

Recuperación ante desastres con CVO y AVS (almacenamiento conectado a invitados)
 Sugerir cambios
Sugerir cambios
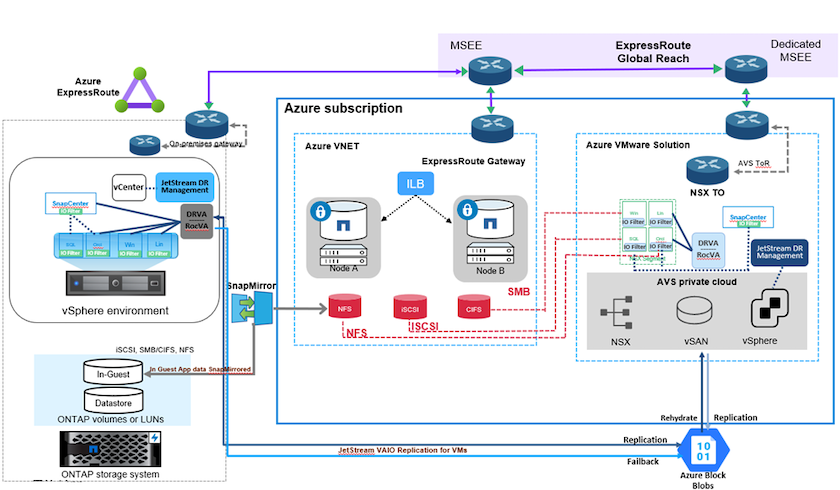
La recuperación ante desastres en la nube es una forma resiliente y rentable de proteger las cargas de trabajo contra interrupciones del sitio y eventos de corrupción de datos como ransomware. Con NetApp SnapMirror, las cargas de trabajo locales de VMware que usan almacenamiento conectado a invitados se pueden replicar en NetApp Cloud Volumes ONTAP que se ejecuta en Azure.
Descripción general
This covers application data; however, what about the actual VMs themselves. Disaster recovery should cover all dependent components, including virtual machines, VMDKs, application data, and more. To accomplish this, SnapMirror along with Jetstream can be used to seamlessly recover workloads replicated from on-premises to Cloud Volumes ONTAP while using vSAN storage for VM VMDKs. Este documento proporciona un enfoque paso a paso para configurar y realizar la recuperación ante desastres que utiliza NetApp SnapMirror, JetStream y Azure VMware Solution (AVS).
Suposiciones
Este documento se centra en el almacenamiento interno de datos de aplicaciones (también conocido como almacenamiento conectado por invitado) y asumimos que el entorno local utiliza SnapCenter para realizar copias de seguridad consistentes con las aplicaciones.

|
Este documento se aplica a cualquier solución de copia de seguridad o recuperación de terceros. Dependiendo de la solución utilizada en el entorno, siga las mejores prácticas para crear políticas de respaldo que cumplan con los SLA de la organización. |
Para la conectividad entre el entorno local y la red virtual de Azure, utilice la ruta rápida Global Reach o una WAN virtual con una puerta de enlace VPN. Los segmentos deben crearse según el diseño de VLAN local.
|
|
Existen múltiples opciones para conectar centros de datos locales a Azure, lo que nos impide delinear un flujo de trabajo específico en este documento. Consulte la documentación de Azure para conocer el método de conectividad local a Azure adecuado. |
Implementación de la solución de recuperación ante desastres
Descripción general de la implementación de la solución
-
Asegúrese de que los datos de la aplicación estén respaldados mediante SnapCenter con los requisitos de RPO necesarios.
-
Aprovisione Cloud Volumes ONTAP con el tamaño de instancia correcto utilizando Cloud Manager dentro de la suscripción y la red virtual adecuadas.
-
Configure SnapMirror para los volúmenes de aplicación relevantes.
-
Actualice las políticas de respaldo en SnapCenter para activar las actualizaciones de SnapMirror después de los trabajos programados.
-
-
Instale el software JetStream DR en el centro de datos local e inicie la protección para máquinas virtuales.
-
Instale el software JetStream DR en la nube privada de Azure VMware Solution.
-
Durante un evento de desastre, interrumpa la relación de SnapMirror mediante Cloud Manager y active la conmutación por error de las máquinas virtuales a Azure NetApp Files o a los almacenes de datos de vSAN en el sitio de AVS DR designado.
-
Vuelva a conectar los LUN ISCSI y los montajes NFS para las máquinas virtuales de la aplicación.
-
-
Invoque la conmutación por error al sitio protegido mediante la resincronización inversa de SnapMirror después de que se haya recuperado el sitio principal.
Detalles de la implementación
Configurar CVO en Azure y replicar volúmenes en CVO
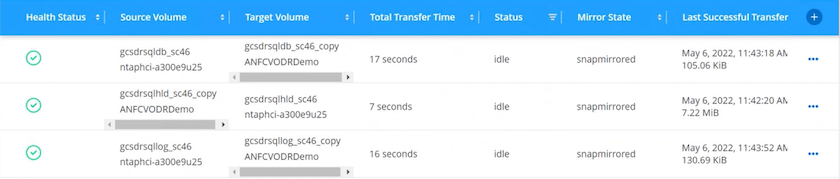
El primer paso es configurar Cloud Volumes ONTAP en Azure ("Enlace" ) y replique los volúmenes deseados en Cloud Volumes ONTAP con las frecuencias y retenciones de instantáneas deseadas.
Configurar los hosts AVS y el acceso a los datos CVO
Dos factores importantes a tener en cuenta al implementar el SDDC son el tamaño del clúster SDDC en la solución Azure VMware y cuánto tiempo mantener el SDDC en servicio. Estas dos consideraciones clave para una solución de recuperación ante desastres ayudan a reducir los costos operativos generales. El SDDC puede ser tan pequeño como tres hosts, o incluso un clúster de múltiples hosts en una implementación a gran escala.
La decisión de implementar un clúster AVS se basa principalmente en los requisitos de RPO/RTO. Con la solución Azure VMware, el SDDC se puede aprovisionar justo a tiempo para prepararse para pruebas o para un evento de desastre real. Un SDDC implementado justo a tiempo ahorra costos de host ESXi cuando no se enfrenta a un desastre. Sin embargo, esta forma de implementación afecta el RTO en algunas horas mientras se aprovisiona el SDDC.
La opción implementada más común es tener el SDDC funcionando en un modo de operación siempre activo y con luz piloto. Esta opción proporciona un espacio reducido de tres hosts que están siempre disponibles y también acelera las operaciones de recuperación al proporcionar una línea base en funcionamiento para actividades de simulación y verificaciones de cumplimiento, evitando así el riesgo de desviaciones operativas entre los sitios de producción y de recuperación ante desastres. El grupo de luces piloto se puede ampliar rápidamente al nivel deseado cuando sea necesario para manejar un evento de DR real.
Para configurar AVS SDDC (ya sea a pedido o en modo piloto), consulte"Implementar y configurar el entorno de virtualización en Azure" . Como requisito previo, verifique que las máquinas virtuales invitadas que residen en los hosts AVS puedan consumir datos de Cloud Volumes ONTAP una vez que se haya establecido la conectividad.
Una vez que Cloud Volumes ONTAP y AVS se hayan configurado correctamente, comience a configurar Jetstream para automatizar la recuperación de cargas de trabajo locales en AVS (máquinas virtuales con VMDK de aplicaciones y máquinas virtuales con almacenamiento invitado) mediante el mecanismo VAIO y aprovechando SnapMirror para las copias de volúmenes de aplicaciones en Cloud Volumes ONTAP.
Instalar JetStream DR en el centro de datos local
El software JetStream DR consta de tres componentes principales: JetStream DR Management Server Virtual Appliance (MSA), DR Virtual Appliance (DRVA) y componentes de host (paquetes de filtros de E/S). El MSA se utiliza para instalar y configurar componentes del host en el clúster de cómputo y luego para administrar el software JetStream DR. El proceso de instalación es el siguiente:
-
Consulte los requisitos previos.
-
Ejecute la herramienta de planificación de capacidad para obtener recomendaciones de recursos y configuración.
-
Implemente JetStream DR MSA en cada host vSphere en el clúster designado.
-
Inicie el MSA utilizando su nombre DNS en un navegador.
-
Registre el servidor vCenter con MSA.
-
Una vez implementado JetStream DR MSA y registrado vCenter Server, navegue hasta el complemento JetStream DR con vSphere Web Client. Esto se puede hacer navegando a Centro de datos > Configurar > JetStream DR.
-
Desde la interfaz de JetStream DR, complete las siguientes tareas:
-
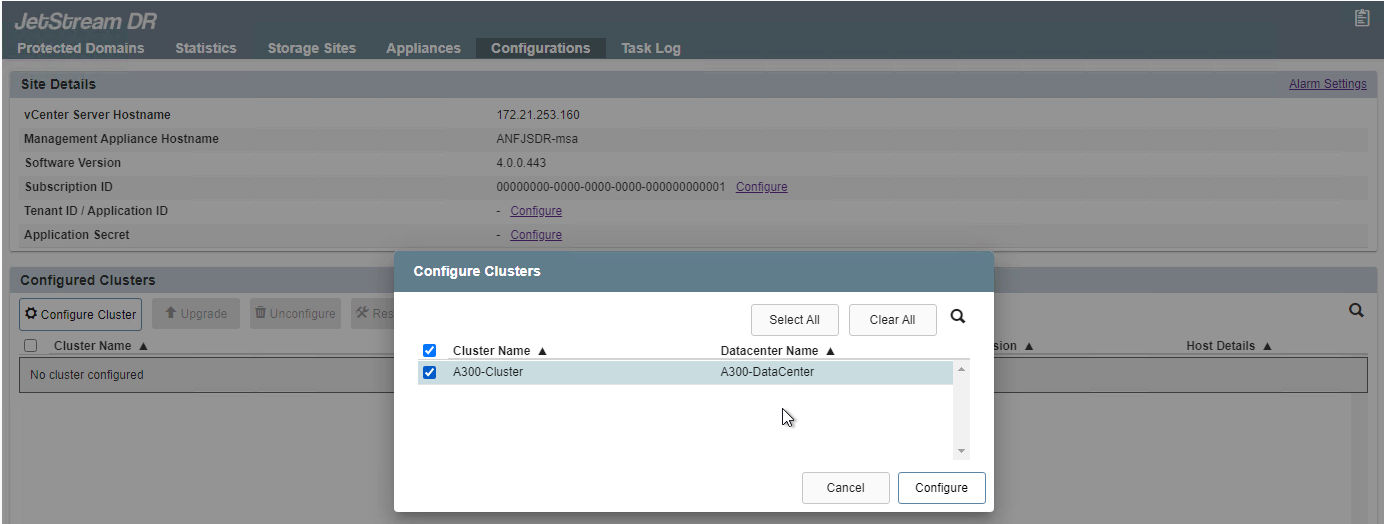
Configure el clúster con el paquete de filtro de E/S.
-
Agregue el almacenamiento de blobs de Azure ubicado en el sitio de recuperación.
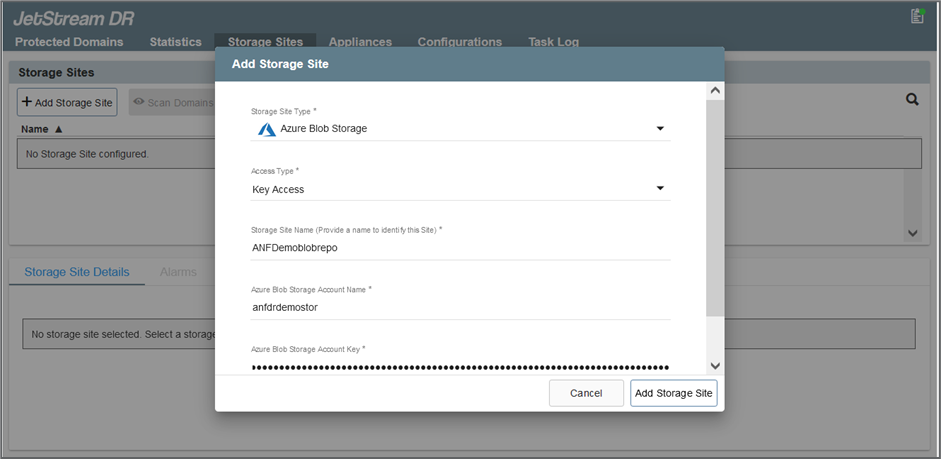
-
-
Implemente la cantidad necesaria de dispositivos virtuales de recuperación ante desastres (DRVA) desde la pestaña Dispositivos.
Utilice la herramienta de planificación de capacidad para estimar la cantidad de DRVA necesarios. 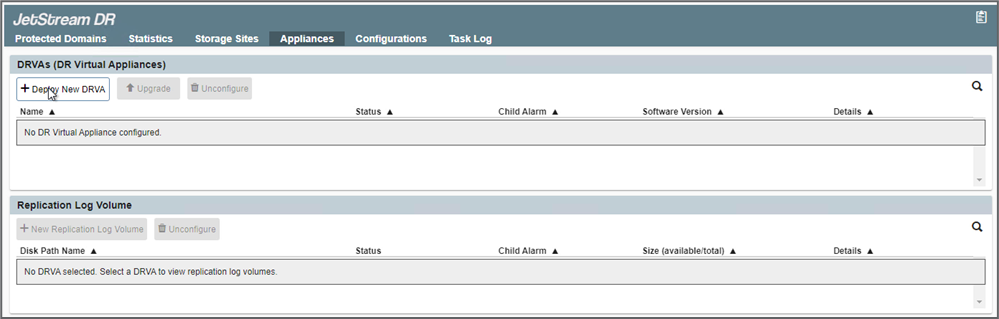
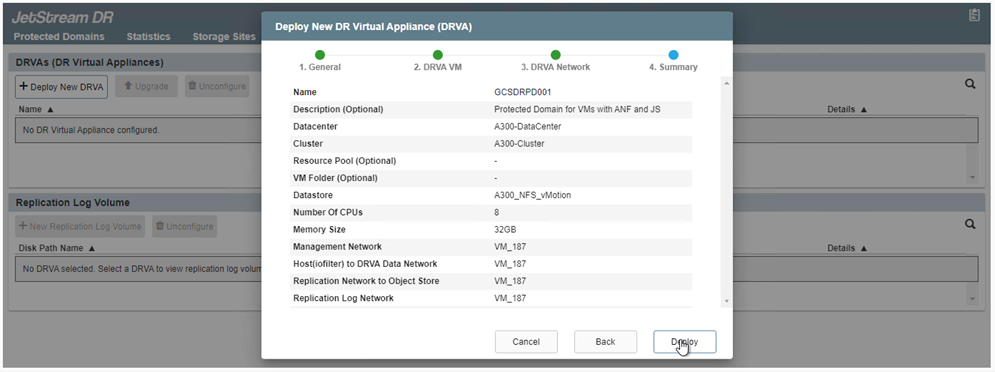
-
Cree volúmenes de registro de replicación para cada DRVA utilizando el VMDK de los almacenes de datos disponibles o el grupo de almacenamiento iSCSI compartido independiente.
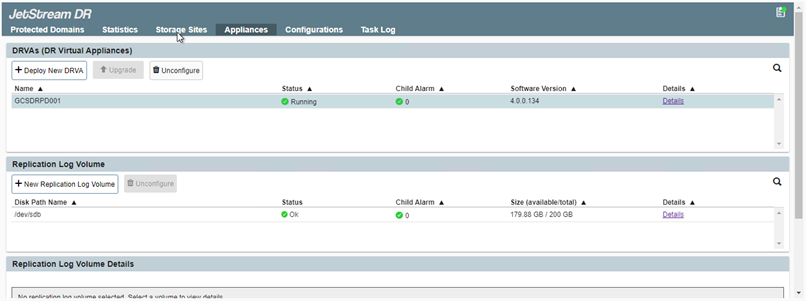
-
Desde la pestaña Dominios protegidos, cree la cantidad necesaria de dominios protegidos utilizando información sobre el sitio de Azure Blob Storage, la instancia de DRVA y el registro de replicación. Un dominio protegido define una máquina virtual específica o un conjunto de máquinas virtuales de aplicación dentro del clúster que están protegidas juntas y a las que se les asigna un orden de prioridad para operaciones de conmutación por error/recuperación.
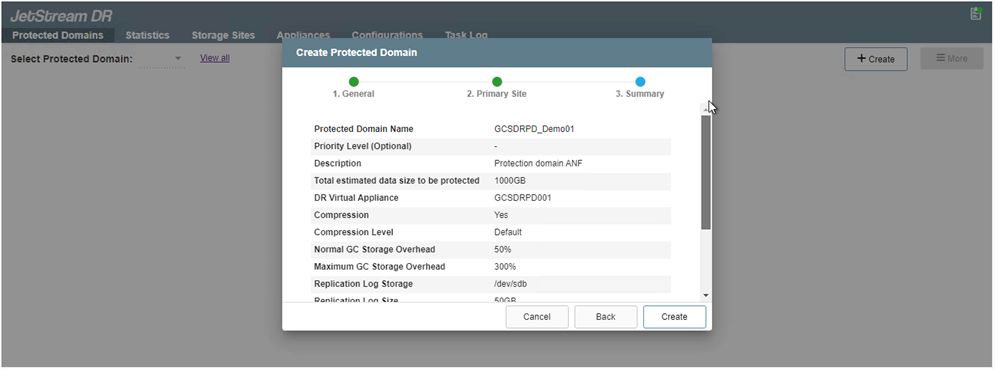
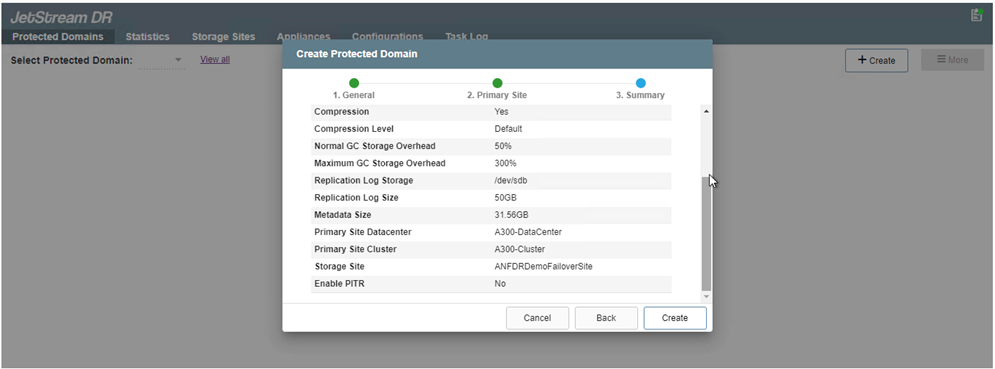
-
Seleccione las máquinas virtuales que desea proteger y agrúpelas en grupos de aplicaciones según la dependencia. Las definiciones de aplicación le permiten agrupar conjuntos de máquinas virtuales en grupos lógicos que contienen sus órdenes de arranque, retrasos de arranque y validaciones de aplicaciones opcionales que se pueden ejecutar durante la recuperación.
Asegúrese de que se utilice el mismo modo de protección para todas las máquinas virtuales en un dominio protegido.
El modo de escritura diferida (VMDK) ofrece un mayor rendimiento. 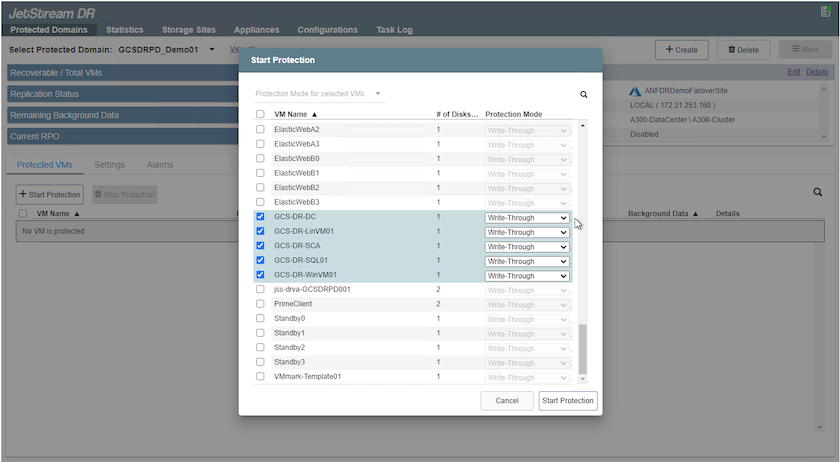
-
Asegúrese de que los volúmenes de registro de replicación estén ubicados en un almacenamiento de alto rendimiento.
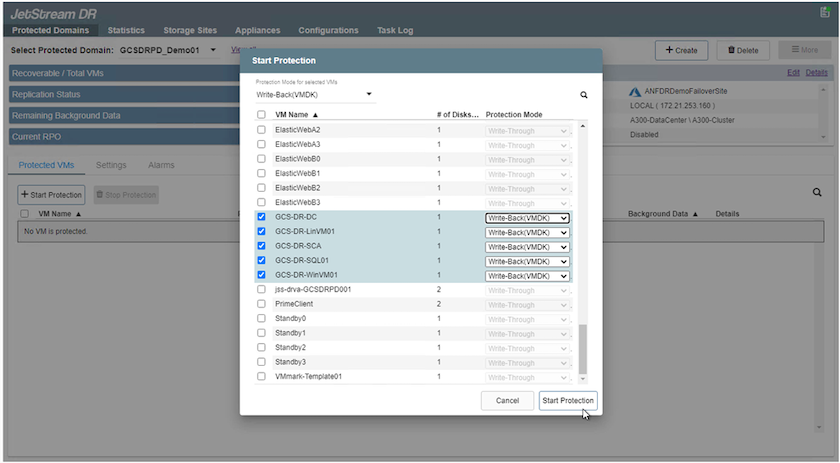
-
Una vez que haya terminado, haga clic en Iniciar protección para el dominio protegido. Esto inicia la replicación de datos de las máquinas virtuales seleccionadas en el almacén de blobs designado.
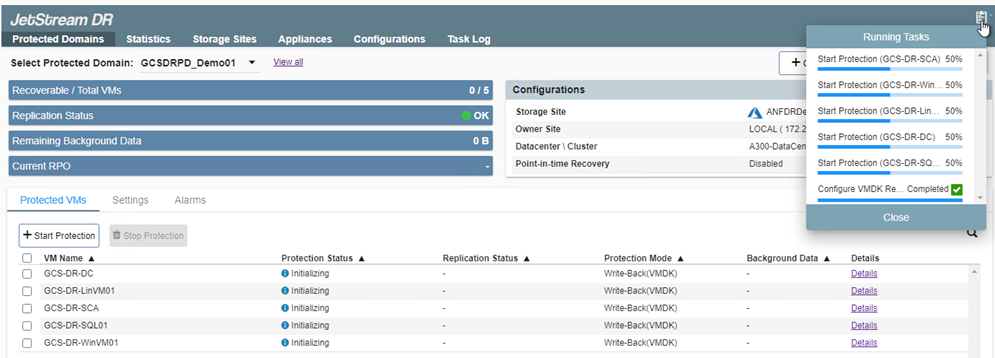
-
Una vez completada la replicación, el estado de protección de la máquina virtual se marca como Recuperable.
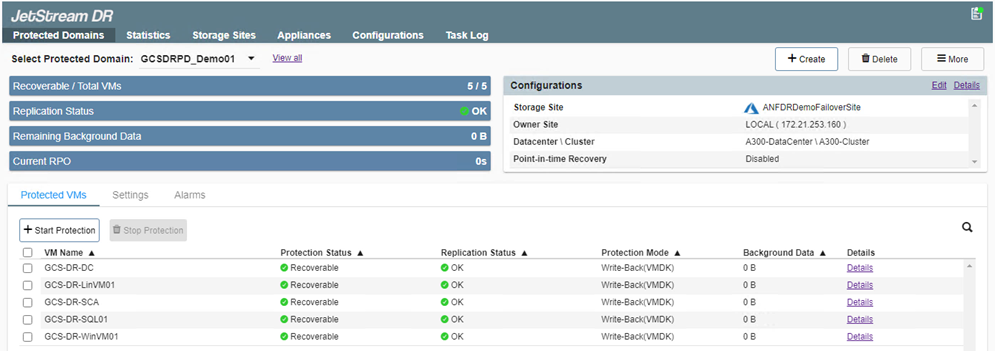
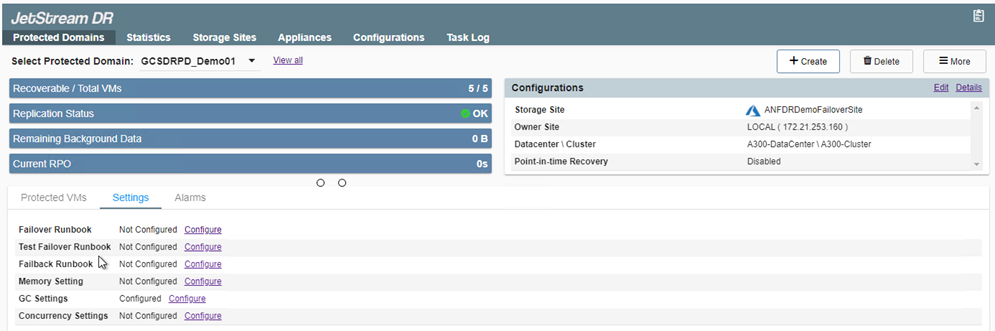
Los libros de ejecución de conmutación por error se pueden configurar para agrupar las máquinas virtuales (llamado grupo de recuperación), establecer la secuencia de orden de arranque y modificar las configuraciones de CPU/memoria junto con las configuraciones de IP. -
Haga clic en Configuración y luego en el vínculo Configurar del libro de ejecución para configurar el grupo de libros de ejecución.
-
Haga clic en el botón Crear grupo para comenzar a crear un nuevo grupo de libros de ejecución.
Si es necesario, en la parte inferior de la pantalla, aplique pre-scripts y post-scripts personalizados para que se ejecuten automáticamente antes y después de la operación del grupo de libros de ejecución. Asegúrese de que los scripts de Runbook residan en el servidor de administración. 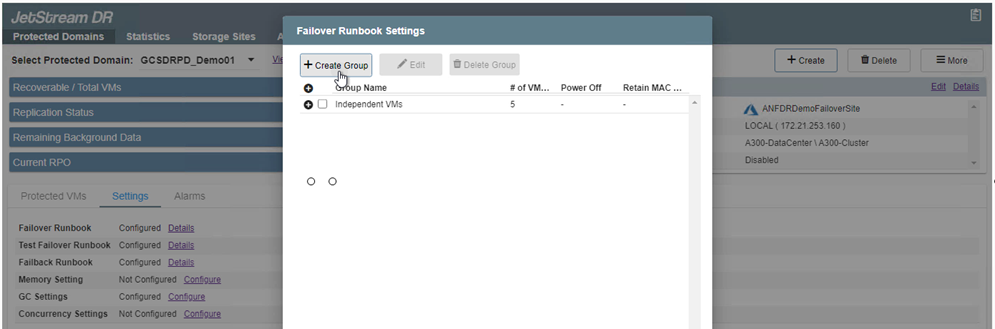
-
Edite la configuración de la máquina virtual según sea necesario. Especifique los parámetros para recuperar las máquinas virtuales, incluida la secuencia de arranque, el retraso de arranque (especificado en segundos), la cantidad de CPU y la cantidad de memoria a asignar. Cambie la secuencia de arranque de las máquinas virtuales haciendo clic en las flechas hacia arriba o hacia abajo. También se proporcionan opciones para conservar MAC.
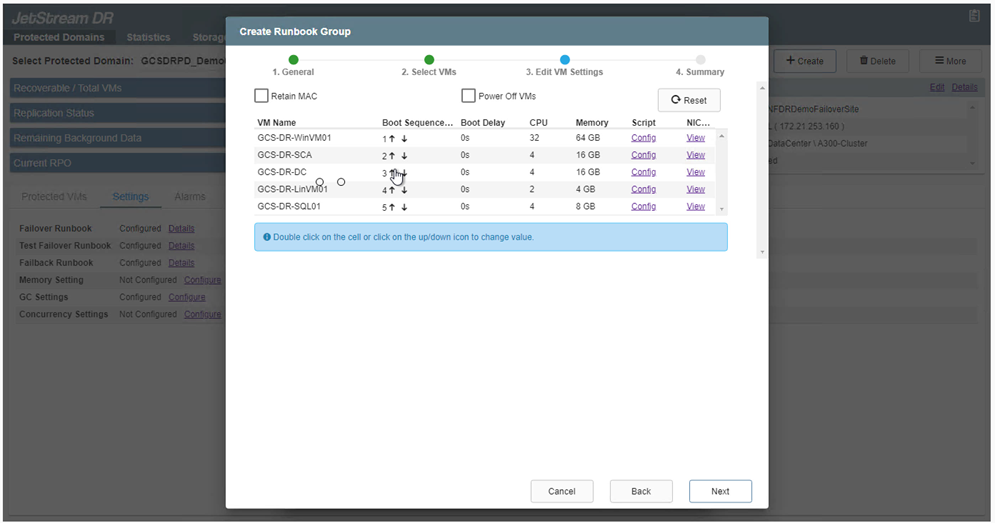
-
Las direcciones IP estáticas se pueden configurar manualmente para las máquinas virtuales individuales del grupo. Haga clic en el enlace Vista NIC de una VM para configurar manualmente sus ajustes de dirección IP.
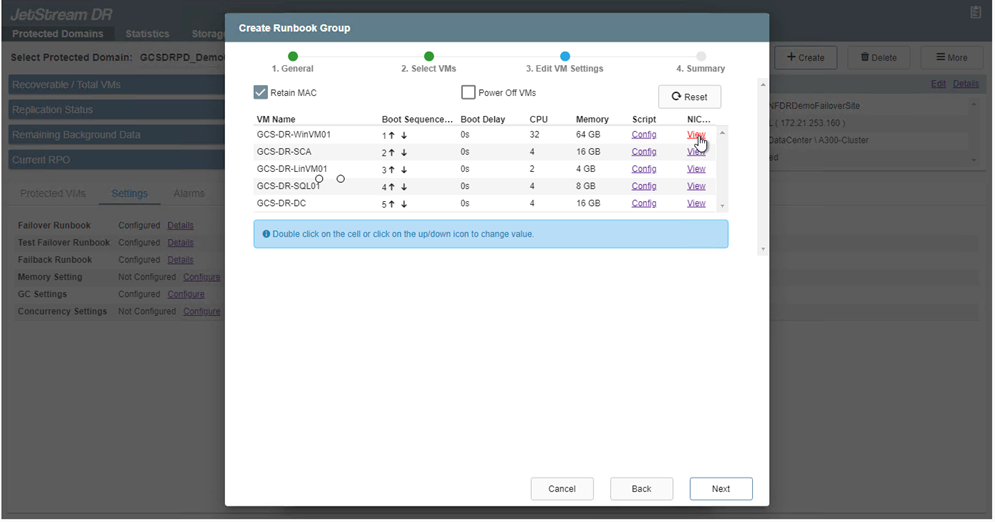
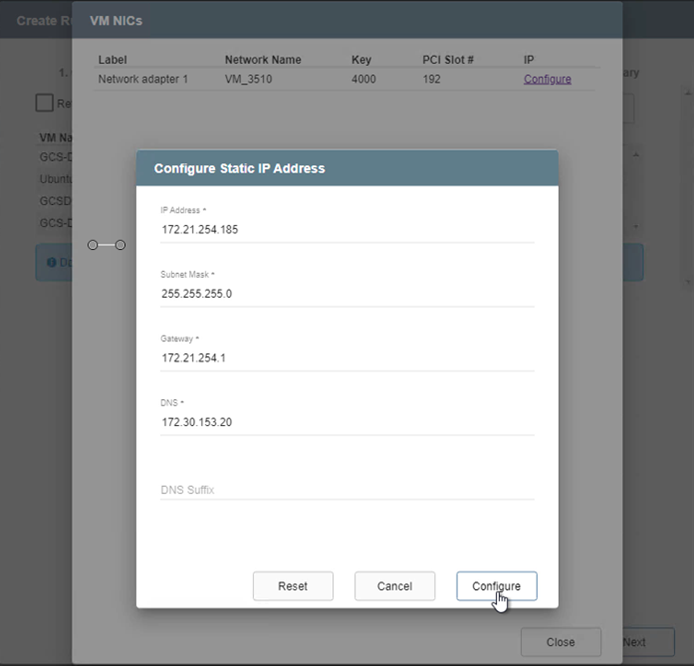
-
Haga clic en el botón Configurar para guardar la configuración de NIC para las respectivas máquinas virtuales.
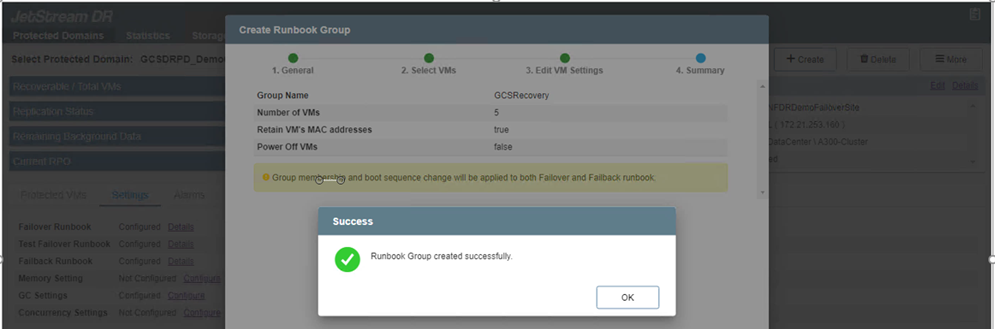
El estado de los libros de ejecución de conmutación por error y de recuperación ahora aparece como Configurado. Los grupos de libros de ejecución de conmutación por error y recuperación se crean en pares utilizando el mismo grupo inicial de máquinas virtuales y configuraciones. Si es necesario, es posible personalizar individualmente la configuración de cualquier grupo de runbooks haciendo clic en su enlace Detalles correspondiente y realizando cambios.
Instalar JetStream DR para AVS en la nube privada
Una práctica recomendada para un sitio de recuperación (AVS) es crear con anticipación un clúster piloto de tres nodos. Esto permite preconfigurar la infraestructura del sitio de recuperación, incluido lo siguiente:
-
Segmentos de red de destino, firewalls, servicios como DHCP y DNS, etc.
-
Instalación de JetStream DR para AVS
-
Configuración de volúmenes ANF como almacenes de datos y más
JetStream DR admite un modo RTO casi cero para dominios de misión crítica. Para estos dominios, el almacenamiento de destino debe estar preinstalado. ANF es el tipo de almacenamiento recomendado en este caso.
|
|
La configuración de la red, incluida la creación de segmentos, debe configurarse en el clúster AVS para que coincida con los requisitos locales. |
|
|
Dependiendo de los requisitos de SLA y RTO, puede utilizar el modo de conmutación por error continuo o el modo de conmutación por error regular (estándar). Para un RTO cercano a cero, debe comenzar la rehidratación continua en el sitio de recuperación. |
-
Para instalar JetStream DR para AVS en una nube privada de Azure VMware Solution, use el comando Ejecutar. Desde el portal de Azure, vaya a la solución Azure VMware, seleccione la nube privada y seleccione Ejecutar comando > Paquetes > JSDR.Configuration.
El usuario CloudAdmin predeterminado de Azure VMware Solution no tiene privilegios suficientes para instalar JetStream DR para AVS. La solución Azure VMware permite una instalación simplificada y automatizada de JetStream DR invocando el comando Ejecutar de la solución Azure VMware para JetStream DR. La siguiente captura de pantalla muestra la instalación utilizando una dirección IP basada en DHCP.
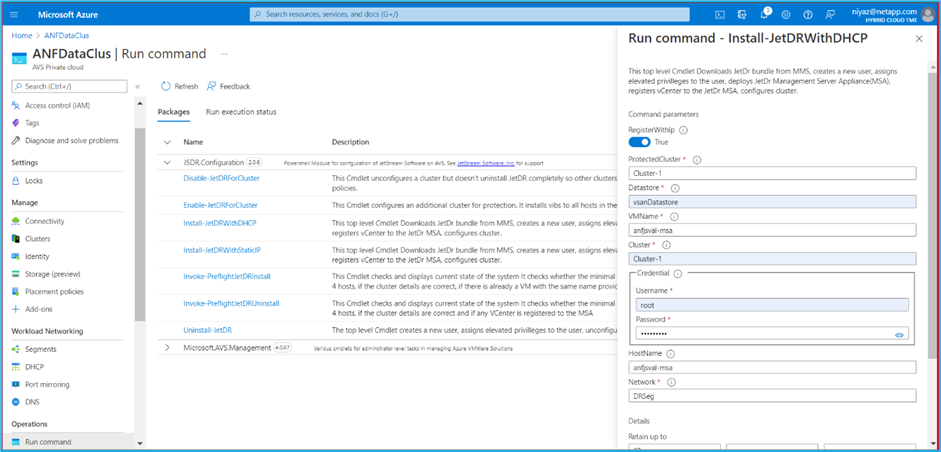
-
Una vez completada la instalación de JetStream DR para AVS, actualice el navegador. Para acceder a la interfaz de usuario de JetStream DR, vaya a SDDC Datacenter > Configurar > JetStream DR.
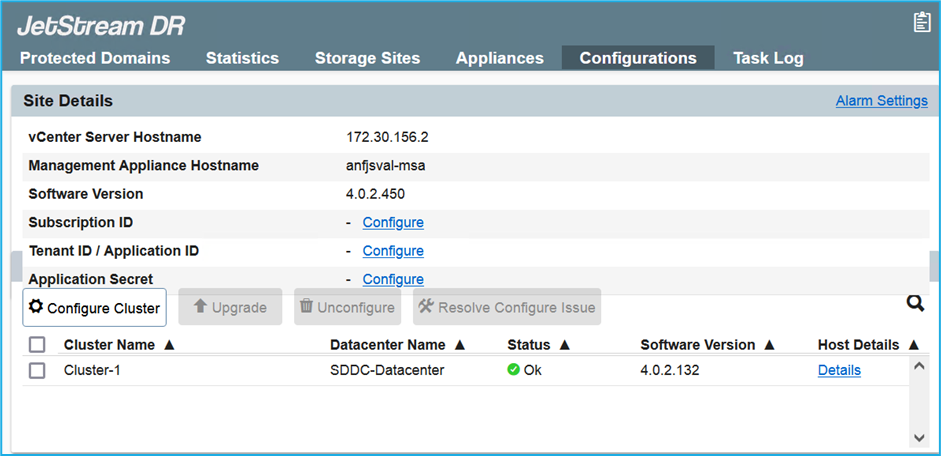
-
Desde la interfaz de JetStream DR, complete las siguientes tareas:
-
Agregue la cuenta de Azure Blob Storage que se usó para proteger el clúster local como un sitio de almacenamiento y luego ejecute la opción Escanear dominios.
-
En la ventana de diálogo emergente que aparece, seleccione el dominio protegido que desea importar y luego haga clic en su enlace Importar.

-
-
El dominio se importa para su recuperación. Vaya a la pestaña Dominios protegidos y verifique que se haya seleccionado el dominio deseado o elija el deseado en el menú Seleccionar dominio protegido. Se muestra una lista de las máquinas virtuales recuperables en el dominio protegido.
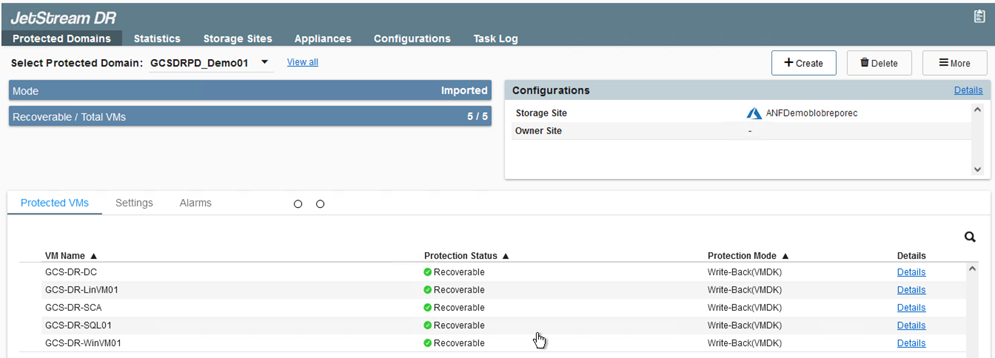
-
Una vez importados los dominios protegidos, implemente los dispositivos DRVA.
Estos pasos también se pueden automatizar utilizando planes creados por CPT. -
Cree volúmenes de registro de replicación utilizando almacenes de datos vSAN o ANF disponibles.
-
Importe los dominios protegidos y configure el VA de recuperación para utilizar un almacén de datos ANF para las ubicaciones de VM.
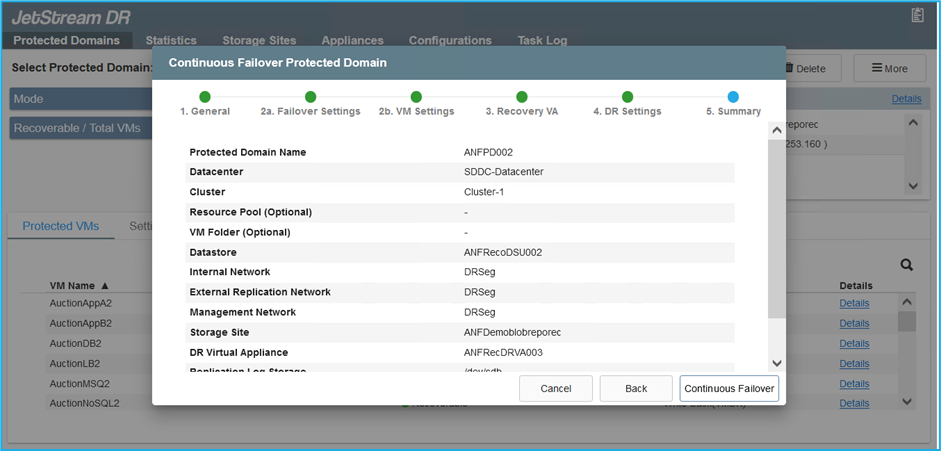
Asegúrese de que DHCP esté habilitado en el segmento seleccionado y que haya suficientes IP disponibles. Las IP dinámicas se utilizan temporalmente mientras los dominios se recuperan. Cada VM en recuperación (incluida la rehidratación continua) requiere una IP dinámica individual. Una vez completada la recuperación, la IP se libera y se puede reutilizar. -
Seleccione la opción de conmutación por error adecuada (conmutación por error continua o conmutación por error). En este ejemplo, se selecciona la rehidratación continua (conmutación por error continua).
Aunque los modos de conmutación por error continua y conmutación por error difieren en cuanto al momento en que se realiza la configuración, ambos modos de conmutación por error se configuran utilizando los mismos pasos. Los pasos de conmutación por error se configuran y se ejecutan juntos en respuesta a un evento de desastre. La conmutación por error continua se puede configurar en cualquier momento y luego permitir que se ejecute en segundo plano durante el funcionamiento normal del sistema. Después de que ocurre un evento de desastre, se completa una conmutación por error continua para transferir de inmediato la propiedad de las máquinas virtuales protegidas al sitio de recuperación (RTO cercano a cero). 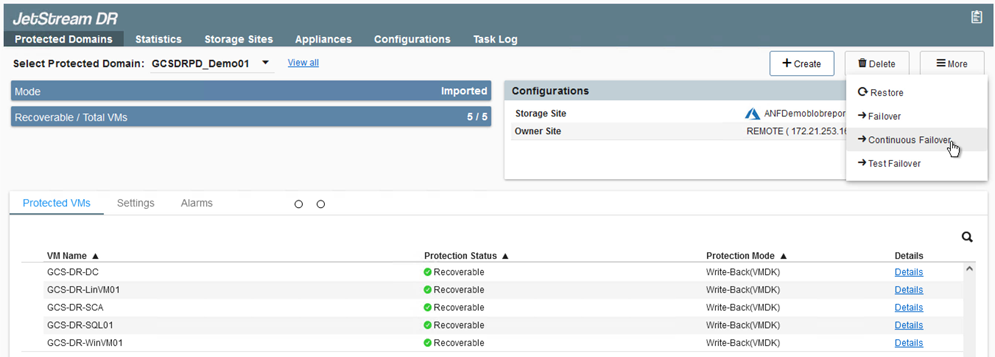
Comienza el proceso de conmutación por error continua y su progreso se puede supervisar desde la interfaz de usuario. Al hacer clic en el ícono azul en la sección Paso actual, se abre una ventana emergente que muestra detalles del paso actual del proceso de conmutación por error.
Conmutación por error y recuperación
-
Después de que ocurre un desastre en el clúster protegido del entorno local (falla parcial o completa), puede activar la conmutación por error para las máquinas virtuales mediante Jetstream después de romper la relación SnapMirror para los respectivos volúmenes de la aplicación.
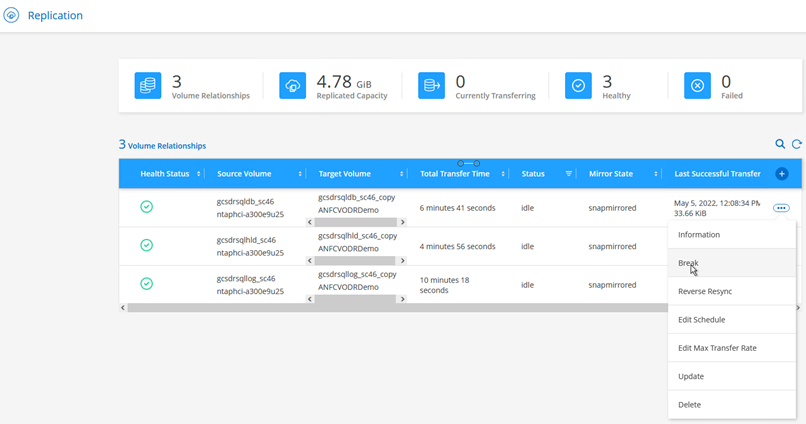
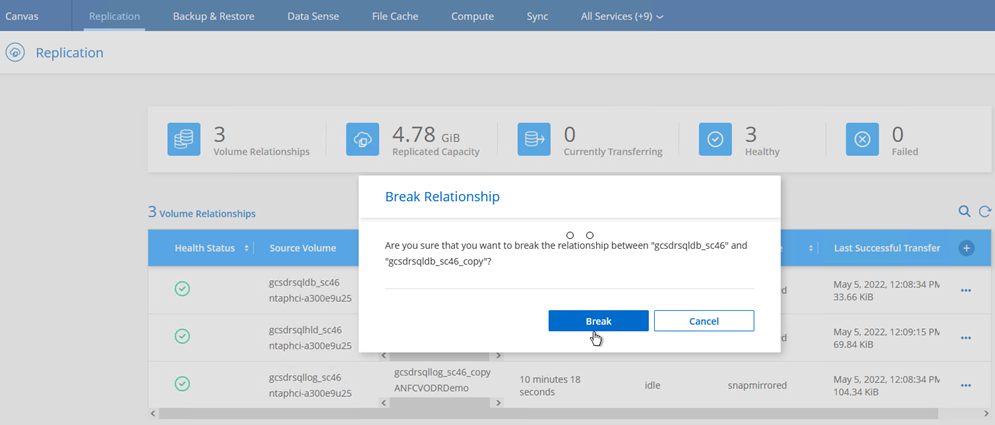
Este paso se puede automatizar fácilmente para facilitar el proceso de recuperación. -
Acceda a la interfaz de usuario de Jetstream en AVS SDDC (lado de destino) y active la opción de conmutación por error para completar la conmutación por error. La barra de tareas muestra el progreso de las actividades de conmutación por error.
En la ventana de diálogo que aparece al completar la conmutación por error, se puede especificar la tarea de conmutación por error como planificada o asumir que será forzada.
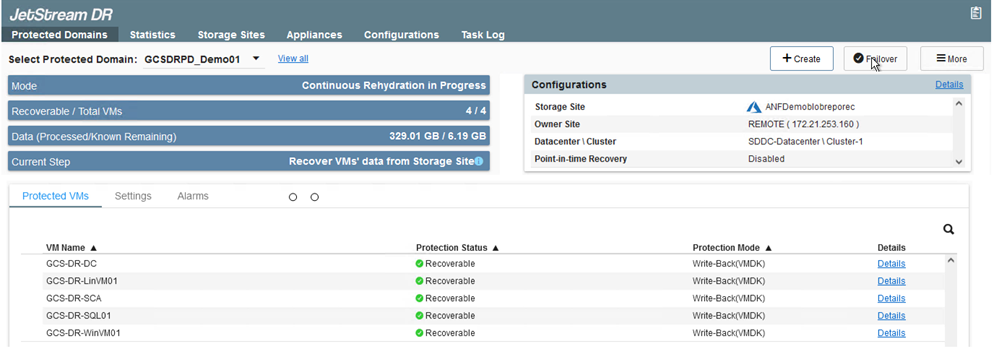
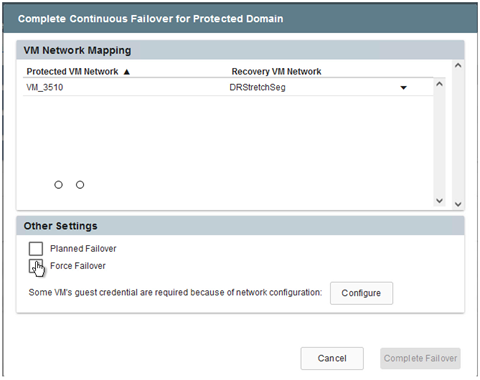
La conmutación por error forzada supone que el sitio principal ya no es accesible y que la propiedad del dominio protegido debe ser asumida directamente por el sitio de recuperación.
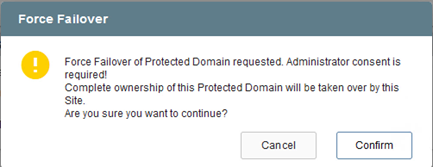
-
Una vez completada la conmutación por error continua, aparece un mensaje que confirma la finalización de la tarea. Una vez completada la tarea, acceda a las máquinas virtuales recuperadas para configurar sesiones ISCSI o NFS.
El modo de conmutación por error cambia a Ejecutándose en conmutación por error y el estado de la VM es Recuperable. Todas las máquinas virtuales del dominio protegido ahora se están ejecutando en el sitio de recuperación en el estado especificado por la configuración del libro de ejecución de conmutación por error.
Para verificar la configuración y la infraestructura de conmutación por error, JetStream DR se puede utilizar en modo de prueba (opción de conmutación por error de prueba) para observar la recuperación de las máquinas virtuales y sus datos desde el almacén de objetos a un entorno de recuperación de prueba. Cuando se ejecuta un procedimiento de conmutación por error en modo de prueba, su funcionamiento se asemeja a un proceso de conmutación por error real. 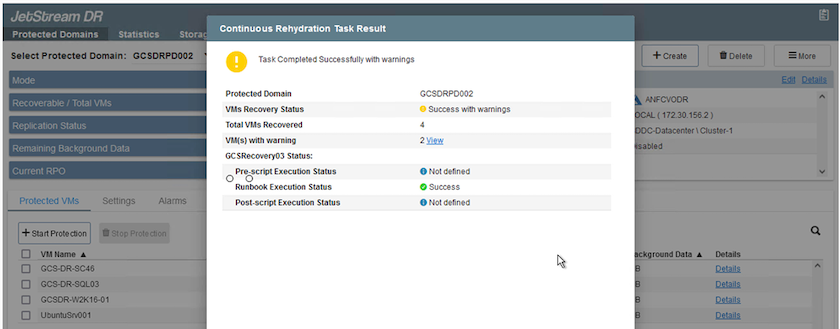
-
Una vez recuperadas las máquinas virtuales, utilice la recuperación ante desastres de almacenamiento para el almacenamiento invitado. Para demostrar este proceso, en este ejemplo se utiliza el servidor SQL.
-
Inicie sesión en la máquina virtual SnapCenter recuperada en AVS SDDC y habilite el modo DR.
-
Acceda a la interfaz de usuario de SnapCenter mediante el navegadorN.
-
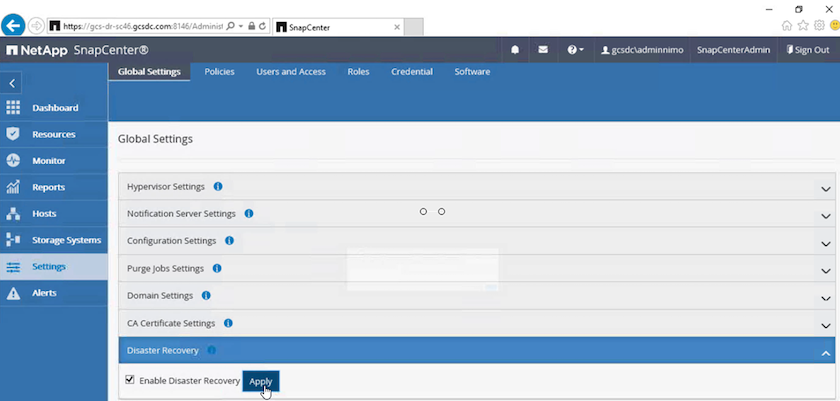
En la página de Configuración, navegue a Configuración > Configuración global > Recuperación ante desastres.
-
Seleccione Habilitar recuperación ante desastres.
-
Haga clic en Aplicar.
-
Verifique si el trabajo de DR está habilitado haciendo clic en Monitorear > Trabajos.
Se debe utilizar NetApp SnapCenter 4.6 o posterior para la recuperación ante desastres de almacenamiento. Para versiones anteriores, se deben utilizar instantáneas consistentes con la aplicación (replicadas mediante SnapMirror) y se debe ejecutar una recuperación manual en caso de que se deban recuperar copias de seguridad anteriores en el sitio de recuperación ante desastres.
-
-
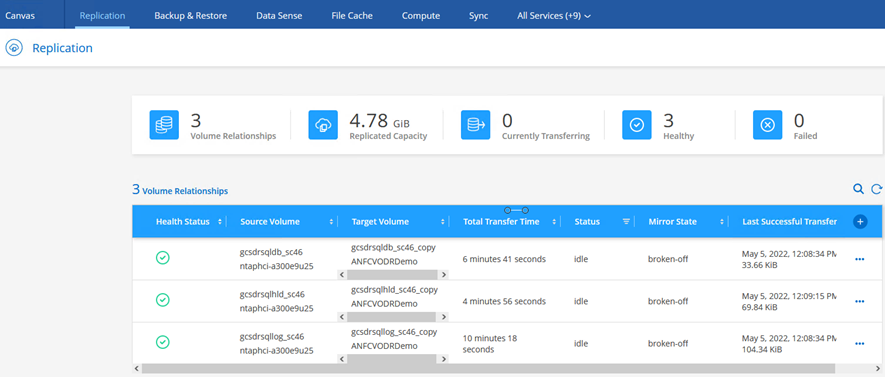
Asegúrese de que la relación SnapMirror esté rota.
-
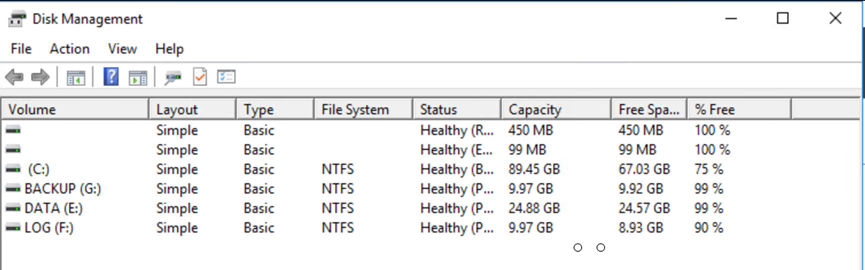
Adjunte el LUN de Cloud Volumes ONTAP a la máquina virtual invitada SQL recuperada con las mismas letras de unidad.
-
Abra el iniciador iSCSI, borre la sesión desconectada anterior y agregue el nuevo destino junto con la ruta múltiple para los volúmenes de Cloud Volumes ONTAP replicados.
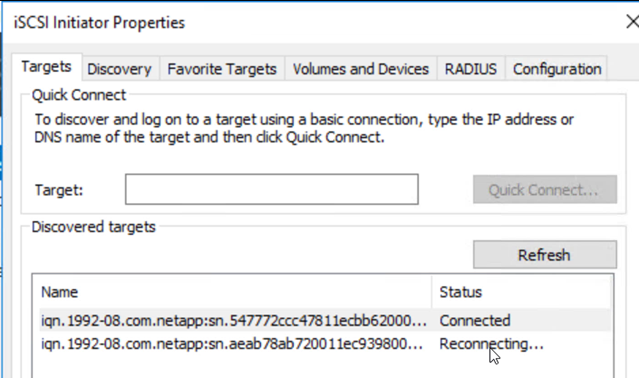
-
Asegúrese de que todos los discos estén conectados utilizando las mismas letras de unidad que se usaron antes de la recuperación ante desastres.
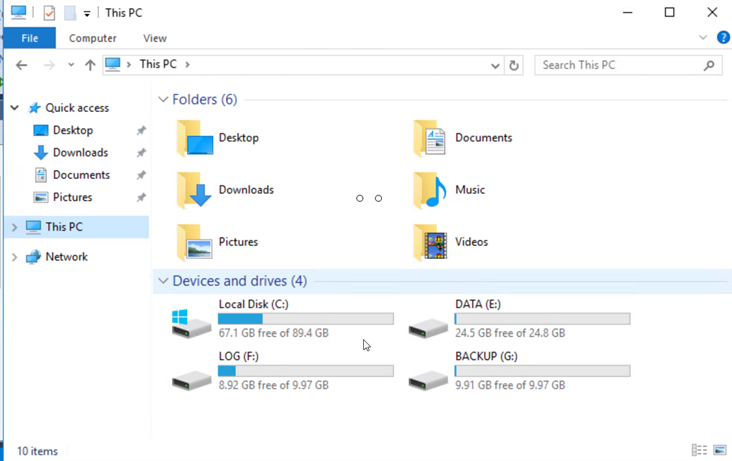
-
Reinicie el servicio del servidor MSSQL.
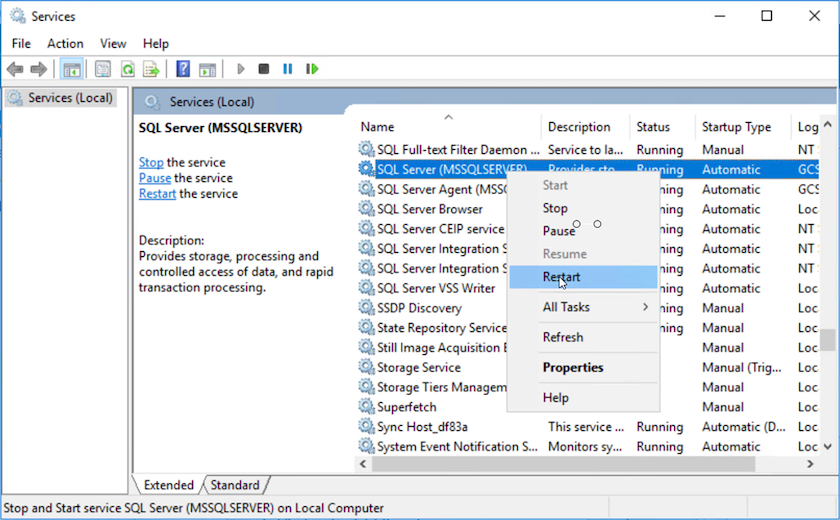
-
Asegúrese de que los recursos de SQL vuelvan a estar en línea.
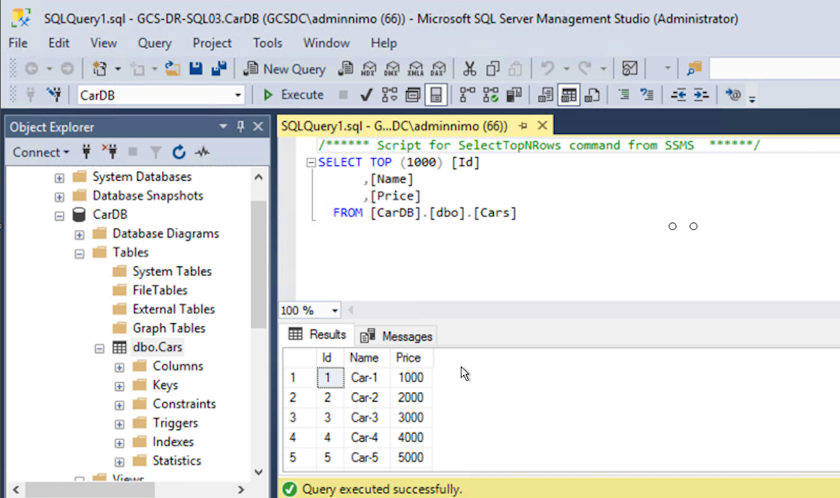
En el caso de NFS, adjunte los volúmenes usando el comando mount y actualice el /etc/fstabentradas.En este punto, las operaciones pueden ejecutarse y el negocio continúa normalmente.
En el extremo NSX-T, se puede crear una puerta de enlace de nivel 1 dedicada e independiente para simular escenarios de conmutación por error. Esto garantiza que todas las cargas de trabajo puedan comunicarse entre sí, pero que ningún tráfico pueda entrar o salir del entorno, de modo que cualquier tarea de clasificación, contención o refuerzo se pueda realizar sin riesgo de contaminación cruzada. Esta operación está fuera del alcance de este documento, pero se puede lograr fácilmente para simular el aislamiento.
Una vez que el sitio principal esté funcionando nuevamente, puedes realizar una conmutación por error. Jetstream reanuda la protección de la máquina virtual y se debe revertir la relación de SnapMirror .
-
Restaurar el entorno local. Dependiendo del tipo de incidente de desastre, podría ser necesario restaurar y/o verificar la configuración del clúster protegido. Si es necesario, es posible que sea necesario reinstalar el software JetStream DR.
-
Acceda al entorno local restaurado, vaya a la interfaz de usuario de Jetstream DR y seleccione el dominio protegido adecuado. Una vez que el sitio protegido esté listo para la conmutación por recuperación, seleccione la opción Conmutación por recuperación en la interfaz de usuario.
El plan de conmutación por error generado por CPT también se puede utilizar para iniciar el retorno de las máquinas virtuales y sus datos desde el almacén de objetos al entorno VMware original. 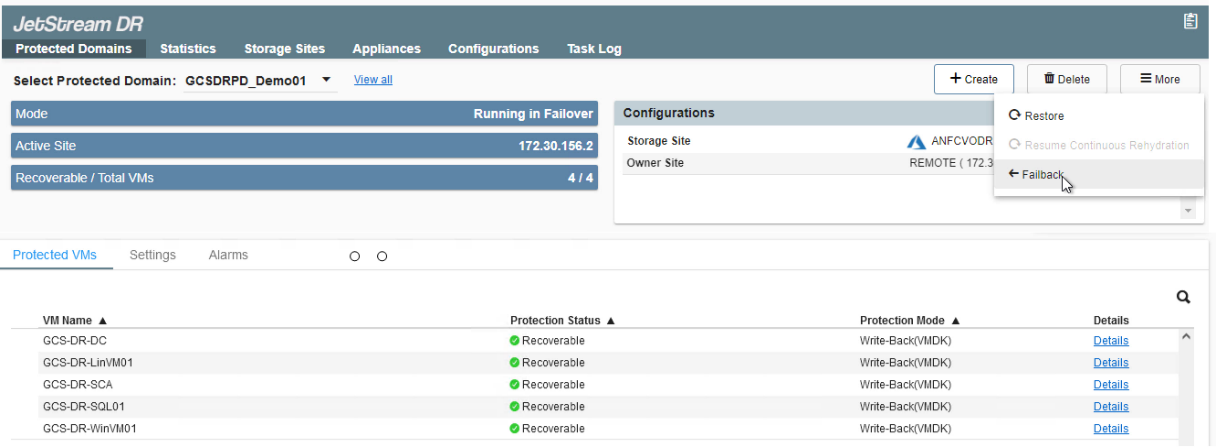
Especifique el retraso máximo después de pausar las máquinas virtuales en el sitio de recuperación y reiniciarlas en el sitio protegido. El tiempo necesario para completar este proceso incluye la finalización de la replicación después de detener las máquinas virtuales de conmutación por error, el tiempo necesario para limpiar el sitio de recuperación y el tiempo necesario para recrear las máquinas virtuales en el sitio protegido. NetApp recomienda 10 minutos. 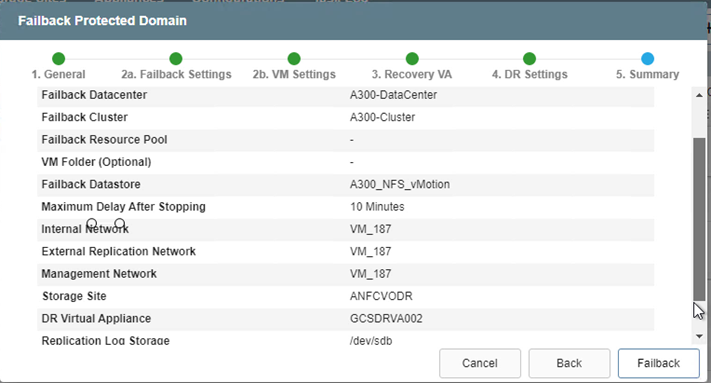
-
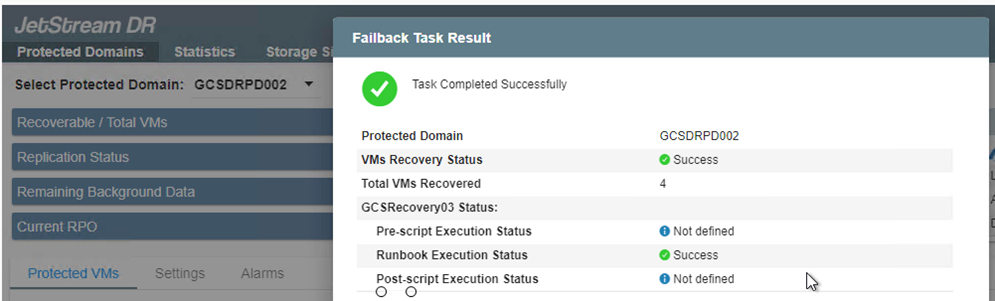
Complete el proceso de conmutación por error y luego confirme la reanudación de la protección de la máquina virtual y la consistencia de los datos.
-
Una vez recuperadas las máquinas virtuales, desconecte el almacenamiento secundario del host y conéctese al almacenamiento primario.
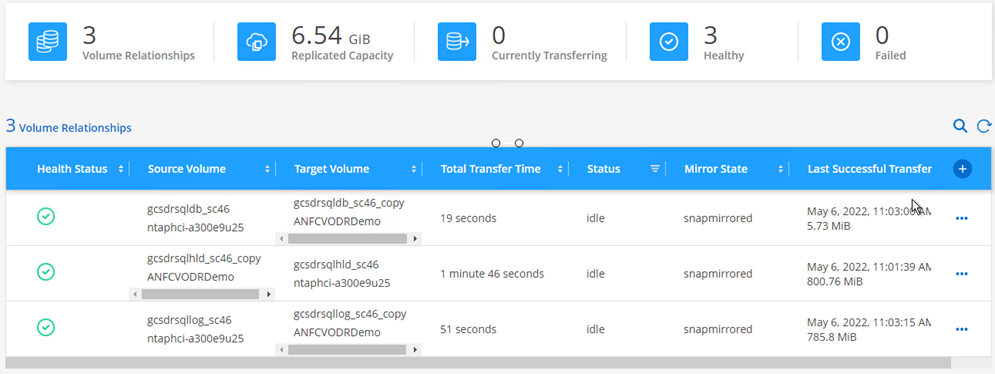
-
Reinicie el servicio del servidor MSSQL.
-
Verifique que los recursos SQL estén nuevamente en línea.
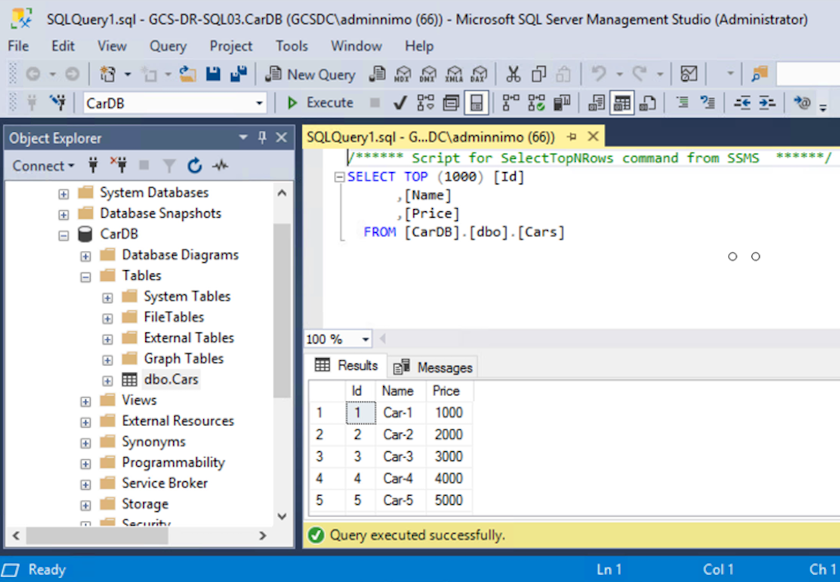
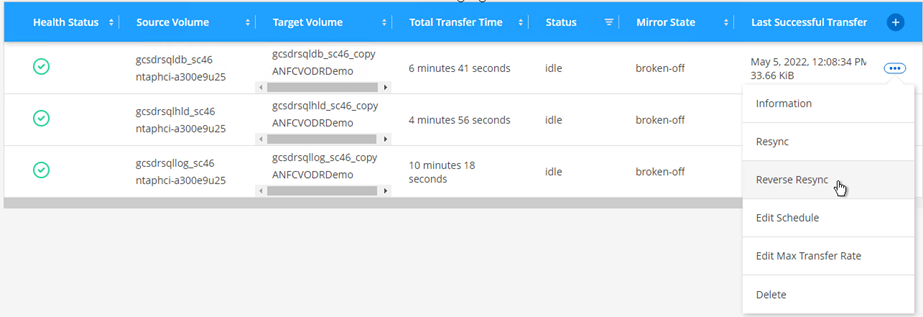
Para volver al almacenamiento principal, asegúrese de que la dirección de la relación siga siendo la misma que antes de la conmutación por error realizando una operación de resincronización inversa.
Para conservar las funciones de almacenamiento primario y secundario después de la operación de resincronización inversa, realice la operación de resincronización inversa nuevamente.
Este proceso es aplicable a otras aplicaciones como Oracle, bases de datos similares y cualquier otra aplicación que utilice almacenamiento conectado a invitados.
Como siempre, pruebe los pasos necesarios para recuperar las cargas de trabajo críticas antes de trasladarlas a producción.
Beneficios de esta solución
-
Utiliza la replicación eficiente y resistente de SnapMirror.
-
Se recupera a cualquier punto disponible en el tiempo con retención de instantáneas ONTAP .
-
La automatización completa está disponible para todos los pasos necesarios para recuperar cientos a miles de máquinas virtuales, desde los pasos de almacenamiento, computación, red y validación de aplicaciones.
-
SnapCenter utiliza mecanismos de clonación que no modifican el volumen replicado.
-
Esto evita el riesgo de corrupción de datos en volúmenes e instantáneas.
-
Evita interrupciones de replicación durante los flujos de trabajo de prueba de DR.
-
Aprovecha los datos de DR para flujos de trabajo más allá de DR, como desarrollo y prueba, pruebas de seguridad, pruebas de parches y actualizaciones, y pruebas de remediación.
-
-
La optimización de la CPU y la RAM puede ayudar a reducir los costos de la nube al permitir la recuperación a clústeres de cómputo más pequeños.