

Vertica Eon-Modus-Datenbank mit NetApp StorageGRID als gemeinschaftliche Storage-Lösung
 Änderungen vorschlagen
Änderungen vorschlagen
Von Angela Cheng
In diesem Leitfaden werden die Verfahren zum Erstellen einer Vertica Eon-Modus-Datenbank mit gemeinsamem Speicher auf NetApp StorageGRID beschrieben.
Einführung
Vertica ist eine Software für das Analyse-Datenbankmanagement. Es handelt sich um eine spaltenbasierte Storage-Plattform zur Verarbeitung großer Datenvolumen. Damit ermöglicht sie eine sehr schnelle Abfrage-Performance in einem klassisch intensiven Szenario. Eine Vertica-Datenbank läuft in einem der beiden Modi: Eon oder Enterprise. Beide Modi können sowohl lokal als auch in der Cloud implementiert werden.
Eon- und Enterprise-Modi unterscheiden sich hauptsächlich darin, wo sie Daten speichern:
-
Die Eon-Modus-Datenbanken verwenden einen gemeinsamen Speicher für ihre Daten. Dies wird von Vertica empfohlen.
-
Die Enterprise-Mode-Datenbanken speichern die Daten lokal im Dateisystem der Knoten, aus denen die Datenbank besteht.
Eon-Mode-Architektur
Eon-Modus trennt die Computing-Ressourcen von der gemeinsamen Storage-Schicht der Datenbank, wodurch Computing- und Storage-Ressourcen getrennt skaliert werden können. Vertica im Eon-Modus ist für variable Workloads optimiert und kann durch die Nutzung separater Computing- und Storage-Ressourcen voneinander isoliert werden.
Eon-Modus speichert Daten in einem gemeinsam genutzten Objektspeicher, dem sogenannten Communal Storage – einem S3-Bucket, der entweder lokal oder in Amazon S3 gehostet wird.
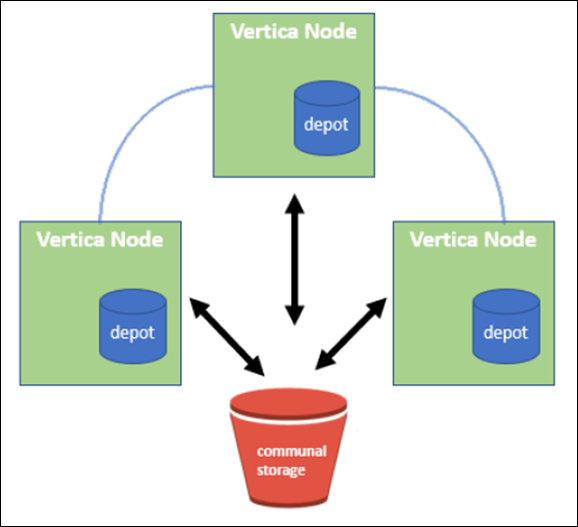
Gemeinschaftsspeicher
Statt Daten lokal zu speichern, verwendet der Eon-Modus einen einzigen gemeinsamen Speicherort für alle Daten und den Katalog (Metadaten). Der zentrale Speicherort der Datenbank, der von den Datenbank-Nodes gemeinsam genutzt wird, ist die gemeinsame Speicherung.
Kommunale Lagerung hat folgende Eigenschaften:
-
Kommunaler Storage in der Cloud oder On-Premises-Objekt-Storage ist ausfallsicherer und anfällig für Datenverluste aufgrund von Storage-Ausfällen als Storage auf Festplatte an individuellen Maschinen.
-
Alle Daten können von jedem Node aus denselben Pfad gelesen werden.
-
Die Kapazität ist nicht durch den Festplattenspeicher auf Nodes begrenzt.
-
Da Daten communal gespeichert werden, können Sie den Cluster flexibel skalieren, um den sich ändernden Anforderungen gerecht zu werden. Falls die Daten lokal auf den Nodes gespeichert wurden, müssten beim Hinzufügen oder Entfernen von Nodes umfangreiche Datenmengen zwischen Nodes verschoben werden, um sie entweder von entfernten Nodes oder auf neu erstellte Nodes zu verschieben.
Das Depot
Ein Nachteil der kommunalen Lagerung ist seine Geschwindigkeit. Der Zugriff auf Daten von einem gemeinsam genutzten Cloud-Speicherort ist langsamer als das Lesen von einer lokalen Festplatte. Darüber hinaus kann die Verbindung zu kommunalem Storage zu einem Engpass werden, wenn viele Nodes die Daten gleichzeitig lesen. Zur Verbesserung der Zugriffsgeschwindigkeit für Daten führen die Knoten in einer Eon-Modus-Datenbank einen lokalen Festplatten-Cache mit Daten, die als Depot bezeichnet werden. Bei der Ausführung einer Abfrage prüfen die Knoten zunächst, ob sich die erforderlichen Daten im Depot befinden. Ist dies der Fall, wird die Abfrage beendet, indem die lokale Kopie der Daten verwendet wird. Wenn sich die Daten nicht im Depot befindet, ruft der Knoten die Daten aus dem gemeinsamen Lager ab und speichert eine Kopie im Depot.
NetApp StorageGRID-Empfehlungen
Vertica speichert Datenbankdaten im Objekt-Storage als Tausende (oder Millionen) komprimierter Objekte (die beobachtete Größe beträgt 200 bis 500 MB pro Objekt. Wenn ein Benutzer Datenbankabfragen ausführt, ruft Vertica den ausgewählten Datenbereich aus diesen komprimierten Objekten parallel mit dem GET-Aufruf des Byte-Bereichs ab. Jeder Byte-Bereich HAT ca. 8 KB.
Während des 10-TB-Datenbankdepots zur Prüfung von Benutzeranfragen wurden 4,000 bis 10,000 GET-Anforderungen (Byte-Bereich GET) pro Sekunde an das Grid gesendet. Bei diesem Test werden SG6060 Appliances eingesetzt, obwohl die CPU-Auslastung des % pro Appliance-Node niedrig ist (etwa 20 bis 30 %), warten 2/3 der CPU-Zeit auf I/O Bei SGF6024 wird ein sehr kleiner Prozentsatz (0 % bis 0.5 %) des I/O-Wartens beobachtet.
Aufgrund der hohen Anforderungen an kleine IOPS mit sehr niedrigen Latenzanforderungen (der Durchschnitt liegt bei weniger als 0.01 Sekunden) empfiehlt NetApp die Verwendung von SFG6024 für Objekt-Storage-Services. Falls das SG6060 für sehr große Datenbanken benötigt wird, sollte der Kunde mit dem Vertica Account-Team zusammenarbeiten, um den aktiv abgefragten Datensatz zu unterstützen.
Für den Admin-Node und den API-Gateway-Node kann der Kunde das SG100 oder SG1000 verwenden. Die Wahl hängt von der Anzahl der Abfragen der Benutzer in paralleler und Datenbank-Größe ab. Wenn der Kunde einen Drittanbieter-Load-Balancer einsetzen möchte, empfiehlt NetApp einen dedizierten Load Balancer für Workloads mit hohen Performance-Anforderungen. Informationen zur StorageGRID Dimensionierung erhalten Sie vom NetApp Account Team.
Weitere Empfehlungen für die StorageGRID-Konfiguration:
-
Grid-Topologie. Kombinieren Sie SGF6024 nicht mit anderen Storage Appliance-Modellen am selben Grid-Standort. Wenn Sie den SG6060 für den langfristigen Archivierungsschutz verwenden möchten, sollten Sie den SGF6024 mit einem dedizierten Grid Load Balancer am eigenen Grid-Standort (entweder am physischen oder logischen Standort) für eine aktive Datenbank aufbewahren, um die Performance zu steigern. Die Kombination verschiedener Appliance-Modelle am selben Standort verringert die Gesamtleistung am Standort.
-
Datenschutz. Verwenden Sie Replizieren-Kopien für die Sicherheit. Verwenden Sie kein Erasure Coding für eine aktive Datenbank. Der Kunde kann das Verfahren zur Einhaltung von Datenkonsistenz (Erasure Coding) verwenden, um inaktive Datenbanken langfristig zu schützen.
-
Gitterkompression nicht aktivieren. Vertica komprimiert Objekte, bevor sie in Objekt-Storage gespeichert werden. Durch die Aktivierung der Grid-Komprimierung wird die Storage-Auslastung nicht weiter gesenkt und DIE GET-Performance im Byte-Bereich wird deutlich verringert.
-
HTTP im Vergleich zu HTTPS S3-Endpunktverbindung. Während des Benchmark-Tests konnten wir bei der Verwendung einer HTTP S3-Verbindung vom Vertica Cluster zum StorageGRID Load Balancer-Endpunkt eine Performance-Steigerung von ca. 5 % feststellen. Diese Auswahl sollte auf den Sicherheitsanforderungen des Kunden basieren.
Empfehlungen für eine Vertica Konfiguration sind:
-
Die Standardeinstellungen des Vertica Datenbank-Depots sind aktiviert (Wert = 1) für Lese- und Schreibvorgänge. NetApp empfiehlt dringend, diese Depoteinstellungen für die Performance-Steigerung zu aktivieren.
-
Streaming-Einschränkungen deaktivieren. Weitere Informationen zur Konfiguration finden Sie im Abschnitt Deaktivieren von Streaming-Einschränkungen.
Installation von Eon-Modus vor Ort mit kommunalem Speicher auf StorageGRID
In den folgenden Abschnitten wird das Verfahren beschrieben, um den Eon-Modus vor Ort mit kommunalem Speicher auf StorageGRID zu installieren. Das Verfahren zur Konfiguration von S3-kompatiblem Objektspeicher (Simple Storage Service) ähnelt dem Verfahren im Vertica-Leitfaden. "Installation einer On-Premises-Eon-Mode-Datenbank".
Für den Funktionstest wurde folgendes Setup verwendet:
-
StorageGRID 11.4.0.4
-
Vertica 10.1.0
-
Drei Virtual Machines (VMs) mit CentOS 7.x OS für Vertica Nodes zu einem Cluster bilden. Dieses Setup gilt nur für den Funktionstest, nicht für das Produktions-Datenbank-Cluster der Vertica.
Diese drei Nodes sind mit einem SSH-Schlüssel (Secure Shell) eingerichtet, um SSH ohne Passwort zwischen den Nodes innerhalb des Clusters zuzulassen.
Erforderliche Informationen von NetApp StorageGRID
Um den Eon-Modus vor Ort mit kommunalem Speicher auf StorageGRID zu installieren, müssen Sie die folgenden Vorbedingung-Informationen haben.
-
IP-Adresse oder vollständig qualifizierter Domain-Name (FQDN) und Portnummer des StorageGRID S3-Endpunkts. Wenn Sie HTTPS verwenden, verwenden Sie eine CA (Custom Certificate Authority) oder ein selbstsigniertes SSL-Zertifikat, das am StorageGRID S3-Endpunkt implementiert wurde.
-
Bucket-Name Er muss vorexistieren und leer sein.
-
Schlüssel-ID und geheimer Zugriffsschlüssel mit Lese- und Schreibzugriff auf den Bucket
Erstellen einer Autorisierungsdatei für den Zugriff auf den S3-Endpunkt
Beim Erstellen einer Autorisierungsdatei für den Zugriff auf den S3-Endpunkt gelten die folgenden Voraussetzungen:
-
Vertica ist installiert.
-
Ein Cluster ist für die Datenbankerstellung eingerichtet, konfiguriert und bereit.
So erstellen Sie eine Autorisierungsdatei für den Zugriff auf den S3-Endpunkt:
-
Melden Sie sich beim Vertica-Knoten an, auf dem Sie ausgeführt werden
admintoolsSo erstellen Sie die Eon-Modus-Datenbank.Der Standardbenutzer ist
dbadmin, Erstellt während der Vertica Cluster Installation. -
Verwenden Sie einen Texteditor, um eine Datei unter dem zu erstellen
/home/dbadminVerzeichnis. Der Dateiname kann alles sein, was Sie wollen, z. B.sg_auth.conf. -
Wenn der S3-Endpunkt einen Standard-HTTP-Port 80 oder HTTPS-Port 443 verwendet, überspringen Sie die Portnummer. Um HTTPS zu verwenden, legen Sie die folgenden Werte fest:
-
awsenablehttps = 1, Sonst setzen Sie den Wert auf0. -
awsauth = <s3 access key ID>:<secret access key> -
awsendpoint = <StorageGRID s3 endpoint>:<port>Um eine benutzerdefinierte CA oder ein selbstsigniertes SSL-Zertifikat für die HTTPS-Verbindung des StorageGRID S3-Endpunkts zu verwenden, geben Sie den vollständigen Dateipfad und den Dateinamen des Zertifikats an. Diese Datei muss sich am selben Speicherort auf jedem Vertica-Knoten befinden und über Leseberechtigung für alle Benutzer verfügen. Überspringen Sie diesen Schritt, wenn das StorageGRID S3 Endpoint SSL-Zertifikat von einer öffentlich bekannten CA signiert wurde.
− awscafile = <filepath/filename>Informationen hierzu finden Sie beispielsweise in der folgenden Beispieldatei:
awsauth = MNVU4OYFAY2xyz123:03vuO4M4KmdfwffT8nqnBmnMVTr78Gu9wANabcxyz awsendpoint = s3.england.connectlab.io:10443 awsenablehttps = 1 awscafile = /etc/custom-cert/grid.pem
+

In einer Produktionsumgebung muss der Kunde ein Serverzertifikat implementieren, das von einer öffentlich bekannten CA auf einem StorageGRID S3 Load Balancer-Endpunkt unterzeichnet wurde. -
Auswählen eines Depotpfads auf allen Vertica-Knoten
Wählen Sie auf jedem Knoten ein Verzeichnis für den Depot-Speicherpfad aus oder erstellen Sie ein Verzeichnis. Das Verzeichnis, das Sie für den Parameter Depot-Speicherpfad bereitstellen, muss Folgendes haben:
-
Derselbe Pfad auf allen Nodes im Cluster (z. B.
/home/dbadmin/depot) -
Vom dbadmin-Benutzer lesbar und beschreibbar sein
-
Ausreichende Lagerung
Standardmäßig verwendet Vertica 60 % des Dateisystemspeichers, der das Verzeichnis für die Depotspeicherung enthält. Sie können die Größe des Depots mithilfe der begrenzen
--depot-sizeArgument increate_dbBefehl. Siehe "Dimensionierung des Vertica Clusters für eine Eon-Mode-Datenbank" Artikel für allgemeine Vertica Größenrichtlinien oder wenden Sie sich an Ihren Vertica Account Manager.Der
admintools create_dbDas Tool versucht, den Depotpfad für Sie zu erstellen, wenn dieser nicht vorhanden ist.
Erstellen der On-Premises-Datenbank von Eon
So erstellen Sie die On-Premises-Datenbank von Eon:
-
Verwenden Sie zum Erstellen der Datenbank die
admintools create_dbWerkzeug.Die folgende Liste enthält eine kurze Erläuterung der Argumente, die in diesem Beispiel verwendet werden. Eine detaillierte Erläuterung aller erforderlichen und optionalen Argumente finden Sie im Dokument Vertica.
-
-X <Pfad/Dateiname der in erstellten Autorisierungsdatei „Erstellen einer Autorisierungsdatei für den Zugriff auf den S3-Endpunkt“ >.
Die Autorisierungsdetails werden nach erfolgreicher Erstellung in der Datenbank gespeichert. Sie können diese Datei entfernen, um zu vermeiden, dass der S3-Geheimschlüssel offengelegt wird.
-
--communal-Storage-location <s3://storagegrid buchname>
-
-S <kommagetrennte Liste der Vertica-Knoten, die für diese Datenbank verwendet werden sollen>
-
-D <Name der zu erstellenden Datenbank>
-
-P <Kennwort für diese neue Datenbank> festlegen. Den folgenden Beispielbefehl können Sie z. B. einsehen:
admintools -t create_db -x sg_auth.conf --communal-storage-location=s3://vertica --depot-path=/home/dbadmin/depot --shard-count=6 -s vertica-vm1,vertica-vm2,vertica-vm3 -d vmart -p '<password>'
Das Erstellen einer neuen Datenbank dauert abhängig von der Anzahl der Nodes für die Datenbank mehrere Minuten. Wenn Sie die Datenbank zum ersten Mal erstellen, werden Sie aufgefordert, die Lizenzvereinbarung zu akzeptieren.
-
Informationen hierzu finden Sie z. B. in der folgenden Beispielautorisierungsdatei und create db Befehl:
[dbadmin@vertica-vm1 ~]$ cat sg_auth.conf
awsauth = MNVU4OYFAY2CPKVXVxxxx:03vuO4M4KmdfwffT8nqnBmnMVTr78Gu9wAN+xxxx
awsendpoint = s3.england.connectlab.io:10445
awsenablehttps = 1
[dbadmin@vertica-vm1 ~]$ admintools -t create_db -x sg_auth.conf --communal-storage-location=s3://vertica --depot-path=/home/dbadmin/depot --shard-count=6 -s vertica-vm1,vertica-vm2,vertica-vm3 -d vmart -p 'xxxxxxxx'
Default depot size in use
Distributing changes to cluster.
Creating database vmart
Starting bootstrap node v_vmart_node0007 (10.45.74.19)
Starting nodes:
v_vmart_node0007 (10.45.74.19)
Starting Vertica on all nodes. Please wait, databases with a large catalog may take a while to initialize.
Node Status: v_vmart_node0007: (DOWN)
Node Status: v_vmart_node0007: (DOWN)
Node Status: v_vmart_node0007: (DOWN)
Node Status: v_vmart_node0007: (UP)
Creating database nodes
Creating node v_vmart_node0008 (host 10.45.74.29)
Creating node v_vmart_node0009 (host 10.45.74.39)
Generating new configuration information
Stopping single node db before adding additional nodes.
Database shutdown complete
Starting all nodes
Start hosts = ['10.45.74.19', '10.45.74.29', '10.45.74.39']
Starting nodes:
v_vmart_node0007 (10.45.74.19)
v_vmart_node0008 (10.45.74.29)
v_vmart_node0009 (10.45.74.39)
Starting Vertica on all nodes. Please wait, databases with a large catalog may take a while to initialize.
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (UP) v_vmart_node0008: (UP) v_vmart_node0009: (UP)
Creating depot locations for 3 nodes
Communal storage detected: rebalancing shards
Waiting for rebalance shards. We will wait for at most 36000 seconds.
Installing AWS package
Success: package AWS installed
Installing ComplexTypes package
Success: package ComplexTypes installed
Installing MachineLearning package
Success: package MachineLearning installed
Installing ParquetExport package
Success: package ParquetExport installed
Installing VFunctions package
Success: package VFunctions installed
Installing approximate package
Success: package approximate installed
Installing flextable package
Success: package flextable installed
Installing kafka package
Success: package kafka installed
Installing logsearch package
Success: package logsearch installed
Installing place package
Success: package place installed
Installing txtindex package
Success: package txtindex installed
Installing voltagesecure package
Success: package voltagesecure installed
Syncing catalog on vmart with 2000 attempts.
Database creation SQL tasks completed successfully. Database vmart created successfully.
| Objektgröße (Byte) | Bucket/Objektschlüssel vollständiger Pfad |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Deaktivieren von Streaming-Einschränkungen
Dieses Verfahren basiert auf dem Vertica-Leitfaden für andere On-Premises-Objektspeicher und sollte für StorageGRID angewendet werden.
-
Deaktivieren Sie nach dem Erstellen der Datenbank das
AWSStreamingConnectionPercentageKonfigurationsparameter durch Festlegen auf0. Diese Einstellung ist für eine On-Premises-Installation im Eon-Modus mit kommunalem Speicher nicht erforderlich. Dieser Konfigurationsparameter steuert die Anzahl der Verbindungen zu dem Objektspeicher, den Vertica für das Streaming von Lesevorgängen verwendet. In einer Cloud-Umgebung verhindert diese Einstellung, dass aus dem Objektspeicher Daten gestreamt werden, alle verfügbaren Datei-Handles nutzen. Einige Datei-Handles stehen für andere Objektspeichervorgänge zur Verfügung. Aufgrund der niedrigen Latenz von On-Premises-Objektspeichern ist diese Option nicht erforderlich. -
Verwenden Sie A
vsqlAnweisung zum Aktualisieren des Parameterwerts. Das Passwort ist das Datenbank-Passwort, das Sie unter „Erstellen der On-Premises-Datenbank von Eon“ festgelegt haben. Informationen hierzu finden Sie z. B. in der folgenden Beispielausgabe:
[dbadmin@vertica-vm1 ~]$ vsql
Password:
Welcome to vsql, the Vertica Analytic Database interactive terminal.
Type: \h or \? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
dbadmin=> ALTER DATABASE DEFAULT SET PARAMETER AWSStreamingConnectionPercentage = 0; ALTER DATABASE
dbadmin=> \q
Depot-Einstellungen werden überprüft
Standarddepot-Einstellungen der Vertica-Datenbank sind aktiviert (Wert = 1) für Lese- und Schreibvorgänge. NetApp empfiehlt dringend, diese Depoteinstellungen für die Performance-Steigerung zu aktivieren.
vsql -c 'show current all;' | grep -i UseDepot DATABASE | UseDepotForReads | 1 DATABASE | UseDepotForWrites | 1
Laden von Probendaten (optional)
Wenn diese Datenbank zu Testzwecken bereit ist und entfernt werden wird, können Sie Beispieldaten zu Testzwecken in diese Datenbank laden. Vertica kommt mit Probendatensatz, VMart, gefunden unter /opt/vertica/examples/VMart_Schema/ Auf jedem Vertica-Knoten. Weitere Informationen zu diesem Beispieldatensatz finden Sie hier "Hier".
Führen Sie die folgenden Schritte aus, um die Probendaten zu laden:
-
Melden Sie sich als dbadmin an einem der Vertica-Knoten an: cd /opt/vertica/examples/VMart_Schema/
-
Laden Sie Beispieldaten in die Datenbank, und geben Sie das Datenbank-Passwort ein, wenn Sie in den Unterschritten c und d aufgefordert werden:
-
cd /opt/vertica/examples/VMart_Schema -
./vmart_gen -
vsql < vmart_define_schema.sql -
vsql < vmart_load_data.sql
-
-
Es gibt mehrere vordefinierte SQL-Abfragen. Sie können einige davon ausführen, um zu bestätigen, dass die Testdaten erfolgreich in die Datenbank geladen wurden. Beispiel:
vsql < vmart_queries1.sql
Wo Sie weitere Informationen finden
Sehen Sie sich die folgenden Dokumente und/oder Websites an, um mehr über die in diesem Dokument beschriebenen Informationen zu erfahren:
Versionsverlauf
| Version | Datum | Versionsverlauf des Dokuments |
|---|---|---|
Version 1.0 |
September 2021 |
Erste Version. |
Von Angela Cheng