Resultados de las pruebas
 Sugerir cambios
Sugerir cambios
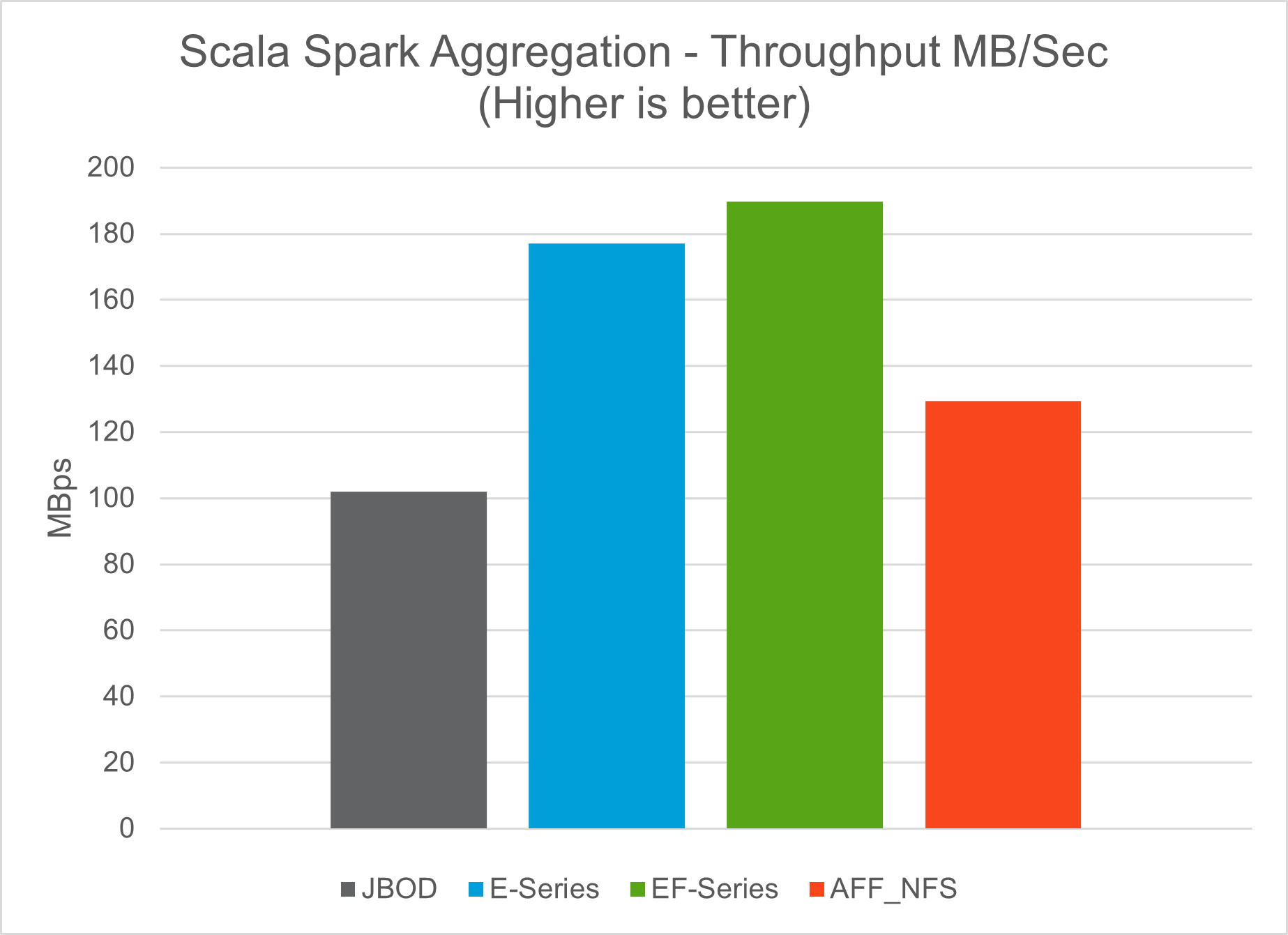
Utilizamos los scripts TeraSort y TeraValidate en la herramienta de evaluación comparativa TeraGen para medir la validación del rendimiento de Spark con configuraciones E5760, E5724 y AFF-A800. Además, se probaron tres casos de uso principales: pipelines de Spark NLP y capacitación distribuida de TensorFlow, capacitación distribuida de Horovod y aprendizaje profundo de múltiples trabajadores usando Keras para predicción de CTR con DeepFM.
Para la validación de E-Series y StorageGRID , utilizamos el factor de replicación de Hadoop 2. Para la validación de AFF , solo utilizamos una fuente de datos.
La siguiente tabla enumera la configuración de hardware para la validación del rendimiento de Spark.
| Tipo | Nodos de trabajo de Hadoop | Tipo de unidad | Unidades por nodo | Controlador de almacenamiento |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
Par único de alta disponibilidad (HA) |
E5760 |
4 |
SAS |
60 |
Par de HA único |
E5724 |
4 |
SAS |
24 |
Par de HA único |
AFF800 |
4 |
Unidad de estado sólido |
6 |
Par de HA único |
La siguiente tabla enumera los requisitos de software.
| Software | Versión |
|---|---|
RHEL |
7,9 |
Entorno de ejecución de OpenJDK |
1.8.0 |
Máquina virtual de servidor OpenJDK de 64 bits |
25,302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
Chispa |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
Flujo de tensor |
2.9.0 |
Keras |
2.9.0 |
Horovod |
0.24.3 |
Análisis del sentimiento financiero
Nosotros publicamos"TR-4910: Análisis de sentimientos de las comunicaciones de los clientes con NetApp AI" , en el que se construyó una canalización de IA conversacional de extremo a extremo utilizando "Kit de herramientas DataOps de NetApp" , almacenamiento AFF y sistema NVIDIA DGX. El pipeline realiza procesamiento de señales de audio por lotes, reconocimiento automático de voz (ASR), aprendizaje por transferencia y análisis de sentimientos aprovechando el kit de herramientas DataOps. "SDK de NVIDIA Riva" , y el "Marco del Tao" . Al ampliar el caso de uso del análisis de sentimientos a la industria de servicios financieros, creamos un flujo de trabajo SparkNLP, cargamos tres modelos BERT para varias tareas de PNL, como el reconocimiento de entidades nombradas, y obtuvimos sentimientos a nivel de oración para las llamadas de ganancias trimestrales de las 10 principales empresas del NASDAQ.
El siguiente script sentiment_analysis_spark. py utiliza el modelo FinBERT para procesar transcripciones en HDFS y producir recuentos de sentimientos positivos, neutrales y negativos, como se muestra en la siguiente tabla:
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
La siguiente tabla enumera el análisis de sentimiento a nivel de oración, tras la presentación de resultados, de las 10 principales empresas del NASDAQ de 2016 a 2020.
| Recuentos y porcentajes de sentimientos | Las 10 empresas | AAPL | AMD | Amazon | Director Ejecutivo | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Recuentos positivos |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
Conteos neutrales |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
Recuentos negativos |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
Recuentos sin categorizar |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(recuentos totales) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
En términos de porcentajes, la mayoría de las frases pronunciadas por los directores ejecutivos y directores financieros son factuales y, por lo tanto, transmiten un sentimiento neutral. Durante una conferencia telefónica sobre ganancias, los analistas hacen preguntas que pueden transmitir un sentimiento positivo o negativo. Vale la pena investigar más a fondo cuantitativamente cómo el sentimiento negativo o positivo afecta los precios de las acciones el mismo día o el siguiente de negociación.
La siguiente tabla enumera el análisis de sentimiento a nivel de oración para las 10 principales empresas del NASDAQ, expresado en porcentaje.
| Porcentaje de sentimiento | Las 10 empresas | AAPL | AMD | Amazon | Director Ejecutivo | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Positivo |
10.13% |
18.06% |
8.69% |
5.24% |
9.07% |
12.08% |
11.44% |
13.25% |
6.23% |
Neutral |
87.17% |
79.02% |
88.82% |
91.87% |
88.42% |
86.50% |
84.65% |
83.77% |
92.44% |
Negativo |
2.43% |
2.92% |
2.49% |
1.52% |
2.51% |
1.42% |
3.91% |
2.96% |
1.33% |
Sin categorizar |
0.27% |
0% |
0% |
1.37% |
0% |
0% |
0% |
0.01% |
0% |
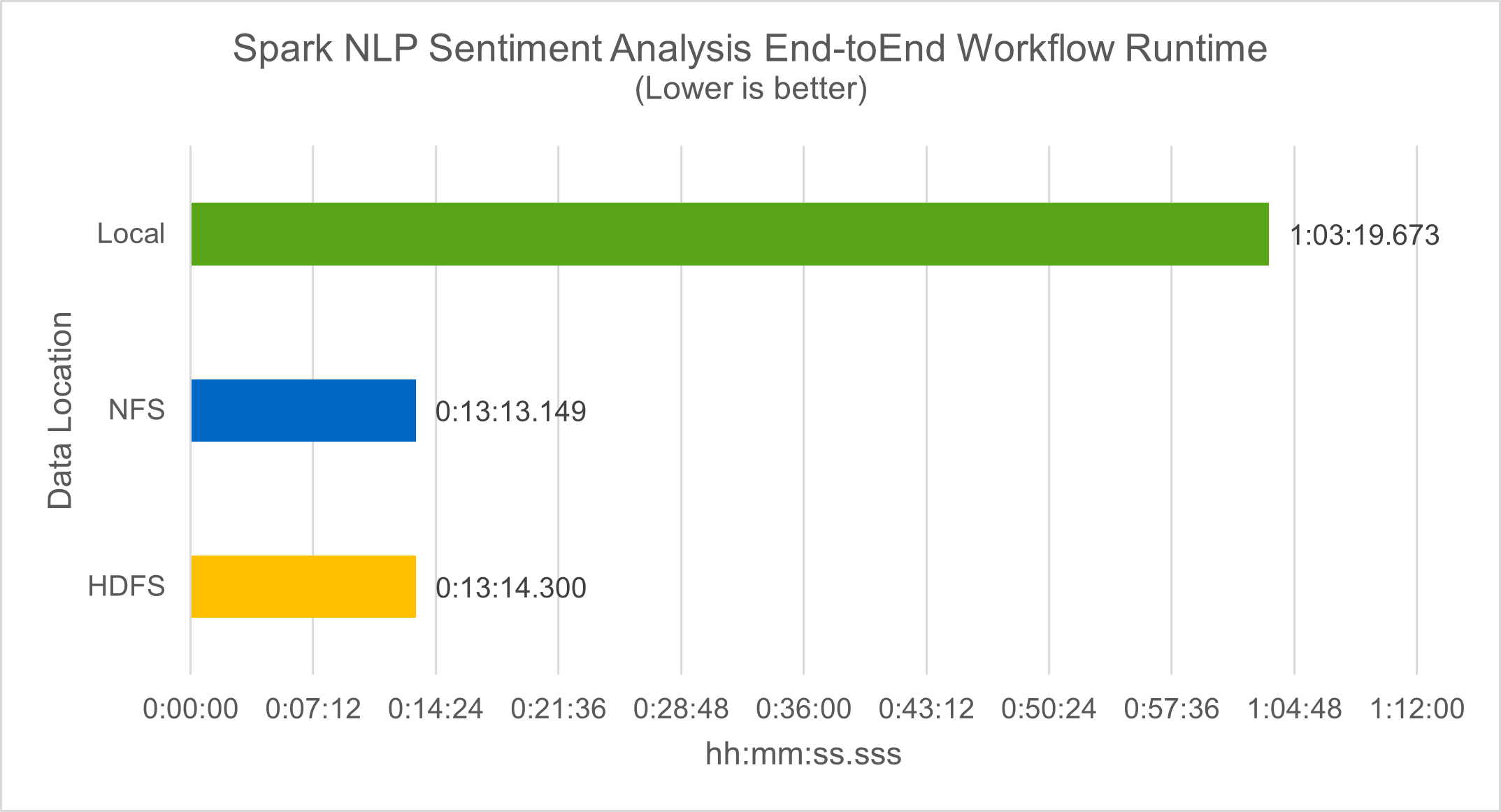
En términos del tiempo de ejecución del flujo de trabajo, vimos una mejora significativa de 4,78x local modo a un entorno distribuido en HDFS y una mejora adicional del 0,14 % al aprovechar NFS.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
Como muestra la siguiente figura, el paralelismo de datos y modelos mejoró el procesamiento de datos y la velocidad de inferencia del modelo distribuido de TensorFlow. La ubicación de datos en NFS produjo un tiempo de ejecución ligeramente mejor porque el cuello de botella del flujo de trabajo es la descarga de modelos previamente entrenados. Si aumentamos el tamaño del conjunto de datos de transcripciones, la ventaja de NFS es más obvia.
Entrenamiento distribuido con rendimiento de Horovod
El siguiente comando produjo información de tiempo de ejecución y un archivo de registro en nuestro clúster Spark usando un solo master nodo con 160 ejecutores cada uno con un núcleo. La memoria del ejecutor se limitó a 5 GB para evitar errores de falta de memoria. Ver la sección"Scripts de Python para cada caso de uso principal" Para obtener más detalles sobre el procesamiento de datos, el entrenamiento del modelo y el cálculo de la precisión del modelo en keras_spark_horovod_rossmann_estimator.py .
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
El tiempo de ejecución resultante con diez épocas de entrenamiento fue el siguiente:
real43m34.608s user12m22.057s sys2m30.127s
Se necesitaron más de 43 minutos para procesar datos de entrada, entrenar un modelo DNN, calcular la precisión y producir puntos de control de TensorFlow y un archivo CSV para los resultados de la predicción. Limitamos el número de épocas de entrenamiento a 10, que en la práctica suele establecerse en 100 para garantizar una precisión satisfactoria del modelo. El tiempo de entrenamiento normalmente se escala linealmente con el número de épocas.
A continuación, utilizamos los cuatro nodos de trabajo disponibles en el clúster y ejecutamos el mismo script en yarn modo con datos en HDFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
El tiempo de ejecución resultante se mejoró de la siguiente manera:
real8m13.728s user7m48.421s sys1m26.063s
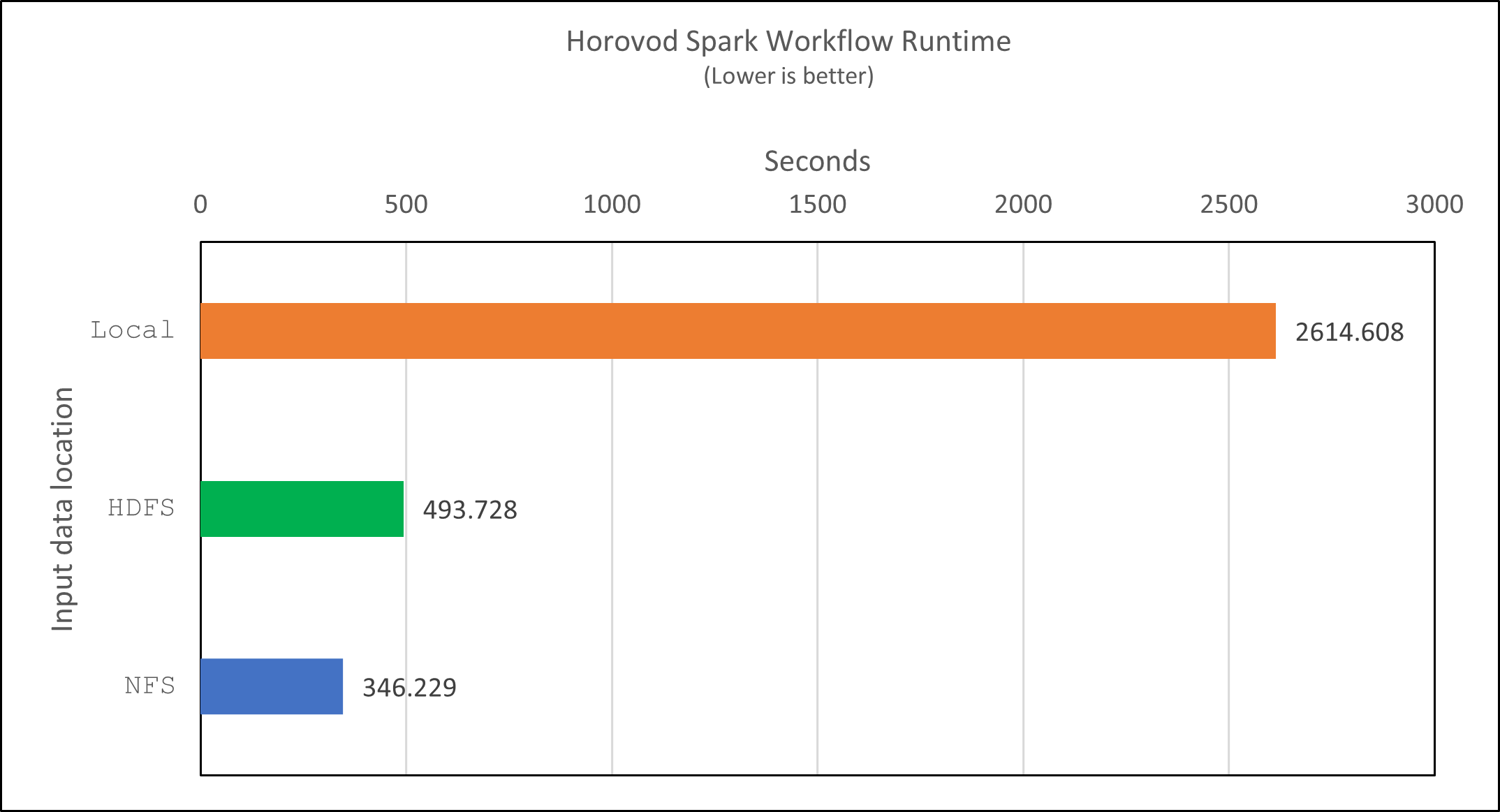
Con el modelo de Horovod y el paralelismo de datos en Spark, vimos una aceleración del tiempo de ejecución de 5,29x yarn versus local Modo con diez épocas de entrenamiento. Esto se muestra en la siguiente figura con las leyendas. HDFS y Local . El entrenamiento del modelo DNN de TensorFlow subyacente se puede acelerar aún más con GPU si están disponibles. Planeamos realizar estas pruebas y publicar los resultados en un futuro informe técnico.
Nuestra siguiente prueba comparó los tiempos de ejecución con datos de entrada que residen en NFS versus HDFS. El volumen NFS en el AFF A800 se montó en /sparkdemo/horovod en los cinco nodos (uno maestro y cuatro trabajadores) de nuestro clúster Spark. Ejecutamos un comando similar al de las pruebas anteriores, con el --data- dir parámetro que ahora apunta al montaje NFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
El tiempo de ejecución resultante con NFS fue el siguiente:
real 5m46.229s user 5m35.693s sys 1m5.615s
Hubo una aceleración adicional de 1,43x, como se muestra en la siguiente figura. Por lo tanto, con un almacenamiento all-flash de NetApp conectado a su clúster, los clientes disfrutan de los beneficios de la transferencia y distribución rápida de datos para los flujos de trabajo de Horovod Spark, logrando una aceleración de 7,55 veces en comparación con la ejecución en un solo nodo.
Modelos de aprendizaje profundo para el rendimiento de la predicción de CTR
Para los sistemas de recomendación diseñados para maximizar el CTR, es necesario aprender interacciones de características sofisticadas detrás de los comportamientos de los usuarios que se puedan calcular matemáticamente desde el orden bajo hasta el orden alto. Las interacciones de características de orden bajo y de orden alto deberían ser igualmente importantes para un buen modelo de aprendizaje profundo sin sesgarse hacia una u otra. Deep Factorization Machine (DeepFM), una red neuronal basada en máquinas de factorización, combina máquinas de factorización para recomendación y aprendizaje profundo para el aprendizaje de características en una nueva arquitectura de red neuronal.
Aunque las máquinas de factorización convencionales modelan interacciones de características por pares como un producto interno de vectores latentes entre características y teóricamente pueden capturar información de alto orden, en la práctica los profesionales del aprendizaje automático usualmente solo usan interacciones de características de segundo orden debido a la alta complejidad de cálculo y almacenamiento. Variantes de redes neuronales profundas como la de Google "Modelos anchos y profundos" Por otro lado, aprende interacciones de características sofisticadas en una estructura de red híbrida combinando un modelo lineal amplio y un modelo profundo.
Hay dos entradas para este modelo amplio y profundo: una para el modelo amplio subyacente y otra para el profundo; la última parte aún requiere ingeniería de características experta y, por lo tanto, hace que la técnica sea menos generalizable a otros dominios. A diferencia del modelo ancho y profundo, DeepFM se puede entrenar de manera eficiente con características sin procesar sin ninguna ingeniería de características porque su parte ancha y su parte profunda comparten la misma entrada y el vector de incrustación.
Primero procesamos el Criteo train.txt (11 GB) en un archivo CSV llamado ctr_train.csv almacenado en un montaje NFS /sparkdemo/tr-4570-data usando run_classification_criteo_spark.py de la sección"Scripts de Python para cada caso de uso principal." Dentro de este script, la función process_input_file Realiza varios métodos de cadena para eliminar tabulaciones e insertar ',' como delimitador y '\n' como nueva línea. Tenga en cuenta que solo necesita procesar el original. train.txt una vez, para que el bloque de código se muestre como comentarios.
Para las siguientes pruebas de diferentes modelos DL, utilizamos ctr_train.csv como archivo de entrada. En ejecuciones de prueba posteriores, el archivo CSV de entrada se leyó en un Spark DataFrame con un esquema que contenía un campo de 'label' , características densas de números enteros ['I1', 'I2', 'I3', …, 'I13'] , y características dispersas ['C1', 'C2', 'C3', …, 'C26'] . La siguiente spark-submit El comando toma un CSV de entrada, entrena los modelos DeepFM con una división del 20 % para la validación cruzada y elige el mejor modelo después de diez épocas de entrenamiento para calcular la precisión de la predicción en el conjunto de prueba:
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
Tenga en cuenta que dado que el archivo de datos ctr_train.csv Si tiene más de 11 GB, debe establecer un espacio suficiente spark.driver.maxResultSize mayor que el tamaño del conjunto de datos para evitar errores.
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
En lo anterior SparkSession.builder configuración que también habilitamos "Flecha apache" , que convierte un Spark DataFrame en un Pandas DataFrame con el df.toPandas() método.
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
Después de la división aleatoria, hay más de 36 millones de filas en el conjunto de datos de entrenamiento y 9 millones de muestras en el conjunto de prueba:
Training dataset size = 36672493 Testing dataset size = 9168124
Debido a que este informe técnico se centra en las pruebas de CPU sin utilizar ninguna GPU, es imperativo que cree TensorFlow con los indicadores de compilador adecuados. Este paso evita invocar bibliotecas aceleradas por GPU y aprovecha al máximo las extensiones vectoriales avanzadas (AVX) y las instrucciones AVX2 de TensorFlow. Estas características están diseñadas para cálculos algebraicos lineales como suma vectorizada, multiplicaciones de matrices dentro de un entrenamiento DNN de propagación hacia adelante o hacia atrás. La instrucción FMA (Multiplicación y Suma Fusionada) disponible con AVX2 que utiliza registros de punto flotante (FP) de 256 bits es ideal para códigos enteros y tipos de datos, lo que da como resultado una aceleración de hasta 2x. Para los tipos de datos y códigos FP, AVX2 logra una aceleración del 8 % con respecto a AVX.
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Para crear TensorFlow desde la fuente, NetApp recomienda usar "Bazel" . Para nuestro entorno, ejecutamos los siguientes comandos en el indicador de shell para instalar dnf , dnf-plugins y Bazel.
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
Debe habilitar GCC 5 o una versión más reciente para usar las características de C++17 durante el proceso de compilación, que proporciona RHEL con la Biblioteca de colecciones de software (SCL). Los siguientes comandos instalan devtoolset y GCC 11.2.1 en nuestro clúster RHEL 7.9:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
Tenga en cuenta que los dos últimos comandos habilitan devtoolset-11 , que utiliza /opt/rh/devtoolset-11/root/usr/bin/gcc (CCG 11.2.1). Además, asegúrese de que su git La versión es mayor que 1.8.3 (viene con RHEL 7.9). Consulte esto "artículo" para actualizar git a 2.24.1.
Suponemos que ya ha clonado el último repositorio maestro de TensorFlow. Luego crea un workspace directorio con un WORKSPACE archivo para compilar TensorFlow desde la fuente con AVX, AVX2 y FMA. Ejecutar el configure archivo y especifique la ubicación binaria de Python correcta. "CUDA" está deshabilitado para nuestras pruebas porque no usamos una GPU. A .bazelrc El archivo se genera según su configuración. Además, editamos el archivo y lo configuramos. build --define=no_hdfs_support=false para habilitar la compatibilidad con HDFS. Referirse a .bazelrc en la sección"Scripts de Python para cada caso de uso principal," para obtener una lista completa de configuraciones y banderas.
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
Después de crear TensorFlow con los indicadores correctos, ejecute el siguiente script para procesar el conjunto de datos de anuncios de Criteo Display, entrenar un modelo DeepFM y calcular el área bajo la curva característica operativa del receptor (ROC AUC) a partir de los puntajes de predicción.
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
Después de diez épocas de entrenamiento, obtuvimos la puntuación AUC en el conjunto de datos de prueba:
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
De manera similar a los casos de uso anteriores, comparamos el tiempo de ejecución del flujo de trabajo de Spark con datos que residen en diferentes ubicaciones. La siguiente figura muestra una comparación de la predicción de CTR de aprendizaje profundo para un tiempo de ejecución de flujos de trabajo de Spark.