

Identificar el problema y realizar acciones correctivas para un trabajo de protección con errores
 Sugerir cambios
Sugerir cambios
Revisa el mensaje de error de error de trabajo en el campo CAUSE de la página de detalles Event y determina que el trabajo ha fallado debido a un error de copia de Snapshot. Luego continúa a la página de detalles Volume / Health para recopilar más información.
Lo que necesitará
Debe tener la función Administrador de aplicaciones.
El mensaje de error proporcionado en el campo causa de la página de detalles Event contiene el siguiente texto sobre el trabajo con errores:
Protection Job Failed. Reason: (Transfer operation for relationship 'cluster2_src_svm:cluster2_src_vol2->cluster3_dst_svm: managed_svc2_vol3' ended unsuccessfully. Last error reported by Data ONTAP: Failed to create Snapshot copy 0426cluster2_src_vol2snap on volume cluster2_src_svm:cluster2_src_vol2. (CSM: An operation failed due to an ONC RPC failure.) Job Details
Este mensaje proporciona la siguiente información:
-
Un trabajo de backup o reflejo no se completó correctamente.
El trabajo implicaba una relación de protección entre el volumen de origen
cluster2_src_vol2en el servidor virtualcluster2_src_svmy el volumen de destinomanaged_svc2_vol3en el servidor virtual llamadocluster3_dst_svm. -
Error de un trabajo de copia Snapshot para
0426cluster2_src_vol2snapen el volumen de origencluster2_src_svm:/cluster2_src_vol2.
En este caso, puede identificar la causa y las posibles acciones correctivas del error del trabajo. Sin embargo, para resolver el fallo es necesario acceder a la interfaz de usuario web de System Manager o a los comandos de la CLI de ONTAP.
-
Revisa el mensaje de error y determina que ha producido un error en un trabajo de copia Snapshot en el volumen de origen, lo que indica que probablemente haya un problema con el volumen de origen.
Si lo desea, puede hacer clic en el enlace Detalles del trabajo al final del mensaje de error, pero a efectos de este escenario, elige no hacerlo.
-
Decide que desea intentar resolver el evento, de modo que haga lo siguiente:
-
Haga clic en el botón asignar a y seleccione Me en el menú.
-
Haga clic en el botón Confirmar para que no siga recibiendo notificaciones de alerta de repetición, si se han configurado alertas para el evento.
-
Opcionalmente, también puede agregar notas sobre el evento.
-
-
Haga clic en el campo Fuente del panel Resumen para ver detalles sobre el volumen de origen.
El campo origen contiene el nombre del objeto de origen: En este caso, el volumen en el que se programó el trabajo de copia Snapshot.
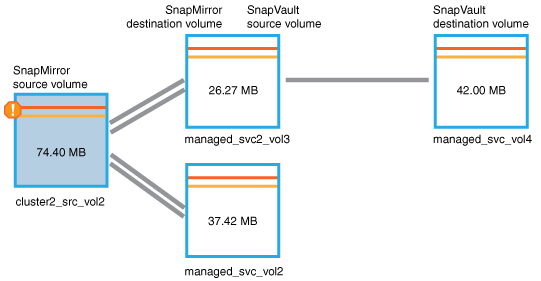
Se muestra la página de detalles volumen / Estado para
cluster2_src_vol2, Que muestra el contenido de la ficha Protección . -
Al ver el gráfico de topología de protección, se muestra un icono de error asociado con el primer volumen de la topología, que es el volumen de origen de la relación de SnapMirror.
También puede ver las barras horizontales en el icono de volumen de origen, que indican los umbrales de advertencia y error definidos para ese volumen.
-
Coloque el cursor sobre el icono de error para ver el cuadro de diálogo emergente que muestra la configuración del umbral y ver que el volumen ha superado el umbral de error, lo que indica un problema de capacidad.
-
Haga clic en la ficha capacidad.
Información de capacidad acerca de volumen
cluster2_src_vol2pantallas. -
En el panel capacidad, verá que hay un icono de error en el gráfico de barras, indicando de nuevo que la capacidad del volumen ha superado el nivel de umbral establecido para el volumen.
-
Debajo del gráfico de capacidad, puede ver que se deshabilitó el crecimiento automático del volumen y que se estableció una garantía de espacio de volumen.
Se puede decidir habilitar el crecimiento automático, pero para los fines de este escenario, se decide investigar más antes de tomar una decisión sobre cómo resolver el problema de capacidad.
-
Desplácese hacia abajo hasta la lista Eventos y vea que se generaron eventos error de trabajo de protección, volumen días hasta lleno y espacio de volumen lleno.
-
En la lista Eventos, usted hace clic en el evento espacio de volumen lleno para obtener más información, habiendo decidido que este evento parece más relevante para su problema de capacidad.
La página de detalles Event muestra el evento Volume Space Full para el volumen de origen.
-
En el área Resumen, lee el campo causa del evento:
The full threshold set at 90% is breached. 45.38 MB (95.54%) of 47.50 MB is used. -
Debajo del área Resumen, verá acciones correctivas sugeridas.

Las acciones correctivas sugeridas se muestran solo para algunos eventos, de modo que no se ve esta área para todos los tipos de eventos.
Haga clic en la lista de acciones sugeridas que puede realizar para resolver el evento Volume Space Full:
-
Habilite el crecimiento automático en este volumen.
-
Cambie el tamaño del volumen.
-
Habilite y ejecute la deduplicación en este volumen.
-
Habilite y ejecute la compresión en este volumen.
-
-
Decida habilitar el crecimiento automático en el volumen, pero para hacerlo, debe determinar el espacio libre disponible en el agregado principal y la tasa de crecimiento del volumen actual:
-
Observe el agregado principal,
cluster2_src_aggr1, En el panel dispositivos relacionados.
Puede hacer clic en el nombre del agregado para obtener más detalles sobre él.
Se determina que el agregado tiene espacio suficiente para habilitar el crecimiento automático del volumen.
-
En la parte superior de la página, observe el icono que indica una incidencia crítica y revise el texto debajo del icono.
Usted determina que "días a lleno: Menos de un día | tasa de crecimiento diario: 5.4%".
-
-
Vaya a System Manager o acceda a la CLI de ONTAP para habilitar el
volume autogrowopción.
Anote los nombres del volumen y del agregado para que estén disponibles al habilitar el crecimiento automático.
-
Después de resolver el problema de capacidad, vuelva a la página de detalles de Unified Manager evento y marque el evento como solucionado.