

NetApp StorageGRID und Big Data Analytics
 Änderungen vorschlagen
Änderungen vorschlagen
Anwendungsfälle für NetApp StorageGRID
Die NetApp StorageGRID Objekt-Storage-Lösung bietet Skalierbarkeit, Datenverfügbarkeit, Sicherheit und hohe Performance. Unternehmen jeder Größe und Branche nutzen StorageGRID S3 für zahlreiche Anwendungsfälle. Sehen wir uns einige typische Szenarien an:
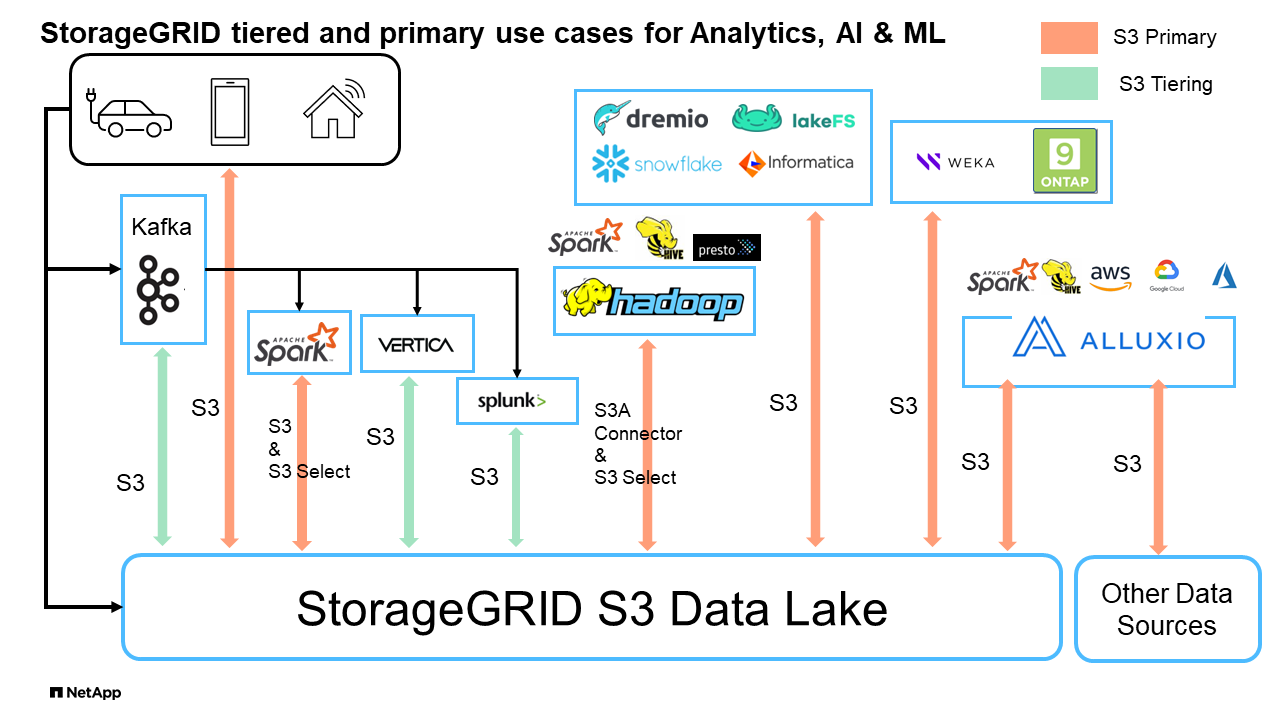
Big Data Analytics: StorageGRID S3 wird häufig als Data Lake verwendet, wo Unternehmen mit Tools wie Apache Spark, Splunk SmartStore und Dremio große Mengen an strukturierten und unstrukturierten Daten für Analysen speichern.
Daten-Tiering: NetApp Kunden nutzen die FabricPool Funktion von ONTAP, um Daten automatisch zwischen einem hochperformanten lokalen Tier zu StorageGRID zu verschieben. Durch Tiering wird teurer Flash-Storage für häufig abgerufene Daten frei. Kalte Daten werden auf kostengünstigem Objekt-Storage bereitgehalten. Dadurch werden Performance und Einsparungen maximiert.
Daten-Backup und Disaster Recovery: Unternehmen können StorageGRID S3 als zuverlässige und kostengünstige Lösung für Backup und Recovery kritischer Daten im Notfall einsetzen.
Datenspeicher für Anwendungen: StorageGRID S3 kann als Speicher-Backend für Anwendungen verwendet werden, so dass Entwickler Dateien, Bilder, Videos und andere Arten von Daten einfach speichern und abrufen können.
Inhaltsbereitstellung: StorageGRID S3 kann verwendet werden, um statische Website-Inhalte, Mediendateien und Software-Downloads für Benutzer auf der ganzen Welt zu speichern und bereitzustellen. Dabei wird die geografische Distribution und der globale Namespace von StorageGRID für eine schnelle und zuverlässige Content-Bereitstellung genutzt.
Datenarchiv: StorageGRID bietet verschiedene Speichertypen und unterstützt Tiering zu öffentlichen, langfristigen und kostengünstigen Speicheroptionen. Damit ist es eine ideale Lösung für die Archivierung und langfristige Aufbewahrung von Daten, die für Compliance- oder historische Zwecke aufbewahrt werden müssen.
Anwendungsfälle für Objekt-Storage
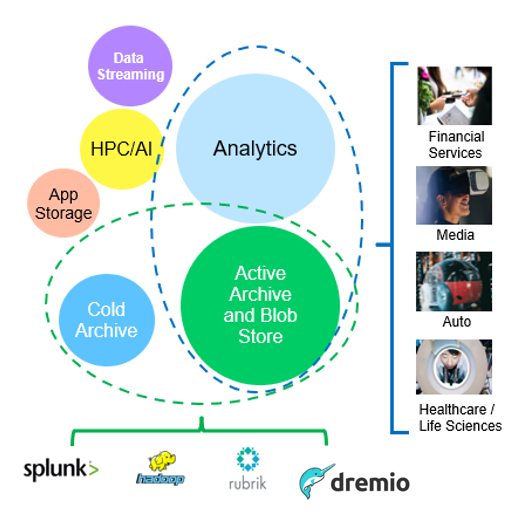
Zu den oben genannten Fällen gehört Big-Data-Analysen zu den häufigsten Nutzungsfällen und die Nutzung dieser Daten ist mit einem Aufwärtstrend verbunden.
Warum StorageGRID für Data Lakes?
-
Verstärkte Zusammenarbeit: Enorme, gemeinsam genutzte Mandantenfähigkeit mit branchenüblicher API-Zugriff
-
Niedrigere Betriebskosten: Einfacher Betrieb in einer einzelnen, automatisierten Scale-out-Architektur mit Selbstreparatur
-
Skalierbarkeit – im Gegensatz zu herkömmlichen Hadoop- und Data-Warehouse-Lösungen entkoppelt der StorageGRID S3 Objekt-Storage den Storage von Computing und Daten. So können Unternehmen ihre Storage-Anforderungen mit wachsendem Bedarf skalieren.
-
Langlebigkeit und Zuverlässigkeit: StorageGRID bietet eine Lebensdauer von 99.999999999 %, was bedeutet, dass die gespeicherten Daten sehr resistent gegen Datenverlust sind. Darüber hinaus ist Hochverfügbarkeit gewährleistet, sodass die Daten jederzeit abrufbar sind.
-
Sicherheit – StorageGRID bietet verschiedene Sicherheitsfunktionen, darunter Verschlüsselung, Zugriffssteuerungsrichtlinien, Daten-Lifecycle-Management, Objektsperre und Versionierung zum Schutz der in S3 Buckets gespeicherten Daten
StorageGRID S3 Data Lakes
Benchmarking von Data Warehouses und Lakehouses mit S3 Object Storage: Eine vergleichende Studie
Dieser Artikel bietet einen umfassenden Vergleich verschiedener Data Warehouse- und Lakehouse-Ökosysteme mithilfe von NetApp StorageGRID. Das Ziel besteht darin, zu ermitteln, welches System mit S3-Objektspeicher die beste Performance bietet. In diesem "Apache Iceberg: Der Endgültige Führer" finden sich weitere Informationen zu Data Warehouse-/Lakehouse-Architekturen und Tabellenformaten (Parquet und Iceberg).
-
Benchmark-Tool - TPC-DS - https://www.tpc.org/tpcds/
-
Big-Data-Ecosysteme
-
Cluster von VMs mit jeweils 128 GB RAM und 24 vCPUs, SSD-Storage für Systemfestplatte
-
Hadoop 3.3.5 mit Hive 3.1.3 (1 Name Node + 4 Daten-Nodes)
-
Delta Lake mit Spark 3.2.0 (1 Master + 4 Workers) und Hadoop 3.3.5
-
Dremio v25.2 (1 Koordinator + 5 Ausführende)
-
Trino v438 (1 Koordinator + 5 Mitarbeiter)
-
Starburst v453 (1 Koordinator + 5 Mitarbeiter)
-
-
Objekt-Storage
-
NetApp® StorageGRID® 11.8 mit 3 SG6060 + 1 SG1000 Load Balancer
-
Objektschutz – 2 Kopien (Ergebnis ist ähnlich wie EC 2+1)
-
-
Datenbankgröße 1.000 GB
-
Cache wurde in allen Ökosystemen für jeden Abfragetest mit dem Parkettformat deaktiviert. Für das Iceberg-Format haben wir die Anzahl der S3-GET-Anforderungen und die gesamte Abfragezeit zwischen Cache-deaktivierten und Cache-fähigen Szenarien verglichen.
TPC-DS umfasst 99 komplexe SQL-Abfragen, die für das Benchmarking entwickelt wurden. Wir haben die Gesamtdauer für die Ausführung aller 99 Abfragen gemessen. Für eine detaillierte Analyse haben wir die Art und Anzahl der S3-Anfragen untersucht. Unsere Tests verglichen die Effizienz zweier beliebter Tischformate: Parkett und Iceberg.
TPC-DS Abfrageergebnis mit Parkett-Tabellenformat
| Ecosystem | Hive | Delta Lake | Dremio | Trino | Starburst |
|---|---|---|---|---|---|
TPCDS 99 Abfragen |
1084 1 |
55 |
36 |
32 |
28 |
S3 Anfragen – Aufschlüsselung |
GET |
1,117,184 |
2,074,610 |
3.939.690 |
1.504.212 |
1.495.039 |
Beobachtung: |
80% Bereich von 2 KB bis 2 MB von 32 MB Objekten, 50 - 100 Anfragen/Sek. |
73% Bereich unter 100 KB von 32-MB-Objekten, 1000 - 1400 Anforderungen/Sek. |
90 % 1 MB-Bereich von Objekten mit 256 MB, 2500 bis 3000 Anforderungen/Sek. |
Bereich GET size: 50% unter 100KB, 16% um 1MB, 27% 2MB-9MB, 3500 - 4000 Anfragen/sec |
Bereich GET size: 50% unter 100KB, 16% um 1MB, 27% 2MB-9MB, 4000 - 5000 Anfrage/sec |
Objekte auflisten |
312,053 |
24,158 |
120 |
509 |
512 |
KOPF |
156,027 |
12,103 |
96 |
0 |
0 |
KOPF |
982,126 |
922,732 |
0 |
0 |
0 |
Gesamtanforderungen |
2,567,390 |
3,033,603 |
3.939,906 |
1.504.721 |
1 Hive konnte die Abfragenummer 72 nicht abschließen
TPC-DS Abfrageergebnis mit Iceberg-Tabellenformat
| Ecosystem | Dremio | Trino | Starburst |
|---|---|---|---|
TPCDS 99 Abfragen + Summe Minuten (Cache deaktiviert) |
22 |
28 |
22 |
TPCDS 99 Abfragen + Gesamtzahl Minuten 2 (Cache aktiviert) |
16 |
28 |
21,5 |
S3 Anfragen – Aufschlüsselung |
ABRUFEN (Cache deaktiviert) |
1.985.922 |
938.639 |
931.582 |
GET (Cache aktiviert) |
611.347 |
30.158 |
3.281 |
Beobachtung: |
Bereich GET size: 67% 1 MB, 15% 100 KB, 10% 500 KB, 3500 - 4500 Anfragen/sec |
Bereich GET size: 42% unter 100KB, 17% um 1MB, 33% 2MB-9MB, 3500 - 4000 Anfragen/sec |
Bereich GET size: 43% unter 100KB, 17% um 1MB, 33% 2MB-9MB, 4000 - 5000 Anfragen/sec |
Objekte auflisten |
1465 |
0 |
0 |
KOPF |
1464 |
0 |
0 |
KOPF |
3.702 |
509 |
509 |
Anfragen gesamt (Cache deaktiviert) |
1.992.553 |
939.148 |
2 die Performance von Trino/Starburst wird durch Computing-Ressourcen in Engpässe gebracht. Durch Hinzufügen von zusätzlichem RAM zum Cluster wird die gesamte Abfragezeit verringert.
Wie in der ersten Tabelle gezeigt, ist Hive deutlich langsamer als andere moderne Data-Lakehouse-Ökosysteme. Wir beobachteten, dass Hive eine große Anzahl von S3-Listenobjektanfragen gesendet hat, die in der Regel auf allen Objekt-Storage-Plattformen langsam sind, insbesondere bei Buckets, die zahlreiche Objekte enthalten. Dadurch erhöht sich die gesamte Abfragedauer deutlich. Zusätzlich können moderne Lakehouse-Ökosysteme eine hohe Anzahl von GET-Anfragen parallel senden, die von 2,000 bis 5,000 Anfragen pro Sekunde reichen, verglichen mit Hive’s 50 bis 100 Anfragen pro Sekunde. Die Standard-Filesystem-Mimikry von Hive und Hadoop S3A trägt zur Langsamkeit von Hive bei der Interaktion mit S3-Objektspeicher bei.
Bei der Nutzung von Hadoop (entweder auf HDFS oder S3 Objekt-Storage) mit Hive oder Spark sind umfassende Kenntnisse sowohl zu Hadoop als auch zu Hive/Spark erforderlich. Außerdem müssen Sie sich mit den Einstellungen der einzelnen Services vertraut machen. Zusammen haben sie über 1,000 Einstellungen, von denen viele miteinander verknüpft sind und nicht unabhängig voneinander geändert werden können. Die optimale Kombination von Einstellungen und Werten zu finden, erfordert viel Zeit und Aufwand.
Wenn wir die Ergebnisse von Parkett und Iceberg vergleichen, stellen wir fest, dass das Tabellenformat ein wichtiger Leistungsfaktor ist. Das Iceberg-Tabellenformat ist hinsichtlich der Anzahl der S3-Anfragen effizienter als das Parkett, mit 35% bis 50% weniger Anfragen im Vergleich zum Parkett-Format.
Die Leistung von Dremio, Trino oder Starburst wird in erster Linie durch die Rechenleistung des Clusters angetrieben. Alle drei verwenden zwar den S3A-Connector für die S3-Objektspeicher-Verbindung, benötigen jedoch kein Hadoop. Die meisten der fs.s3a-Einstellungen von Hadoop werden von diesen Systemen nicht verwendet. Dies vereinfacht das Performance-Tuning und macht das Erlernen und Testen verschiedener Hadoop S3A Einstellungen überflüssig.
Aus diesem Benchmark-Ergebnis können wir schließen, dass Big-Data-Analysesysteme für S3-basierte Workloads zu einem wesentlichen Performance-Faktor werden. Moderne Lakehouses optimieren die Abfrageausführung, nutzen Metadaten effizient und ermöglichen nahtlosen Zugriff auf S3-Daten. Dies ermöglicht eine bessere Performance als Hive bei der Arbeit mit S3 Storage.
Hier "Seite" können Sie die Dremio S3-Datenquelle mit StorageGRID konfigurieren.
Unter den folgenden Links erfahren Sie mehr darüber, wie StorageGRID und Dremio gemeinsam eine moderne und effiziente Data-Lake-Infrastruktur bereitstellen und wie NetApp von Hive + HDFS auf Dremio + StorageGRID migrierte, um die Analyseeffizienz von Big Data drastisch zu steigern.