

TR-4570: Soluciones de almacenamiento de NetApp para Apache Spark: Arquitectura, casos de uso y resultados de rendimiento
 Sugerir cambios
Sugerir cambios
Rick Huang, Karthikeyan Nagalingam, NetApp
Este documento se centra en la arquitectura Apache Spark, los casos de uso de los clientes y la cartera de almacenamiento de NetApp relacionada con el análisis de big data y la inteligencia artificial (IA). También presenta varios resultados de pruebas utilizando herramientas de inteligencia artificial, aprendizaje automático (ML) y aprendizaje profundo (DL) estándar de la industria contra un sistema Hadoop típico para que pueda elegir la solución Spark adecuada. Para comenzar, necesita una arquitectura Spark, componentes apropiados y dos modos de implementación (clúster y cliente).
Este documento también proporciona casos de uso de clientes para abordar problemas de configuración y analiza una descripción general de la cartera de almacenamiento de NetApp relevante para análisis de big data e IA, ML y DL con Spark. Luego finalizamos con los resultados de las pruebas derivadas de los casos de uso específicos de Spark y la cartera de soluciones NetApp Spark.
Desafíos del cliente
Esta sección se centra en los desafíos de los clientes con el análisis de big data y la IA/ML/DL en industrias de crecimiento de datos, como el comercio minorista, el marketing digital, la banca, la fabricación discreta, la fabricación de procesos, el gobierno y los servicios profesionales.
Rendimiento impredecible
Las implementaciones tradicionales de Hadoop generalmente utilizan hardware básico. Para mejorar el rendimiento, debe ajustar la red, el sistema operativo, el clúster Hadoop, los componentes del ecosistema como Spark y el hardware. Incluso si ajusta cada capa, puede ser difícil lograr los niveles de rendimiento deseados porque Hadoop se ejecuta en hardware básico que no fue diseñado para un alto rendimiento en su entorno.
Fallos de medios y nodos
Incluso en condiciones normales, el hardware comercial es propenso a fallar. Si falla un disco en un nodo de datos, el maestro Hadoop considera, por defecto, que ese nodo no está en buen estado. Luego, copia datos específicos de ese nodo a través de la red desde réplicas a un nodo en buen estado. Este proceso ralentiza los paquetes de red para cualquier trabajo de Hadoop. Luego, el clúster debe volver a copiar los datos y eliminar los datos sobre replicados cuando el nodo en mal estado vuelva a un estado correcto.
Dependencia del proveedor de Hadoop
Los distribuidores de Hadoop tienen su propia distribución de Hadoop con su propia versión, lo que limita al cliente a esas distribuciones. Sin embargo, muchos clientes requieren soporte para análisis en memoria que no vincule al cliente a distribuciones específicas de Hadoop. Necesitan la libertad de cambiar distribuciones y aún así llevar consigo sus análisis.
Falta de soporte para más de un idioma
Los clientes a menudo necesitan soporte para varios idiomas además de los programas Java MapReduce para ejecutar sus trabajos. Opciones como SQL y scripts brindan más flexibilidad para obtener respuestas, más opciones para organizar y recuperar datos y formas más rápidas de mover datos a un marco de análisis.
Dificultad de uso
Desde hace algún tiempo, la gente se ha quejado de que Hadoop es difícil de usar. Aunque Hadoop se ha vuelto más simple y más poderoso con cada nueva versión, esta crítica ha persistido. Hadoop requiere que usted comprenda los patrones de programación Java y MapReduce, un desafío para los administradores de bases de datos y personas con habilidades de programación tradicionales.
Marcos y herramientas complicados
Los equipos de IA empresariales enfrentan múltiples desafíos. Incluso con un conocimiento experto en ciencia de datos, las herramientas y los marcos para diferentes ecosistemas de implementación y aplicaciones podrían no ser fácilmente trasladables de uno a otro. Una plataforma de ciencia de datos debe integrarse perfectamente con las plataformas de big data correspondientes creadas en Spark con facilidad de movimiento de datos, modelos reutilizables, código listo para usar y herramientas que respalden las mejores prácticas para crear prototipos, validar, controlar versiones, compartir, reutilizar e implementar rápidamente modelos en producción.
¿Por qué elegir NetApp?
NetApp puede mejorar su experiencia con Spark de las siguientes maneras:
-
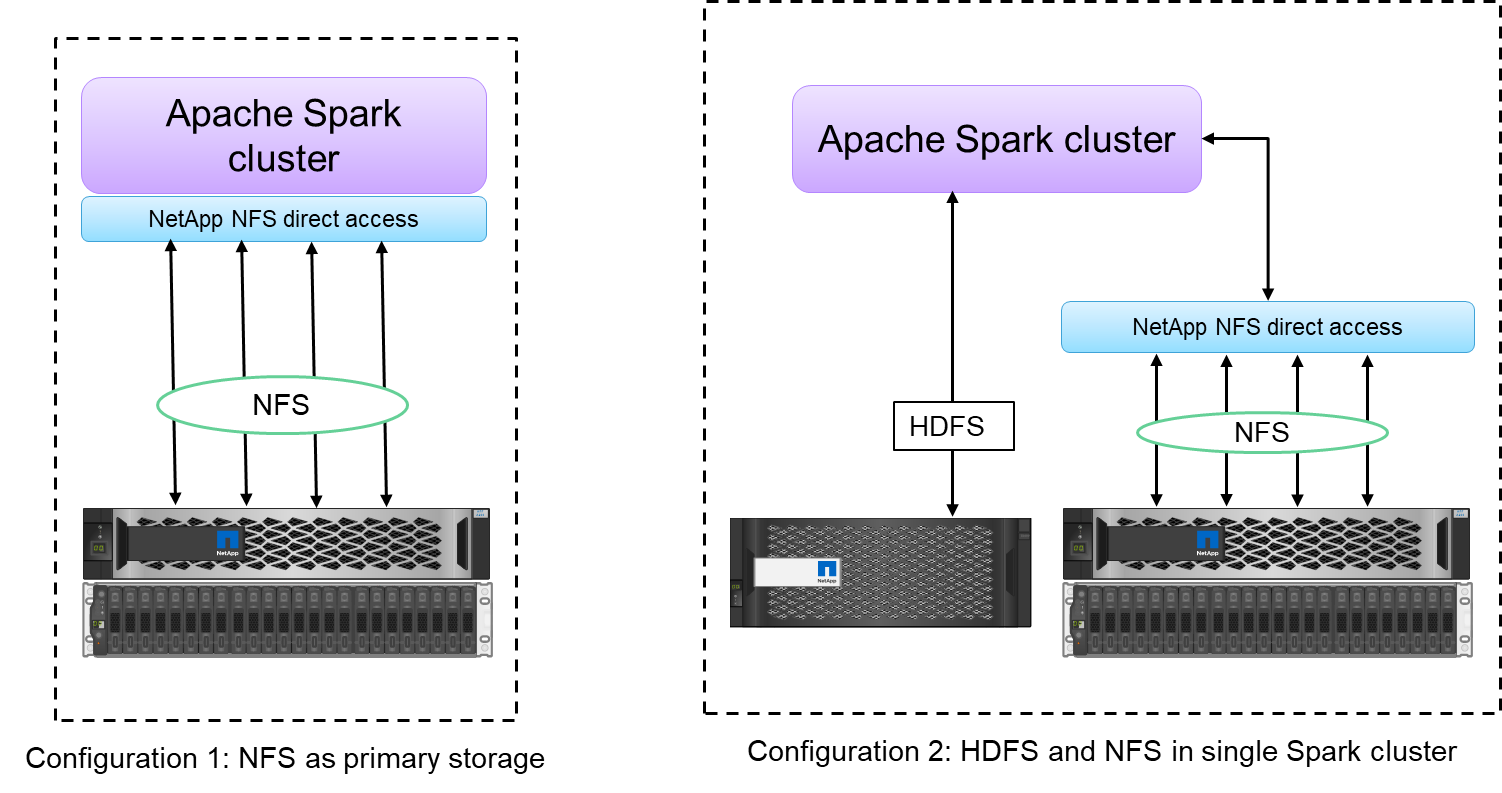
El acceso directo a NFS de NetApp (que se muestra en la figura a continuación) permite a los clientes ejecutar trabajos de análisis de big data en sus datos NFSv3 o NFSv4 existentes o nuevos sin mover ni copiar los datos. Evita copias múltiples de datos y elimina la necesidad de sincronizar los datos con una fuente.
-
Almacenamiento más eficiente y menos replicación de servidores. Por ejemplo, la solución NetApp E-Series Hadoop requiere dos en lugar de tres réplicas de los datos, y la solución FAS Hadoop requiere una fuente de datos pero no replicación ni copias de datos. Las soluciones de almacenamiento de NetApp también producen menos tráfico de servidor a servidor.
-
Mejor comportamiento de los trabajos y clústeres de Hadoop durante fallas de unidades y nodos.
-
Mejor rendimiento en la ingesta de datos.
Por ejemplo, en el sector financiero y sanitario, el traslado de datos de un lugar a otro debe cumplir obligaciones legales, lo que no es una tarea fácil. En este escenario, el acceso directo de NetApp NFS analiza los datos financieros y de atención médica desde su ubicación original. Otro beneficio clave es que el uso del acceso directo NFS de NetApp simplifica la protección de los datos de Hadoop mediante el uso de comandos nativos de Hadoop y la habilitación de flujos de trabajo de protección de datos con la amplia cartera de gestión de datos de NetApp.
El acceso directo NFS de NetApp ofrece dos tipos de opciones de implementación para clústeres Hadoop/Spark:
-
De forma predeterminada, los clústeres Hadoop o Spark utilizan el sistema de archivos distribuido Hadoop (HDFS) para el almacenamiento de datos y el sistema de archivos predeterminado. El acceso directo NFS de NetApp puede reemplazar el HDFS predeterminado con almacenamiento NFS como sistema de archivos predeterminado, lo que permite el análisis directo de datos NFS.
-
En otra opción de implementación, el acceso directo NFS de NetApp admite la configuración de NFS como almacenamiento adicional junto con HDFS en un solo clúster Hadoop o Spark. En este caso, el cliente puede compartir datos a través de exportaciones NFS y acceder a ellos desde el mismo clúster junto con los datos HDFS.
Los beneficios clave de utilizar el acceso directo NFS de NetApp incluyen los siguientes:
-
Analizar los datos desde su ubicación actual, lo que evita la tarea, que consume mucho tiempo y rendimiento, de mover datos analíticos a una infraestructura Hadoop como HDFS.
-
Reducir el número de réplicas de tres a una.
-
Permitir a los usuarios disociar el procesamiento y el almacenamiento para escalarlos de forma independiente.
-
Proporcionar protección de datos empresariales aprovechando las ricas capacidades de gestión de datos de ONTAP.
-
Certificación con la plataforma de datos Hortonworks.
-
Habilitación de implementaciones de análisis de datos híbridos.
-
Reducir el tiempo de backup aprovechando la capacidad multihilo dinámico.
Ver"TR-4657: Soluciones de datos en la nube híbrida de NetApp : Spark y Hadoop, basadas en casos de uso de clientes" para realizar copias de seguridad de datos de Hadoop, realizar copias de seguridad y recuperación ante desastres desde la nube a las instalaciones locales, habilitar DevTest en datos de Hadoop existentes, protección de datos y conectividad multicloud, y acelerar las cargas de trabajo de análisis.
Las siguientes secciones describen las capacidades de almacenamiento que son importantes para los clientes de Spark.
Nivelación de almacenamiento
Con los niveles de almacenamiento de Hadoop, puede almacenar archivos con diferentes tipos de almacenamiento de acuerdo con una política de almacenamiento. Los tipos de almacenamiento incluyen hot , cold , warm , all_ssd , one_ssd , y lazy_persist .
Realizamos la validación de la clasificación en niveles del almacenamiento de Hadoop en un controlador de almacenamiento NetApp AFF y un controlador de almacenamiento E-Series con unidades SSD y SAS con diferentes políticas de almacenamiento. El clúster Spark con AFF-A800 tiene cuatro nodos de trabajo de cómputo, mientras que el clúster con E-Series tiene ocho. Esto es principalmente para comparar el rendimiento de las unidades de estado sólido (SSD) frente a los discos duros (HDD).
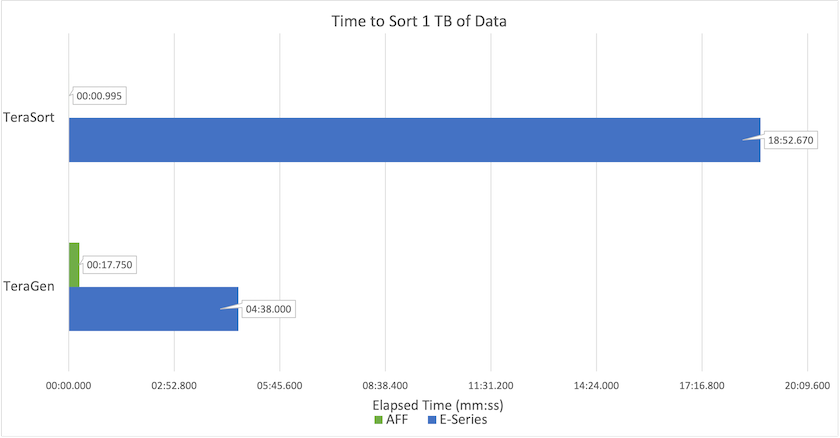
La siguiente figura muestra el rendimiento de las soluciones NetApp para un SSD Hadoop.
-
La configuración básica de NL-SAS utilizó ocho nodos de cómputo y 96 unidades NL-SAS. Esta configuración generó 1 TB de datos en 4 minutos y 38 segundos. Ver "Solución NetApp E-Series TR-3969 para Hadoop" para obtener detalles sobre la configuración del clúster y del almacenamiento.
-
Con TeraGen, la configuración SSD generó 1 TB de datos 15,66 veces más rápido que la configuración NL-SAS. Además, la configuración SSD utilizó la mitad del número de nodos de cómputo y la mitad del número de unidades de disco (24 unidades SSD en total). Según el tiempo de finalización del trabajo, fue casi el doble de rápido que la configuración NL-SAS.
-
Con TeraSort, la configuración SSD ordenó 1 TB de datos 1138,36 veces más rápido que la configuración NL-SAS. Además, la configuración SSD utilizó la mitad del número de nodos de cómputo y la mitad del número de unidades de disco (24 unidades SSD en total). Por lo tanto, por unidad, fue aproximadamente tres veces más rápido que la configuración NL-SAS.
-
La conclusión es que la transición de los discos giratorios a la tecnología flash mejora el rendimiento. El número de nodos de cómputo no fue el cuello de botella. Con el almacenamiento all-flash de NetApp, el rendimiento en tiempo de ejecución escala bien.
-
Con NFS, los datos eran funcionalmente equivalentes a estar agrupados todos juntos, lo que puede reducir la cantidad de nodos de cómputo según su carga de trabajo. Los usuarios del clúster Apache Spark no tienen que reequilibrar manualmente los datos al cambiar la cantidad de nodos de cómputo.
Escalado del rendimiento - Escalamiento horizontal
Cuando necesita más potencia de procesamiento de un clúster Hadoop en una solución AFF , puede agregar nodos de datos con una cantidad adecuada de controladores de almacenamiento. NetApp recomienda comenzar con cuatro nodos de datos por matriz de controlador de almacenamiento y aumentar la cantidad a ocho nodos de datos por controlador de almacenamiento, según las características de la carga de trabajo.
AFF y FAS son perfectos para análisis in situ. Según los requisitos de cálculo, puede agregar administradores de nodos, y las operaciones no disruptivas le permiten agregar un controlador de almacenamiento a pedido sin tiempo de inactividad. Ofrecemos funciones avanzadas con AFF y FAS, como compatibilidad con medios NVME, eficiencia garantizada, reducción de datos, calidad de servicio, análisis predictivo, niveles de nube, replicación, implementación de nube y seguridad. Para ayudar a los clientes a satisfacer sus necesidades, NetApp ofrece funciones como análisis del sistema de archivos, cuotas y equilibrio de carga integrado sin costos de licencia adicionales. NetApp tiene un mejor rendimiento en cantidad de trabajos simultáneos, menor latencia, operaciones más simples y mayor rendimiento de gigabytes por segundo que nuestros competidores. Además, NetApp Cloud Volumes ONTAP se ejecuta en los tres principales proveedores de nube.
Escalado del rendimiento: escalar hacia arriba
Las funciones de ampliación le permiten agregar unidades de disco a los sistemas AFF, FAS y E-Series cuando necesita capacidad de almacenamiento adicional. Con Cloud Volumes ONTAP, escalar el almacenamiento al nivel de PB es una combinación de dos factores: agrupar los datos poco utilizados en el almacenamiento de objetos desde el almacenamiento en bloque y apilar licencias de Cloud Volumes ONTAP sin procesamiento adicional.
Múltiples protocolos
Los sistemas NetApp admiten la mayoría de los protocolos para implementaciones de Hadoop, incluidos SAS, iSCSI, FCP, InfiniBand y NFS.
Soluciones operativas y soportadas
Las soluciones Hadoop descritas en este documento son compatibles con NetApp. Estas soluciones también están certificadas con los principales distribuidores de Hadoop. Para obtener más información, consulte la "Hortonworks" sitio y Cloudera "proceso de dar un título" y "pareja" sitios.