

Berichtsoptionen für ein ausgewähltes Cluster
 Änderungen vorschlagen
Änderungen vorschlagen
Erfahren Sie mehr über das Dropdown-Menü Reporting im Seitenfeld:
Kapazität
Auf der Seite Capacity des Dropdown-Menüs Reporting für einen ausgewählten Cluster können Sie Details zum gesamten Clusterspeicherplatz anzeigen, der in Volumes bereitgestellt wird. Kapazitätsinformationen liefern den aktuellen Status und die Prognosen der Storage-Kapazität von Block- und Metadaten für das Cluster. Die entsprechenden Diagramme bieten zusätzliche Methoden zum Analysieren der Cluster-Daten.

|
Informationen zu Schweregraden und Cluster-Fülle finden Sie im "Dokumentation der Element Software". |
Die folgenden Beschreibungen enthalten Details zur Block-Kapazität, Metadaten-Kapazität und dem bereitgestellten Speicherplatz auf dem ausgewählten Cluster.
| Block-Kapazität | ||
|---|---|---|
Überschrift |
Beschreibung |
Prognose |
Genutzte Kapazität |
Aktuell genutzte Kapazität des Cluster Blocks. |
Keine Angabe |
Warnungsschwellenwert |
Der aktuelle Warnschwellenwert. |
Prognose für den Zeitpunkt, an dem der Warnschwellenwert erreicht wird. |
Fehlerschwellenwert |
Der aktuelle Fehlerschwellenwert. |
Prognose für den Zeitpunkt, zu dem der Fehlerschwellenwert erreicht wird. |
Gesamtkapazität |
Die Gesamtkapazität für den Block. |
Prognose für den Zeitpunkt, zu dem der kritische Schwellenwert erreicht wird. |
Aktueller Status |
Aktueller Status des Blocks. |
Weitere Informationen zu Schweregraden finden Sie im "Dokumentation der Element Software". |
Metadaten-Kapazität |
||
Überschrift |
Beschreibung |
|
Genutzte Kapazität |
Die für dieses Cluster verwendete Metadaten-Cluster-Kapazität. |
Gesamtkapazität |
Die gesamte verfügbare Metadaten-Kapazität für diesen Cluster und die Prognose für den kritischen Schwellenwert. |
Aktueller Status |
Der aktuelle Status der Metadaten-Kapazität für dieses Cluster. |
Provisionierter Speicherplatz |
||
Überschrift |
Beschreibung |
|
Provisionierter Speicherplatz |
Die Menge an Speicherplatz, die derzeit im Cluster bereitgestellt wird. |
Max. Bereitgestellter Speicherplatz |
Effizienz
Auf der Efficiency-Seite des Clusters Reporting-Dropdown-Menüs für einen ausgewählten Cluster können Sie Details zu Thin Provisioning, Deduplizierung und Komprimierung auf dem Cluster anzeigen, wenn Sie den Mauszeiger über Datenpunkte im Diagramm bewegen.
|
|
Alle kombinierten Effizienzen werden durch einfaches Vervielfachen der angegebenen Faktorwerte berechnet. |
Die folgenden Beschreibungen enthalten Details zur berechneten Effizienz für das ausgewählte Cluster.
| Überschrift | Beschreibung |
|---|---|
Gesamteffizienz |
Die Effizienz von Thin Provisioning, Deduplizierung und Komprimierung multipliziert sich. Diese Berechnungen berücksichtigen nicht die im System integrierte Doppelhelix-Funktion. |
Deduplizierung und Komprimierung |
Der kombinierte Effekt des eingesparten Speicherplatzes mithilfe von Deduplizierung und Komprimierung. |
Thin Provisioning |
Die durch die Verwendung dieser Funktion eingesparte Menge an Speicherplatz. Diese Zahl gibt das Delta wieder, das zwischen der Kapazität, die dem Cluster zugewiesen ist, und der tatsächlich gespeicherten Datenmenge entspricht. |
Deduplizierung |
Das Verhältnis-Multiplikator der Menge an Speicherplatz, die eingespart wurde, indem keine doppelten Daten im Cluster gespeichert wurden. |
Komprimierung |
Die Auswirkung der Datenkomprimierung auf gespeicherte Daten im Cluster. Die verschiedenen Datentypen komprimieren mit unterschiedlichen Raten. Zum Beispiel, Text-Daten und die meisten Dokumente leicht auf einen kleineren Speicherplatz zu komprimieren, aber Video-und grafische Bilder in der Regel nicht. |
Leistung
Auf der Seite Performance des Dropdown-Menüs Reporting für einen ausgewählten Cluster können Sie Details zur IOPS-Nutzung, zum Durchsatz und zur Cluster-Auslastung anzeigen, indem Sie die Kategorie auswählen und nach dem Zeitraum filtern.
Knotenauslastung
Auf der Seite Knotenauslastung des Dropdown-Menüs Berichterstellung für einen ausgewählten Cluster können Sie jeden Knoten auswählen und anzeigen.
Ab Element 12.8 sind Informationen zur Knotenauslastung verfügbar als nodeHeat mithilfe der GetNodeStats Und ListNodeStats API-Methoden. Der nodeHeat Objekt ist ein Mitglied der nodeStats Objekt und zeigt Informationen zur Knotenauslastung basierend auf dem Verhältnis der primären Gesamt-IOPS oder der Gesamt-IOPS zu den konfigurierten IOPS im Zeitdurchschnitt an. Das Knotenauslastungsdiagramm zeigt dies als Prozentsatz, der aus der Metrik abgeleitet wird recentPrimaryTotalHeat .
Fehlerprotokoll
Auf der Seite Fehlerprotokoll des Dropdown-Menüs Reporting für ein ausgewähltes Cluster können Sie Informationen über nicht behobene oder behobene Fehler anzeigen, die vom Cluster gemeldet wurden. Diese Informationen können gefiltert und in eine CSV-Datei (Comma Separated Values) exportiert werden. Weitere Informationen zu Schweregraden finden Sie im "Dokumentation der Element Software".
Die folgenden Informationen werden für das ausgewählte Cluster gemeldet.
| Überschrift | Beschreibung |
|---|---|
ID |
ID für einen Cluster-Fehler. |
Datum |
Datum und Uhrzeit der Fehlerprotokollierung. |
Schweregrad |
Dabei kann es sich um Warnung, Fehler, kritische oder Best Practices handelt. |
Typ |
Bei diesem System können Node, Laufwerk, Cluster, Service oder Volume eingesetzt werden. |
Node-ID |
Node-ID für den Node, auf den sich dieser Fehler bezieht. Bei Knoten- und Laufwerkfehlern enthalten; andernfalls auf - (Dash) einstellen. |
Node-Name |
Der vom System generierte Node-Name. |
Laufwerks-ID |
Laufwerk-ID für das Laufwerk, auf das sich dieser Fehler bezieht. Bei Fahrfehlern enthalten; andernfalls auf - (Dash) eingestellt. |
Behoben |
Zeigt an, ob die Ursache des Fehlers behoben ist. |
Auflösungszeit |
Zeigt die Zeit an, zu der ein Problem behoben wurde. |
Fehlercode |
Ein beschreibenden Code, der angibt, was den Fehler verursacht hat. |
Details |
Beschreibung des Fehlers mit zusätzlichen Details. |
Veranstaltungen
Auf der Seite Ereignisse des Dropdown-Menüs Berichterstellung für einen ausgewählten Cluster können Sie zwischen den Registerkarten Ereignisse und gcEvents wählen, um Informationen zu wichtigen Ereignissen anzuzeigen, die im Cluster aufgetreten sind. Wenn Sie „Ereignisse“ auswählen, werden standardmäßig alle Ereignisse außer „gcEvents“ angezeigt, um die Lesbarkeit zu verbessern. Um alle Ereignisse, einschließlich gcEvents, anzuzeigen, wählen Sie die Registerkarte mit der Bezeichnung gcEvents. Diese Informationen können gefiltert und in eine CSV-Datei exportiert werden.
Die folgenden Informationen werden für das ausgewählte Cluster gemeldet.
| Überschrift | Beschreibung |
|---|---|
Ereignis-ID |
Eindeutige ID, die jedem Ereignis zugeordnet ist. |
Ereigniszeit |
Die Zeit, zu der das Ereignis aufgetreten ist. |
Typ |
Der Typ des protokollierten Ereignisses, z. B. API-Ereignisse, Klon-Ereignisse oder GC-Ereignisse. Siehe die "Dokumentation der Element Software" für weitere Informationen. |
Nachricht |
Dem Ereignis zugeordnete Nachricht. |
Service-ID |
Der Dienst, der das Ereignis gemeldet hat (falls zutreffend). |
Node-ID |
Der Node, der das Ereignis gemeldet hat (falls zutreffend). |
Laufwerks-ID |
Das Laufwerk, das das Ereignis gemeldet hat (falls zutreffend). |
Details |
Informationen, mit denen der Grund des Ereignisses ermittelt werden kann. |
Meldungen
Auf der Seite Alerts des Dropdown-Menüs Reporting für ein ausgewähltes Cluster können Sie ungelöste oder aufgelöste Cluster-Warnmeldungen anzeigen. Diese Informationen können gefiltert und in eine CSV-Datei exportiert werden. Weitere Informationen zu Schweregraden finden Sie im "Dokumentation der Element Software".
Die folgenden Informationen werden für das ausgewählte Cluster gemeldet.
| Überschrift | Beschreibung |
|---|---|
Ausgelöst |
Die Zeit, zu der die Meldung in SolidFire Active IQ ausgelöst wurde, nicht im Cluster selbst. |
Letzte Benachrichtigung |
Die Zeit, zu der die letzte Alarm-E-Mail gesendet wurde. |
Behoben |
Zeigt an, ob die Ursache der Warnmeldung behoben wurde. |
Richtlinie |
Dies ist der benutzerdefinierte Name der Meldungsrichtlinie. |
Schweregrad |
Der Schweregrad, der zum Zeitpunkt der Erstellung der Meldungsrichtlinie zugewiesen wurde. |
Ziel |
Die E-Mail-Adresse oder Adressen, die für den Empfang der E-Mail-Benachrichtigung ausgewählt wurden. |
Trigger |
Die benutzerdefinierte Einstellung, die die Warnung ausgelöst hat. |
ISCSI-Sitzungen
Auf der Seite iSCSI-Sitzungen des Dropdown-Menüs Reporting für einen ausgewählten Cluster können Sie Details zur Anzahl der aktiven Sitzungen auf dem Cluster und zur Anzahl der iSCSI-Sitzungen anzeigen, die auf dem Cluster aufgetreten sind.
Erweitern Sie das Beispiel für iSCSI-Sitzungen
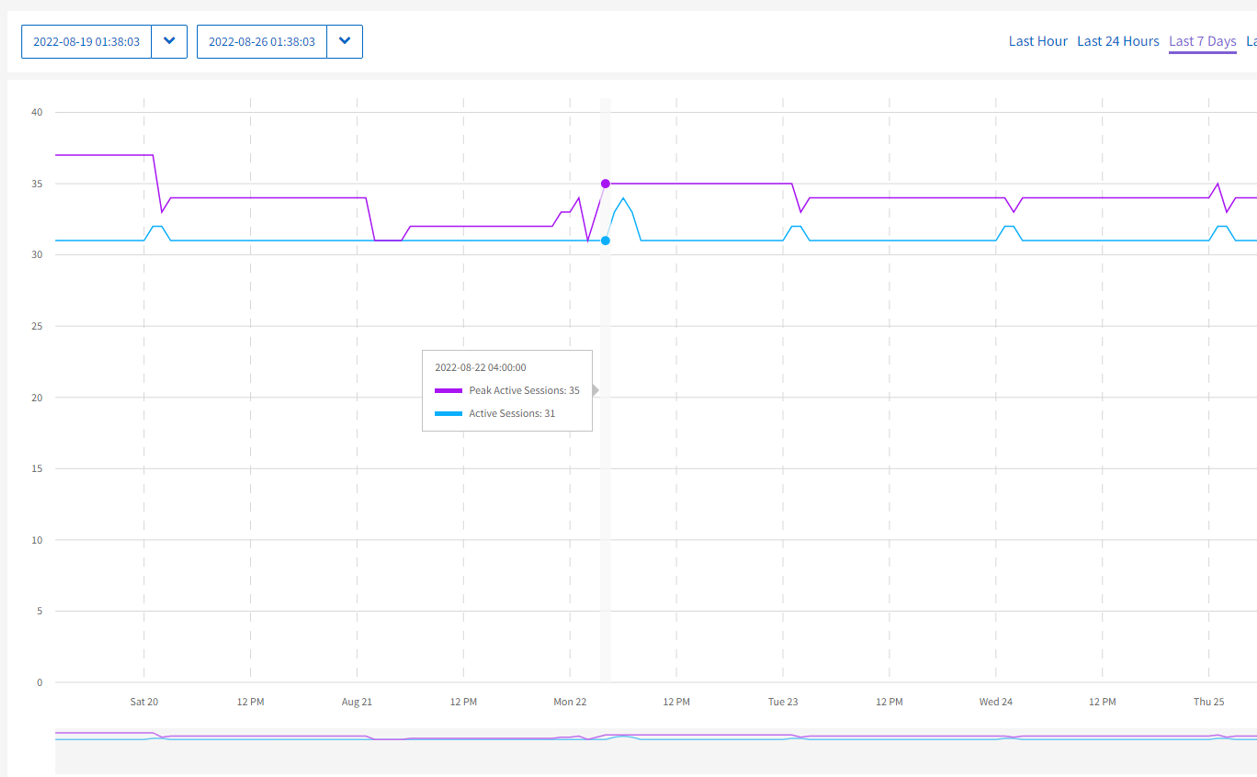
Sie können Ihren Mauszeiger über einen Datenpunkt im Diagramm bewegen, um die Anzahl der Sitzungen für einen definierten Zeitraum zu finden:
-
Aktive Sitzungen: Die Anzahl der iSCSI-Sitzungen, die auf dem Cluster verbunden und aktiv sind.
-
Aktive Spitzensitzungen: Die maximale Anzahl von iSCSI-Sitzungen, die in den letzten 24 Stunden auf dem Cluster aufgetreten sind.
|
|
Diese Daten umfassen iSCSI-Sitzungen, die von FC-Nodes generiert werden. |
Virtuelle Netzwerke
Auf der Virtual Networks-Seite des Dropdown-Menüs Reporting für einen ausgewählten Cluster können Sie die folgenden Informationen zu virtuellen Netzwerken anzeigen, die auf dem Cluster konfiguriert sind.
| Überschrift | Beschreibung |
|---|---|
ID |
Eindeutige ID des VLAN-Netzwerks. Dies wird vom System zugewiesen. |
Name |
Eindeutiger, vom Benutzer zugewiesener Name für das VLAN-Netzwerk. |
VLAN-ID |
VLAN-Tag, das beim Erstellen des virtuellen Netzwerks zugewiesen wurde. |
SVIP |
Dem virtuellen Netzwerk zugewiesene Storage Virtual IP-Adresse. |
Netzmaske |
Netzmaske für dieses virtuelle Netzwerk. |
Gateway |
Eindeutige IP-Adresse eines virtuellen Netzwerk-Gateways. VRF muss aktiviert sein. |
VRF aktiviert |
Zeigt an, ob virtuelles Routing und Forwarding aktiviert ist oder nicht. |
IPS verwendet |
Der Bereich der virtuellen Netzwerk-IP-Adressen, die für das virtuelle Netzwerk verwendet werden. |
API-Sammlung
Auf der Seite API Collection des Dropdown-Menüs Reporting für einen ausgewählten Cluster können Sie die von der NetApp SolidFire Active IQ verwendeten API-Methoden anzeigen. Ausführliche Beschreibungen zu diesen Methoden finden Sie im "Dokumentation der Element Software-API".
|
|
Zusätzlich zu diesen Methoden führt SolidFire Active IQ einige interne API-Aufrufe durch, die von NetApp Support und Engineering zur Überwachung des Cluster-Systemzustands verwendet werden. Diese Anrufe werden nicht dokumentiert, da sie bei falscher Verwendung zu einer Unterbrechung der Cluster-Funktionalität führen können. Falls Sie eine vollständige Liste der SolidFire Active IQ-API-Sammlungen benötigen, müssen Sie sich an den NetApp Support wenden. |