

Descripción general de la tecnología
 Sugerir cambios
Sugerir cambios
Esta sección describe la tecnología utilizada en esta solución.
StorageGRID en NetApp
NetApp StorageGRID es una plataforma de almacenamiento de objetos rentable y de alto rendimiento. Al utilizar almacenamiento en niveles, la mayoría de los datos en Confluent Kafka, que se almacenan en el almacenamiento local o en el almacenamiento SAN del broker, se descargan al almacén de objetos remoto. Esta configuración genera mejoras operativas significativas al reducir el tiempo y el costo de reequilibrar, expandir o reducir clústeres o reemplazar un agente fallido. El almacenamiento de objetos juega un papel importante en la administración de datos que residen en el nivel de almacenamiento de objetos, por eso es importante elegir el almacenamiento de objetos correcto.
StorageGRID ofrece una gestión de datos global inteligente basada en políticas mediante una arquitectura de cuadrícula distribuida basada en nodos. Simplifica la gestión de petabytes de datos no estructurados y miles de millones de objetos a través de su omnipresente espacio de nombres de objetos globales combinado con sofisticadas funciones de gestión de datos. El acceso a objetos mediante una sola llamada se extiende a través de los sitios y simplifica las arquitecturas de alta disponibilidad al tiempo que garantiza el acceso continuo a los objetos, independientemente de las interrupciones del sitio o la infraestructura.
La multitenencia permite que múltiples aplicaciones de datos empresariales y en la nube no estructurados se atiendan de forma segura dentro de la misma red, lo que aumenta el retorno de la inversión y los casos de uso de NetApp StorageGRID. Puede crear múltiples niveles de servicio con políticas de ciclo de vida de objetos basadas en metadatos, optimizando la durabilidad, la protección, el rendimiento y la localidad en múltiples geografías. Los usuarios pueden ajustar las políticas de gestión de datos y monitorear y aplicar límites de tráfico para realinearlos al panorama de datos de manera no disruptiva a medida que sus requisitos cambian en entornos de TI en constante cambio.
Gestión sencilla con Grid Manager
StorageGRID Grid Manager es una interfaz gráfica basada en navegador que le permite configurar, administrar y monitorear su sistema StorageGRID en ubicaciones distribuidas globalmente en un solo panel.
Puede realizar las siguientes tareas con la interfaz de StorageGRID Grid Manager:
-
Administre repositorios de objetos, como imágenes, vídeos y registros, distribuidos globalmente y a escala de petabytes.
-
Supervisar los nodos y servicios de la red para garantizar la disponibilidad de los objetos.
-
Gestione la ubicación de los datos de objetos a lo largo del tiempo utilizando reglas de gestión del ciclo de vida de la información (ILM). Estas reglas rigen lo que sucede con los datos de un objeto después de su ingesta, cómo se protegen contra pérdidas, dónde se almacenan los datos del objeto y durante cuánto tiempo.
-
Supervisar transacciones, rendimiento y operaciones dentro del sistema.
Políticas de gestión del ciclo de vida de la información
StorageGRID tiene políticas de administración de datos flexibles que incluyen mantener copias de réplica de sus objetos y usar esquemas EC (codificación de borrado) como 2+1 y 4+2 (entre otros) para almacenar sus objetos, dependiendo de los requisitos específicos de rendimiento y protección de datos. A medida que las cargas de trabajo y los requisitos cambian con el tiempo, es común que las políticas de ILM también deban cambiar con el tiempo. La modificación de las políticas de ILM es una característica fundamental que permite a los clientes de StorageGRID adaptarse a su entorno en constante cambio de forma rápida y sencilla.
Actuación
StorageGRID escala el rendimiento agregando más nodos de almacenamiento, que pueden ser máquinas virtuales, hardware o dispositivos diseñados específicamente como el"SG5712, SG5760, SG6060 o SGF6024" . En nuestras pruebas, superamos los requisitos clave de rendimiento de Apache Kafka con una cuadrícula de tres nodos de tamaño mínimo utilizando el dispositivo SGF6024. A medida que los clientes escalan su clúster de Kafka con agentes adicionales, pueden agregar más nodos de almacenamiento para aumentar el rendimiento y la capacidad.
Configuración del balanceador de carga y del punto final
Los nodos de administración en StorageGRID proporcionan la interfaz de usuario (IU) de Grid Manager y el punto final de API REST para ver, configurar y administrar su sistema StorageGRID , así como registros de auditoría para rastrear la actividad del sistema. Para proporcionar un punto final S3 de alta disponibilidad para el almacenamiento en niveles de Confluent Kafka, implementamos el balanceador de carga StorageGRID , que se ejecuta como un servicio en los nodos de administración y los nodos de puerta de enlace. Además, el balanceador de carga también administra el tráfico local y se comunica con GSLB (Global Server Load Balancing) para ayudar con la recuperación ante desastres.
Para mejorar aún más la configuración de los puntos finales, StorageGRID proporciona políticas de clasificación de tráfico integradas en el nodo de administración, le permite monitorear el tráfico de su carga de trabajo y aplica varios límites de calidad de servicio (QoS) a sus cargas de trabajo. Las políticas de clasificación de tráfico se aplican a los puntos finales del servicio StorageGRID Load Balancer para los nodos de puerta de enlace y los nodos de administración. Estas políticas pueden ayudar a configurar y monitorear el tráfico.
Clasificación del tráfico en StorageGRID
StorageGRID tiene funcionalidad QoS incorporada. Las políticas de clasificación de tráfico pueden ayudar a monitorear diferentes tipos de tráfico S3 provenientes de una aplicación cliente. Luego, puede crear y aplicar políticas para poner límites a este tráfico en función del ancho de banda de entrada y salida, la cantidad de solicitudes de lectura y escritura simultáneas o la tasa de solicitudes de lectura y escritura.
Apache Kafka
Apache Kafka es una implementación de marco de un bus de software que utiliza procesamiento de flujo escrito en Java y Scala. Su objetivo es proporcionar una plataforma unificada, de alto rendimiento y baja latencia para gestionar transmisiones de datos en tiempo real. Kafka puede conectarse a un sistema externo para exportar e importar datos a través de Kafka Connect y proporciona Kafka Streams, una biblioteca de procesamiento de flujos de Java. Kafka utiliza un protocolo binario basado en TCP que está optimizado para la eficiencia y se apoya en una abstracción de "conjunto de mensajes" que agrupa naturalmente los mensajes para reducir la sobrecarga del viaje de ida y vuelta de la red. Esto permite operaciones de disco secuenciales más grandes, paquetes de red más grandes y bloques de memoria contiguos, lo que permite a Kafka convertir un flujo ráfaga de escrituras de mensajes aleatorios en escrituras lineales. La siguiente figura representa el flujo de datos básico de Apache Kafka.
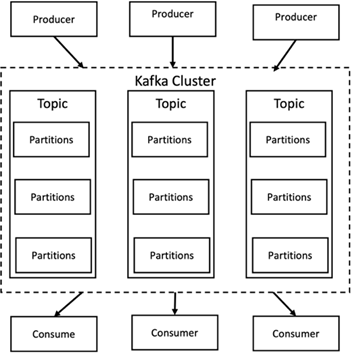
Kafka almacena mensajes clave-valor que provienen de una cantidad arbitraria de procesos llamados productores. Los datos se pueden dividir en diferentes particiones dentro de diferentes temas. Dentro de una partición, los mensajes se ordenan estrictamente por sus desplazamientos (la posición de un mensaje dentro de una partición) y se indexan y almacenan junto con una marca de tiempo. Otros procesos llamados consumidores pueden leer mensajes de las particiones. Para el procesamiento de flujos, Kafka ofrece la API Streams que permite escribir aplicaciones Java que consumen datos de Kafka y escriben los resultados en Kafka. Apache Kafka también funciona con sistemas de procesamiento de flujo externos como Apache Apex, Apache Flink, Apache Spark, Apache Storm y Apache NiFi.
Kafka se ejecuta en un clúster de uno o más servidores (llamados intermediarios) y las particiones de todos los temas se distribuyen entre los nodos del clúster. Además, las particiones se replican en múltiples intermediarios. Esta arquitectura permite a Kafka entregar flujos masivos de mensajes de manera tolerante a fallos y le ha permitido reemplazar algunos de los sistemas de mensajería convencionales como Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP), etc. Desde el lanzamiento de la versión 0.11.0.0, Kafka ofrece escrituras transaccionales, que proporcionan exactamente un procesamiento de flujo mediante la API Streams.
Kafka admite dos tipos de temas: regulares y compactados. Los temas regulares se pueden configurar con un tiempo de retención o un límite de espacio. Si hay registros que son más antiguos que el tiempo de retención especificado o si se excede el límite de espacio para una partición, Kafka puede eliminar datos antiguos para liberar espacio de almacenamiento. De forma predeterminada, los temas están configurados con un tiempo de retención de 7 días, pero también es posible almacenar datos indefinidamente. Para los temas compactados, los registros no caducan según límites de tiempo o espacio. En cambio, Kafka trata los mensajes posteriores como actualizaciones de mensajes más antiguos con la misma clave y garantiza nunca eliminar el mensaje más reciente por clave. Los usuarios pueden eliminar mensajes por completo escribiendo un mensaje denominado "tombstone" con un valor nulo para una clave específica.
Hay cinco API principales en Kafka:
-
API de productor. Permite que una aplicación publique flujos de registros.
-
API del consumidor. Permite que una aplicación se suscriba a temas y procese flujos de registros.
-
API de conector. Ejecuta las API de productor y consumidor reutilizables que pueden vincular los temas a las aplicaciones existentes.
-
API de transmisiones. Esta API convierte los flujos de entrada en salida y produce el resultado.
-
API de administración. Se utiliza para administrar temas de Kafka, intermediarios y otros objetos de Kafka.
Las API de consumidor y productor se basan en el protocolo de mensajería de Kafka y ofrecen una implementación de referencia para los clientes consumidores y productores de Kafka en Java. El protocolo de mensajería subyacente es un protocolo binario que los desarrolladores pueden usar para escribir sus propios clientes consumidores o productores en cualquier lenguaje de programación. Esto desbloquea Kafka del ecosistema de la máquina virtual Java (JVM). En la wiki de Apache Kafka se mantiene una lista de clientes que no son Java disponibles.
Casos de uso de Apache Kafka
Apache Kafka es más popular para mensajería, seguimiento de actividad del sitio web, métricas, agregación de registros, procesamiento de transmisiones, abastecimiento de eventos y registro de confirmaciones.
-
Kafka ha mejorado el rendimiento, la partición integrada, la replicación y la tolerancia a fallas, lo que lo convierte en una buena solución para aplicaciones de procesamiento de mensajes a gran escala.
-
Kafka puede reconstruir las actividades de un usuario (visitas de página, búsquedas) en un canal de seguimiento como un conjunto de feeds de publicación y suscripción en tiempo real.
-
Kafka se utiliza a menudo para datos de seguimiento operativo. Esto implica agregar estadísticas de aplicaciones distribuidas para producir fuentes centralizadas de datos operativos.
-
Muchas personas utilizan Kafka como reemplazo de una solución de agregación de registros. La agregación de registros generalmente recopila archivos de registro físicos de los servidores y los coloca en un lugar central (por ejemplo, un servidor de archivos o HDFS) para su procesamiento. Kafka abstrae los detalles de los archivos y proporciona una abstracción más limpia de los datos de registro o eventos como un flujo de mensajes. Esto permite un procesamiento de menor latencia y un soporte más sencillo para múltiples fuentes de datos y un consumo de datos distribuido.
-
Muchos usuarios de Kafka procesan datos en canales de procesamiento que constan de varias etapas, en las que los datos de entrada sin procesar se consumen de los temas de Kafka y luego se agregan, enriquecen o transforman de otro modo en nuevos temas para un mayor consumo o procesamiento de seguimiento. Por ejemplo, un canal de procesamiento para recomendar artículos de noticias podría rastrear el contenido de los artículos desde fuentes RSS y publicarlo en un tema de "artículos". Un procesamiento posterior podría normalizar o desduplicar este contenido y publicar el contenido del artículo limpio en un nuevo tema, y una etapa de procesamiento final podría intentar recomendar este contenido a los usuarios. Estos canales de procesamiento crean gráficos de flujos de datos en tiempo real basados en temas individuales.
-
El almacenamiento en caché de eventos es un estilo de diseño de aplicaciones para el cual los cambios de estado se registran como una secuencia de registros ordenada en el tiempo. El soporte de Kafka para datos de registros almacenados de gran tamaño lo convierte en un excelente backend para una aplicación creada en este estilo.
-
Kafka puede servir como una especie de registro de confirmación externo para un sistema distribuido. El registro ayuda a replicar datos entre nodos y actúa como un mecanismo de resincronización para que los nodos fallidos restauren sus datos. La función de compactación de registros en Kafka ayuda a respaldar este caso de uso.
Confluente
Confluent Platform es una plataforma preparada para la empresa que completa Kafka con capacidades avanzadas diseñadas para ayudar a acelerar el desarrollo y la conectividad de las aplicaciones, permitir transformaciones a través del procesamiento de flujo, simplificar las operaciones empresariales a escala y cumplir con estrictos requisitos arquitectónicos. Desarrollado por los creadores originales de Apache Kafka, Confluent amplía los beneficios de Kafka con funciones de nivel empresarial y al mismo tiempo elimina la carga de la administración o el monitoreo de Kafka. Hoy en día, más del 80% de las empresas Fortune 100 utilizan tecnología de transmisión de datos y la mayoría de ellas utilizan Confluent.
¿Por qué Confluent?
Al integrar datos históricos y en tiempo real en una única fuente central de verdad, Confluent facilita la creación de una categoría totalmente nueva de aplicaciones modernas basadas en eventos, obtiene una canalización de datos universal y desbloquea nuevos casos de uso poderosos con total escalabilidad, rendimiento y confiabilidad.
¿Para qué se utiliza Confluent?
Confluent Platform le permite centrarse en cómo obtener valor comercial de sus datos en lugar de preocuparse por la mecánica subyacente, como la forma en que se transportan o integran los datos entre sistemas dispares. En concreto, Confluent Platform simplifica la conexión de fuentes de datos a Kafka, la creación de aplicaciones de transmisión, así como la protección, la supervisión y la gestión de su infraestructura de Kafka. Hoy en día, Confluent Platform se utiliza para una amplia gama de casos de uso en numerosas industrias, desde servicios financieros, venta minorista omnicanal y automóviles autónomos hasta detección de fraudes, microservicios e IoT.
La siguiente figura muestra los componentes de la plataforma Confluent Kafka.
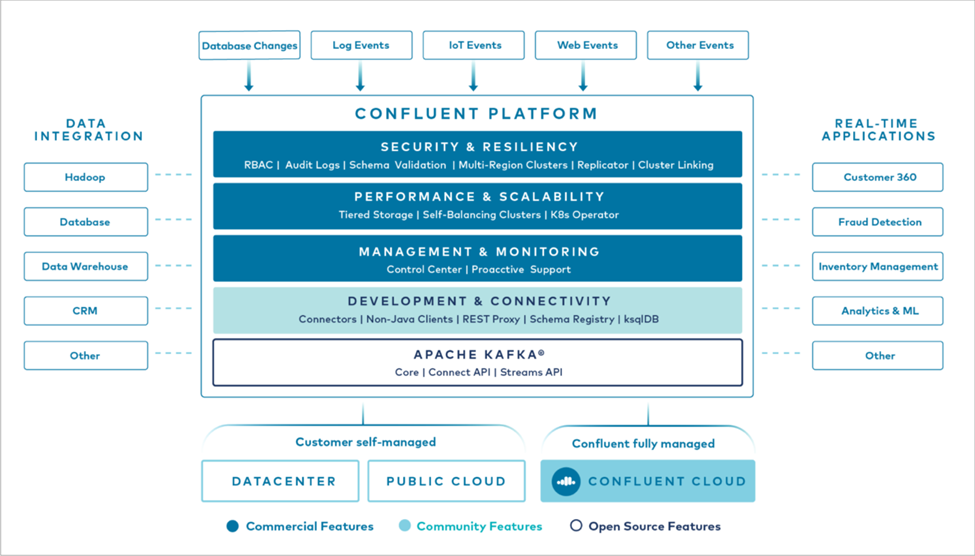
Descripción general de la tecnología de transmisión de eventos de Confluent
En el núcleo de la Plataforma Confluent se encuentra "Apache Kafka" , la plataforma de transmisión distribuida de código abierto más popular. Las capacidades clave de Kafka son las siguientes:
-
Publicar y suscribirse a flujos de registros.
-
Almacene flujos de registros de manera tolerante a fallos.
-
Procesar flujos de registros.
De fábrica, Confluent Platform también incluye Schema Registry, REST Proxy, un total de más de 100 conectores Kafka prediseñados y ksqlDB.
Descripción general de las funciones empresariales de la plataforma Confluent
-
Centro de Control de Confluentes. Un sistema basado en GUI para administrar y supervisar Kafka. Le permite administrar fácilmente Kafka Connect y crear, editar y administrar conexiones a otros sistemas.
-
Confluent para Kubernetes. Confluent for Kubernetes es un operador de Kubernetes. Los operadores de Kubernetes amplían las capacidades de orquestación de Kubernetes al proporcionar características y requisitos únicos para una aplicación de plataforma específica. Para Confluent Platform, esto incluye simplificar enormemente el proceso de implementación de Kafka en Kubernetes y automatizar las tareas típicas del ciclo de vida de la infraestructura.
-
Conectores confluentes a Kafka. Los conectores utilizan la API de Kafka Connect para conectar Kafka a otros sistemas, como bases de datos, almacenes de clave-valor, índices de búsqueda y sistemas de archivos. Confluent Hub tiene conectores descargables para las fuentes y receptores de datos más populares, incluidas versiones totalmente probadas y compatibles de estos conectores con Confluent Platform. Se pueden encontrar más detalles "aquí" .
-
Clústeres autoequilibrados. Proporciona equilibrio de carga automatizado, detección de fallas y autorreparación. Proporciona soporte para agregar o desmantelar corredores según sea necesario, sin necesidad de realizar ajustes manuales.
-
Enlace de clústeres confluentes. Conecta directamente los clústeres entre sí y refleja temas de un clúster a otro a través de un puente de enlace. La vinculación de clústeres simplifica la configuración de implementaciones de múltiples centros de datos, múltiples clústeres y nubes híbridas.
-
Balanceador automático de datos Confluent. Supervisa su clúster para conocer la cantidad de intermediarios, el tamaño de las particiones, la cantidad de particiones y la cantidad de líderes dentro del clúster. Le permite cambiar datos para crear una carga de trabajo uniforme en todo el clúster, al mismo tiempo que limita el tráfico de reequilibrio para minimizar el efecto en las cargas de trabajo de producción durante el reequilibrio.
-
Replicador confluente. Hace que sea más fácil que nunca mantener múltiples clústeres de Kafka en múltiples centros de datos.
-
Almacenamiento por niveles. Proporciona opciones para almacenar grandes volúmenes de datos de Kafka utilizando su proveedor de nube favorito, reduciendo así la carga operativa y los costos. Con el almacenamiento por niveles, puede mantener los datos en un almacenamiento de objetos rentable y escalar intermediarios solo cuando necesite más recursos computacionales.
-
Cliente JMS Confluent. Confluent Platform incluye un cliente compatible con JMS para Kafka. Este cliente de Kafka implementa la API estándar JMS 1.1, utilizando intermediarios de Kafka como backend. Esto es útil si tiene aplicaciones heredadas que usan JMS y desea reemplazar el agente de mensajes JMS existente con Kafka.
-
Proxy MQTT confluente. Proporciona una manera de publicar datos directamente en Kafka desde dispositivos y puertas de enlace MQTT sin la necesidad de un agente MQTT en el medio.
-
Complementos de seguridad de Confluent. Los complementos de seguridad de Confluent se utilizan para agregar capacidades de seguridad a varias herramientas y productos de la plataforma Confluent. Actualmente, hay un complemento disponible para el proxy REST de Confluent que ayuda a autenticar las solicitudes entrantes y propagar el principal autenticado a las solicitudes a Kafka. Esto permite que los clientes proxy REST de Confluent utilicen las funciones de seguridad multiinquilino del bróker Kafka.