

TR-4886: Inferencia de IA en el borde - NetApp con Lenovo ThinkSystem - Diseño de soluciones
 Sugerir cambios
Sugerir cambios
Sathish Thyagarajan, NetApp Miroslav Hodak, Lenovo
Este documento describe una arquitectura de computación y almacenamiento para implementar inferencia de inteligencia artificial (IA) basada en GPU en controladores de almacenamiento NetApp y servidores Lenovo ThinkSystem en un entorno de borde que satisface escenarios de aplicaciones emergentes.
Resumen
Varios escenarios de aplicación emergentes, como los sistemas avanzados de asistencia al conductor (ADAS), la Industria 4.0, las ciudades inteligentes y la Internet de las cosas (IoT), requieren el procesamiento de flujos de datos continuos con una latencia cercana a cero. Este documento describe una arquitectura de computación y almacenamiento para implementar inferencia de inteligencia artificial (IA) basada en GPU en controladores de almacenamiento NetApp y servidores Lenovo ThinkSystem en un entorno de borde que cumple con estos requisitos. Este documento también proporciona datos de rendimiento para el punto de referencia de inferencia MLPerf, estándar de la industria, que evalúa varias tareas de inferencia en servidores perimetrales equipados con GPU NVIDIA T4. Investigamos el rendimiento de escenarios de inferencia fuera de línea, de flujo único y de múltiples flujos y demostramos que la arquitectura con un sistema de almacenamiento en red compartido rentable tiene un gran rendimiento y proporciona un punto central para la gestión de datos y modelos para múltiples servidores de borde.
Introducción
Las empresas generan cada vez más volúmenes masivos de datos en el borde de la red. Para obtener el máximo valor de los sensores inteligentes y los datos de IoT, las organizaciones buscan una solución de transmisión de eventos en tiempo real que permita la computación de borde. Por lo tanto, los trabajos que requieren un alto nivel de exigencia computacional se realizan cada vez más en el borde, fuera de los centros de datos. La inferencia de IA es uno de los impulsores de esta tendencia. Los servidores de borde proporcionan suficiente potencia computacional para estas cargas de trabajo, especialmente cuando se utilizan aceleradores, pero el almacenamiento limitado suele ser un problema, especialmente en entornos de múltiples servidores. En este documento mostramos cómo se puede implementar un sistema de almacenamiento compartido en el entorno de borde y cómo beneficia las cargas de trabajo de inferencia de IA sin imponer una penalización en el rendimiento.
Este documento describe una arquitectura de referencia para la inferencia de IA en el borde. Combina varios servidores edge Lenovo ThinkSystem con un sistema de almacenamiento NetApp para crear una solución fácil de implementar y administrar. Se pretende que sea una guía de base para implementaciones prácticas en diversas situaciones, como en el área de producción con múltiples cámaras y sensores industriales, sistemas de puntos de venta (POS) en transacciones minoristas o sistemas de conducción autónoma total (FSD) que identifican anomalías visuales en vehículos autónomos.
Este documento cubre las pruebas y la validación de una configuración de cómputo y almacenamiento que consta de un servidor Lenovo ThinkSystem SE350 Edge y un sistema de almacenamiento NetApp AFF y EF-Series de nivel básico. Las arquitecturas de referencia brindan una solución eficiente y rentable para implementaciones de IA al mismo tiempo que brindan servicios de datos integrales, protección de datos integrada, escalabilidad perfecta y almacenamiento de datos conectado a la nube con el software de gestión de datos NetApp ONTAP y NetApp SANtricity .
Público objetivo
Este documento está dirigido a los siguientes públicos:
-
Líderes empresariales y arquitectos empresariales que desean convertir la IA en un producto en el borde.
-
Científicos de datos, ingenieros de datos, investigadores de IA/aprendizaje automático (ML) y desarrolladores de sistemas de IA.
-
Arquitectos empresariales que diseñan soluciones para el desarrollo de modelos y aplicaciones de IA/ML.
-
Científicos de datos e ingenieros de IA que buscan formas eficientes de implementar modelos de aprendizaje profundo (DL) y ML.
-
Administradores de dispositivos perimetrales y administradores de servidores perimetrales responsables de la implementación y la administración de modelos de inferencia perimetral.
Arquitectura de la solución
Esta solución de almacenamiento NetApp ONTAP o NetApp SANtricity y servidor Lenovo ThinkSystem está diseñada para manejar la inferencia de IA en grandes conjuntos de datos utilizando la potencia de procesamiento de las GPU junto con las CPU tradicionales. Esta validación demuestra un alto rendimiento y una gestión óptima de datos con una arquitectura que utiliza uno o varios servidores perimetrales Lenovo SR350 interconectados con un único sistema de almacenamiento NetApp AFF , como se muestra en las dos figuras siguientes.
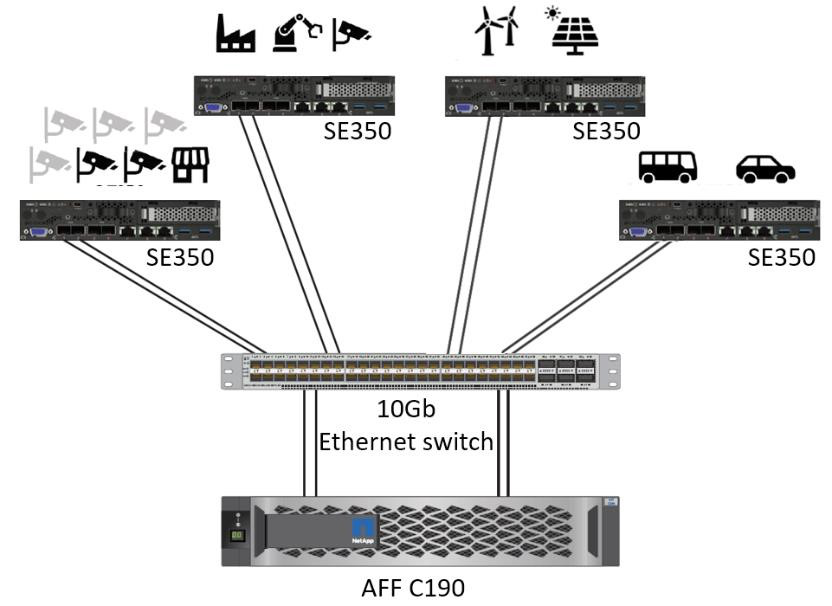
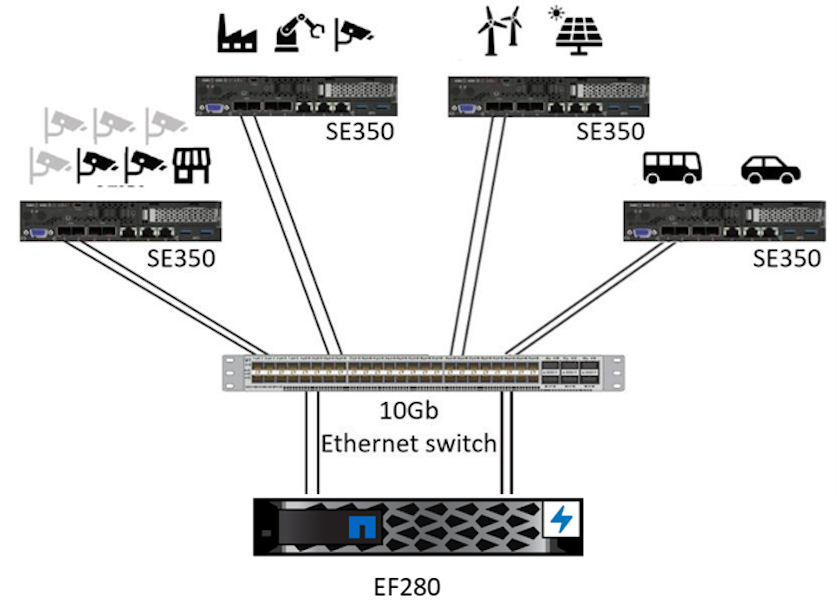
La descripción general de la arquitectura lógica en la siguiente figura muestra las funciones de los elementos de cómputo y almacenamiento en esta arquitectura. En concreto, muestra lo siguiente:
-
Dispositivos informáticos de borde que realizan inferencias sobre los datos que reciben de cámaras, sensores, etc.
-
Un elemento de almacenamiento compartido que sirve para múltiples propósitos:
-
Proporciona una ubicación central para los modelos de inferencia y otros datos necesarios para realizar la inferencia. Los servidores de cómputo acceden directamente al almacenamiento y utilizan modelos de inferencia en toda la red sin necesidad de copiarlos localmente.
-
Los modelos actualizados se envían aquí.
-
Archiva datos de entrada que los servidores perimetrales reciben para su posterior análisis. Por ejemplo, si los dispositivos de borde están conectados a cámaras, el elemento de almacenamiento mantiene los vídeos capturados por las cámaras.
-

rojo |
azul |
Sistema informático Lenovo |
Sistema de almacenamiento NetApp AFF |
Dispositivos de borde que realizan inferencias sobre las entradas de cámaras, sensores, etc. |
Almacenamiento compartido que contiene modelos de inferencia y datos de dispositivos perimetrales para su posterior análisis. |
Esta solución de NetApp y Lenovo ofrece los siguientes beneficios clave:
-
Computación acelerada por GPU en el borde.
-
Implementación de múltiples servidores de borde respaldados y administrados desde un almacenamiento compartido.
-
Protección de datos robusta para cumplir con objetivos de punto de recuperación (RPO) bajos y objetivos de tiempo de recuperación (RTO) sin pérdida de datos.
-
Gestión de datos optimizada con copias y clones de NetApp Snapshot para agilizar los flujos de trabajo de desarrollo.
Cómo utilizar esta arquitectura
Este documento valida el diseño y el rendimiento de la arquitectura propuesta. Sin embargo, no hemos probado ciertas piezas a nivel de software, como la gestión de contenedores, cargas de trabajo o modelos y la sincronización de datos con la nube o el centro de datos local, porque son específicas de un escenario de implementación. Aquí existen múltiples opciones.
A nivel de gestión de contenedores, la gestión de contenedores de Kubernetes es una buena opción y cuenta con un buen soporte tanto en una versión totalmente upstream (Canonical) como en una versión modificada adecuada para implementaciones empresariales (Red Hat). El"Plano de control de IA de NetApp" que utiliza NetApp Trident y el recién agregado "Kit de herramientas DataOps de NetApp" Proporciona trazabilidad integrada, funciones de gestión de datos, interfaces y herramientas para que los científicos e ingenieros de datos se integren con el almacenamiento de NetApp . Kubeflow, el kit de herramientas de ML para Kubernetes, proporciona capacidades de IA adicionales junto con soporte para control de versiones de modelos y KFServing en varias plataformas como TensorFlow Serving o NVIDIA Triton Inference Server. Otra opción es la plataforma NVIDIA EGX, que proporciona gestión de carga de trabajo junto con acceso a un catálogo de contenedores de inferencia de IA habilitados para GPU. Sin embargo, estas opciones pueden requerir un esfuerzo y una experiencia importantes para ponerlas en producción y pueden requerir la asistencia de un consultor o proveedor de software independiente (ISV).
Áreas de solución
El beneficio clave de la inferencia de IA y la computación de borde es la capacidad de los dispositivos de calcular, procesar y analizar datos con un alto nivel de calidad sin latencia. Hay demasiados ejemplos de casos de uso de computación de borde para describirlos en este documento, pero aquí hay algunos destacados:
Automóviles: vehículos autónomos
El ejemplo clásico de computación de borde se encuentra en los sistemas avanzados de asistencia al conductor (ADAS) en vehículos autónomos (AV). La IA de los coches sin conductor debe procesar rápidamente una gran cantidad de datos de cámaras y sensores para ser un conductor seguro y exitoso. Tomar demasiado tiempo para interpretar la diferencia entre un objeto y un humano puede significar vida o muerte, por lo tanto, poder procesar esos datos lo más cerca posible del vehículo es crucial. En este caso, uno o más servidores informáticos de borde manejan la entrada de cámaras, RADAR, LiDAR y otros sensores, mientras que el almacenamiento compartido contiene modelos de inferencia y almacena datos de entrada de los sensores.
Atención sanitaria: Monitorización de pacientes
Uno de los mayores impactos de la IA y la computación de borde es su capacidad para mejorar el monitoreo continuo de pacientes con enfermedades crónicas tanto en atención domiciliaria como en unidades de cuidados intensivos (UCI). Los datos de los dispositivos periféricos que monitorean los niveles de insulina, la respiración, la actividad neurológica, el ritmo cardíaco y las funciones gastrointestinales requieren un análisis instantáneo de datos que se deben procesar de inmediato porque hay tiempo limitado para actuar y salvar la vida de alguien.
Comercio minorista: Pago sin cajero
La computación de borde puede potenciar la IA y el ML para ayudar a los minoristas a reducir el tiempo de pago y aumentar el tráfico peatonal. Los sistemas sin cajero admiten varios componentes, como los siguientes:
-
Autenticación y acceso. Conectar al comprador físico a una cuenta validada y permitir el acceso al espacio minorista.
-
Monitoreo de inventario. Utilizando sensores, etiquetas RFID y sistemas de visión artificial para ayudar a confirmar la selección o deselección de artículos por parte de los compradores.
Aquí, cada uno de los servidores perimetrales gestiona cada mostrador de pago y el sistema de almacenamiento compartido sirve como punto de sincronización central.
Servicios financieros: seguridad humana en los quioscos y prevención del fraude
Las organizaciones bancarias están utilizando inteligencia artificial y computación de borde para innovar y crear experiencias bancarias personalizadas. Los quioscos interactivos que utilizan análisis de datos en tiempo real e inferencia de inteligencia artificial ahora permiten a los cajeros automáticos no solo ayudar a los clientes a retirar dinero, sino también monitorear de manera proactiva los quioscos a través de las imágenes capturadas por las cámaras para identificar riesgos para la seguridad humana o comportamiento fraudulento. En este escenario, los servidores informáticos de borde y los sistemas de almacenamiento compartido están conectados a quioscos y cámaras interactivas para ayudar a los bancos a recopilar y procesar datos con modelos de inferencia de IA.
Manufactura: Industria 4.0
La cuarta revolución industrial (Industria 4.0) ha comenzado, junto con tendencias emergentes como Smart Factory y la impresión 3D. Para prepararse para un futuro basado en datos, la comunicación de máquina a máquina (M2M) a gran escala y la IoT se integran para una mayor automatización sin necesidad de intervención humana. La fabricación ya está altamente automatizada y agregar funciones de IA es una continuación natural de la tendencia a largo plazo. La IA permite automatizar operaciones que pueden automatizarse con la ayuda de la visión artificial y otras capacidades de IA. Puede automatizar el control de calidad o las tareas que dependen de la visión humana o la toma de decisiones para realizar análisis más rápidos de los materiales en las líneas de ensamblaje de las fábricas para ayudar a las plantas de fabricación a cumplir con los estándares ISO requeridos de seguridad y gestión de calidad. Aquí, cada servidor de borde computacional está conectado a una serie de sensores que monitorean el proceso de fabricación y los modelos de inferencia actualizados se envían al almacenamiento compartido, según sea necesario.
Telecomunicaciones: Detección de óxido, inspección de torres y optimización de redes
La industria de las telecomunicaciones utiliza técnicas de visión artificial e inteligencia artificial para procesar imágenes que detectan automáticamente el óxido e identifican las torres de telefonía celular que contienen corrosión y, por lo tanto, requieren una inspección más profunda. El uso de imágenes de drones y modelos de IA para identificar regiones distintas de una torre para analizar el óxido, las grietas superficiales y la corrosión ha aumentado en los últimos años. La demanda de tecnologías de IA que permitan inspeccionar eficientemente la infraestructura de telecomunicaciones y las torres de telefonía celular, evaluarlas periódicamente para detectar degradación y repararlas rápidamente cuando sea necesario continúa creciendo.
Además, otro caso de uso emergente en telecomunicaciones es el uso de algoritmos de IA y ML para predecir patrones de tráfico de datos, detectar dispositivos con capacidad 5G y automatizar y aumentar la gestión de energía de múltiples entradas y múltiples salidas (MIMO). El hardware MIMO se utiliza en torres de radio para aumentar la capacidad de la red; sin embargo, esto implica costos de energía adicionales. Los modelos ML para el "modo de suspensión MIMO" implementados en sitios celulares pueden predecir el uso eficiente de las radios y ayudar a reducir los costos de consumo de energía para los operadores de redes móviles (MNO). Las soluciones de inferencia de IA y computación de borde ayudan a los MNO a reducir la cantidad de datos transmitidos entre centros de datos, disminuir su TCO, optimizar las operaciones de red y mejorar el rendimiento general para los usuarios finales.