

Configurar la recuperación ante desastres para almacenes de datos VMFS mediante la BlueXP disaster recovery
 Sugerir cambios
Sugerir cambios
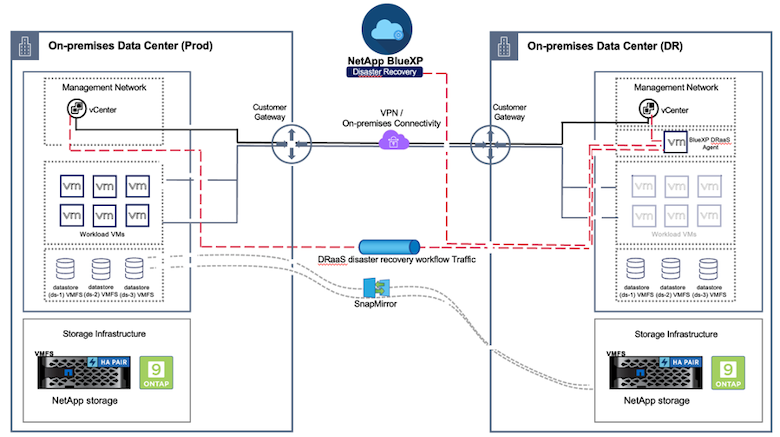
En este caso de uso, describimos el procedimiento para configurar la recuperación ante desastres mediante la BlueXP disaster recovery para máquinas virtuales VMware locales que utilizan almacenes de datos del sistema de archivos de máquina virtual VMware (VMFS). Este procedimiento incluye la configuración de la cuenta y el conector de BlueXP , el establecimiento de la replicación de SnapMirror entre sistemas ONTAP , la integración con VMware vCenter y la automatización de las operaciones de conmutación por error y recuperación.
La recuperación ante desastres mediante la replicación a nivel de bloque desde el sitio de producción al sitio de recuperación ante desastres es una forma resiliente y rentable de proteger las cargas de trabajo contra interrupciones del sitio y eventos de corrupción de datos, como ataques de ransomware. Con la replicación SnapMirror de NetApp , las cargas de trabajo de VMware que se ejecutan en sistemas ONTAP locales que utilizan un almacén de datos VMFS se pueden replicar en otro sistema de almacenamiento ONTAP en un centro de datos de recuperación designado donde reside VMware.
Introducción
Esta sección del documento describe la configuración de BlueXP DRaaS para configurar la recuperación ante desastres de las máquinas virtuales VMware locales en otro sitio designado. Como parte de esta configuración, la cuenta BlueXP , el conector BlueXP y las matrices ONTAP agregadas dentro del espacio de trabajo de BlueXP son necesarias para habilitar la comunicación desde VMware vCenter al almacenamiento ONTAP . Además, este documento detalla cómo configurar la replicación entre sitios y cómo configurar y probar un plan de recuperación. La última sección tiene instrucciones para realizar una conmutación por error completa del sitio y cómo realizar una conmutación por error cuando el sitio principal se recupera y se compra en línea.
Al utilizar el servicio de BlueXP disaster recovery , que está integrado en la consola BlueXP de NetApp , los clientes pueden descubrir sus VMware vCenters locales junto con el almacenamiento ONTAP , crear agrupaciones de recursos, crear un plan de recuperación ante desastres, asociarlo con grupos de recursos y probar o ejecutar conmutación por error y recuperación. SnapMirror proporciona replicación de bloques a nivel de almacenamiento para mantener los dos sitios actualizados con cambios incrementales, lo que da como resultado un RPO de hasta 5 minutos. También es posible simular procedimientos de DR como un simulacro regular sin afectar la producción ni los almacenes de datos replicados ni incurrir en costos de almacenamiento adicionales. La BlueXP disaster recovery aprovecha la tecnología FlexClone de ONTAP para crear una copia que ahorra espacio del almacén de datos VMFS a partir de la última instantánea replicada en el sitio de recuperación ante desastres. Una vez completada la prueba de DR, los clientes pueden simplemente eliminar el entorno de prueba, nuevamente sin ningún impacto en los recursos de producción replicados reales. Cuando existe una necesidad (planificada o no planificada) de una conmutación por error real, con unos pocos clics, el servicio de BlueXP disaster recovery orquestará todos los pasos necesarios para activar automáticamente las máquinas virtuales protegidas en el sitio de recuperación ante desastres designado. El servicio también revertirá la relación de SnapMirror con el sitio principal y replicará cualquier cambio del secundario al principal para una operación de conmutación por error, cuando sea necesario. Todo esto se puede lograr con una fracción del costo en comparación con otras alternativas conocidas.
Empezando
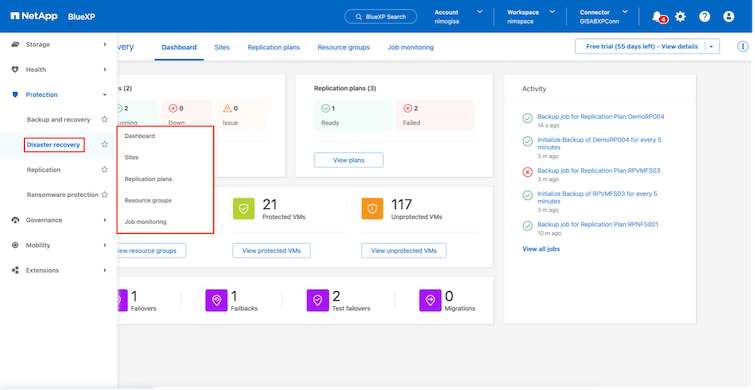
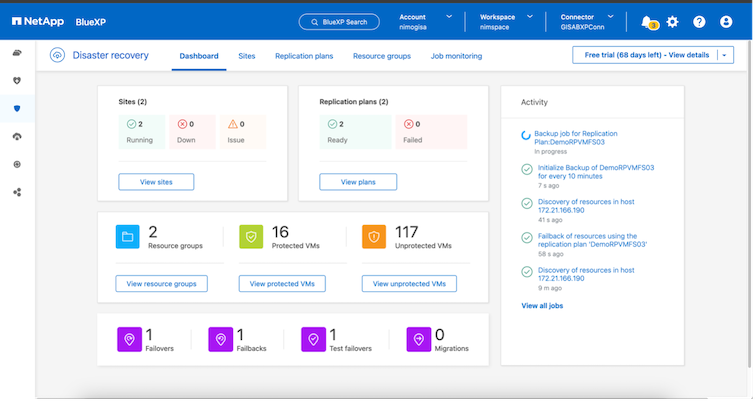
Para comenzar con la BlueXP disaster recovery, utilice la consola de BlueXP y luego acceda al servicio.
-
Inicie sesión en BlueXP.
-
Desde la navegación izquierda de BlueXP , seleccione Protección > Recuperación ante desastres.
-
Aparece el panel de BlueXP disaster recovery .
Antes de configurar el plan de recuperación ante desastres, asegúrese de que se cumplan los siguientes requisitos previos:
-
El conector BlueXP está configurado en NetApp BlueXP. El conector debe implementarse en AWS VPC.
-
La instancia del conector BlueXP tiene conectividad con el vCenter de origen y destino y con los sistemas de almacenamiento.
-
Los sistemas de almacenamiento NetApp locales que alojan almacenes de datos VMFS para VMware se agregan en BlueXP.
-
La resolución de DNS debe estar vigente cuando se utilizan nombres DNS. De lo contrario, utilice direcciones IP para vCenter.
-
La replicación de SnapMirror está configurada para los volúmenes de almacén de datos basados en VMFS designados.
Una vez establecida la conectividad entre los sitios de origen y destino, continúe con los pasos de configuración, que deberían tomar entre 3 y 5 minutos.

|
NetApp recomienda implementar el conector BlueXP en el sitio de recuperación ante desastres o en un tercer sitio, para que el conector BlueXP pueda comunicarse a través de la red con los recursos de origen y destino durante interrupciones reales o desastres naturales. |
|
|
La compatibilidad con almacenes de datos VMFS locales a locales se encuentra en versión preliminar tecnológica al momento de escribir este documento. Esta capacidad es compatible con almacenes de datos VMFS basados en protocolos FC e ISCSI. |
Configuración de BlueXP disaster recovery
El primer paso para prepararse para la recuperación ante desastres es descubrir y agregar los recursos de almacenamiento y vCenter locales a la BlueXP disaster recovery.
|
|
Asegúrese de que los sistemas de almacenamiento ONTAP se agreguen al entorno de trabajo dentro del lienzo. Abra la consola BlueXP y seleccione Protección > Recuperación ante desastres en la navegación izquierda. Seleccione Descubrir servidores vCenter o utilice el menú superior, seleccione Sitios > Agregar > Agregar vCenter. |
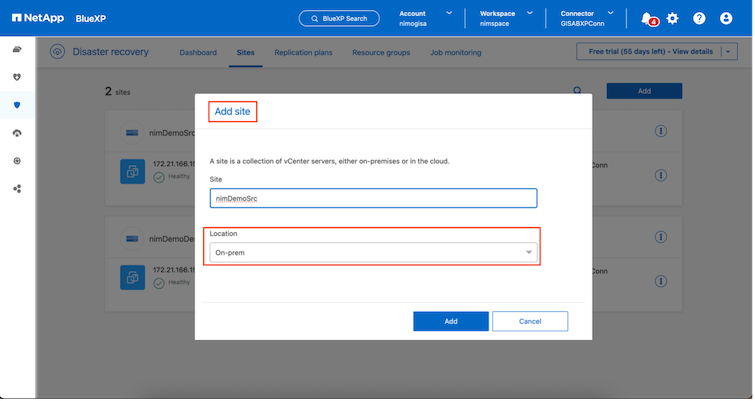
Agregue las siguientes plataformas:
-
Fuente. vCenter local.
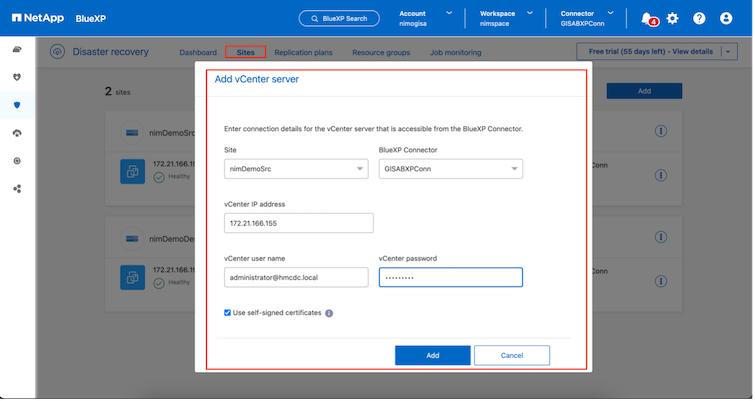
-
Destino. Centro de datos SDDC de VMC.
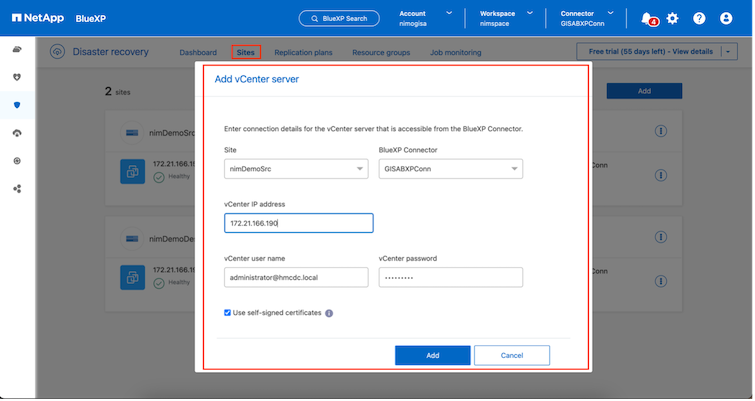
Una vez que se agregan los vCenters, se activa el descubrimiento automático.
Configuración de la replicación de almacenamiento entre el sitio de origen y el de destino
SnapMirror utiliza instantáneas de ONTAP para administrar la transferencia de datos de una ubicación a otra. Inicialmente, se copia una copia completa basada en una instantánea del volumen de origen al destino para realizar una sincronización de línea base. A medida que se producen cambios en los datos en la fuente, se crea una nueva instantánea y se compara con la instantánea de referencia. Luego, los bloques que se han modificado se replican en el destino, y la instantánea más nueva se convierte en la línea de base actual, o la instantánea común más nueva. Esto permite que el proceso se repita y que se envíen actualizaciones incrementales al destino.
Cuando se establece una relación SnapMirror , el volumen de destino está en un estado de solo lectura en línea y, por lo tanto, aún es accesible. SnapMirror trabaja con bloques físicos de almacenamiento, en lugar de a nivel de archivos u otro nivel lógico. Esto significa que el volumen de destino es una réplica idéntica del de origen, incluidas instantáneas, configuraciones de volumen, etc. Si el volumen de origen utiliza funciones de eficiencia de espacio de ONTAP , como compresión de datos y deduplicación de datos, el volumen replicado conservará estas optimizaciones.
Al romper la relación de SnapMirror , el volumen de destino se puede escribir y normalmente se utiliza para realizar una conmutación por error cuando se utiliza SnapMirror para sincronizar datos con un entorno de recuperación ante desastres. SnapMirror es lo suficientemente sofisticado para permitir que los datos modificados en el sitio de conmutación por error se resincronicen de manera eficiente con el sistema principal, en caso de que más tarde vuelva a estar en línea, y luego permitir que se restablezca la relación original de SnapMirror .
Cómo configurarlo para VMware Disaster Recovery
El proceso para crear la replicación de SnapMirror sigue siendo el mismo para cualquier aplicación. El proceso puede ser manual o automatizado. La forma más sencilla es aprovechar BlueXP para configurar la replicación de SnapMirror mediante el simple arrastrar y soltar del sistema ONTAP de origen en el entorno al destino para activar el asistente que lo guía a través del resto del proceso.
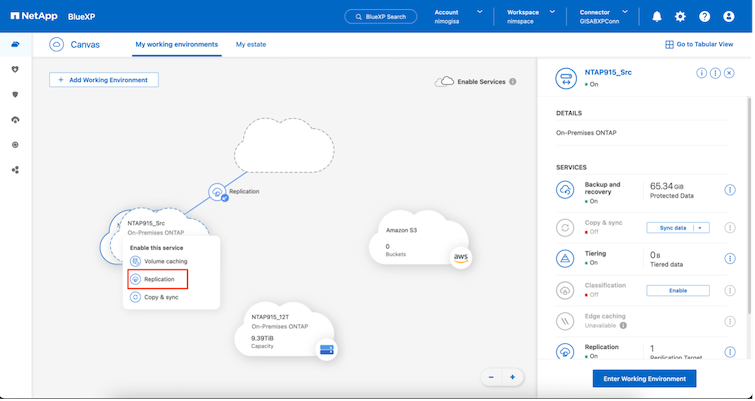
BlueXP DRaaS también puede automatizar lo mismo siempre que se cumplan los dos criterios siguientes:
-
Los clústeres de origen y destino tienen una relación de pares.
-
El SVM de origen y el SVM de destino tienen una relación de pares.
|
|
Si la relación SnapMirror ya está configurada para el volumen a través de CLI, BlueXP DRaaS retoma la relación y continúa con el resto de las operaciones del flujo de trabajo. |
|
|
Además de los enfoques anteriores, la replicación de SnapMirror también se puede crear a través de ONTAP CLI o el Administrador del sistema. Independientemente del enfoque utilizado para sincronizar los datos mediante SnapMirror, BlueXP DRaaS organiza el flujo de trabajo para lograr operaciones de recuperación ante desastres fluidas y eficientes. |
¿Qué puede hacer por usted la BlueXP disaster recovery ?
Una vez agregados los sitios de origen y destino, la BlueXP disaster recovery realiza un descubrimiento profundo automático y muestra las máquinas virtuales junto con los metadatos asociados. La BlueXP disaster recovery también detecta automáticamente las redes y los grupos de puertos utilizados por las máquinas virtuales y los completa.
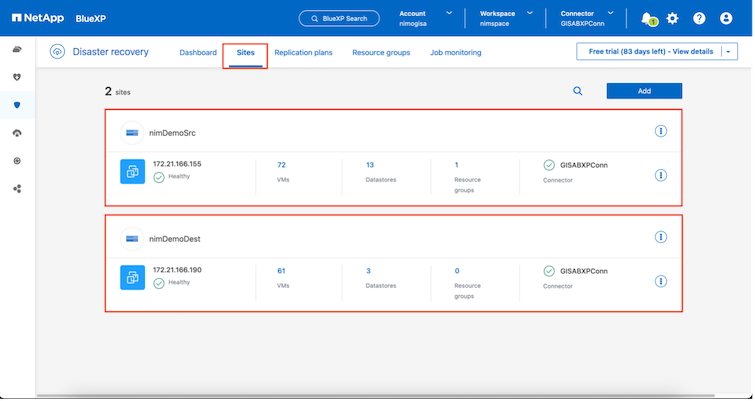
Una vez agregados los sitios, las máquinas virtuales se pueden agrupar en grupos de recursos. Los grupos de recursos de BlueXP disaster recovery le permiten agrupar un conjunto de máquinas virtuales dependientes en grupos lógicos que contienen sus órdenes de arranque y los retrasos de arranque que se pueden ejecutar durante la recuperación. Para comenzar a crear grupos de recursos, navegue a Grupos de recursos y haga clic en Crear nuevo grupo de recursos.
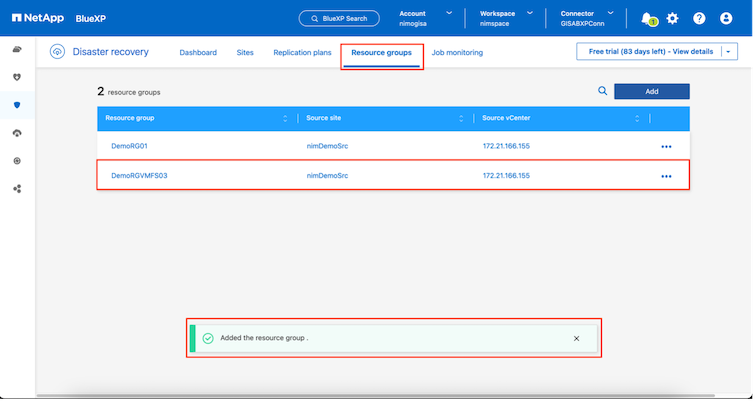
|
|
El grupo de recursos también se puede crear mientras se crea un plan de replicación. |
El orden de arranque de las máquinas virtuales se puede definir o modificar durante la creación de grupos de recursos mediante un simple mecanismo de arrastrar y soltar.
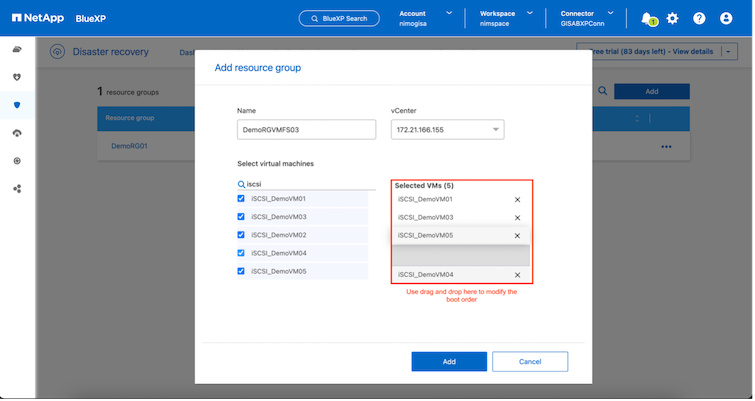
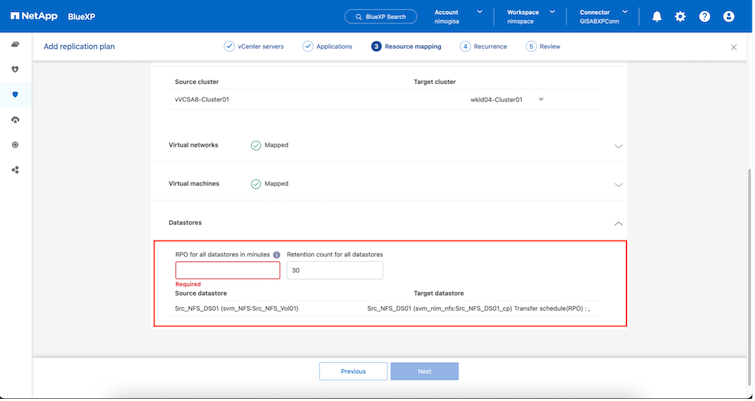
Una vez creados los grupos de recursos, el siguiente paso es crear el plan de ejecución o un plan para recuperar máquinas virtuales y aplicaciones en caso de desastre. Como se menciona en los requisitos previos, la replicación de SnapMirror se puede configurar de antemano o DRaaS puede configurarla utilizando el RPO y el recuento de retención especificados durante la creación del plan de replicación.
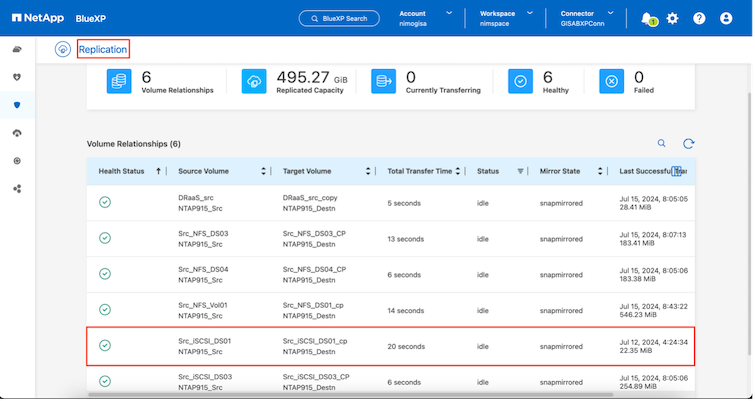
Configure el plan de replicación seleccionando las plataformas vCenter de origen y destino en el menú desplegable y elija los grupos de recursos que se incluirán en el plan, junto con la agrupación de cómo se deben restaurar y encender las aplicaciones y el mapeo de clústeres y redes. Para definir el plan de recuperación, navegue a la pestaña Plan de replicación y haga clic en Agregar plan.
Primero, seleccione el vCenter de origen y luego seleccione el vCenter de destino.
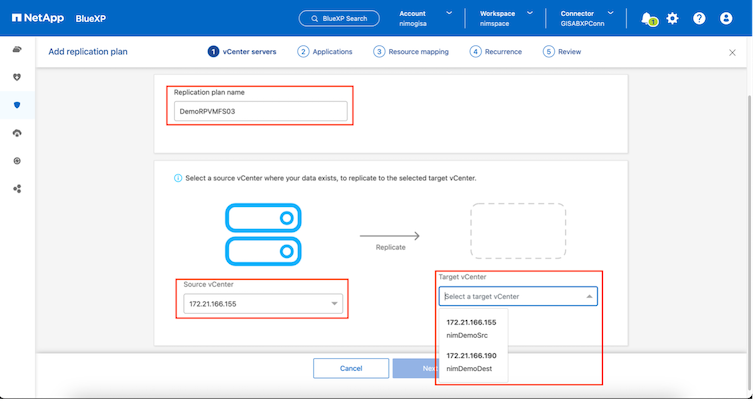
El siguiente paso es seleccionar los grupos de recursos existentes. Si no se crean grupos de recursos, el asistente ayuda a agrupar las máquinas virtuales necesarias (básicamente, crea grupos de recursos funcionales) en función de los objetivos de recuperación. Esto también ayuda a definir la secuencia de operaciones de cómo se deben restaurar las máquinas virtuales de la aplicación.
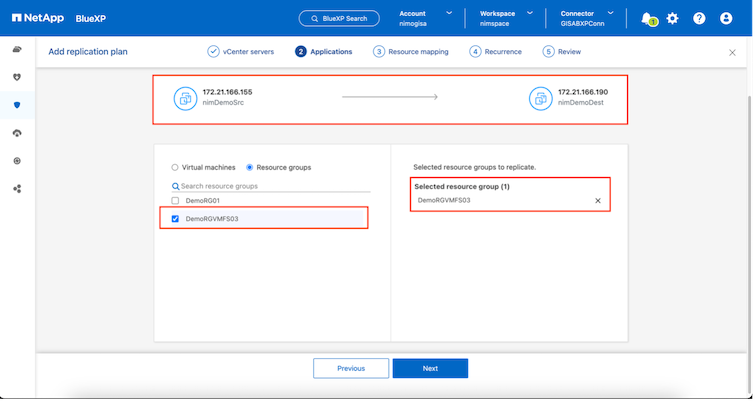
|
|
El grupo de recursos permite establecer el orden de arranque mediante la funcionalidad de arrastrar y soltar. Se puede utilizar para modificar fácilmente el orden en que se encenderán las máquinas virtuales durante el proceso de recuperación. |
|
|
Cada máquina virtual dentro de un grupo de recursos se inicia en secuencia según el orden. Se inician dos grupos de recursos en paralelo. |
La siguiente captura de pantalla muestra la opción para filtrar máquinas virtuales o almacenes de datos específicos según los requisitos organizativos si no se crean grupos de recursos de antemano.
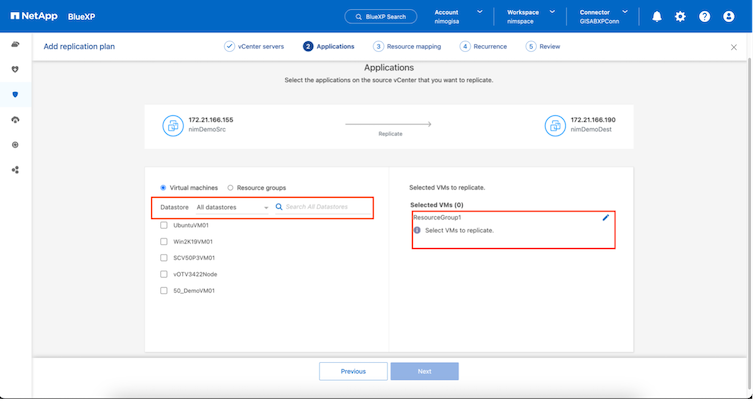
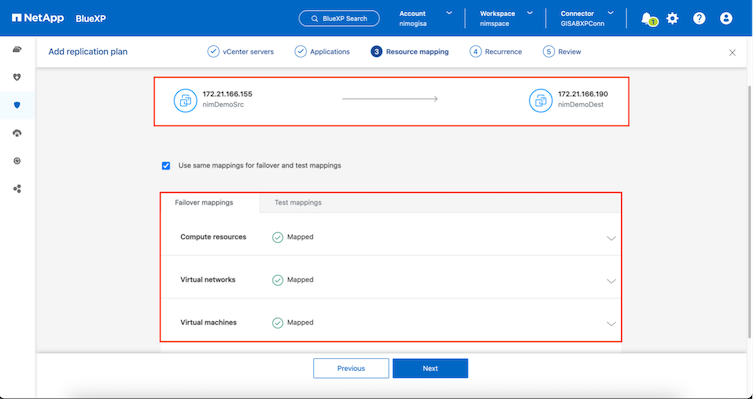
Una vez seleccionados los grupos de recursos, cree las asignaciones de conmutación por error. En este paso, especifique cómo se asignan los recursos del entorno de origen al destino. Esto incluye recursos computacionales y redes virtuales. Personalización de IP, scripts previos y posteriores, retrasos en el arranque, consistencia de la aplicación, etc. Para obtener información detallada, consulte"Crear un plan de replicación" .
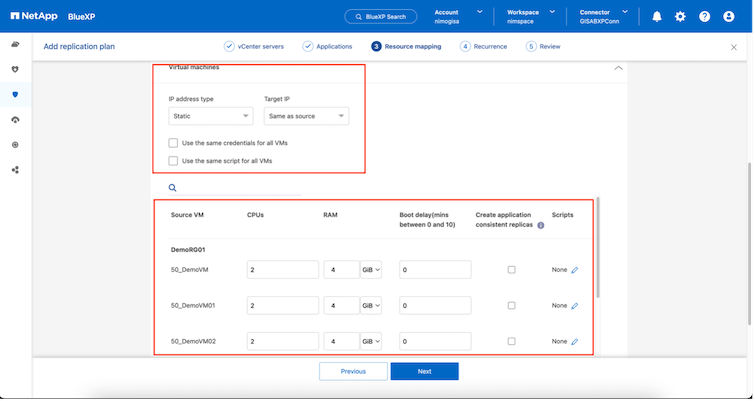
|
|
De forma predeterminada, se utilizan los mismos parámetros de mapeo para las operaciones de prueba y de conmutación por error. Para aplicar diferentes asignaciones para el entorno de prueba, seleccione la opción Asignación de prueba después de desmarcar la casilla de verificación como se muestra a continuación: |
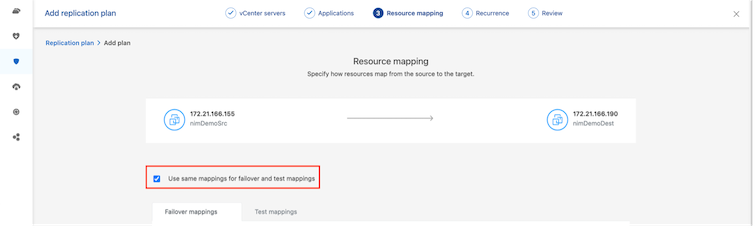
Una vez completado el mapeo de recursos, haga clic en Siguiente.
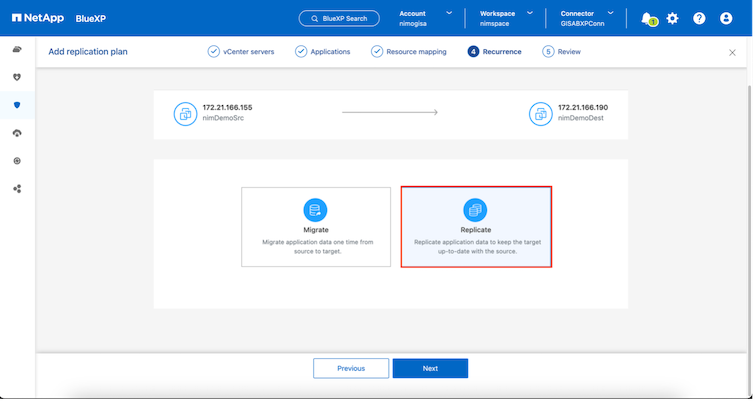
Seleccione el tipo de recurrencia. En palabras simples, seleccione la opción Migrar (migración única mediante conmutación por error) o replicación continua recurrente. En este tutorial, se selecciona la opción Replicar.
Una vez hecho esto, revise los mapeos creados y luego haga clic en Agregar plan.
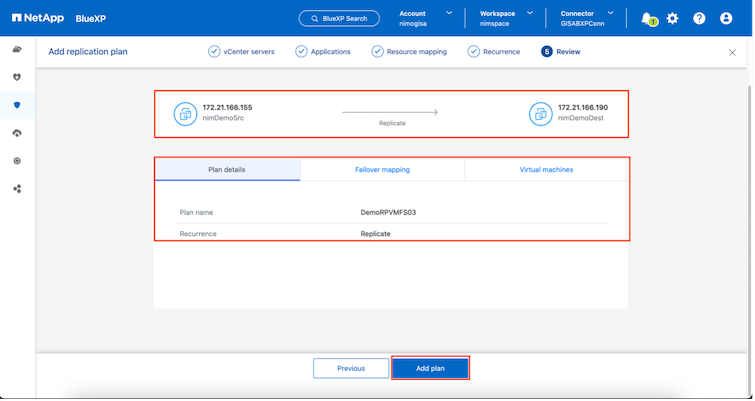
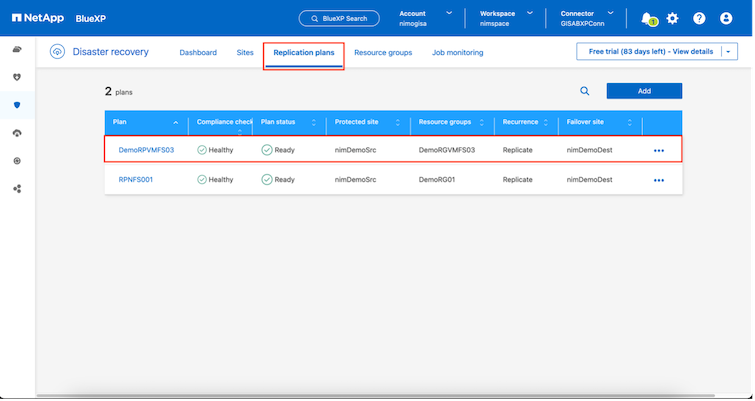
Una vez creado el plan de replicación, se puede realizar una conmutación por error según los requisitos seleccionando la opción de conmutación por error, la opción de conmutación por error de prueba o la opción de migración. La BlueXP disaster recovery garantiza que el proceso de replicación se ejecute según el plan cada 30 minutos. Durante las opciones de conmutación por error y conmutación por error de prueba, puede utilizar la copia de instantánea de SnapMirror más reciente o puede seleccionar una copia de instantánea específica de una copia de instantánea de un momento determinado (según la política de retención de SnapMirror). La opción de punto en el tiempo puede ser muy útil si hay un evento de corrupción como ransomware, donde las réplicas más recientes ya están comprometidas o cifradas. La BlueXP disaster recovery muestra todos los puntos de recuperación disponibles.
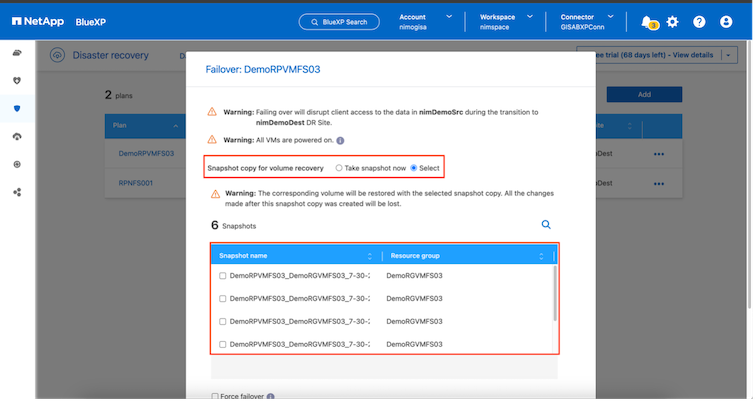
Para activar o probar la conmutación por error con la configuración especificada en el plan de replicación, haga clic en Conmutación por error o Probar conmutación por error.
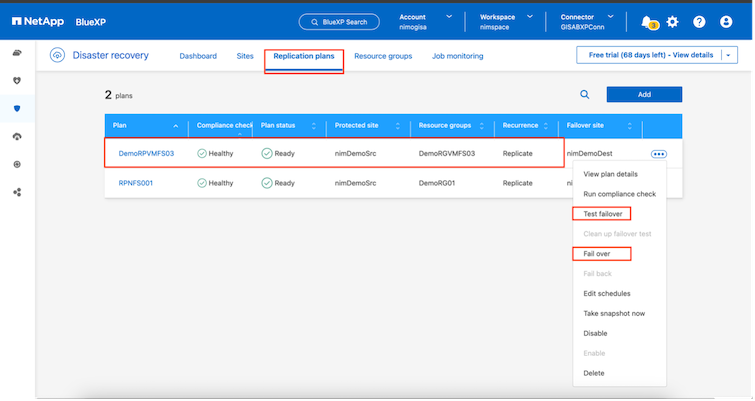
¿Qué sucede durante una operación de conmutación por error o de prueba?
Durante una operación de conmutación por error de prueba, la BlueXP disaster recovery crea un volumen FlexClone en el sistema de almacenamiento ONTAP de destino utilizando la última copia de instantánea o una instantánea seleccionada del volumen de destino.
|
|
Una operación de conmutación por error de prueba crea un volumen clonado en el sistema de almacenamiento ONTAP de destino. |
|
|
Ejecutar una operación de recuperación de prueba no afecta la replicación de SnapMirror . |
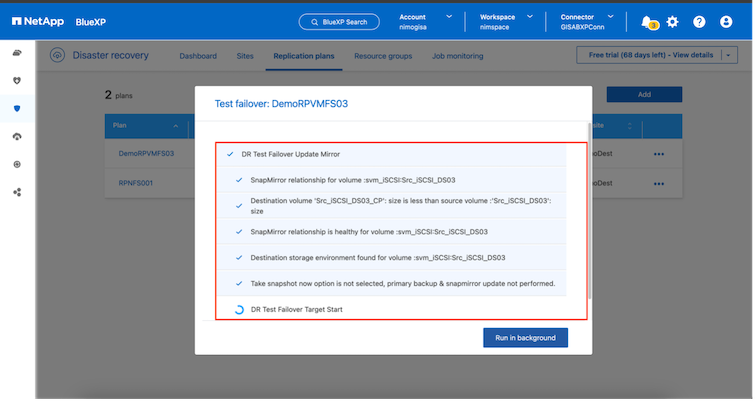
Durante el proceso, la BlueXP disaster recovery no asigna el volumen de destino original. En lugar de ello, crea un nuevo volumen FlexClone a partir de la instantánea seleccionada y un almacén de datos temporal que respalda el volumen FlexClone se asigna a los hosts ESXi.
Cuando se completa la operación de conmutación por error de prueba, se puede activar la operación de limpieza utilizando "Limpiar prueba de conmutación por error". Durante esta operación, la BlueXP disaster recovery destruye el volumen FlexClone que se utilizó en la operación.
En caso de que ocurra un desastre real, la BlueXP disaster recovery realiza los siguientes pasos:
-
Rompe la relación SnapMirror entre los sitios.
-
Monta el volumen del almacén de datos VMFS después de la renovación para su uso inmediato.
-
Registrar las máquinas virtuales
-
Encender las máquinas virtuales
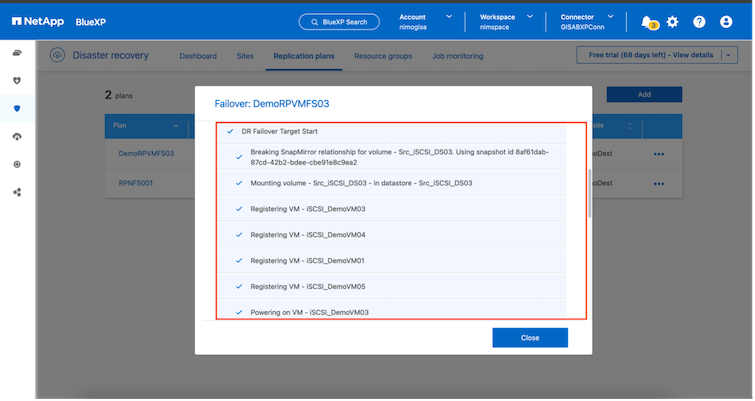
Una vez que el sitio principal está en funcionamiento, la BlueXP disaster recovery permite la resincronización inversa para SnapMirror y habilita la conmutación por recuperación, que nuevamente se puede realizar con el clic de un botón.
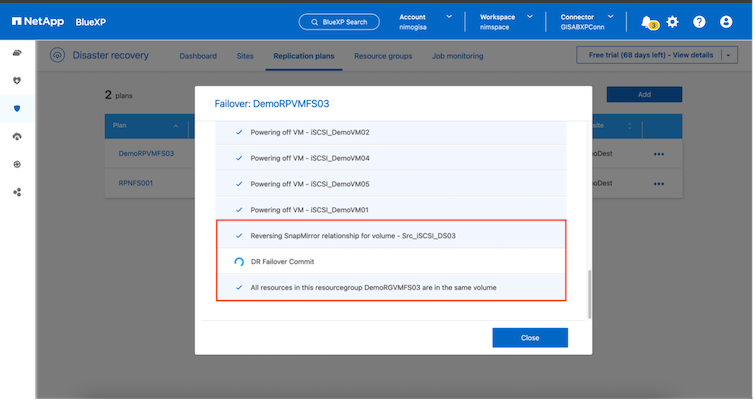
Y si se elige la opción de migrar, se considera como un evento de conmutación por error planificado. En este caso, se activa un paso adicional que consiste en apagar las máquinas virtuales en el sitio de origen. El resto de los pasos siguen siendo los mismos que en el evento de conmutación por error.
Desde BlueXP o la CLI de ONTAP , puede supervisar el estado de salud de la replicación para los volúmenes de almacén de datos adecuados, y el estado de una conmutación por error o de una conmutación por error de prueba se puede rastrear a través de la Supervisión de trabajos.
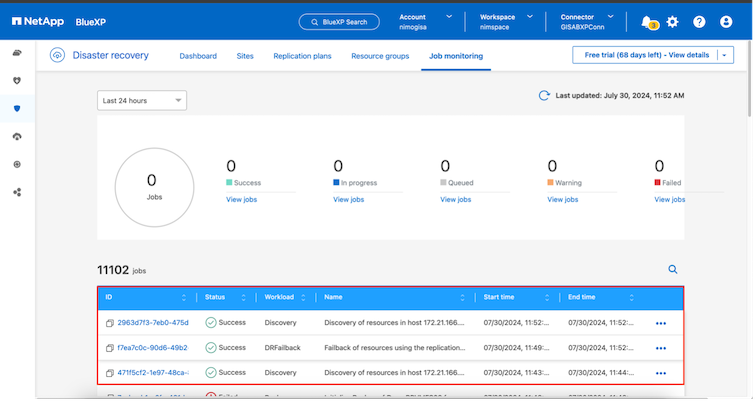
Esto proporciona una solución poderosa para gestionar un plan de recuperación ante desastres personalizado y adaptado. La conmutación por error se puede realizar de forma planificada o con solo hacer clic en un botón cuando ocurre un desastre y se toma la decisión de activar el sitio de recuperación ante desastres.
Para obtener más información sobre este proceso, no dude en seguir el video tutorial detallado o utilizar el"simulador de soluciones" .