

Ersetzen Sie das NVRAM-Modul oder die NVRAM-DIMMs – FAS9000
 Änderungen vorschlagen
Änderungen vorschlagen
Das NVRAM Modul besteht aus NVRAM10 und DIMMs und bis zu zwei NVMe SSD Flash Cache Modulen (Flash Cache oder Caching-Module) pro NVRAM Modul. Ein ausgefallenes NVRAM-Modul oder die DIMMs im NVRAM-Modul können Sie ersetzen.
Um ein ausgefallenes NVRAM-Modul zu ersetzen, müssen Sie es aus dem Gehäuse entfernen, das Flash Cache Modul oder die Flash Cache Module aus dem NVRAM Modul entfernen, die DIMMs auf das Ersatzmodul verschieben, das Flash Cache Modul oder die Flash Cache Module wieder einsetzen und das Ersatz-NVRAM-Modul ins Gehäuse einsetzen.
Da die System-ID vom NVRAM-Modul abgeleitet wird, werden beim Ersetzen des Moduls Festplatten, die zum System gehören, der neuen System-ID neu zugewiesen.
-
Alle Platten-Shelves müssen ordnungsgemäß funktionieren.
-
Wenn sich Ihr System in einem HA-Paar befindet, muss der Partner-Node in der Lage sein, den Node, der dem zu ersetzenden NVRAM-Modul zugeordnet ist, zu übernehmen.
-
Bei diesem Verfahren wird die folgende Terminologie verwendet:
-
Der Node Impared ist der Knoten, auf dem Sie Wartungsarbeiten durchführen.
-
Der Node Healthy ist der HA-Partner des Node mit beeinträchtigten Störungen.
-
-
Dieses Verfahren umfasst Schritte zur automatischen oder manuellen Neuzuteilung von Festplatten an das Controller-Modul, das dem neuen NVRAM-Modul zugeordnet ist. Sie müssen die Festplatten neu zuweisen, wenn Sie dazu aufgefordert werden. Das Ausfüllen der Neuzuweisung von Festplatte vor dem Giveback kann Probleme verursachen.
-
Sie müssen die fehlerhafte Komponente durch eine vom Anbieter empfangene Ersatz-FRU-Komponente ersetzen.
-
Im Rahmen dieses Verfahrens können Festplatten oder Platten-Shelfs nicht geändert werden.
Schritt 1: Schalten Sie den beeinträchtigten Regler aus
Fahren Sie den Regler herunter oder übernehmen Sie ihn mit einer der folgenden Optionen.
Übernehmen Sie den fehlerhaften Controller und stoppen Sie ihn, damit der intakte Controller weiterhin Daten aus dem Speicher des fehlerhaften Controllers bereitstellt. Dazu unterdrücken Sie die automatische Fallerstellung in AutoSupport, deaktivieren die automatische Rückgabe und bringen den fehlerhaften Controller zur LOADER-Eingabeaufforderung. Die LOADER-Eingabeaufforderung ist der sichere, angehaltene Zustand, aus dem Sie die FRU ersetzen können.
-
Wenn Sie über ein SAN-System verfügen, müssen Sie Event-Meldungen ) für den beeinträchtigten Controller SCSI Blade überprüft haben
cluster kernel-service show. Mit demcluster kernel-service showBefehl (im erweiterten Modus von priv) werden der Knotenname, der Node, der Verfügbarkeitsstatus dieses Node und der Betriebsstatus dieses Node angezeigt"Quorum-Status".Jeder Prozess des SCSI-Blades sollte sich im Quorum mit den anderen Nodes im Cluster befinden. Probleme müssen behoben werden, bevor Sie mit dem Austausch fortfahren.
-
Wenn Sie über ein Cluster mit mehr als zwei Nodes verfügen, muss es sich im Quorum befinden. Wenn sich das Cluster nicht im Quorum befindet oder ein gesunder Controller FALSE anzeigt, um die Berechtigung und den Zustand zu erhalten, müssen Sie das Problem korrigieren, bevor Sie den beeinträchtigten Controller herunterfahren; siehe "Synchronisieren eines Node mit dem Cluster".
-
Wenn AutoSupport aktiviert ist, unterdrücken Sie die automatische Erstellung eines Cases durch Aufrufen einer AutoSupport Meldung:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hDies verhindert, dass während Ihres geplanten Wartungsfensters automatisch Supportfälle eröffnet werden. Die maximale Unterdrückungsdauer beträgt 72 Stunden. Falls Ihre Wartung vorzeitig abgeschlossen ist, können Sie die Fallerstellung wieder aktivieren, indem Sie eine AutoSupport-Nachricht mit
MAINT=ENDauslösen. Weitere Informationen finden Sie unter "Wie man die automatische Fallerstellung während geplanter Wartungsfenster unterdrückt".Die folgende AutoSupport Meldung unterdrückt die automatische Erstellung von Cases für zwei Stunden:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Automatische Rückgabe deaktivieren:
-
Geben Sie den folgenden Befehl von der Konsole des fehlerfreien Controllers ein:
storage failover modify -node impaired_node_name -auto-giveback false -
Eingeben
ywenn die Eingabeaufforderung Möchten Sie die automatische Rückgabe deaktivieren? angezeigt wird
-
-
Nehmen Sie den beeinträchtigten Controller zur LOADER-Eingabeaufforderung:
Wenn der eingeschränkte Controller angezeigt wird… Dann… Die LOADER-Eingabeaufforderung
Fahren Sie mit dem nächsten Schritt fort.
Warten auf Giveback…
Drücken Sie Strg-C, und antworten Sie dann
yWenn Sie dazu aufgefordert werden.Eingabeaufforderung für das System oder Passwort
Übernehmen oder stoppen Sie den beeinträchtigten Regler von der gesunden Steuerung:
storage failover takeover -ofnode impaired_node_name -halt trueDer Parameter -stop true führt Sie zur Loader-Eingabeaufforderung.
Um den beeinträchtigten Controller herunterzufahren, müssen Sie den Status des Controllers bestimmen und gegebenenfalls den Controller umschalten, damit der gesunde Controller weiterhin Daten aus dem beeinträchtigten Reglerspeicher bereitstellen kann.
-
Sie müssen die Netzteile am Ende dieses Verfahrens einschalten, um den gesunden Controller mit Strom zu versorgen.
-
Überprüfen Sie den MetroCluster-Status, um festzustellen, ob der beeinträchtigte Controller automatisch auf den gesunden Controller umgeschaltet wurde:
metrocluster show -
Je nachdem, ob eine automatische Umschaltung stattgefunden hat, fahren Sie mit der folgenden Tabelle fort:
Wenn die eingeschränkte Steuerung… Dann… Ist automatisch umgeschaltet
Fahren Sie mit dem nächsten Schritt fort.
Nicht automatisch umgeschaltet
Einen geplanten Umschaltvorgang vom gesunden Controller durchführen:
metrocluster switchoverHat nicht automatisch umgeschaltet, haben Sie versucht, mit dem zu wechseln
metrocluster switchoverBefehl und Switchover wurde vetoedÜberprüfen Sie die Veto-Meldungen, und beheben Sie das Problem, wenn möglich, und versuchen Sie es erneut. Wenn das Problem nicht behoben werden kann, wenden Sie sich an den technischen Support.
-
Synchronisieren Sie die Datenaggregate neu, indem Sie das ausführen
metrocluster heal -phase aggregatesBefehl aus dem verbleibenden Cluster.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Wenn die Heilung ein Vetorecht ist, haben Sie die Möglichkeit, das zurückzugeben
metrocluster healBefehl mit dem-override-vetoesParameter. Wenn Sie diesen optionalen Parameter verwenden, überschreibt das System alle weichen Vetos, die die Heilung verhindern. -
Überprüfen Sie, ob der Vorgang mit dem befehl „MetroCluster Operation show“ abgeschlossen wurde.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Überprüfen Sie den Status der Aggregate mit
storage aggregate showBefehl.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Heilen Sie die Root-Aggregate mit dem
metrocluster heal -phase root-aggregatesBefehl.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Wenn die Heilung ein Vetorecht ist, haben Sie die Möglichkeit, das zurückzugeben
metrocluster healBefehl mit dem Parameter -override-vetoes. Wenn Sie diesen optionalen Parameter verwenden, überschreibt das System alle weichen Vetos, die die Heilung verhindern. -
Stellen Sie sicher, dass der Heilungsvorgang abgeschlossen ist, indem Sie den verwenden
metrocluster operation showBefehl auf dem Ziel-Cluster:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
Trennen Sie am Controller-Modul mit eingeschränkter Betriebsstörung die Netzteile.
Schritt 2: Ersetzen Sie das NVRAM-Modul
Zum Austauschen des NVRAM-Moduls suchen Sie es in Steckplatz 6 im Chassis und befolgen die spezifische Sequenz von Schritten.
-
Wenn Sie nicht bereits geerdet sind, sollten Sie sich richtig Erden.
-
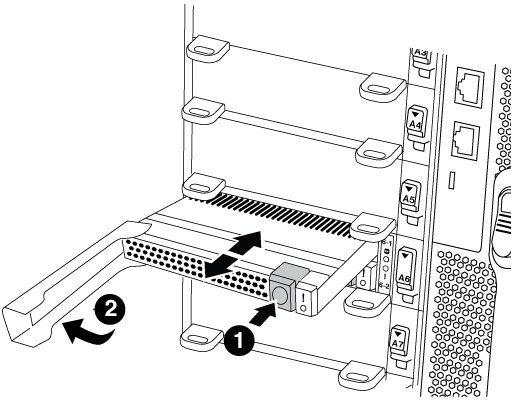
Verschieben Sie das Flash Cache Modul aus dem alten NVRAM Modul in das neue NVRAM Modul:

Orangefarbene Entriegelungstaste (grau bei leeren Flash Cache Modulen)

Flash Cache Nockengriff
-
Drücken Sie die orangefarbene Taste auf der Vorderseite des Flash Cache Moduls.

Die Entriegelungstaste an leeren Flash Cache Modulen ist grau dargestellt. -
Drehen Sie den Nockengriff heraus, bis das Modul beginnt, aus dem alten NVRAM-Modul zu schieben.
-
Fassen Sie den Nockengriff des Moduls an, und schieben Sie ihn aus dem NVRAM-Modul und setzen Sie ihn an die Vorderseite des neuen NVRAM-Moduls.
-
Schieben Sie das Flash Cache-Modul vorsichtig in das NVRAM-Modul, und schwenken Sie den Nockengriff dann zu, bis das Modul einrastet.
-
-
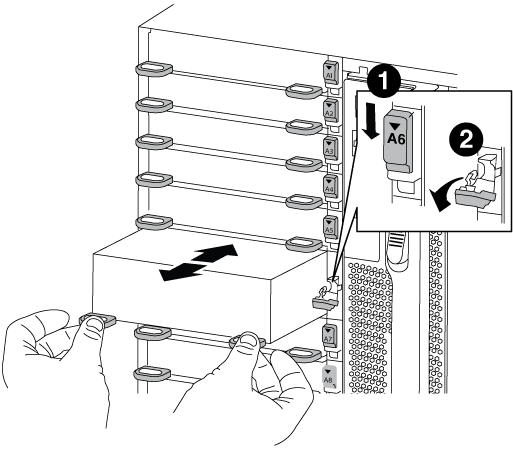
Entfernen des Ziel-NVRAM-Moduls aus dem Chassis:
-
Drücken Sie die Taste mit der Nummerierung und dem Buchstaben.
Die Nockentaste bewegt sich vom Gehäuse weg.
-
Drehen Sie die Nockenverriegelung nach unten, bis sie sich in horizontaler Position befindet.
Das NVRAM-Modul geht aus dem Chassis heraus und bewegt sich einige Zentimeter heraus.
-
Entfernen Sie das NVRAM-Modul aus dem Gehäuse, indem Sie an den Zuglaschen an den Seiten der Modulfläche ziehen.
Gerettete und nummerierte E/A-Nockenverriegelung
E/A-Riegel vollständig entriegelt
-
-
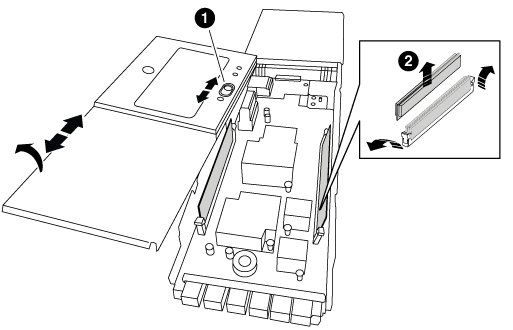
Setzen Sie das NVRAM-Modul auf eine stabile Fläche und entfernen Sie die Abdeckung vom NVRAM-Modul, indem Sie die blaue Verriegelungstaste auf der Abdeckung nach unten drücken und dann, während Sie die blaue Taste gedrückt halten, den Deckel aus dem NVRAM-Modul schieben.
Verriegelungsknopf für die Abdeckung
DIMM- und DIMM-Auswurfklammern
-
Entfernen Sie nacheinander die DIMMs aus dem alten NVRAM-Modul und installieren Sie sie im ErsatzNVRAM-Modul.
-
Schließen Sie die Abdeckung am Modul.
-
Installieren Sie das Ersatz-NVRAM-Modul in das Chassis:
-
Richten Sie das Modul an den Kanten der Gehäuseöffnung in Steckplatz 6 aus.
-
Schieben Sie das Modul vorsichtig in den Steckplatz, bis der vorletzte und nummerierte E/A-Nockenriegel mit dem E/A-Nockenstift einrastet. Drücken Sie dann die E/A-Nockenverriegelung ganz nach oben, um das Modul zu verriegeln.
-
Schritt 3: Ersetzen Sie ein NVRAM-DIMM
Um NVRAM-DIMMs im NVRAM-Modul zu ersetzen, müssen Sie das NVRAM-Modul entfernen, das Modul öffnen und dann das Ziel-DIMM ersetzen.
-
Wenn Sie nicht bereits geerdet sind, sollten Sie sich richtig Erden.
-
Entfernen des Ziel-NVRAM-Moduls aus dem Chassis:
-
Drücken Sie die Taste mit der Nummerierung und dem Buchstaben.
Die Nockentaste bewegt sich vom Gehäuse weg.
-
Drehen Sie die Nockenverriegelung nach unten, bis sie sich in horizontaler Position befindet.
Das NVRAM-Modul geht aus dem Chassis heraus und bewegt sich einige Zentimeter heraus.
-
Entfernen Sie das NVRAM-Modul aus dem Gehäuse, indem Sie an den Zuglaschen an den Seiten der Modulfläche ziehen.
Gerettete und nummerierte E/A-Nockenverriegelung
E/A-Riegel vollständig entriegelt
-
-
Setzen Sie das NVRAM-Modul auf eine stabile Fläche und entfernen Sie die Abdeckung vom NVRAM-Modul, indem Sie die blaue Verriegelungstaste auf der Abdeckung nach unten drücken und dann, während Sie die blaue Taste gedrückt halten, den Deckel aus dem NVRAM-Modul schieben.
Verriegelungsknopf für die Abdeckung
DIMM- und DIMM-Auswurfklammern
-
Suchen Sie das DIMM, das im NVRAM-Modul ausgetauscht werden soll, und entfernen Sie es, indem Sie die DIMM-Verriegelungslaschen nach unten drücken und das DIMM aus dem Sockel heben.
-
Installieren Sie das ErsatzDIMM, indem Sie das DIMM-Modul am Sockel ausrichten und das DIMM vorsichtig in den Sockel schieben, bis die Verriegelungslaschen einrasten.
-
Schließen Sie die Abdeckung am Modul.
-
Installieren Sie das Ersatz-NVRAM-Modul in das Chassis:
-
Richten Sie das Modul an den Kanten der Gehäuseöffnung in Steckplatz 6 aus.
-
Schieben Sie das Modul vorsichtig in den Steckplatz, bis der vorletzte und nummerierte E/A-Nockenriegel mit dem E/A-Nockenstift einrastet. Drücken Sie dann die E/A-Nockenverriegelung ganz nach oben, um das Modul zu verriegeln.
-
Schritt 4: Starten Sie den Controller nach dem FRU-Austausch neu
Nachdem Sie die FRU ersetzt haben, müssen Sie das Controller-Modul neu booten.
-
Um ONTAP von der LOADER-Eingabeaufforderung zu booten, geben Sie ein
bye.
Schritt 5: Festplatten neu zuweisen
Je nachdem, ob Sie über ein HA-Paar oder eine MetroCluster Konfiguration mit zwei Nodes verfügen, müssen Sie entweder die Neuzuweisung von Festplatten an das neue Controller-Modul überprüfen oder die Festplatten manuell neu zuweisen.
Wählen Sie eine der folgenden Optionen aus, um Anweisungen zur Neuzuweisung von Laufwerken an den neuen Controller zu erhalten.
Sie müssen die Änderung der System-ID beim Booten des Node Replacement bestätigen und anschließend überprüfen, ob die Änderung implementiert wurde.

|
Eine Neuzuweisung der Festplatte ist nur erforderlich, wenn das NVRAM-Modul ersetzt wird. Dies gilt nicht für den Austausch des NVRAM-DIMM. |
-
Wenn sich der Ersatz-Node im Wartungsmodus befindet (zeigt das an
*>Eingabeaufforderung, beenden Sie den Wartungsmodus und gehen Sie zur LOADER-Eingabeaufforderung:halt -
Booten Sie an der LOADER-Eingabeaufforderung beim Ersatz-Node den Node und geben Sie ein
yWenn Sie aufgrund einer nicht übereinstimmenden System-ID aufgefordert werden, die System-ID außer Kraft zu setzen.boot_ontap byeDer Node wird neu gebootet, wenn Autoboot festgelegt ist.
-
Warten Sie, bis der
Waiting for giveback…Die Meldung wird auf der Konsole „Replacement Node“ angezeigt und anschließend vom gesunden Node aus überprüfen, ob die neue Partner-System-ID automatisch zugewiesen wurde:storage failover showIn der Befehlsausgabe sollte eine Meldung angezeigt werden, dass sich die System-ID auf dem Knoten „beeinträchtigt“ geändert hat und die korrekten alten und neuen IDs angezeigt werden. Im folgenden Beispiel wurde node2 ersetzt und hat eine neue System-ID von 151759706.
node1> `storage failover show` Takeover Node Partner Possible State Description ------------ ------------ -------- ------------------------------------- node1 node2 false System ID changed on partner (Old: 151759755, New: 151759706), In takeover node2 node1 - Waiting for giveback (HA mailboxes) -
Vergewissern Sie sich am gesunden Knoten, dass alle Corestapy gespeichert sind:
-
Ändern Sie die erweiterte Berechtigungsebene:
set -privilege advancedSie können antworten
YWenn Sie aufgefordert werden, den erweiterten Modus fortzusetzen. Die Eingabeaufforderung für den erweiterten Modus wird angezeigt (*>). -
Speichern von CoreDumps:
system node run -node local-node-name partner savecore -
Warten Sie, bis der Befehl `savecore`abgeschlossen ist, bevor Sie das Giveback ausgeben.
Sie können den folgenden Befehl eingeben, um den Fortschritt des Befehls savecore zu überwachen:
system node run -node local-node-name partner savecore -s -
Zurück zur Administratorberechtigungsebene:
set -privilege admin
-
-
Geben Sie den Knoten zurück:
-
Geben Sie vom ordnungsgemäßen Node den Speicher des ersetzten Node wieder:
storage failover giveback -ofnode replacement_node_nameDer Node Replacement nimmt seinen Storage wieder ein und schließt den Booten ab.
Wenn Sie aufgrund einer nicht übereinstimmenden System-ID aufgefordert werden, die System-ID außer Kraft zu setzen, sollten Sie eingeben
y.
Wenn das Rückübertragung ein Vetorecht ist, können Sie erwägen, das Vetos außer Kraft zu setzen.
-
Nachdem das Giveback abgeschlossen ist, bestätigen Sie, dass das HA-Paar sich gesund befindet und ein Takeover möglich ist:
storage failover showDie Ausgabe von der
storage failover showDer Befehl sollte nicht enthaltenSystem ID changed on partnerNachricht:
-
-
Überprüfen Sie, ob die Festplatten ordnungsgemäß zugewiesen wurden:
storage disk show -ownershipDie Festplatten, die zum Node Replacement gehören, sollten die neue System-ID anzeigen. Im folgenden Beispiel zeigen die Festplatten von node1 jetzt die neue System-ID, 1873775277:
node1> `storage disk show -ownership` Disk Aggregate Home Owner DR Home Home ID Owner ID DR Home ID Reserver Pool ----- ------ ----- ------ -------- ------- ------- ------- --------- --- 1.0.0 aggr0_1 node1 node1 - 1873775277 1873775277 - 1873775277 Pool0 1.0.1 aggr0_1 node1 node1 1873775277 1873775277 - 1873775277 Pool0 . . .
-
Wenn sich das System in einer MetroCluster-Konfiguration befindet, überwachen Sie den Status des Node:
metrocluster node showDie MetroCluster-Konfiguration dauert einige Minuten nach dem Austausch und kehrt in den normalen Zustand zurück. Zu diesem Zeitpunkt zeigt jeder Node einen konfigurierten Status mit aktivierter DR-Spiegelung und einem normalen Modus. Der
metrocluster node show -fields node-systemidIn der Befehlsausgabe wird die alte System-ID angezeigt, bis die MetroCluster-Konfiguration den normalen Status aufweist. -
Wenn sich der Node abhängig vom MetroCluster-Status in einer MetroCluster-Konfiguration befindet, vergewissern Sie sich, dass im Feld für die DR-Home-ID der ursprüngliche Eigentümer der Festplatte angezeigt wird, wenn der ursprüngliche Eigentümer ein Node am Disaster-Standort ist.
Dies ist erforderlich, wenn beide der folgenden Werte erfüllt sind:
-
Die MetroCluster Konfiguration befindet sich in einem Switchover-Zustand.
-
Der Node Replacement ist der aktuelle Besitzer der Festplatten am Disaster-Site.
-
-
Wenn sich Ihr System in einer MetroCluster-Konfiguration befindet, vergewissern Sie sich, dass jeder Node konfiguriert ist:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Vergewissern Sie sich, dass die erwarteten Volumes für jeden Node vorhanden sind:
vol show -node node-name -
Wenn Sie die automatische Übernahme beim Neustart deaktiviert haben, aktivieren Sie sie vom gesunden Knoten:
storage failover modify -node replacement-node-name -onreboot true
Bei einer MetroCluster-Konfiguration mit zwei Knoten, in der ONTAP ausgeführt wird, müssen Sie Festplatten manuell der System-ID des neuen Controllers zuweisen, bevor Sie den normalen Betrieb des Systems zurückgeben.
Dieses Verfahren gilt nur für Systeme in einer MetroCluster-Konfiguration mit zwei Nodes, auf denen ONTAP ausgeführt wird.
Sie müssen sicherstellen, dass Sie die Befehle in diesem Verfahren auf dem richtigen Node eingeben:
-
Der Node Impared ist der Knoten, auf dem Sie Wartungsarbeiten durchführen.
-
Der Node Replacement ist der neue Node, der den beeinträchtigten Knoten im Rahmen dieses Verfahrens ersetzt.
-
Der Node Healthy ist der DR-Partner des beeinträchtigten Knotens.
-
Falls Sie dies noch nicht getan haben, starten Sie den Node Replacement neu, unterbrechen Sie den Bootvorgang, indem Sie eingeben
Ctrl-C, Und wählen Sie dann die Option zum Starten in den Wartungsmodus aus dem angezeigten Menü.Eingabe ist erforderlich
YWenn Sie aufgefordert werden, die System-ID aufgrund einer nicht übereinstimmenden System-ID zu überschreiben. -
Zeigen Sie die alten System-IDs vom gesunden Knoten an:
`metrocluster node show -fields node-systemid,dr-Partner-System`In diesem Beispiel ist der Node_B_1 der alte Node mit der alten System-ID von 118073209:
dr-group-id cluster node node-systemid dr-partner-systemid ----------- --------------------- -------------------- ------------- ------------------- 1 Cluster_A Node_A_1 536872914 118073209 1 Cluster_B Node_B_1 118073209 536872914 2 entries were displayed.
-
Zeigen Sie die neue System-ID an der Eingabeaufforderung für den Wartungsmodus auf dem Knoten „beeinträchtigt“ an:
disk showIn diesem Beispiel lautet die neue System-ID 118065481:
Local System ID: 118065481 ... ... -
Weisen Sie die Festplatteneigentümer (für FAS Systeme) neu zu. Verwenden Sie dabei die System-ID-Informationen, die vom Befehl Disk show abgerufen werden:
disk reassign -s old system IDIm Fall des vorhergehenden Beispiels lautet der Befehl:
disk reassign -s 118073209Sie können antworten
YWenn Sie dazu aufgefordert werden, fortzufahren. -
Überprüfen Sie, ob die Festplatten ordnungsgemäß zugewiesen wurden:
disk show -aVergewissern Sie sich, dass die Festplatten, die zum Node Replacement gehören, die neue System-ID für den Node Replacement anzeigen. Im folgenden Beispiel zeigen die Festplatten von System-1 jetzt die neue System-ID, 118065481:
*> disk show -a Local System ID: 118065481 DISK OWNER POOL SERIAL NUMBER HOME ------- ------------- ----- ------------- ------------- disk_name system-1 (118065481) Pool0 J8Y0TDZC system-1 (118065481) disk_name system-1 (118065481) Pool0 J8Y09DXC system-1 (118065481) . . .
-
Vergewissern Sie sich am gesunden Knoten, dass alle Corestapy gespeichert sind:
-
Ändern Sie die erweiterte Berechtigungsebene:
set -privilege advancedSie können antworten
YWenn Sie aufgefordert werden, den erweiterten Modus fortzusetzen. Die Eingabeaufforderung für den erweiterten Modus wird angezeigt (*>). -
Vergewissern Sie sich, dass die Corestapes gespeichert sind:
system node run -node local-node-name partner savecoreWenn die Befehlsausgabe angibt, dass savecore gerade ist, warten Sie, bis savecore abgeschlossen ist, bevor Sie das Giveback ausgeben. Sie können den Fortschritt des Savecore mit dem überwachen
system node run -node local-node-name partner savecore -s command.</info>. -
Zurück zur Administratorberechtigungsebene:
set -privilege admin
-
-
Wenn sich der Node Replacement im Wartungsmodus befindet (mit der Eingabeaufforderung *>), beenden Sie den Wartungsmodus, und wechseln Sie zur LOADER-Eingabeaufforderung:
halt -
Starten Sie den Node Replacement:
boot_ontap -
Nachdem der Node Replacement vollständig gestartet wurde, führen Sie einen Wechsel zurück durch:
metrocluster switchback -
Überprüfen Sie die MetroCluster Konfiguration:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Überprüfen Sie den Betrieb der MetroCluster-Konfiguration in Data ONTAP:
-
Überprüfen Sie auf beiden Clustern auf Zustandswarnmeldungen:
system health alert show -
Vergewissern Sie sich, dass die MetroCluster konfiguriert ist und sich im normalen Modus befindet:
metrocluster show -
Durchführen einer MetroCluster-Prüfung:
metrocluster check run -
Ergebnisse der MetroCluster-Prüfung anzeigen:
metrocluster check show -
Nutzen Sie Config Advisor. Wechseln Sie zur Config Advisor-Seite auf der NetApp Support Site unter "support.netapp.com/NOW/download/tools/config_advisor/".
Überprüfen Sie nach dem Ausführen von Config Advisor die Ausgabe des Tools und befolgen Sie die Empfehlungen in der Ausgabe, um die erkannten Probleme zu beheben.
-
-
Simulation eines Switchover-Vorgangs:
-
Ändern Sie von der Eingabeaufforderung eines beliebigen Node auf die erweiterte Berechtigungsebene:
set -privilege advancedSie müssen mit reagieren
yWenn Sie dazu aufgefordert werden, den erweiterten Modus fortzusetzen und die Eingabeaufforderung für den erweiterten Modus (*>) anzuzeigen. -
Führen Sie den Wechsel zurück mit dem Parameter -Simulate durch:
metrocluster switchover -simulate -
Zurück zur Administratorberechtigungsebene:
set -privilege admin
-
Schritt 6: Senden Sie das fehlgeschlagene Teil an NetApp zurück
Senden Sie das fehlerhafte Teil wie in den dem Kit beiliegenden RMA-Anweisungen beschrieben an NetApp zurück. "Rückgabe und Austausch von Teilen"Weitere Informationen finden Sie auf der Seite.