

Parte 2: Aprovechamiento de AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) como fuente de datos para el entrenamiento de modelos en SageMaker
 Sugerir cambios
Sugerir cambios
Este artículo es un tutorial sobre el uso de Amazon FSx for NetApp ONTAP (FSx ONTAP) para entrenar modelos de PyTorch en SageMaker, específicamente para un proyecto de clasificación de calidad de neumáticos.
Introducción
Este tutorial ofrece un ejemplo práctico de un proyecto de clasificación de visión artificial y proporciona experiencia práctica en la creación de modelos de aprendizaje automático que utilizan FSx ONTAP como fuente de datos dentro del entorno de SageMaker. El proyecto se centra en el uso de PyTorch, un marco de aprendizaje profundo, para clasificar la calidad de los neumáticos basándose en imágenes de neumáticos. Se enfatiza en el desarrollo de modelos de aprendizaje automático utilizando FSx ONTAP como fuente de datos en Amazon SageMaker.
¿Qué es FSx ONTAP?
Amazon FSx ONTAP es de hecho una solución de almacenamiento totalmente administrada ofrecida por AWS. Aprovecha el sistema de archivos ONTAP de NetApp para proporcionar almacenamiento confiable y de alto rendimiento. Con soporte para protocolos como NFS, SMB e iSCSI, permite un acceso sin inconvenientes desde diferentes instancias de cómputo y contenedores. El servicio está diseñado para ofrecer un rendimiento excepcional, garantizando operaciones de datos rápidas y eficientes. También ofrece alta disponibilidad y durabilidad, garantizando que sus datos permanezcan accesibles y protegidos. Además, la capacidad de almacenamiento de Amazon FSx ONTAP es escalable, lo que le permite ajustarla fácilmente según sus necesidades.
Requisito previo
Entorno de red
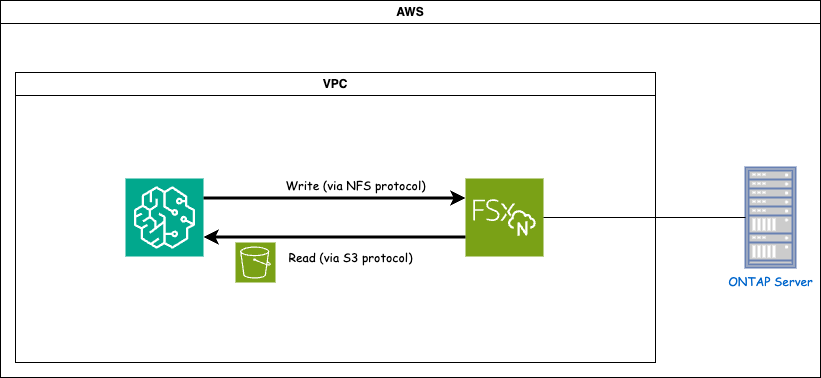
FSx ONTAP (Amazon FSx ONTAP) es un servicio de almacenamiento de AWS. Incluye un sistema de archivos que se ejecuta en el sistema NetApp ONTAP y una máquina virtual del sistema (SVM) administrada por AWS que se conecta a él. En el diagrama proporcionado, el servidor NetApp ONTAP administrado por AWS está ubicado fuera de la VPC. La SVM actúa como intermediario entre SageMaker y el sistema NetApp ONTAP , recibiendo solicitudes de operación de SageMaker y reenviándolas al almacenamiento subyacente. Para acceder a FSx ONTAP, SageMaker debe ubicarse dentro de la misma VPC que la implementación de FSx ONTAP . Esta configuración garantiza la comunicación y el acceso a los datos entre SageMaker y FSx ONTAP.
Acceso a datos
En escenarios del mundo real, los científicos de datos normalmente utilizan los datos existentes almacenados en FSx ONTAP para construir sus modelos de aprendizaje automático. Sin embargo, para fines de demostración, dado que el sistema de archivos FSx ONTAP está inicialmente vacío después de su creación, es necesario cargar manualmente los datos de entrenamiento. Esto se puede lograr montando FSx ONTAP como un volumen en SageMaker. Una vez que el sistema de archivos esté montado correctamente, puede cargar su conjunto de datos en la ubicación montada, lo que lo hará accesible para entrenar sus modelos dentro del entorno de SageMaker. Este enfoque le permite aprovechar la capacidad de almacenamiento y las capacidades de FSx ONTAP mientras trabaja con SageMaker para el desarrollo y entrenamiento de modelos.
El proceso de lectura de datos implica configurar FSx ONTAP como un depósito S3 privado. Para conocer las instrucciones de configuración detalladas, consulte"Parte 1: Integración de Amazon FSx for NetApp ONTAP (FSx ONTAP) como un bucket S3 privado en AWS SageMaker"
Descripción general de la integración
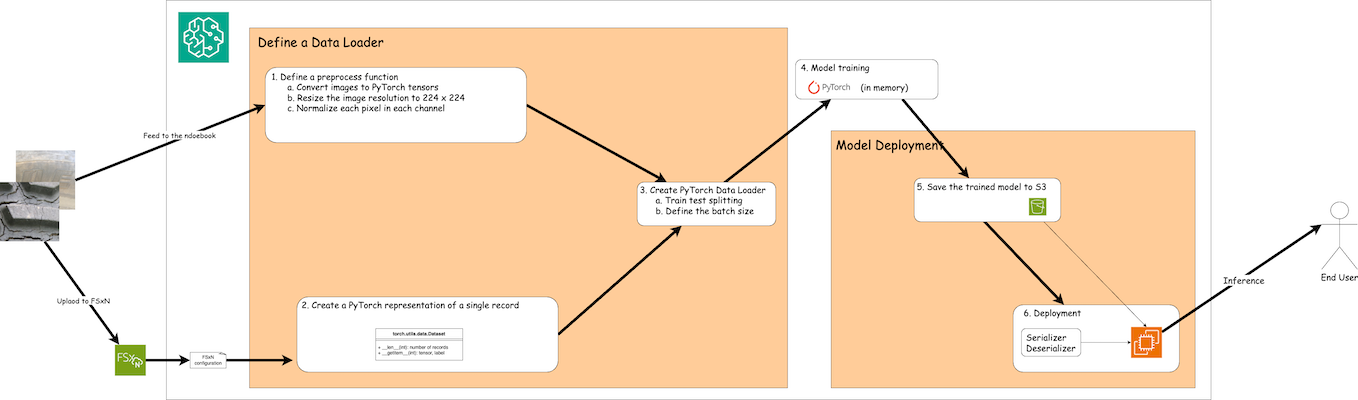
El flujo de trabajo de uso de datos de entrenamiento en FSx ONTAP para crear un modelo de aprendizaje profundo en SageMaker se puede resumir en tres pasos principales: definición del cargador de datos, entrenamiento del modelo e implementación. En un nivel alto, estos pasos forman la base de un flujo de trabajo MLOps. Sin embargo, cada paso implica varios subpasos detallados para una implementación integral. Estos subpasos abarcan varias tareas, como el preprocesamiento de datos, la división del conjunto de datos, la configuración del modelo, el ajuste de hiperparámetros, la evaluación del modelo y la implementación del modelo. Estos pasos garantizan un proceso exhaustivo y eficaz para crear e implementar modelos de aprendizaje profundo utilizando datos de entrenamiento de FSx ONTAP dentro del entorno de SageMaker.
Integración paso a paso
Loader de datos
Para entrenar una red de aprendizaje profundo de PyTorch con datos, se crea un cargador de datos para facilitar la alimentación de datos. El cargador de datos no solo define el tamaño del lote, sino que también determina el procedimiento para leer y preprocesar cada registro dentro del lote. Al configurar el cargador de datos, podemos gestionar el procesamiento de datos en lotes, lo que permite el entrenamiento de la red de aprendizaje profundo.
El cargador de datos consta de 3 partes.
Función de preprocesamiento
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])El fragmento de código anterior demuestra la definición de transformaciones de preprocesamiento de imágenes utilizando el módulo torchvision.transforms. En este tutorial, se crea el objeto de preproceso para aplicar una serie de transformaciones. En primer lugar, la transformación ToTensor() convierte la imagen en una representación tensorial. Posteriormente, la transformación Resize224,224 redimensiona la imagen a un tamaño fijo de 224x224 píxeles. Finalmente, la transformación Normalize() normaliza los valores del tensor restando la media y dividiéndolos por la desviación estándar a lo largo de cada canal. Los valores de media y desviación estándar utilizados para la normalización se emplean comúnmente en modelos de redes neuronales preentrenados. En general, este código prepara los datos de la imagen para su posterior procesamiento o ingreso a un modelo entrenado previamente convirtiéndolos en un tensor, redimensionándolos y normalizando los valores de los píxeles.
La clase de conjunto de datos de PyTorch
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, labelEsta clase proporciona funcionalidad para obtener el número total de registros en el conjunto de datos y define el método para leer datos para cada registro. Dentro de la función getitem, el código utiliza el objeto bucket S3 boto3 para recuperar los datos binarios de FSx ONTAP. El estilo de código para acceder a datos de FSx ONTAP es similar al de leer datos de Amazon S3. La explicación siguiente profundiza en el proceso de creación del objeto privado S3 bucket.
FSx ONTAP como repositorio privado de S3
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---Para leer datos de FSx ONTAP en SageMaker, se crea un controlador que apunta al almacenamiento de FSx ONTAP mediante el protocolo S3. Esto permite que FSx ONTAP sea tratado como un depósito S3 privado. La configuración del controlador incluye la especificación de la dirección IP del SVM de FSx ONTAP , el nombre del depósito y las credenciales necesarias. Para obtener una explicación completa sobre cómo obtener estos elementos de configuración, consulte el documento en"Parte 1: Integración de Amazon FSx for NetApp ONTAP (FSx ONTAP) como un bucket S3 privado en AWS SageMaker" .
En el ejemplo mencionado anteriormente, el objeto bucket se utiliza para crear una instancia del objeto de conjunto de datos de PyTorch. El objeto del conjunto de datos se explicará con más detalle en la sección siguiente.
El Loader de datos de PyTorch
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)En el ejemplo proporcionado, se especifica un tamaño de lote de 64, lo que indica que cada lote contendrá 64 registros. Al combinar la clase Dataset de PyTorch, la función de preprocesamiento y el tamaño del lote de entrenamiento, obtenemos el cargador de datos para el entrenamiento. Este cargador de datos facilita el proceso de iteración a través del conjunto de datos en lotes durante la fase de entrenamiento.
Entrenamiento de modelos
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')Este código implementa un proceso de entrenamiento estándar de PyTorch. Define un modelo de red neuronal llamado TyreQualityClassifier que utiliza capas convolucionales y una capa lineal para clasificar la calidad de los neumáticos. El bucle de entrenamiento itera sobre lotes de datos, calcula la pérdida y actualiza los parámetros del modelo mediante retropropagación y optimización. Además, imprime la hora actual, la época, el lote y la pérdida para fines de monitoreo.
Implementación del modelo
Despliegue
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())El código guarda el modelo de PyTorch en Amazon S3 porque SageMaker requiere que el modelo se almacene en S3 para su implementación. Al cargar el modelo en Amazon S3, se vuelve accesible para SageMaker, lo que permite la implementación y la inferencia en el modelo implementado.
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)Este código facilita la implementación de un modelo de PyTorch en SageMaker. Define un serializador personalizado, TyreQualitySerializer, que preprocesa y serializa los datos de entrada como un tensor de PyTorch. La clase TyreQualityPredictor es un predictor personalizado que utiliza el serializador definido y un JSONDeserializer. El código también crea un objeto PyTorchModel para especificar la ubicación S3 del modelo, la función IAM, la versión del marco y el punto de entrada para la inferencia. El código genera una marca de tiempo y construye un nombre de punto final basado en el modelo y la marca de tiempo. Finalmente, el modelo se implementa utilizando el método de implementación, especificando la cantidad de instancias, el tipo de instancia y el nombre del punto final generado. Esto permite que el modelo PyTorch se implemente y sea accesible para inferencia en SageMaker.
Inferencia
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)Este es el ejemplo del uso del punto final implementado para realizar la inferencia.