

Validación del rendimiento de la base de datos vectorial
 Sugerir cambios
Sugerir cambios
Esta sección destaca la validación del rendimiento que se realizó en la base de datos vectorial.
Validación del rendimiento
La validación del rendimiento juega un papel fundamental tanto en las bases de datos vectoriales como en los sistemas de almacenamiento, y actúa como un factor clave para garantizar un funcionamiento óptimo y una utilización eficiente de los recursos. Las bases de datos vectoriales, conocidas por manejar datos de alta dimensión y ejecutar búsquedas de similitud, necesitan mantener altos niveles de rendimiento para procesar consultas complejas con rapidez y precisión. La validación del rendimiento ayuda a identificar cuellos de botella, ajustar configuraciones y garantizar que el sistema pueda manejar las cargas esperadas sin degradación del servicio. De manera similar, en los sistemas de almacenamiento, la validación del rendimiento es esencial para garantizar que los datos se almacenen y recuperen de manera eficiente, sin problemas de latencia o cuellos de botella que puedan afectar el rendimiento general del sistema. También ayuda a tomar decisiones informadas sobre actualizaciones o cambios necesarios en la infraestructura de almacenamiento. Por lo tanto, la validación del rendimiento es un aspecto crucial de la gestión del sistema y contribuye significativamente a mantener una alta calidad del servicio, la eficiencia operativa y la confiabilidad general del sistema.
En esta sección, nuestro objetivo es profundizar en la validación del rendimiento de bases de datos vectoriales, como Milvus y pgvecto.rs, centrándonos en sus características de rendimiento de almacenamiento, como el perfil de E/S y el comportamiento del controlador de almacenamiento Netapp en apoyo de RAG y cargas de trabajo de inferencia dentro del ciclo de vida de LLM. Evaluaremos e identificaremos cualquier diferenciador de rendimiento cuando estas bases de datos se combinen con la solución de almacenamiento ONTAP . Nuestro análisis se basará en indicadores clave de rendimiento, como el número de consultas procesadas por segundo (QPS).
Consulte la metodología utilizada para milvus y el progreso a continuación.
Detalles |
Milvus (independiente y en clúster) |
Postgres(pgvecto.rs) # |
versión |
2.3.2 |
0.2.0 |
Sistema de archivos |
XFS en LUN iSCSI |
|
Generador de carga de trabajo |
"Banco VectorDB"– versión 0.0.5 |
|
Conjuntos de datos |
Conjunto de datos LAION * 10 millones de incrustaciones * 768 dimensiones * tamaño de conjunto de datos de ~300 GB |
|
Controlador de almacenamiento |
AFF 800 * Versión – 9.14.1 * 4 x 100 GbE – para milvus y 2 x 100 GbE para postgres * iscsi |
VectorDB-Bench con clúster independiente Milvus
Realizamos la siguiente validación de rendimiento en el clúster independiente milvus con vectorDB-Bench. La conectividad de red y servidor del clúster independiente milvus se muestra a continuación.
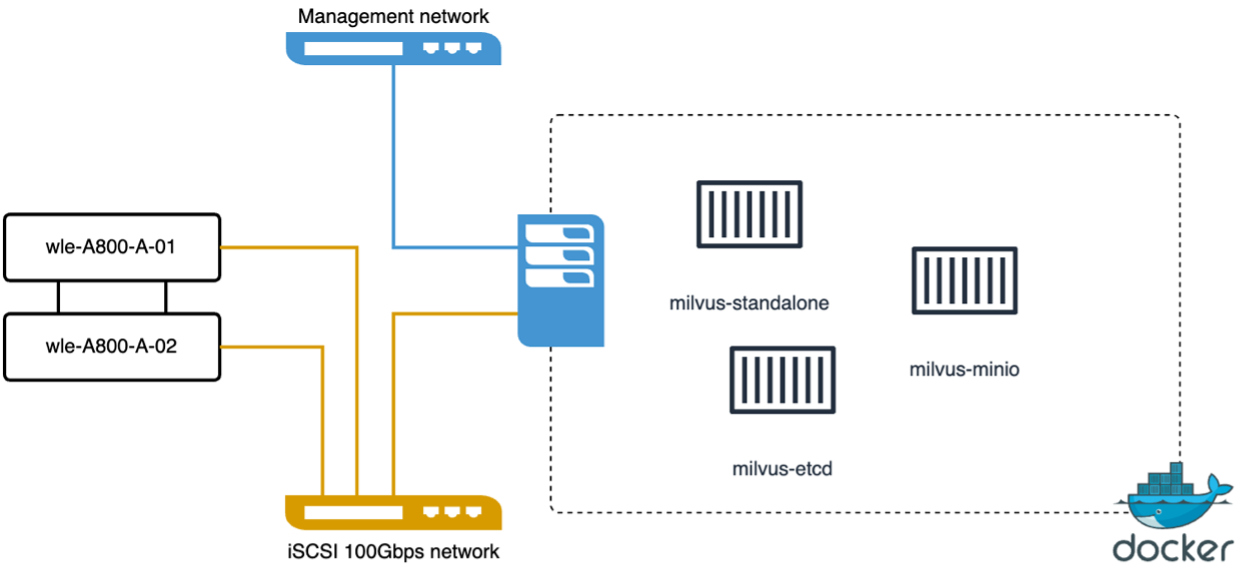
En esta sección, compartimos nuestras observaciones y resultados de la prueba de la base de datos independiente de Milvus. . Seleccionamos DiskANN como el tipo de índice para estas pruebas. . La ingesta, optimización y creación de índices para un conjunto de datos de aproximadamente 100 GB tomó alrededor de 5 horas. Durante la mayor parte de este período, el servidor Milvus, equipado con 20 núcleos (lo que equivale a 40 vcpu cuando Hyper-Threading está habilitado), estuvo funcionando a su capacidad máxima de CPU del 100 %. Descubrimos que DiskANN es particularmente importante para conjuntos de datos grandes que exceden el tamaño de la memoria del sistema. . En la fase de consulta, observamos una tasa de consultas por segundo (QPS) de 10,93 con una recuperación de 0,9987. La latencia del percentil 99 para las consultas se midió en 708,2 milisegundos.
Desde la perspectiva del almacenamiento, la base de datos emitió alrededor de 1000 operaciones por segundo durante las fases de ingesta, optimización posterior a la inserción y creación del índice. En la fase de consulta, demandó 32.000 operaciones por segundo.
En la siguiente sección se presentan las métricas de rendimiento del almacenamiento.
| Fase de carga de trabajo | Métrico | Valor |
|---|---|---|
Ingesta de datos y optimización posterior a la inserción |
IOPS |
< 1.000 |
Estado latente |
< 400 usecs |
|
Carga de trabajo |
Mezcla de lectura y escritura, principalmente escrituras |
|
Tamaño de IO |
64 KB |
|
Consulta |
IOPS |
Pico a los 32.000 |
Estado latente |
< 400 usecs |
|
Carga de trabajo |
Lectura en caché al 100% |
|
Tamaño de IO |
Principalmente 8 KB |
El resultado de vectorDB-bench se muestra a continuación.
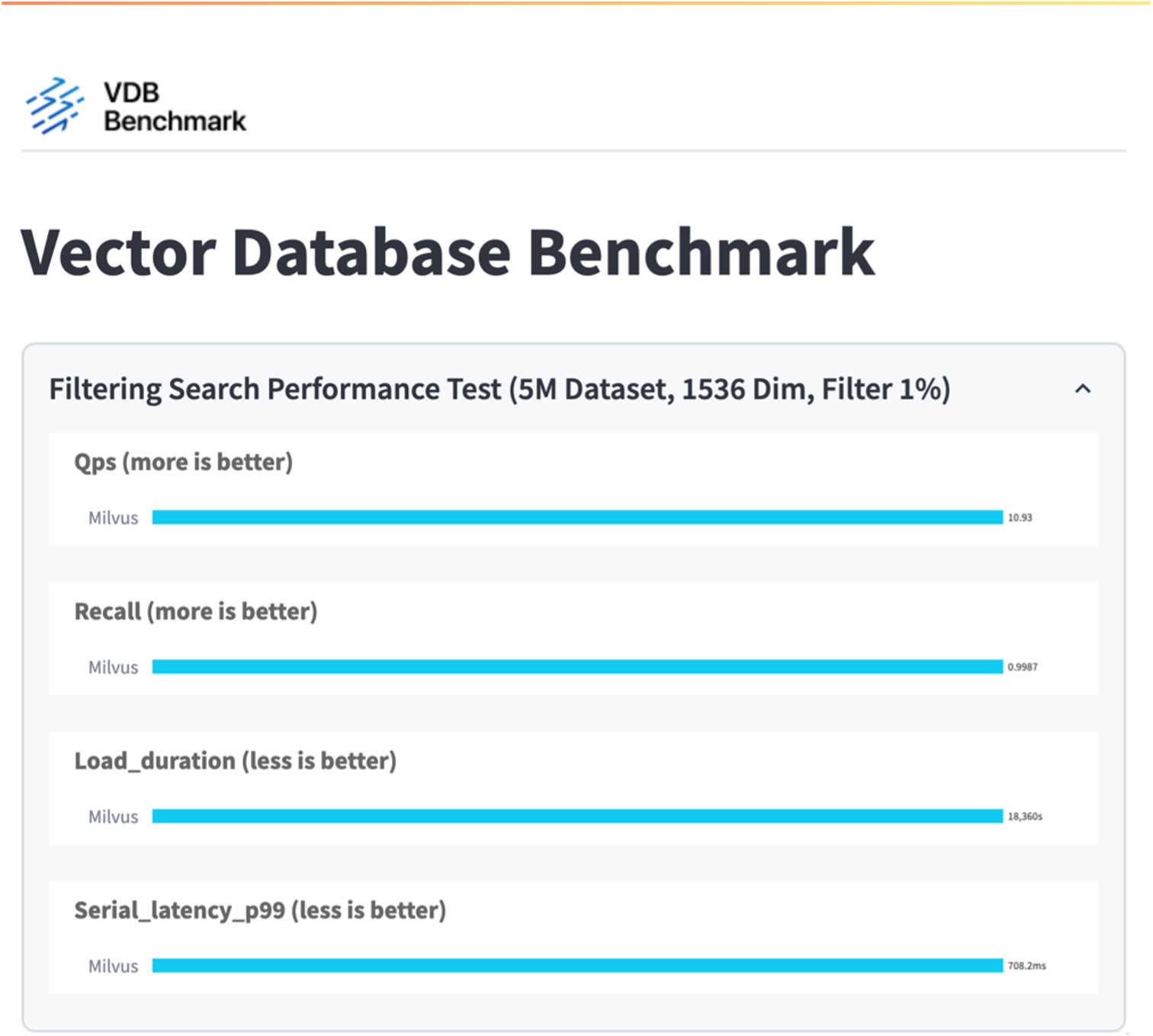
A partir de la validación del rendimiento de la instancia independiente de Milvus, es evidente que la configuración actual es insuficiente para soportar un conjunto de datos de 5 millones de vectores con una dimensionalidad de 1536. Hemos determinado que el almacenamiento posee recursos adecuados y no constituye un cuello de botella en el sistema.
VectorDB-Bench con clúster milvus
En esta sección, analizamos la implementación de un clúster Milvus dentro de un entorno de Kubernetes. Esta configuración de Kubernetes se construyó sobre una implementación de VMware vSphere, que alojaba los nodos maestros y de trabajo de Kubernetes.
Los detalles de las implementaciones de VMware vSphere y Kubernetes se presentan en las siguientes secciones.
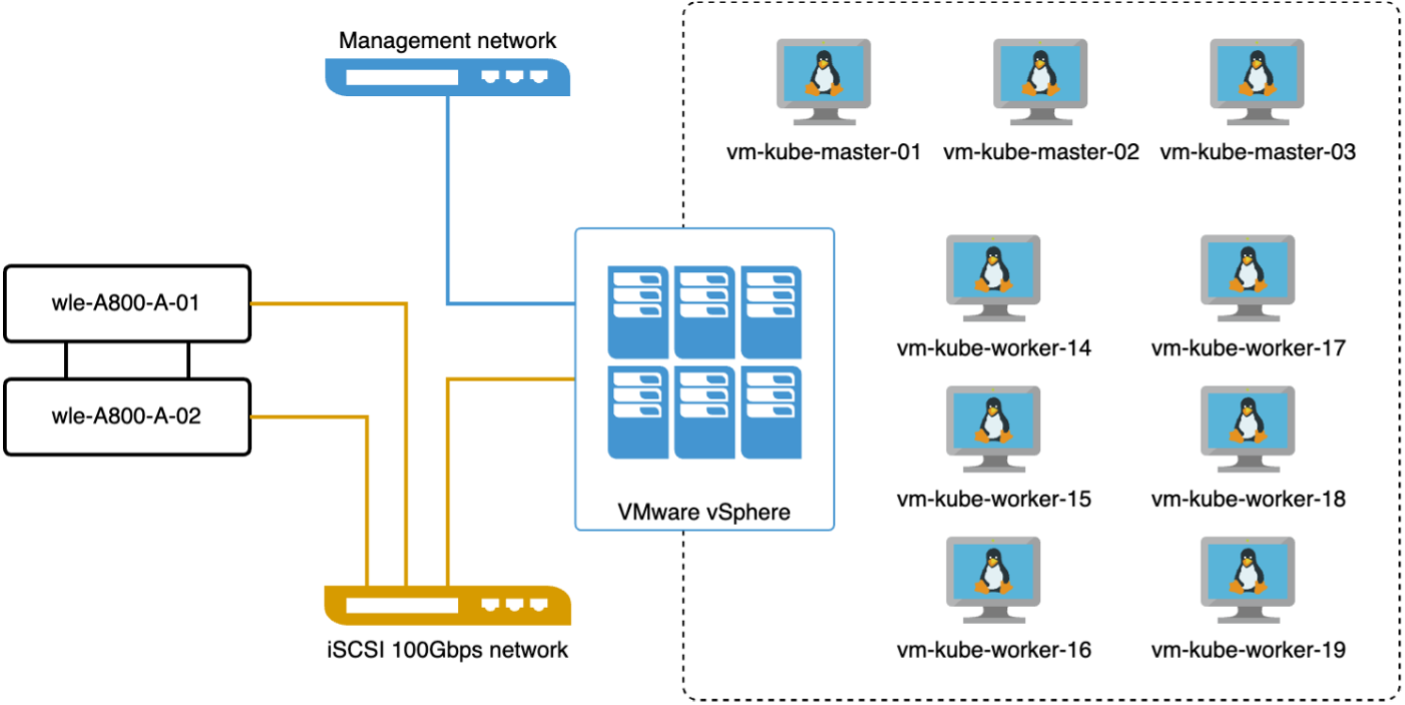
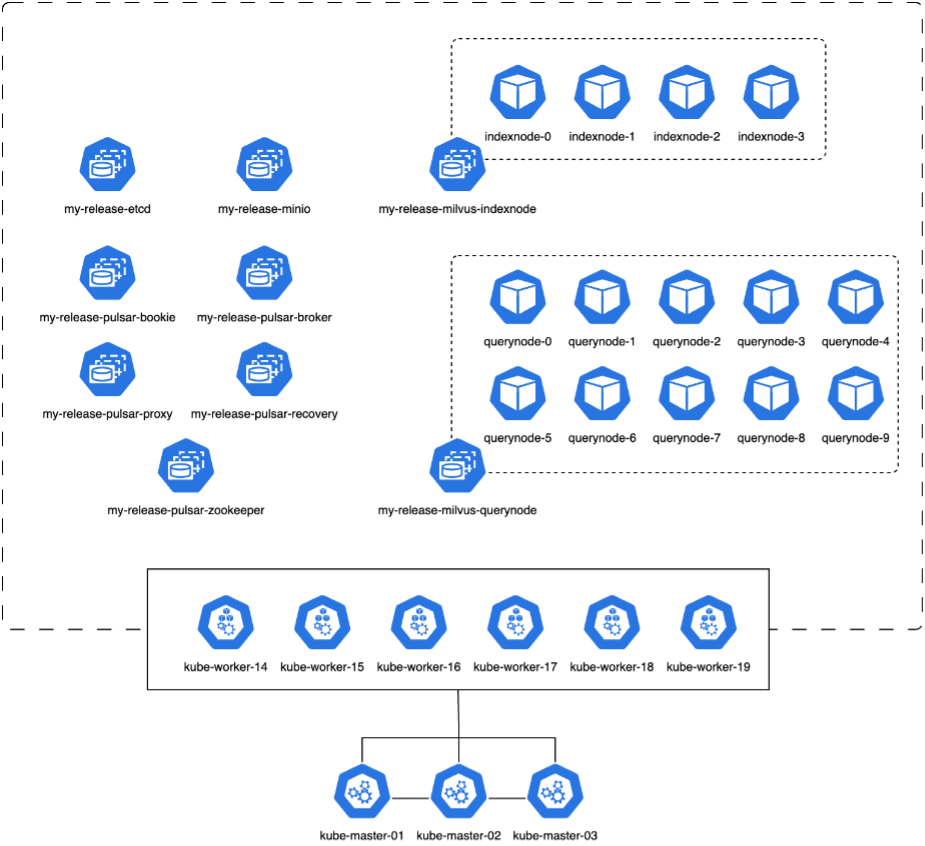
En esta sección, presentamos nuestras observaciones y resultados de las pruebas de la base de datos Milvus. *El tipo de índice utilizado fue DiskANN. * La siguiente tabla proporciona una comparación entre las implementaciones independientes y en clúster cuando se trabaja con 5 millones de vectores con una dimensionalidad de 1536. Observamos que el tiempo necesario para la ingesta de datos y la optimización posterior a la inserción fue menor en la implementación del clúster. La latencia del percentil 99 para las consultas se redujo seis veces en la implementación del clúster en comparación con la configuración independiente. * Aunque la tasa de consultas por segundo (QPS) fue mayor en la implementación del clúster, no estuvo en el nivel deseado.

Las imágenes a continuación proporcionan una vista de varias métricas de almacenamiento, incluida la latencia del clúster de almacenamiento y el total de IOPS (operaciones de entrada/salida por segundo).
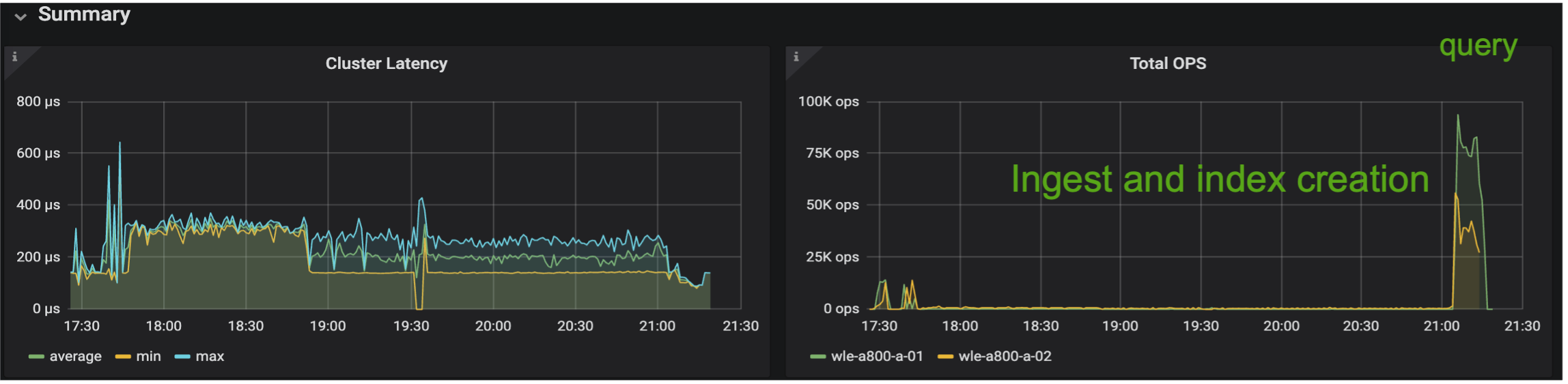
En la siguiente sección se presentan las métricas clave del rendimiento del almacenamiento.
| Fase de carga de trabajo | Métrico | Valor |
|---|---|---|
Ingesta de datos y optimización posterior a la inserción |
IOPS |
< 1.000 |
Estado latente |
< 400 usecs |
|
Carga de trabajo |
Mezcla de lectura y escritura, principalmente escrituras |
|
Tamaño de IO |
64 KB |
|
Consulta |
IOPS |
Pico en 147.000 |
Estado latente |
< 400 usecs |
|
Carga de trabajo |
Lectura en caché al 100% |
|
Tamaño de IO |
Principalmente 8 KB |
Con base en la validación del rendimiento tanto del Milvus independiente como del clúster Milvus, presentamos los detalles del perfil de E/S de almacenamiento. * Observamos que el perfil de E/S permanece consistente tanto en implementaciones independientes como en clúster. * La diferencia observada en el IOPS máximo se puede atribuir a la mayor cantidad de clientes en la implementación del clúster.
vectorDB-Bench con Postgres (pgvecto.rs)
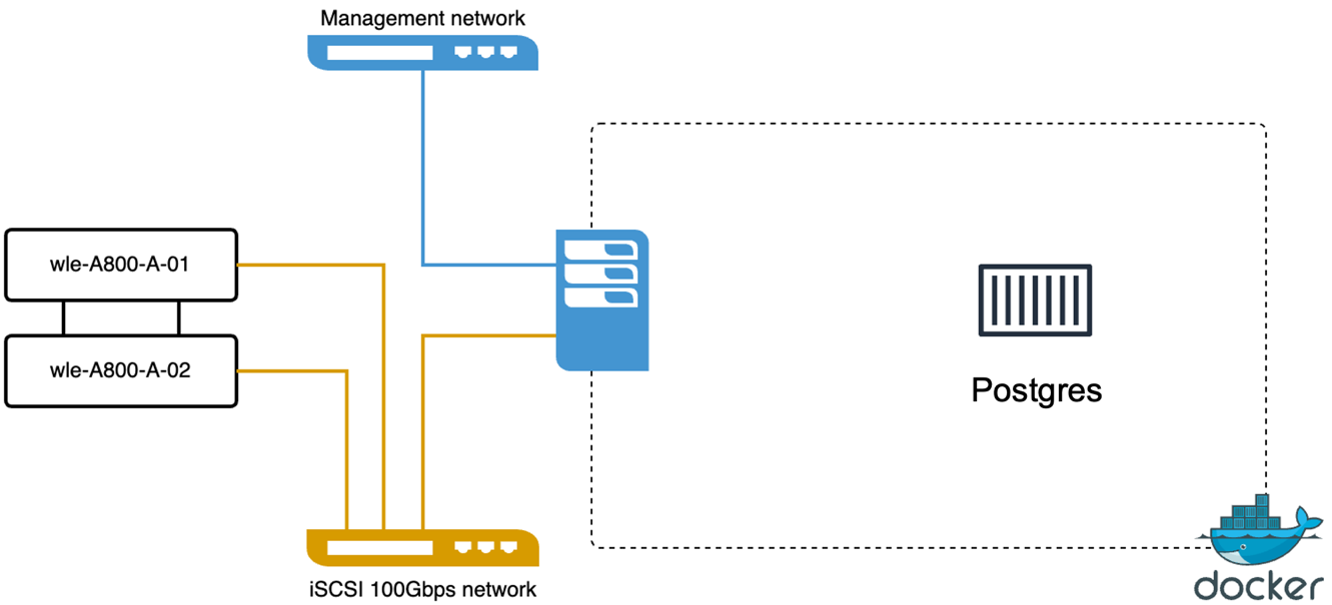
Realizamos las siguientes acciones en PostgreSQL(pgvecto.rs) usando VectorDB-Bench: Los detalles sobre la conectividad de red y servidor de PostgreSQL (específicamente, pgvecto.rs) son los siguientes:
En esta sección, compartimos nuestras observaciones y resultados de las pruebas de la base de datos PostgreSQL, específicamente utilizando pgvecto.rs. * Seleccionamos HNSW como el tipo de índice para estas pruebas porque en el momento de la prueba, DiskANN no estaba disponible para pgvecto.rs. * Durante la fase de ingesta de datos, cargamos el conjunto de datos Cohere, que consta de 10 millones de vectores con una dimensionalidad de 768. Este proceso tardó aproximadamente 4,5 horas. * En la fase de consulta, observamos una tasa de consultas por segundo (QPS) de 1,068 con un recall de 0,6344. La latencia del percentil 99 para las consultas se midió en 20 milisegundos. Durante la mayor parte del tiempo de ejecución, la CPU del cliente funcionó al 100 % de su capacidad.
Las imágenes a continuación proporcionan una vista de varias métricas de almacenamiento, incluidas las IOPS totales (operaciones de entrada/salida por segundo) de latencia del clúster de almacenamiento.

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["Figura que muestra el diálogo de entrada/salida o representa contenido escrito"]
Comparación del rendimiento entre milvus y postgres en Vector DB Bench
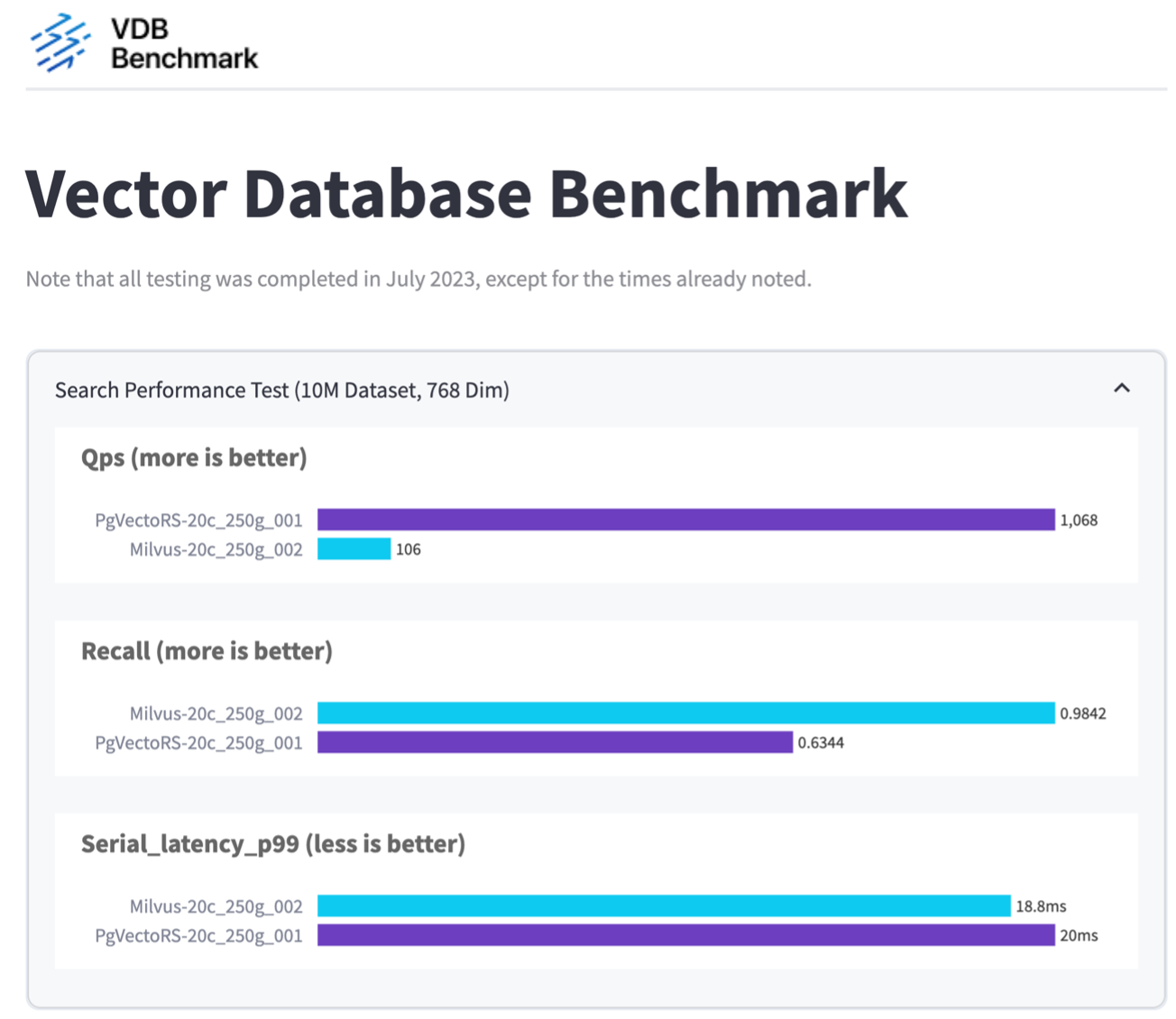
Basándonos en nuestra validación del rendimiento de Milvus y PostgreSQL utilizando VectorDBBench, observamos lo siguiente:
-
Tipo de índice: HNSW
-
Conjunto de datos: Cohere con 10 millones de vectores en 768 dimensiones
Descubrimos que pgvecto.rs logró una tasa de consultas por segundo (QPS) de 1068 con un recall de 0,6344, mientras que Milvus logró una tasa de QPS de 106 con un recall de 0,9842.
Si la alta precisión en sus consultas es una prioridad, Milvus supera a pgvecto.rs ya que recupera una mayor proporción de elementos relevantes por consulta. Sin embargo, si el número de consultas por segundo es un factor más crucial, pgvecto.rs supera a Milvus. Es importante señalar, sin embargo, que la calidad de los datos recuperados a través de pgvecto.rs es menor, y alrededor del 37 % de los resultados de búsqueda son elementos irrelevantes.
Observación basada en nuestras validaciones de desempeño:
Con base en nuestras validaciones de desempeño, hemos realizado las siguientes observaciones:
En Milvus, el perfil de E/S se parece mucho a una carga de trabajo OLTP, como la que se observa con Oracle SLOB. El benchmark consta de tres fases: ingestión de datos, post-optimización y consulta. Las etapas iniciales se caracterizan principalmente por operaciones de escritura de 64 KB, mientras que la fase de consulta implica predominantemente lecturas de 8 KB. Esperamos que ONTAP gestione la carga de E/S de Milvus de manera competente.
El perfil de E/S de PostgreSQL no presenta una carga de trabajo de almacenamiento desafiante. Dada la implementación en memoria actualmente en curso, no observamos ninguna E/S de disco durante la fase de consulta.
DiskANN surge como una tecnología crucial para la diferenciación del almacenamiento. Permite el escalamiento eficiente de la búsqueda en bases de datos vectoriales más allá del límite de la memoria del sistema. Sin embargo, es poco probable que se establezca una diferenciación en el rendimiento del almacenamiento con índices de bases de datos vectoriales en memoria como HNSW.
También vale la pena señalar que el almacenamiento no juega un papel crítico durante la fase de consulta cuando el tipo de índice es HSNW, que es la fase operativa más importante para las bases de datos vectoriales que admiten aplicaciones RAG. La implicación aquí es que el rendimiento del almacenamiento no afecta significativamente el rendimiento general de estas aplicaciones.