unter "ONTAP einrichten".
-
Schalten Sie den ersten Node ein.
Sie müssen diesen Schritt auf dem Node am Disaster-Recovery-Standort (DR) wiederholen. Der Node bootet. Anschließend startet der Cluster-Setup-Assistent auf der Konsole, sodass Sie informiert werden, dass AutoSupport automatisch aktiviert wird.
::> Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: Enter the node management interface IP address [10.101.01.01]: Enter the node management interface netmask [101.010.101.0]: Enter the node management interface default gateway [10.101.01.0]: Do you want to create a new cluster or join an existing cluster? {create, join}: -
Erstellen eines neuen Clusters:
create -
Wählen Sie, ob der Node als Single Node Cluster verwendet werden soll.
Do you intend for this node to be used as a single node cluster? {yes, no} [yes]: -
Akzeptieren Sie die Standardeinstellung des Systems
yesDrücken Sie die Eingabetaste, oder geben Sie Ihre eigenen Werte ein, indem Sie eingebenno, Und drücken Sie dann die Eingabetaste. -
Befolgen Sie die Anweisungen, um den Assistenten Cluster Setup abzuschließen. Drücken Sie die Eingabetaste, um die Standardwerte zu akzeptieren, oder geben Sie Ihre eigenen Werte ein, und drücken Sie dann die Eingabetaste.
Die Standardwerte werden automatisch basierend auf Ihrer Plattform und Netzwerkkonfiguration ermittelt.
-
Nachdem Sie den Cluster Setup-Assistenten abgeschlossen und beendet haben, überprüfen Sie, ob der Cluster aktiv ist und der erste Knoten ordnungsgemäß ist: `
cluster showDas folgende Beispiel zeigt ein Cluster, in dem der erste Node (cluster1-01) sich in einem ordnungsgemäßen Zustand befindet und zur Teilnahme berechtigt ist:
cluster1::> cluster show Node Health Eligibility --------------------- ------- ------------ cluster1-01 true true
Falls eine der Einstellungen geändert werden muss, die Sie für die Admin-SVM oder Node-SVM eingegeben haben, können Sie über den Cluster-Setup-Befehl auf den Cluster-Setup-Assistenten zugreifen.
Einrichten von ONTAP in einer MetroCluster Konfiguration mit acht oder vier Nodes
Nachdem Sie jeden Node gebootet haben, werden Sie aufgefordert, das System Setup Tool auszuführen, um die grundlegende Node- und Cluster-Konfiguration durchzuführen. Nach dem Konfigurieren des Clusters kehren Sie zur ONTAP-CLI zurück, um Aggregate zu erstellen und die MetroCluster-Konfiguration zu erstellen.
Sie müssen die MetroCluster-Konfiguration verkabelt haben.
Diese Aufgabe gilt für MetroCluster Konfigurationen mit acht oder vier Nodes mithilfe von nativem NetApp Storage.
Neue MetroCluster Systeme sind vorkonfiguriert. Sie müssen diese Schritte nicht ausführen. Sie sollten jedoch das AutoSupport-Tool konfigurieren.
Diese Aufgabe muss auf beiden Clustern in der MetroCluster Konfiguration ausgeführt werden.
Dieses Verfahren verwendet das System-Setup-Tool. Wenn gewünscht, können Sie stattdessen den CLI-Cluster-Setup-Assistenten verwenden.
-
Falls noch nicht geschehen, schalten Sie jeden Knoten ein und lassen Sie ihn vollständig booten.
Wenn sich das System im Wartungsmodus befindet, geben Sie den Befehl stop ein, um den Wartungsmodus zu beenden, und geben Sie dann den folgenden Befehl an der LOADER-Eingabeaufforderung aus:
boot_ontapDie Ausgabe sollte wie folgt aussehen:
Welcome to node setup You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the setup wizard. Any changes you made before quitting will be saved. To accept a default or omit a question, do not enter a value. . . .
-
Aktivieren Sie das AutoSupport-Tool, indem Sie den vom System bereitgestellten Anweisungen folgen.
-
Befolgen Sie die Aufforderungen zur Konfiguration der Node-Managementoberfläche.
Die Eingabeaufforderungen sind ähnlich wie folgende:
Enter the node management interface port: [e0M]: Enter the node management interface IP address: 10.228.160.229 Enter the node management interface netmask: 225.225.252.0 Enter the node management interface default gateway: 10.228.160.1
-
Sicherstellen, dass die Nodes im Hochverfügbarkeits-Modus konfiguriert sind:
storage failover show -fields modeWenn nicht, müssen Sie für jeden Node den folgenden Befehl eingeben und den Node neu booten:
storage failover modify -mode ha -node localhostDieser Befehl konfiguriert den Hochverfügbarkeits-Modus, ermöglicht jedoch kein Storage Failover. Das Storage-Failover wird automatisch aktiviert, wenn die MetroCluster-Konfiguration zu einem späteren Zeitpunkt im Konfigurationsprozess durchgeführt wird.
-
Sicherstellen, dass vier Ports als Cluster Interconnects konfiguriert sind:
network port showIm folgenden Beispiel wird die Ausgabe für „Cluster_A“ angezeigt:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ node_A_1 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 node_A_2 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Wenn Sie einen 2-Node-Cluster ohne Switches (ein Cluster ohne Cluster-Interconnect-Switches) erstellen, aktivieren Sie den Networking-Modus ohne Switches:
-
Ändern Sie die erweiterte Berechtigungsebene:
set -privilege advanced
Sie können antworten
yWenn Sie aufgefordert werden, den erweiterten Modus fortzusetzen. Die Eingabeaufforderung für den erweiterten Modus wird angezeigt (*).-
Aktivieren des Cluster-Modus ohne Switches:
network options switchless-cluster modify -enabled true -
Zurück zur Administratorberechtigungsebene:
set -privilege admin
-
-
Starten Sie das System-Setup-Tool gemäß den Informationen, die nach dem ersten Booten auf der Systemkonsole angezeigt werden.
-
Verwenden Sie das System Setup Tool, um jeden Node zu konfigurieren und den Cluster zu erstellen, jedoch keine Aggregate zu erstellen.
Sie erstellen gespiegelte Aggregate in späteren Aufgaben.
Kehren Sie zur ONTAP-Befehlszeilenschnittstelle zurück und führen Sie die MetroCluster-Konfiguration durch. Führen Sie dazu die folgenden Aufgaben aus.
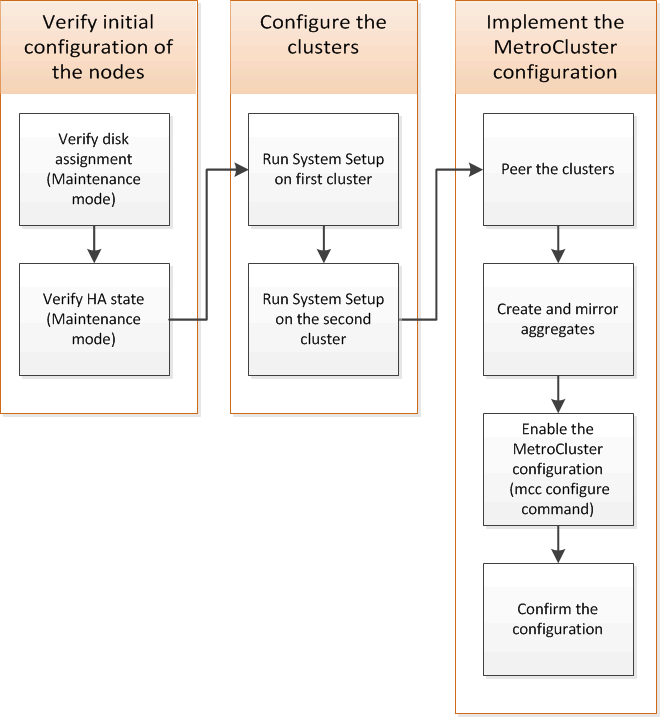
Konfigurieren der Cluster in einer MetroCluster-Konfiguration
Sie müssen die Cluster Peer, die Root-Aggregate spiegeln, ein gespiegeltes Datenaggregat erstellen und dann den Befehl zum Implementieren der MetroCluster Operationen ausgeben.
Bevor Sie ausführen metrocluster configure, HA-Modus und DR-Spiegelung sind nicht aktiviert und Sie können eine Fehlermeldung in Bezug auf dieses erwartete Verhalten sehen. Sie aktivieren später den HA-Modus und die DR-Spiegelung, wenn Sie den Befehl ausführen metrocluster configure Um die Konfiguration zu implementieren.
Peering der Cluster
Die Cluster in der MetroCluster Konfiguration müssen sich in einer Peer-Beziehung zueinander finden, damit sie kommunizieren und die für MetroCluster Disaster Recovery essentielle Datenspiegelung durchführen können.
Konfigurieren von Intercluster-LIFs
Sie müssen Intercluster-LIFs an Ports erstellen, die für die Kommunikation zwischen den MetroCluster-Partner-Clustern verwendet werden. Sie können dedizierte Ports oder Ports verwenden, die auch Datenverkehr haben.
Konfigurieren von Intercluster-LIFs auf dedizierten Ports
Sie können Intercluster-LIFs auf dedizierten Ports konfigurieren. Dadurch wird typischerweise die verfügbare Bandbreite für den Replizierungsverkehr erhöht.
-
Liste der Ports im Cluster:
network port showEine vollständige Befehlssyntax finden Sie in der man-Page.
Im folgenden Beispiel werden die Netzwerk-Ports in „cluster01“ angezeigt:
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
Bestimmen Sie, welche Ports für die Intercluster-Kommunikation verfügbar sind:
network interface show -fields home-port,curr-portEine vollständige Befehlssyntax finden Sie in der man-Page.
Das folgende Beispiel zeigt, dass den Ports „e0e“ und „e0f“ keine LIFs zugewiesen wurden:
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
Erstellen Sie eine Failover-Gruppe für die dedizierten Ports:
network interface failover-groups create -vserver system_SVM -failover-group failover_group -targets physical_or_logical_portsDas folgende Beispiel weist den Failover-Gruppe intercluster01 Ports „e0e“ und „e0f“ auf dem System „SVMcluster01“ zu:
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
Vergewissern Sie sich, dass die Failover-Gruppe erstellt wurde:
network interface failover-groups showEine vollständige Befehlssyntax finden Sie in der man-Page.
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
Erstellen Sie Intercluster-LIFs auf der System-SVM und weisen Sie sie der Failover-Gruppe zu.
ONTAP 9.6 und höhernetwork interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupONTAP 9.5 und frühernetwork interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupEine vollständige Befehlssyntax finden Sie in der man-Page.
Im folgenden Beispiel werden Intercluster-LIFs „cluster01_ic.01“ und „cluster01_ic02“ in der Failover-Gruppe „intercluster01“ erstellt:
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
Überprüfen Sie, ob die Intercluster-LIFs erstellt wurden:
ONTAP 9.6 und höherFühren Sie den Befehl aus:
network interface show -service-policy default-interclusterONTAP 9.5 und früherFühren Sie den Befehl aus:
network interface show -role interclusterEine vollständige Befehlssyntax finden Sie in der man-Page.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
Vergewissern Sie sich, dass die Intercluster-LIFs redundant sind:
ONTAP 9.6 und höherFühren Sie den Befehl aus:
network interface show -service-policy default-intercluster -failoverONTAP 9.5 und früherFühren Sie den Befehl aus:
network interface show -role intercluster -failoverEine vollständige Befehlssyntax finden Sie in der man-Page.
Das folgende Beispiel zeigt, dass der Intercluster LIFs „cluster01_ic.01“ und „cluster01_ic.02“ auf dem SVM „e0e“-Port an den „e0f“-Port scheitern.
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
Wenn Sie bestimmen, ob die Verwendung eines dedizierten Ports für die Intercluster-Replikation die richtige Intercluster-Netzwerklösung ist, sollten Sie Konfigurationen und Anforderungen wie LAN-Typ, verfügbare WAN-Bandbreite, Replikationsintervall, Änderungsrate und Anzahl der Ports berücksichtigen.
Konfigurieren von Intercluster-LIFs auf gemeinsam genutzten Datenports
Sie können Intercluster-LIFs an Ports konfigurieren, die gemeinsam mit dem Datennetzwerk verwendet werden. Auf diese Weise wird die Anzahl der Ports reduziert, die Sie für Intercluster-Netzwerke benötigen.
-
Liste der Ports im Cluster:
network port showEine vollständige Befehlssyntax finden Sie in der man-Page.
Im folgenden Beispiel werden die Netzwerkports in cluster01 angezeigt:
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
Intercluster-LIFs auf der System-SVM erstellen:
ONTAP 9.6 und höherFühren Sie den Befehl aus:
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskONTAP 9.5 und früherFühren Sie den Befehl aus:
network interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmaskEine vollständige Befehlssyntax finden Sie in der man-Page. Im folgenden Beispiel werden Intercluster-LIFs cluster01_ic.01 und cluster01_ic02 erstellt:
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
Überprüfen Sie, ob die Intercluster-LIFs erstellt wurden:
ONTAP 9.6 und höherFühren Sie den Befehl aus:
network interface show -service-policy default-interclusterONTAP 9.5 und früherFühren Sie den Befehl aus:
network interface show -role interclusterEine vollständige Befehlssyntax finden Sie in der man-Page.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
Vergewissern Sie sich, dass die Intercluster-LIFs redundant sind:
ONTAP 9.6 und höherFühren Sie den Befehl aus:
network interface show –service-policy default-intercluster -failoverONTAP 9.5 und früherFühren Sie den Befehl aus:
network interface show -role intercluster -failoverEine vollständige Befehlssyntax finden Sie in der man-Page.
Das folgende Beispiel zeigt, dass der Intercluster LIFs „cluster01_ic.01“ und „cluster01_ic.02“ auf dem „e0c“-Port an den „e0d“-Port scheitern wird.
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
Erstellen einer Cluster-Peer-Beziehung
Sie müssen die Cluster-Peer-Beziehung zwischen den MetroCluster Clustern erstellen.
Sie können das verwenden cluster peer create Befehl zum Erstellen einer Peer-Beziehung zwischen einem lokalen und einem Remote-Cluster. Nachdem die Peer-Beziehung erstellt wurde, können Sie ausführen cluster peer create Im Remote-Cluster zur Authentifizierung beim lokalen Cluster.
-
Sie müssen auf jedem Node in den Clustern, die Peering durchführen, Intercluster LIFs erstellt haben.
-
Die Cluster müssen ONTAP 9.3 oder höher ausführen.
-
Erstellen Sie auf dem Ziel-Cluster eine Peer-Beziehung mit dem Quell-Cluster:
cluster peer create -generate-passphrase -offer-expiration MM/DD/YYYY HH:MM:SS|1…7days|1…168hours -peer-addrs peer_LIF_IPs -ipspace ipspaceWenn Sie beides angeben
-generate-passphraseUnd-peer-addrs, Nur der Cluster, dessen Intercluster LIFs in angegeben sind-peer-addrsKann das generierte Passwort verwenden.Sie können die ignorieren
-ipspaceOption, wenn kein benutzerdefinierter IPspace verwendet wird. Eine vollständige Befehlssyntax finden Sie in der man-Page.Im folgenden Beispiel wird eine Cluster-Peer-Beziehung auf einem nicht angegebenen Remote-Cluster erstellt:
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
Authentifizierung des Quellclusters im Quellcluster beim Ziel-Cluster:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspaceEine vollständige Befehlssyntax finden Sie in der man-Page.
Im folgenden Beispiel wird der lokale Cluster an den Remote-Cluster unter LIF-IP-Adressen „192.140.112.101“ und „192.140.112.102“ authentifiziert:
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.Geben Sie die Passphrase für die Peer-Beziehung ein, wenn Sie dazu aufgefordert werden.
-
Vergewissern Sie sich, dass die Cluster-Peer-Beziehung erstellt wurde:
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
Prüfen Sie die Konnektivität und den Status der Knoten in der Peer-Beziehung:
cluster peer health showcluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Erstellen einer Cluster-Peer-Beziehung (ONTAP 9.2 und älter)
Sie können das verwenden cluster peer create Befehl zum Initiierung einer Anforderung für eine Peering-Beziehung zwischen einem lokalen und einem Remote-Cluster. Nachdem die Peer-Beziehung vom lokalen Cluster angefordert wurde, können Sie ausführen cluster peer create Auf dem Remote-Cluster, um die Beziehung zu akzeptieren.
-
Sie müssen auf jedem Node in den Clustern, die Peering durchführen, Intercluster LIFs erstellt haben.
-
Cluster-Administratoren müssen der Passphrase zugestimmt haben, die jedes Cluster verwendet, um sich beim anderen zu authentifizieren.
-
Erstellen Sie auf dem Ziel-Cluster für die Datensicherung eine Peer-Beziehung mit dem Quell-Cluster:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspaceSie können die Option -ipspace ignorieren, wenn Sie keinen benutzerdefinierten IPspace verwenden. Eine vollständige Befehlssyntax finden Sie in der man-Page.
Das folgende Beispiel erstellt eine Cluster-Peer-Beziehung zum Remote-Cluster bei intercluster LIF IP-Adressen „192.168.2.201“ und „192.168.2.202“:
cluster02::> cluster peer create -peer-addrs 192.168.2.201,192.168.2.202 Enter the passphrase: Please enter the passphrase again:
Geben Sie die Passphrase für die Peer-Beziehung ein, wenn Sie dazu aufgefordert werden.
-
Authentifizieren Sie das Quell-Cluster im Datensicherungs-Quellcluster beim Ziel-Cluster:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspaceEine vollständige Befehlssyntax finden Sie in der man-Page.
Im folgenden Beispiel wird der lokale Cluster an den Remote-Cluster unter LIF-IP-Adressen „192.140.112.203“ und „192.140.112.204“ authentifiziert:
cluster01::> cluster peer create -peer-addrs 192.168.2.203,192.168.2.204 Please confirm the passphrase: Please confirm the passphrase again:
Geben Sie die Passphrase für die Peer-Beziehung ein, wenn Sie dazu aufgefordert werden.
-
Vergewissern Sie sich, dass die Cluster-Peer-Beziehung erstellt wurde:
cluster peer show –instanceEine vollständige Befehlssyntax finden Sie in der man-Page.
cluster01::> cluster peer show –instance Peer Cluster Name: cluster01 Remote Intercluster Addresses: 192.168.2.201,192.168.2.202 Availability: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.168.2.201,192.168.2.202 Cluster Serial Number: 1-80-000013
-
Prüfen Sie die Konnektivität und den Status der Knoten in der Peer-Beziehung:
cluster peer health show`Eine vollständige Befehlssyntax finden Sie in der man-Page.
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Spiegelung der Root-Aggregate
Um Datensicherung zu ermöglichen, müssen Sie die Root-Aggregate spiegeln.
Standardmäßig wird das Root-Aggregat als RAID-DP Typ Aggregat erstellt. Sie können das Root-Aggregat von RAID-DP zu einem Aggregat des RAID4-Typs ändern. Mit dem folgenden Befehl wird das Root-Aggregat für das RAID4-Typ-Aggregat modifiziert:
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
|
Auf Systemen anderer Hersteller kann der RAID-Typ des Aggregats von dem Standard RAID-DP zu RAID4 vor oder nach der Spiegelung des Aggregats geändert werden. |
-
Root-Aggregat spiegeln:
storage aggregate mirror aggr_nameDer folgende Befehl spiegelt das Root-Aggregat für Controller_A_1:
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
Dies spiegelt das Aggregat, also besteht es aus einem lokalen Plex und einem Remote Plex am Remote MetroCluster Standort.
-
Wiederholen Sie den vorherigen Schritt für jeden Node in der MetroCluster-Konfiguration.
Erstellung eines gespiegelten Datenaggregats auf jedem Node
Sie müssen auf jedem Knoten in der DR-Gruppe ein gespiegeltes Datenaggregat erstellen.
-
Sie sollten wissen, welche Laufwerke in dem neuen Aggregat verwendet werden.
-
Wenn Sie mehrere Laufwerktypen in Ihrem System haben (heterogener Speicher), sollten Sie verstehen, wie Sie sicherstellen können, dass der richtige Laufwerkstyp ausgewählt ist.
-
Laufwerke sind Eigentum eines bestimmten Nodes. Wenn Sie ein Aggregat erstellen, müssen alle Laufwerke in diesem Aggregat im Besitz desselben Nodes sein, der zum Home-Node für das Aggregat wird.
-
Aggregatnamen sollten dem Benennungsschema entsprechen, das Sie beim Planen Ihrer MetroCluster-Konfiguration ermittelt haben. Siehe "Festplatten- und Aggregatmanagement".
-
Die Namen der Aggregate müssen auf allen MetroCluster-Standorten eindeutig sein. Das bedeutet, dass Sie nicht zwei verschiedene Aggregate mit demselben Namen auf Standort A und Standort B haben können.
-
Liste der verfügbaren Ersatzteile anzeigen:
storage disk show -spare -owner node_name -
Erstellen Sie das Aggregat mit dem Storage-Aggregat create -mirror TRUE Befehl.
Wenn Sie auf der Cluster-Managementoberfläche beim Cluster angemeldet sind, können Sie auf jedem Node im Cluster ein Aggregat erstellen. Um sicherzustellen, dass das Aggregat auf einem bestimmten Node erstellt wird, verwenden Sie die
-nodeParameter oder geben Sie Laufwerke an, die diesem Node gehören.Sie können die folgenden Optionen angeben:
-
Der Home Node des Aggregats (d. h. der Knoten, der das Aggregat im normalen Betrieb besitzt)
-
Liste spezifischer Laufwerke, die dem Aggregat hinzugefügt werden sollen
-
Anzahl der zu einführenden Laufwerke
In der minimal unterstützten Konfiguration, bei der eine begrenzte Anzahl von Laufwerken verfügbar ist, müssen Sie den verwenden force-small-aggregateOption zum Erstellen eines RAID-DP Aggregats mit drei Festplatten.-
Prüfsummenstil, den Sie für das Aggregat verwenden möchten
-
Typ der zu verwendenden Laufwerke
-
Die Größe der zu verwendenden Laufwerke
-
Fahrgeschwindigkeit zu verwenden
-
RAID-Typ für RAID-Gruppen auf dem Aggregat
-
Maximale Anzahl an Laufwerken, die in eine RAID-Gruppe aufgenommen werden können
-
Gibt an, ob Laufwerke mit unterschiedlichen U/min zulässig sind
Weitere Informationen zu diesen Optionen finden Sie im
storage aggregate createMan-Page.Mit dem folgenden Befehl wird ein gespiegeltes Aggregat mit 10 Festplatten erstellt:
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Überprüfen Sie die RAID-Gruppe und die Laufwerke Ihres neuen Aggregats:
storage aggregate show-status -aggregate aggregate-name
Erstellen von nicht gespiegelten Datenaggregaten
Optional können Sie nicht gespiegelte Datenaggregate für Daten erstellen, für die keine redundante Spiegelung von MetroCluster-Konfigurationen erforderlich ist.
-
Stellen Sie sicher, dass Sie wissen, welche Laufwerke im neuen Aggregat verwendet werden.
-
Wenn Sie mehrere Laufwerktypen in Ihrem System haben (heterogener Speicher), sollten Sie verstehen, wie Sie überprüfen können, ob der richtige Laufwerkstyp ausgewählt ist.

|
Bei MetroCluster FC-Konfigurationen sind die nicht gespiegelten Aggregate erst nach einer Umschaltung online, wenn auf die Remote-Festplatten im Aggregat zugegriffen werden kann. Wenn die ISLs ausfallen, kann der lokale Knoten möglicherweise nicht auf die Daten auf den nicht gespiegelten Remote-Festplatten zugreifen. Der Ausfall eines Aggregats kann zu einem Neustart des lokalen Node führen. |
-
Laufwerke sind Eigentum eines bestimmten Nodes. Wenn Sie ein Aggregat erstellen, müssen alle Laufwerke in diesem Aggregat im Besitz desselben Nodes sein, der zum Home-Node für das Aggregat wird.
|
|
Die nicht gespiegelten Aggregate müssen sich lokal an dem Node halten, auf dem sie sich enthalten. |
-
Aggregatnamen sollten dem Benennungsschema entsprechen, das Sie beim Planen Ihrer MetroCluster-Konfiguration ermittelt haben.
-
Festplatten- und Aggregatmanagement enthält weitere Informationen zur Spiegelung von Aggregaten.
-
Liste der verfügbaren Ersatzteile anzeigen:
storage disk show -spare -owner node_name -
Erstellen Sie das Aggregat:
storage aggregate createWenn Sie auf der Cluster-Managementoberfläche beim Cluster angemeldet sind, können Sie auf jedem Node im Cluster ein Aggregat erstellen. Um zu überprüfen, ob das Aggregat auf einem bestimmten Node erstellt wird, sollten Sie das verwenden
-nodeParameter oder geben Sie Laufwerke an, die diesem Node gehören.Sie können die folgenden Optionen angeben:
-
Der Home Node des Aggregats (d. h. der Knoten, der das Aggregat im normalen Betrieb besitzt)
-
Liste spezifischer Laufwerke, die dem Aggregat hinzugefügt werden sollen
-
Anzahl der zu einführenden Laufwerke
-
Prüfsummenstil, den Sie für das Aggregat verwenden möchten
-
Typ der zu verwendenden Laufwerke
-
Die Größe der zu verwendenden Laufwerke
-
Fahrgeschwindigkeit zu verwenden
-
RAID-Typ für RAID-Gruppen auf dem Aggregat
-
Maximale Anzahl an Laufwerken, die in eine RAID-Gruppe aufgenommen werden können
-
Gibt an, ob Laufwerke mit unterschiedlichen U/min zulässig sind
Weitere Informationen zu diesen Optionen finden Sie auf der „Storage Aggregate create man page“.
Mit dem folgenden Befehl wird ein nicht gespiegeltes Aggregat mit 10 Festplatten erstellt:
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Überprüfen Sie die RAID-Gruppe und die Laufwerke Ihres neuen Aggregats:
storage aggregate show-status -aggregate aggregate-name
Implementieren der MetroCluster-Konfiguration
Sie müssen den ausführen metrocluster configure Befehl zum Starten der Datensicherung in einer MetroCluster-Konfiguration.
-
Es sollten mindestens zwei gespiegelte Datenaggregate ohne Root-Wurzeln auf jedem Cluster vorhanden sein.
Zusätzliche Datenaggregate können entweder gespiegelt oder nicht gespiegelt werden.
Sie können dies mit dem überprüfen
storage aggregate showBefehl.
Wenn Sie ein einzelnes gespiegeltes Datenaggregat verwenden möchten, finden Sie weitere Informationen unter Schritt 1 Weitere Anweisungen. -
Der HA-Konfigurationsstatus der Controller und des Chassis muss „mcc“ sein.
Sie stellen das aus metrocluster configure Um die MetroCluster-Konfiguration zu aktivieren, aktivieren Sie einmal den Befehl auf einem der Nodes. Sie müssen den Befehl nicht für jede der Standorte oder Nodes ausführen. Es ist nicht von Bedeutung, auf welchem Node oder Standort Sie den Befehl ausgeben möchten.
Der metrocluster configure Befehl koppelt die beiden Nodes automatisch mit den niedrigsten System-IDs in jedem der beiden Cluster als Disaster Recovery (DR) Partner. In einer MetroCluster Konfiguration mit vier Nodes gibt es zwei DR-Partnerpaare. Das zweite DR-Paar wird aus den beiden Knoten mit höheren System-IDs erstellt.
|
|
Sie müssen vor Ausführung des Befehls * Onboard Key Manager (OKM) oder externe Schlüsselverwaltung nicht konfigurieren metrocluster configure.
|
-
[[step1_aggr] Konfigurieren Sie die MetroCluster im folgenden Format:
Wenn Ihre MetroCluster Konfiguration…
Dann tun Sie das…
Mehrere Datenaggregate
Konfigurieren Sie an der Eingabeaufforderung eines beliebigen Nodes MetroCluster:
metrocluster configure node-nameEin einzelnes gespiegeltes Datenaggregat
-
Ändern Sie von der Eingabeaufforderung eines beliebigen Node auf die erweiterte Berechtigungsebene:
set -privilege advancedSie müssen mit reagieren
yWenn Sie aufgefordert werden, den erweiterten Modus fortzusetzen, wird die Eingabeaufforderung für den erweiterten Modus (*>) angezeigt. -
Konfigurieren Sie die MetroCluster mit dem
-allow-with-one-aggregate trueParameter:metrocluster configure -allow-with-one-aggregate true node-name -
Zurück zur Administratorberechtigungsebene:
set -privilege admin
Die Best Practice besteht in der Nutzung mehrerer Datenaggregate. Wenn die erste DR-Gruppe nur ein Aggregat hat und Sie eine DR-Gruppe mit einem Aggregat hinzufügen möchten, müssen Sie das Metadaten-Volume aus dem einzelnen Datenaggregat verschieben. Weitere Informationen zu diesem Verfahren finden Sie unter "Verschieben eines Metadaten-Volumes in MetroCluster Konfigurationen". Mit dem folgenden Befehl wird die MetroCluster-Konfiguration auf allen Knoten in der DR-Gruppe aktiviert, die Controller_A_1 enthält:
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
Überprüfen Sie den Netzwerkstatus auf Standort A:
network port showIm folgenden Beispiel wird die Verwendung von Netzwerkports in einer MetroCluster Konfiguration mit vier Nodes angezeigt:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Überprüfen Sie die MetroCluster Konfiguration von beiden Standorten in der MetroCluster Konfiguration.
-
Überprüfen Sie die Konfiguration von Standort A:
metrocluster showcluster_A::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
Überprüfen Sie die Konfiguration von Standort B:
metrocluster show
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
Konfigurieren von in-Order-Lieferung oder Lieferung von Frames auf ONTAP Software außerhalb der Reihenfolge
Sie müssen entweder in-Order-Lieferung (IOD) oder Out-of-Order-Lieferung (OOD) von Frames entsprechend der Fibre-Channel (FC) Switch-Konfiguration konfigurieren.
Wenn der FC-Switch für IOD konfiguriert ist, muss die ONTAP-Software für IOD konfiguriert werden. Gleiches gilt, wenn der FC-Switch für OOD konfiguriert ist, dann muss ONTAP für OOD konfiguriert werden.
|
|
Sie müssen den Controller neu booten, um die Konfiguration zu ändern. |
-
Konfigurieren Sie ONTAP für den Betrieb von IOD oder OOD von Frames.
-
Standardmäßig ist IOD von Frames in ONTAP aktiviert. So prüfen Sie die Konfigurationsdetails:
-
Erweiterten Modus aufrufen:
set advanced -
Überprüfen Sie die Einstellungen:
metrocluster interconnect adapter show
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
-
Die folgenden Schritte müssen auf jedem Knoten ausgeführt werden, um OOD von Frames zu konfigurieren:
-
Erweiterten Modus aufrufen:
set advanced -
Überprüfen Sie die MetroCluster-Konfigurationseinstellungen:
metrocluster interconnect adapter showmcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
OOD auf Knoten „
mcc4-b1“ und Knoten „mcc4-b2“ aktivieren:metrocluster interconnect adapter modify -node node_name -is-ood-enabled true
mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b1 -is-ood-enabled true mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b2 -is-ood-enabled true
-
Starten Sie den Controller neu, indem Sie in beide Richtungen eine HA-Übernahme durchführen.
-
Überprüfen Sie die Einstellungen:
metrocluster interconnect adapter show
-
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up true 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up true 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up true 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up true 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
Konfigurieren von SNMPv3 in einer MetroCluster FC-Konfiguration
Die Authentifizierungs- und Datenschutzprotokolle auf den Switches und auf dem ONTAP System müssen identisch sein.
ONTAP unterstützt derzeit AES-128 für die Verschlüsselung (Privacy) und SHA-256 für die Authentifizierung.
|
|
|
-
Erstellen Sie einen SNMP-Benutzer für jeden Switch von der Controller-Eingabeaufforderung:
security login createController_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10.10.10.10
-
Beantworten Sie bei Bedarf an Ihrem Standort die folgenden Fragen:
Drücken Sie für EngineID die Eingabetaste, um den Standardwert zuzuweisen. Enter the authoritative entity's EngineID [remote EngineID]: Which authentication protocol do you want to choose (none, md5, sha, sha2-256) [none]: sha Enter the authentication protocol password (minimum 8 characters long): Enter the authentication protocol password again: Which privacy protocol do you want to choose (none, des, aes128) [none]: aes128 Enter privacy protocol password (minimum 8 characters long): Enter privacy protocol password again:
Derselbe Benutzername kann zu verschiedenen Switches mit unterschiedlichen IP-Adressen hinzugefügt werden. -
Erstellen Sie einen SNMP-Benutzer für den Rest der Switches.
Das folgende Beispiel zeigt, wie ein Benutzername für einen Switch mit der IP-Adresse 10.10.10.11 erstellt wird.
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10. 10.10.11
-
Überprüfen Sie, ob für jeden Switch ein Anmeldeeintrag vorhanden ist:
security login showController_A_1::> security login show -user-or-group-name snmpv3user -fields remote-switch-ipaddress vserver user-or-group-name application authentication-method remote-switch-ipaddress ------------ ------------------ ----------- --------------------- ----------------------- node_A_1 SVM 1 snmpv3user snmp usm 10.10.10.10 node_A_1 SVM 2 snmpv3user snmp usm 10.10.10.11 node_A_1 SVM 3 snmpv3user snmp usm 10.10.10.12 node_A_1 SVM 4 snmpv3user snmp usm 10.10.10.13 4 entries were displayed.
-
Konfigurieren Sie SNMPv3 an den Switches über die Switch-Eingabeaufforderung:
Brocade Switches (FOS 9.x)snmpconfig --add snmpv3 -index <index> -user <user_name> -groupname <rw/ro> -auth_proto <auth_protocol> -auth_passwd <auth_password> -priv_proto <priv_protocol> -priv_passwd <priv_password>Brocade -Switches (FOS 8.x und früher)snmpconfig --set snmpv3Das Beispiel zeigt, wie ein schreibgeschützter Benutzer konfiguriert wird. Sie können die RW-Benutzer bei Bedarf anpassen. Wenn Sie RO-Zugriff benötigen, geben Sie nach „Benutzer (ro):“ den „snmpv3user“ an.
Switch-A1:admin> snmpconfig --set snmpv3 SNMP Informs Enabled (true, t, false, f): [false] true SNMPv3 user configuration(snmp user not configured in FOS user database will have physical AD and admin role as the default): User (rw): [snmpadmin1] Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [3] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [2] Engine ID: [00:00:00:00:00:00:00:00:00] User (ro): [snmpuser2] snmpv3user Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [2] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [3]
Cisco Switchessnmp-server user <user_name> auth [md5/sha/sha-256] <auth_password> priv (aes-128) <priv_password>
Sie sollten auch Passwörter für nicht verwendete Konten festlegen, um diese zu sichern und die beste in Ihrer ONTAP-Version verfügbare Verschlüsselung zu verwenden. -
Konfigurieren Sie die Verschlüsselung und Passwörter für die übrigen Switch-Benutzer nach Bedarf an Ihrem Standort.
Konfigurieren von MetroCluster Komponenten für das Monitoring des Systemzustands
Sie müssen einige spezielle Konfigurationsschritte durchführen, bevor Sie die Komponenten einer MetroCluster-Konfiguration überwachen.
|
|
Zur Verbesserung der Sicherheit empfiehlt NetApp, SNMPv2 oder SNMPv3 zur Überwachung des Switch-Zustands zu konfigurieren. |
Diese Aufgaben gelten nur für Systeme mit FC-to-SAS-Bridges.
Ab Fabric OS 9.0.1 wird SNMPv2 für die Zustandsüberwachung auf Brocade Switches nicht unterstützt, stattdessen ist SNMPv3 zu verwenden. Bei Verwendung von SNMPv3 ist SNMPv3 in ONTAP zu konfigurieren, bevor mit dem folgenden Abschnitt fortgefahren wird. Weitere Details finden sich unter Konfigurieren von SNMPv3 in einer MetroCluster FC-Konfiguration.
|
|
|
NetApp unterstützt nur die folgenden Tools zur Überwachung der Komponenten in einer MetroCluster FC-Konfiguration:
-
Brocade Network Advisor (BNA)
-
Brocade Sannav
-
Active IQ Config Advisor
-
NetApp Zustandsüberwachung (ONTAP)
-
MetroCluster-Datensammler (MC_DC)
Konfigurieren von MetroCluster FC-Switches für das Monitoring des Systemzustands
In einer Fabric-Attached MetroCluster-Konfiguration müssen Sie einige zusätzliche Konfigurationsschritte durchführen, um die FC-Switches zu überwachen.
|
|
Ab ONTAP 9.8 wird der storage switch Befehl durch ersetzt system switch fibre-channel. Im Folgenden wird der Befehl angezeigt storage switch. Wenn Sie jedoch ONTAP 9.8 oder höher ausführen, ist der system switch fibre-channel Befehl bevorzugt.
|
-
Fügen Sie jedem MetroCluster-Knoten einen Switch mit einer IP-Adresse hinzu:
Der Befehl, den Sie ausführen, hängt davon ab, ob Sie SNMPv2 oder SNMPv3 verwenden.
Switch mit SNMPv3 hinzufügen:storage switch add -address <ip_adddress> -snmp-version SNMPv3 -snmp-community-or-username <SNMP_user_configured_on_the_switch>Switch mit SNMPv2 hinzufügen:storage switch add -address ipaddressDieser Befehl muss bei allen vier Switches der MetroCluster-Konfiguration wiederholt werden.
Brocade 7840 FC-Switches und alle Warnmeldungen werden in der Statusüberwachung unterstützt, außer NoISLPresent_Alert. Das folgende Beispiel zeigt den Befehl zum Hinzufügen eines Switches mit der IP-Adresse 10.10.10.10:
controller_A_1::> storage switch add -address 10.10.10.10
-
Überprüfen Sie, ob alle Switches richtig konfiguriert sind:
storage switch showEs kann bis zu 15 Minuten dauern, bis alle Daten aufgrund des 15-minütigen Abrufintervalls reflektiert werden.
Im folgenden Beispiel wird der Befehl angezeigt, der zur Überprüfung der Konfiguration der MetroCluster FC-Switches gegeben wurde:
controller_A_1::> storage switch show Fabric Switch Name Vendor Model Switch WWN Status ---------------- --------------- ------- ------------ ---------------- ------ 1000000533a9e7a6 brcd6505-fcs40 Brocade Brocade6505 1000000533a9e7a6 OK 1000000533a9e7a6 brcd6505-fcs42 Brocade Brocade6505 1000000533d3660a OK 1000000533ed94d1 brcd6510-fcs44 Brocade Brocade6510 1000000533eda031 OK 1000000533ed94d1 brcd6510-fcs45 Brocade Brocade6510 1000000533ed94d1 OK 4 entries were displayed. controller_A_1::>
Wenn der weltweite Name (WWN) des Switches angezeigt wird, kann die ONTAP-Systemzustandsüberwachung den FC-Switch kontaktieren und überwachen.
Konfiguration von FC-to-SAS-Bridges für das Monitoring des Systemzustands
Bei Systemen mit ONTAP-Versionen vor 9.8 müssen Sie einige besondere Konfigurationsschritte durchführen, um die FC-zu-SAS-Bridges in der MetroCluster-Konfiguration zu überwachen.
-
SNMP-Überwachungstools anderer Anbieter werden für FibreBridge-Brücken nicht unterstützt.
-
Ab ONTAP 9.8 werden FC-to-SAS-Bridges standardmäßig über in-Band-Verbindungen überwacht, keine zusätzliche Konfiguration erforderlich.
|
|
Ab ONTAP 9.8 beginnt der storage bridge Befehl wird durch ersetzt system bridge. Die folgenden Schritte zeigen das storage bridge Befehl, aber wenn Sie ONTAP 9.8 oder höher ausführen, der system bridge Befehl ist bevorzugt.
|
-
Fügen Sie von der ONTAP Cluster-Eingabeaufforderung die Bridge zur Statusüberwachung hinzu:
-
Fügen Sie die Bridge mit dem Befehl für Ihre ONTAP-Version hinzu:
ONTAP-Version
Befehl
9.5 und höher
storage bridge add -address 0.0.0.0 -managed-by in-band -name bridge-name9.4 und früher
storage bridge add -address bridge-ip-address -name bridge-name -
Überprüfen Sie, ob die Bridge hinzugefügt und richtig konfiguriert wurde:
storage bridge showEs kann bis zu 15 Minuten dauern, bis alle Daten aufgrund des Abrufintervalls reflektiert wurden. Die ONTAP Systemzustandsüberwachung kann die Brücke kontaktieren und überwachen, wenn der Wert in der Spalte „Status“ „ok“ lautet und weitere Informationen, z. B. der weltweite Name (WWN), angezeigt werden.
Das folgende Beispiel zeigt, dass die FC-to-SAS-Bridges konfiguriert sind:
controller_A_1::> storage bridge show Bridge Symbolic Name Is Monitored Monitor Status Vendor Model Bridge WWN ------------------ ------------- ------------ -------------- ------ ----------------- ---------- ATTO_10.10.20.10 atto01 true ok Atto FibreBridge 7500N 20000010867038c0 ATTO_10.10.20.11 atto02 true ok Atto FibreBridge 7500N 20000010867033c0 ATTO_10.10.20.12 atto03 true ok Atto FibreBridge 7500N 20000010867030c0 ATTO_10.10.20.13 atto04 true ok Atto FibreBridge 7500N 2000001086703b80 4 entries were displayed controller_A_1::>
-
Überprüfen der MetroCluster-Konfiguration
Sie können überprüfen, ob die Komponenten und Beziehungen in der MetroCluster Konfiguration ordnungsgemäß funktionieren.
Nach der Erstkonfiguration und nach sämtlichen Änderungen an der MetroCluster-Konfiguration sollten Sie einen Check durchführen. Sie sollten auch vor einer ausgehandelten (geplanten) Umschaltung oder einem Switchback prüfen.
Wenn der metrocluster check run Befehl wird zweimal innerhalb kürzester Zeit auf einem oder beiden Clustern ausgegeben. Ein Konflikt kann auftreten, und der Befehl erfasst möglicherweise nicht alle Daten. Danach metrocluster check show Befehle, dann wird die erwartete Ausgabe nicht angezeigt.
-
Überprüfen Sie die Konfiguration:
metrocluster check runDer Befehl wird als Hintergrundjob ausgeführt und wird möglicherweise nicht sofort ausgeführt.
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
Zeigen Sie detailliertere Ergebnisse der letzten Zeit an
metrocluster check runBefehl:metrocluster check aggregate showmetrocluster check cluster showmetrocluster check config-replication showmetrocluster check lif showmetrocluster check node show
Der metrocluster check showBefehle zeigen die Ergebnisse der letztenmetrocluster check runBefehl. Sie sollten immer den ausführenmetrocluster check runBefehl vor Verwendung desmetrocluster check showBefehle, sodass die angezeigten Informationen aktuell sind.Das folgende Beispiel zeigt die
metrocluster check aggregate showBefehlsausgabe für eine gesunde MetroCluster Konfiguration mit vier Nodes:cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.Das folgende Beispiel zeigt die
metrocluster check cluster showBefehlsausgabe für eine gesunde MetroCluster Konfiguration mit vier Nodes. Sie zeigt an, dass die Cluster bei Bedarf bereit sind, eine ausgehandelte Umschaltung durchzuführen.Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Überprüfen auf MetroCluster-Konfigurationsfehler mit Config Advisor
Sie können die NetApp Support-Website besuchen und das Config Advisor-Tool herunterladen, um häufige Konfigurationsfehler zu überprüfen.
Config Advisor ist ein Tool zur Konfigurationsvalidierung und Statusüberprüfung. Sie können die Lösung sowohl an sicheren Standorten als auch an nicht sicheren Standorten zur Datenerfassung und Systemanalyse einsetzen.
|
|
Der Support für Config Advisor ist begrenzt und steht nur online zur Verfügung. |
-
Rufen Sie die Config Advisor Download-Seite auf und laden Sie das Tool herunter.
-
Führen Sie Config Advisor aus, überprüfen Sie die Ausgabe des Tools und folgen Sie den Empfehlungen in der Ausgabe, um erkannte Probleme zu beheben.
Überprüfen des lokalen HA-Vorgangs
Wenn Sie über eine MetroCluster Konfiguration mit vier Nodes verfügen, sollten Sie den Betrieb der lokalen HA-Paare in der MetroCluster Konfiguration überprüfen. Dies ist nicht für Konfigurationen mit zwei Nodes erforderlich.
MetroCluster-Konfigurationen mit zwei Nodes bestehen nicht aus lokalen HA-Paaren, und diese Aufgabe gilt nicht.
In den Beispielen für diese Aufgabe werden standardmäßige Namenskonventionen verwendet:
-
Cluster_A
-
Controller_A_1
-
Controller_A_2
-
-
Cluster_B
-
Controller_B_1
-
Controller_B_2
-
-
Führen Sie auf Cluster_A Failover und Giveback in beide Richtungen durch.
-
Vergewissern Sie sich, dass Storage-Failover aktiviert ist:
storage failover showDie Ausgabe sollte darauf hinweisen, dass ein Takeover für beide Knoten möglich ist:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed. -
Übernehmen Sie Controller_A_2 von Controller_A_1:
storage failover takeover controller_A_2Sie können das verwenden
storage failover show-takeoverBefehl zum Überwachen des Fortschritts des Übernahmvorgangs. -
Bestätigen Sie, dass der Takeover abgeschlossen ist:
storage failover showDie Ausgabe sollte angeben, dass Controller_A_1 sich im Übernahmemodus befindet, was bedeutet, dass sie seinen HA-Partner übernommen hat:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ----------------- controller_A_1 controller_A_2 false In takeover controller_A_2 controller_A_1 - Unknown 2 entries were displayed. -
Controller_A_2 zurückgeben:
storage failover giveback controller_A_2Sie können das verwenden
storage failover show-givebackBefehl zum Überwachen des Fortschritts für den Giveback-Vorgang -
Bestätigen Sie, dass der Speicher-Failover wieder in einen normalen Status zurückkehrt:
storage failover showDie Ausgabe sollte darauf hinweisen, dass ein Takeover für beide Knoten möglich ist:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed.-
Wiederholen Sie die vorherigen Teilschritte, und dieses Mal wird Controller_A_1 von Controller_A_2 verwendet.
-
-
Wiederholen Sie die vorherigen Schritte auf Cluster_B.
Überprüfung von Umschaltung, Reparatur und Wechsel zurück
Sie sollten die Umschalttavorgänge, die Reparatur und den Wechsel der MetroCluster Konfiguration überprüfen.
-
Verwenden Sie die im genannten Verfahren für die ausgehandelte Umschaltung, die Reparatur und den Wechsel zurück "Nach einem Ausfall wiederherstellen".
Sichern von Backup-Dateien der Konfiguration
Sie können einen zusätzlichen Schutz für die Backup-Dateien der Clusterkonfiguration bieten, indem Sie eine Remote-URL (entweder HTTP oder FTP) angeben, bei der die Backup-Dateien der Konfiguration zusätzlich zu den Standardstandorten im lokalen Cluster hochgeladen werden.
-
Legen Sie die URL des Remote-Ziels für die Backup-Dateien der Konfiguration fest:
system configuration backup settings modify URL-of-destinationDer "Cluster-Management mit der CLI" Enthält zusätzliche Informationen unter dem Abschnitt Verwalten von Konfigurations-Backups.