

Ejecutar una carga de trabajo de IA distribuida sincrónica
 Sugerir cambios
Sugerir cambios
Para ejecutar un trabajo de IA y ML sincrónico de múltiples nodos en su clúster de Kubernetes, realice las siguientes tareas en el host de salto de implementación. Este proceso le permite aprovechar los datos almacenados en un volumen de NetApp y utilizar más GPU de las que un solo nodo de trabajo puede proporcionar. Vea la siguiente figura para ver una representación de un trabajo de IA distribuido sincrónico.

|
Los trabajos distribuidos sincrónicos pueden ayudar a aumentar el rendimiento y la precisión del entrenamiento en comparación con los trabajos distribuidos asincrónicos. Una discusión de los pros y contras de los trabajos sincrónicos versus los trabajos asincrónicos está fuera del alcance de este documento. |
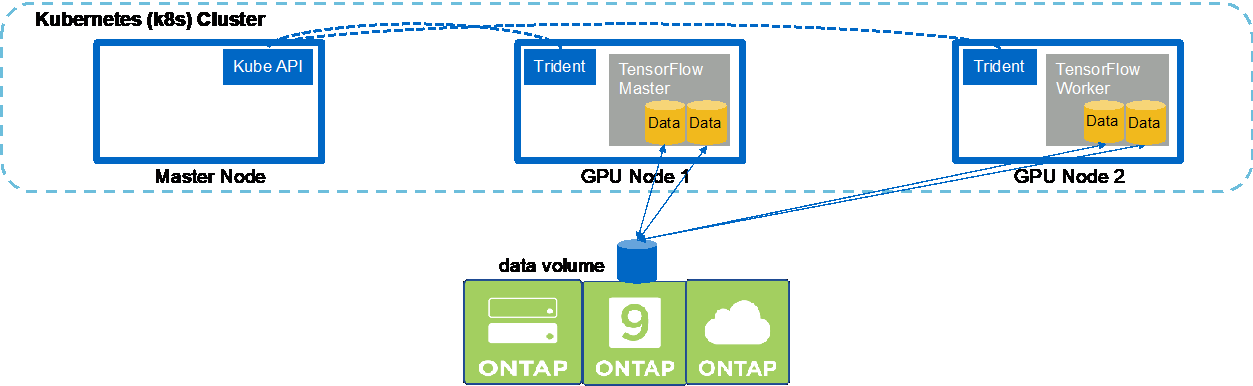
-
Los siguientes comandos de ejemplo muestran la creación de un trabajador que participa en la ejecución distribuida sincrónica del mismo trabajo de referencia de TensorFlow que se ejecutó en un solo nodo en el ejemplo de la sección"Ejecutar una carga de trabajo de IA de un solo nodo" . En este ejemplo específico, solo se implementa un único trabajador porque el trabajo se ejecuta en dos nodos de trabajo.
Esta implementación de trabajador de ejemplo solicita ocho GPU y, por lo tanto, puede ejecutarse en un solo nodo de trabajador de GPU que tenga ocho o más GPU. Si sus nodos de trabajo de GPU cuentan con más de ocho GPU, para maximizar el rendimiento, es posible que desee aumentar este número para que sea igual a la cantidad de GPU que cuentan sus nodos de trabajo. Para obtener más información sobre las implementaciones de Kubernetes, consulte "documentación oficial de Kubernetes" .
En este ejemplo se crea una implementación de Kubernetes porque este trabajador en contenedor específico nunca se completaría por sí solo. Por lo tanto, no tiene sentido implementarlo utilizando la construcción del trabajo de Kubernetes. Si su trabajador está diseñado o escrito para completarse por sí solo, entonces podría tener sentido utilizar la construcción del trabajo para implementar su trabajador.
Al pod que se especifica en esta especificación de implementación de ejemplo se le asigna un
hostNetworkvalor detrue. Este valor significa que el pod utiliza la pila de red del nodo de trabajo host en lugar de la pila de red virtual que Kubernetes normalmente crea para cada pod. Esta anotación se utiliza en este caso porque la carga de trabajo específica depende de Open MPI, NCCL y Horovod para ejecutarla de manera distribuida sincrónica. Por lo tanto, requiere acceso a la pila de red del host. Una discusión sobre Open MPI, NCCL y Horovod está fuera del alcance de este documento. Sea esto o nohostNetwork: trueLa anotación es necesaria dependiendo de los requisitos de la carga de trabajo específica que esté ejecutando. Para obtener más información sobre lahostNetworkcampo, ver el "documentación oficial de Kubernetes" .$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
Confirme que la implementación del trabajador que creó en el paso 1 se inició correctamente. Los siguientes comandos de ejemplo confirman que se creó un solo pod de trabajo para la implementación, como se indica en la definición de implementación, y que este pod se está ejecutando actualmente en uno de los nodos de trabajo de la GPU.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
Cree un trabajo de Kubernetes para un maestro que inicie, participe y realice un seguimiento de la ejecución del trabajo multinodo sincrónico. Los siguientes comandos de ejemplo crean un maestro que inicia, participa y rastrea la ejecución distribuida sincrónica del mismo trabajo de referencia de TensorFlow que se ejecutó en un solo nodo en el ejemplo de la sección"Ejecutar una carga de trabajo de IA de un solo nodo" .
Este trabajo maestro de ejemplo solicita ocho GPU y, por lo tanto, puede ejecutarse en un solo nodo de trabajo de GPU que tenga ocho o más GPU. Si sus nodos de trabajo de GPU cuentan con más de ocho GPU, para maximizar el rendimiento, es posible que desee aumentar este número para que sea igual a la cantidad de GPU que cuentan sus nodos de trabajo.
Al pod maestro que se especifica en esta definición de trabajo de ejemplo se le asigna un
hostNetworkvalor detrue, justo cuando se le dio un puesto al trabajadorhostNetworkvalor detrueen el paso 1. Consulte el paso 1 para obtener detalles sobre por qué es necesario este valor.$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
Confirme que el trabajo maestro que creó en el paso 3 se esté ejecutando correctamente. El siguiente comando de ejemplo confirma que se creó un solo pod maestro para el trabajo, como se indica en la definición del trabajo, y que este pod se está ejecutando actualmente en uno de los nodos de trabajo de la GPU. También debería ver que el pod de trabajo que vio originalmente en el paso 1 todavía está ejecutándose y que los pods maestro y de trabajo se están ejecutando en nodos diferentes.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
Confirme que el trabajo maestro que creó en el paso 3 se complete exitosamente. Los siguientes comandos de ejemplo confirman que el trabajo se completó correctamente.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
Elimina la implementación del trabajador cuando ya no la necesites. Los siguientes comandos de ejemplo muestran la eliminación del objeto de implementación de trabajador que se creó en el paso 1.
Cuando elimina el objeto de implementación del trabajador, Kubernetes elimina automáticamente todos los pods de trabajador asociados.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
Opcional: Limpiar los artefactos del trabajo maestro. Los siguientes comandos de ejemplo muestran la eliminación del objeto de trabajo maestro que se creó en el paso 3.
Cuando elimina el objeto de trabajo maestro, Kubernetes elimina automáticamente todos los pods maestros asociados.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.