

Tecnología de soluciones
 Sugerir cambios
Sugerir cambios
Apache Spark es un marco de programación popular para escribir aplicaciones Hadoop que funciona directamente con el sistema de archivos distribuidos Hadoop (HDFS). Spark está listo para producción, admite el procesamiento de datos de transmisión y es más rápido que MapReduce. Spark tiene almacenamiento en caché de datos en memoria configurable para una iteración eficiente, y el shell de Spark es interactivo para aprender y explorar datos. Con Spark, puedes crear aplicaciones en Python, Scala o Java. Las aplicaciones Spark constan de uno o más trabajos que tienen una o más tareas.
Cada aplicación Spark tiene un controlador Spark. En el modo YARN-Client, el controlador se ejecuta en el cliente localmente. En el modo YARN-Cluster, el controlador se ejecuta en el clúster en el maestro de aplicaciones. En el modo de clúster, la aplicación continúa ejecutándose incluso si el cliente se desconecta.
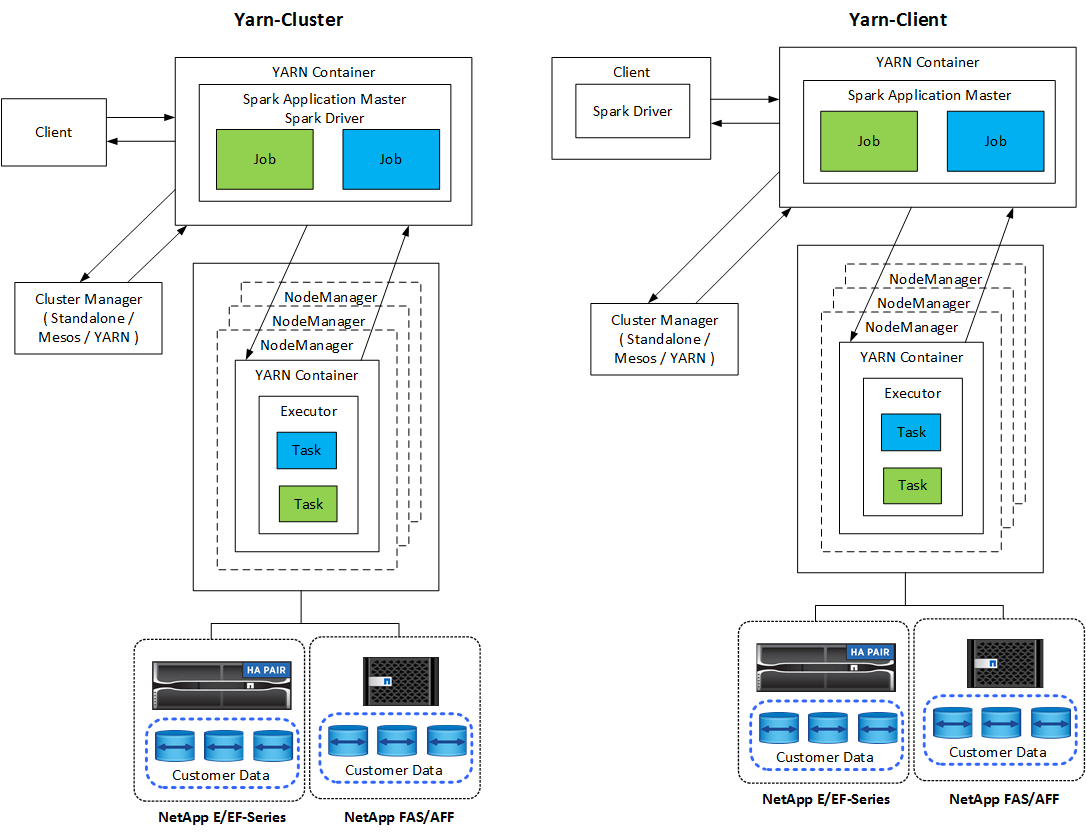
Hay tres administradores de clúster:
-
Autónomo. Este administrador es parte de Spark, lo que facilita la configuración de un clúster.
-
Mesos Apache. Este es un administrador de clúster general que también ejecuta MapReduce y otras aplicaciones.
-
HILO DE HADOOP. Este es un administrador de recursos en Hadoop 3.
El conjunto de datos distribuidos resilientes (RDD) es el componente principal de Spark. RDD recrea los datos perdidos y faltantes a partir de los datos almacenados en la memoria del clúster y almacena los datos iniciales que provienen de un archivo o se crean mediante programación. Los RDD se crean a partir de archivos, datos en la memoria u otro RDD. La programación Spark realiza dos operaciones: transformación y acciones. La transformación crea un nuevo RDD basado en uno existente. Las acciones devuelven un valor de un RDD.
Las transformaciones y acciones también se aplican a los conjuntos de datos y marcos de datos de Spark. Un conjunto de datos es una colección distribuida de datos que proporciona los beneficios de los RDD (tipificación fuerte, uso de funciones lambda) con los beneficios del motor de ejecución optimizado de Spark SQL. Se puede construir un conjunto de datos a partir de objetos JVM y luego manipularlo mediante transformaciones funcionales (mapa, flatMap, filtro, etc.). Un DataFrame es un conjunto de datos organizado en columnas con nombre. Es conceptualmente equivalente a una tabla en una base de datos relacional o un marco de datos en R/Python. Los DataFrames se pueden construir a partir de una amplia variedad de fuentes, como archivos de datos estructurados, tablas en Hive/HBase, bases de datos externas locales o en la nube, o RDD existentes.
Las aplicaciones Spark incluyen uno o más trabajos Spark. Los trabajos ejecutan tareas en ejecutores, y los ejecutores se ejecutan en contenedores YARN. Cada ejecutor se ejecuta en un solo contenedor y los ejecutores existen durante toda la vida de una aplicación. Un ejecutor se fija después de que se inicia la aplicación y YARN no redimensiona el contenedor ya asignado. Un ejecutor puede ejecutar tareas simultáneamente en datos en memoria.