

StorageGRID-Speichervolumes neu einbinden und neu formatieren (manuelle Schritte)
 Änderungen vorschlagen
Änderungen vorschlagen
Falls die automatische Prozedur zum Wiederherstellen der gesicherten Speichervolumes und zum Neuformatieren fehlerhafter Speichervolumes fehlschlägt, müssen zwei Skripte manuell ausgeführt werden, um diese Vorgänge abzuschließen. Das erste Skript bindet Volumes wieder ein, die ordnungsgemäß als StorageGRID Speichervolumes formatiert sind. Das zweite Skript formatiert alle nicht eingebundenen Volumes neu, stellt die Cassandra Datenbank bei Bedarf wieder her und startet die Dienste.
Während einer Storage Node-Wiederherstellung erscheint im Grid Manager die Meldung „Warten auf manuelle Schritte“, wenn manuelle Maßnahmen erforderlich sind, um die Speichervolumes erneut einzubinden und zu formatieren. Wenn diese Meldung nicht angezeigt wird, wurden die Einbindungs- und Formatierungsvorgänge automatisch abgeschlossen, sodass dieses Verfahren übersprungen werden kann "Objektdaten wiederherstellen".
-
Sie haben bereits die Hardware für alle ausgefallenen Storage Volumes ausgetauscht, die ausgetauscht werden müssen.
Das Ausführen des
sn-remount-volumesSkripts kann Ihnen dabei helfen, zusätzliche fehlerhafte Speichervolumes zu identifizieren. -
Sie haben überprüft, dass keine Außerbetriebnahme eines Speicherknotens im Gange ist, oder Sie haben den Vorgang zur Außerbetriebnahme des Knotens angehalten. (Wählen Sie im Grid Manager Wartung > Aufgaben > Außerbetriebnahme.)
-
Sie haben überprüft, dass keine Erweiterung im Gange ist. (Wählen Sie im Grid Manager Wartung > Aufgaben > Erweiterung.)
-
Sie haben "Überprüfen Sie die Warnungen für die Wiederherstellung des Speicherknoten-Systemlaufwerks".

Wenden Sie sich an den technischen Support, wenn mehr als ein Speicherknoten offline ist. Führen Sie nicht die sn-recovery-postinstall.shSkript.
Zum Abschluss dieses Vorgangs führen Sie die folgenden grundlegenden Aufgaben aus:
-
Melden Sie sich beim wiederhergestellten Speicherknoten an.
-
Führen Sie das Skript aus
sn-remount-volumes, um ordnungsgemäß formatierte Speichervolumes neu zu mounten. Wenn dieses Skript ausgeführt wird, führt es Folgendes aus:-
Hängt jedes Storage-Volume an und ab, um das XFS-Journal wiederzugeben.
-
Führt eine Konsistenzprüfung der XFS-Datei durch.
-
Wenn das Dateisystem konsistent ist, bestimmt, ob das Storage Volume ein ordnungsgemäß formatiertes StorageGRID Storage Volume ist.
-
Wenn das Storage Volume ordnungsgemäß formatiert ist, wird das Storage-Volume wieder gemountet. Alle bestehenden Daten auf dem Volume bleiben erhalten.
-
-
Prüfen Sie die Skriptausgabe und beheben Sie etwaige Probleme.
-
Führen Sie das Skript aus
sn-recovery-postinstall.sh. Wenn dieses Skript ausgeführt wird, führt es Folgendes aus.
Starten Sie einen Storage Node während der Recovery nicht neu, bevor Sie ihn ausführen, um die fehlerhaften Storage-Volumes neu sn-recovery-postinstall.shzu formatieren und Objektmetadaten wiederherzustellen. Das Neubooten des Speicher-Node vorsn-recovery-postinstall.shAbschluss verursacht Fehler für Dienste, die versuchen, zu starten, und bewirkt, dass StorageGRID-Appliance-Nodes den Wartungsmodus beenden. Siehe den Schritt für Skript nach der Installation.-
Formatiert alle Speichervolumes, die das Skript nicht mounten konnte oder die nicht ordnungsgemäß formatiert wurden, neu
sn-remount-volumes.
Wenn ein Speicher-Volume neu formatiert wird, gehen alle Daten auf diesem Volume verloren. Sie müssen ein zusätzliches Verfahren durchführen, um Objektdaten von anderen Standorten im Grid wiederherzustellen, vorausgesetzt, dass ILM-Regeln für die Speicherung von mehr als einer Objektkopie konfiguriert wurden. -
Stellt die Cassandra-Datenbank bei Bedarf auf dem Node wieder her.
-
Startet die Dienste auf dem Speicherknoten.
-
-
Melden Sie sich beim wiederhergestellten Speicherknoten an:
-
Geben Sie den folgenden Befehl ein:
ssh admin@grid_node_IP -
Geben Sie das in der Datei aufgeführte Passwort ein
Passwords.txt. -
Geben Sie den folgenden Befehl ein, um zu root zu wechseln:
su - -
Geben Sie das in der Datei aufgeführte Passwort ein
Passwords.txt.
Wenn Sie als root angemeldet sind, wechselt die Eingabeaufforderung von
$zu#. -
-
Führen Sie das erste Skript aus, um alle ordnungsgemäß formatierten Speicher-Volumes neu zu mounten.
Wenn alle Speicher-Volumes neu sind und formatiert werden müssen, oder wenn alle Speicher-Volumes ausgefallen sind, können Sie diesen Schritt überspringen und das zweite Skript ausführen, um alle nicht abgehängt Speicher-Volumes neu zu formatieren. -
Führen Sie das Skript aus:
sn-remount-volumesDieses Skript kann Stunden dauern, bis es auf Storage-Volumes ausgeführt wird, die Daten enthalten.
-
Überprüfen Sie die Ausgabe, während das Skript ausgeführt wird, und beantworten Sie alle Eingabeaufforderungen.
Bei Bedarf können Sie den Befehl verwenden tail -f, um den Inhalt der Protokolldatei des Skripts zu überwachen (/var/local/log/sn-remount-volumes.log) . Die Protokolldatei enthält ausführlichere Informationen als die Befehlsausgabe der Befehlszeile.root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
In der Beispielausgabe wurde ein Storage-Volume erfolgreich neu eingebunden und drei Storage-Volumes wiesen Fehler auf.
-
/dev/sdbDie Konsistenzprüfung des XFS-Dateisystems bestanden und eine gültige Volumestruktur hatten, so dass sie erfolgreich neu gemountet wurde. Daten auf Geräten, die vom Skript neu eingebunden werden, bleiben erhalten. -
/dev/sdcDie Konsistenzprüfung des XFS-Dateisystems ist fehlgeschlagen, weil das Speichervolume neu oder beschädigt war. -
/dev/sddKonnte nicht gemountet werden, da die Festplatte nicht initialisiert wurde oder der Superblock der Festplatte beschädigt war. Wenn das Skript ein Speichervolume nicht mounten kann, werden Sie gefragt, ob Sie die Konsistenzprüfung des Dateisystems ausführen möchten.-
Wenn das Speichervolumen an eine neue Festplatte angeschlossen ist, beantworten Sie N mit der Eingabeaufforderung. Sie müssen das Dateisystem auf einer neuen Festplatte nicht überprüfen.
-
Wenn das Speichervolumen an eine vorhandene Festplatte angeschlossen ist, beantworten Sie Y mit der Eingabeaufforderung. Sie können die Ergebnisse der Dateisystemüberprüfung verwenden, um die Quelle der Beschädigung zu bestimmen. Die Ergebnisse werden in der Protokolldatei gespeichert
/var/local/log/sn-remount-volumes.log.
-
-
/dev/sdeDie Konsistenzprüfung des XFS-Dateisystems wurde bestanden und es gab eine gültige Volumestruktur. Die LDR-Knoten-ID in der volID-Datei stimmt jedoch nicht mit der ID für diesen Speicher-Node überein (derconfigured LDR noidoben angezeigt wird). Diese Meldung gibt an, dass dieses Volume zu einem anderen Speicherknoten gehört.
-
-
-
Prüfen Sie die Skriptausgabe und beheben Sie etwaige Probleme.
Wenn ein Speichervolume die Konsistenzprüfung des XFS-Dateisystems fehlgeschlagen ist oder nicht gemountet werden konnte, überprüfen Sie sorgfältig die Fehlermeldungen in der Ausgabe. Sie müssen die Auswirkungen der Ausführung des Skripts auf diesen Volumes verstehen sn-recovery-postinstall.sh.-
Überprüfen Sie, ob die Ergebnisse einen Eintrag für alle Volumes enthalten, die Sie erwartet haben. Wenn keine Volumes aufgeführt sind, führen Sie das Skript erneut aus.
-
Überprüfen Sie die Meldungen für alle angeschlossenen Geräte. Stellen Sie sicher, dass keine Fehler vorliegen, die darauf hinweisen, dass ein Speichervolume nicht zu diesem Speicherknoten gehört.
In dem Beispiel enthält die Ausgabe für
/dev/sdedie folgende Fehlermeldung:Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Wenn ein Storage-Volume gemeldet wird, das zu einem anderen Storage Node gehört, wenden Sie sich an den technischen Support. Wenn Sie das Skript ausführen sn-recovery-postinstall.sh, wird das Speichervolume neu formatiert, was zu Datenverlust führen kann. -
Wenn keine Speichergeräte montiert werden konnten, notieren Sie sich den Gerätenamen und reparieren oder ersetzen Sie das Gerät.
Sie müssen Speichergeräte reparieren oder ersetzen, die nicht montiert werden können. -
Führen Sie nach der Reparatur oder dem Austausch aller nicht montierbaren Geräte das Skript erneut aus
sn-remount-volumes, um zu bestätigen, dass alle Speicher-Volumes, die neu gemountet werden können, neu gemountet wurden.
Wenn ein Storage-Volume nicht gemountet oder nicht ordnungsgemäß formatiert werden kann und Sie mit dem nächsten Schritt fortfahren, werden das Volume und sämtliche Daten auf dem Volume gelöscht. Falls Sie zwei Kopien von Objektdaten hatten, ist nur eine einzige Kopie verfügbar, bis Sie das nächste Verfahren (Wiederherstellen von Objektdaten) abgeschlossen haben.
Führen Sie das Skript nicht sn-recovery-postinstall.shaus, wenn Sie glauben, dass die auf einem ausgefallenen Storage-Volume verbleibenden Daten nicht von anderer Stelle im Grid neu erstellt werden können (z. B. wenn Ihre ILM-Richtlinie eine Regel verwendet, die nur eine Kopie macht oder wenn Volumes auf mehreren Nodes ausgefallen sind). Wenden Sie sich stattdessen an den technischen Support, um zu ermitteln, wie Sie Ihre Daten wiederherstellen können. -
-
Führen Sie das Skript aus
sn-recovery-postinstall.sh:sn-recovery-postinstall.shDieses Skript formatiert alle Storage-Volumes, die nicht gemountet werden konnten oder die sich als falsch formatiert herausfanden. Darüber hinaus wird die Cassandra-Datenbank bei Bedarf auf dem Node wiederhergestellt und die Services auf dem Storage-Node gestartet.
Beachten Sie Folgendes:
-
Das Skript kann Stunden in Anspruch nehmen.
-
Im Allgemeinen sollten Sie die SSH-Sitzung allein lassen, während das Skript ausgeführt wird.
-
Drücken Sie nicht Strg+C, während die SSH-Sitzung aktiv ist.
-
Das Skript wird im Hintergrund ausgeführt, wenn eine Netzwerkunterbrechung auftritt und die SSH-Sitzung beendet wird. Sie können jedoch den Fortschritt auf der Seite Wiederherstellung anzeigen.
-
Wenn der Storage-Node den RSM-Service verwendet, wird das Skript möglicherweise 5 Minuten lang blockiert, während die Node-Services neu gestartet werden. Diese 5-minütige Verzögerung wird erwartet, wenn der RSM-Dienst zum ersten Mal startet.
Der RSM-Dienst ist auf Speicherknoten vorhanden, die den ADC-Service enthalten.
Einige StorageGRID-Wiederherstellungsverfahren verwenden Reaper für die Bearbeitung von Cassandra-Reparaturen. Reparaturen werden automatisch ausgeführt, sobald die entsprechenden oder erforderlichen Services gestartet wurden. Sie können die Skriptausgabe bemerken, die „Reaper“ oder „Cassandra Repair“ erwähnt. Wenn eine Fehlermeldung angezeigt wird, dass die Reparatur fehlgeschlagen ist, führen Sie den Befehl aus, der in der Fehlermeldung angezeigt wird. -
-
Überwachen Sie während des
sn-recovery-postinstall.shSkripts die Wiederherstellungsseite im Grid Manager.Der Fortschrittsbalken und die Spalte Stufe auf der Seite Wiederherstellung geben einen übergeordneten Status des
sn-recovery-postinstall.shSkripts an.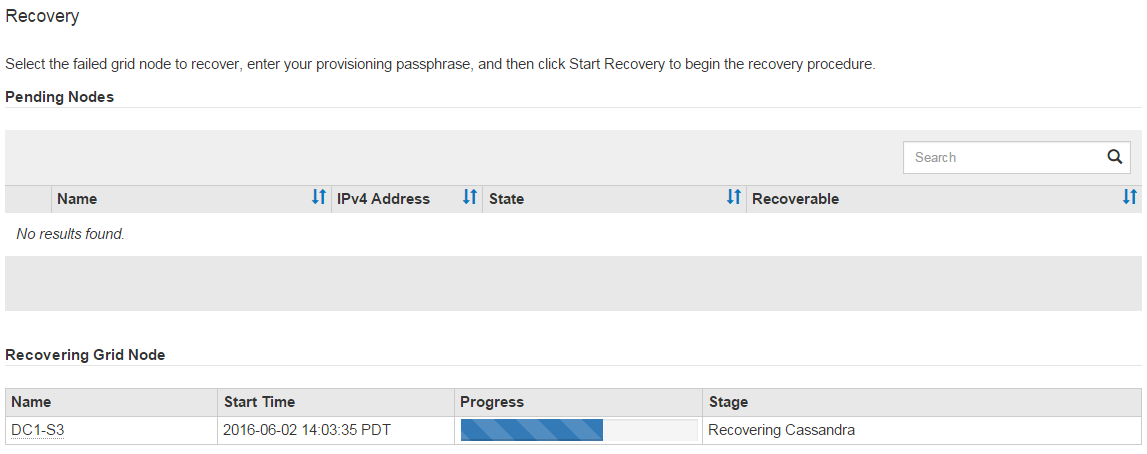
-
Nachdem das
sn-recovery-postinstall.shSkript Dienste auf dem Node gestartet hat, können Sie Objektdaten auf allen Speichervolumes wiederherstellen, die mit dem Skript formatiert wurden.Das Skript fragt Sie, ob Sie den Wiederherstellungsprozess für das Grid Manager-Volume verwenden möchten.
-
In den meisten Fällen sollte "Stellen Sie Objektdaten mithilfe von Grid Manager wieder her" verwendet werden. Antwort
yzur Verwendung des Grid Manager. -
In seltenen Fällen, beispielsweise wenn bekannt ist, dass der Ersatzknoten weniger Volumes für die Objektspeicherung als der ursprüngliche Knoten zur Verfügung hat, sollte der technische Support kontaktiert werden, um die Objektdaten manuell wiederherzustellen. Wenn einer dieser Fälle zutrifft,
nund eine beliebige Taste gedrückt wird, erfolgt die Rückkehr zur Befehlszeile.
-