

Solucionar problemas de metadatos
 Sugerir cambios
Sugerir cambios
Puede realizar varias tareas para determinar el origen de los problemas de metadatos.
Solucione los problemas de la alerta de almacenamiento de metadatos bajos
Si se activa la alerta almacenamiento de metadatos bajo, debe agregar nuevos nodos de almacenamiento.
-
Debe iniciar sesión en Grid Manager mediante un navegador web compatible.
StorageGRID reserva una cierta cantidad de espacio en el volumen 0 de cada nodo de almacenamiento para los metadatos del objeto. Este espacio se conoce como el espacio reservado real y se subdivide en el espacio permitido para los metadatos del objeto (el espacio de metadatos permitido) y el espacio necesario para las operaciones esenciales de la base de datos, como la compactación y la reparación. El espacio de metadatos permitido rige la capacidad general del objeto.
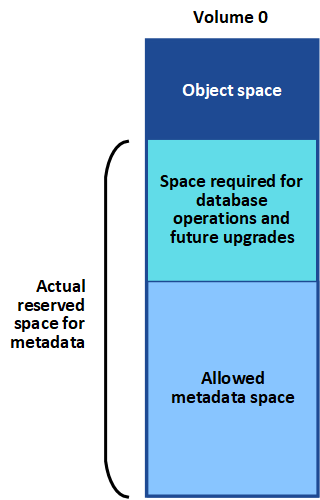
Si los metadatos de los objetos consumen más del 100% del espacio permitido para los metadatos, las operaciones de base de datos no se pueden ejecutar de forma eficiente y se producirán errores.
Puede hacerlo Supervise la capacidad de metadatos de los objetos para cada nodo de almacenamiento para ayudarle a anticiparse a los errores y corregirlos antes de que ocurran.
StorageGRID utiliza la siguiente métrica Prometheus para medir lo completo que está el espacio de metadatos permitido:
storagegrid_storage_utilization_metadata_bytes/storagegrid_storage_utilization_metadata_allowed_bytes
Cuando esta expresión Prometheus alcanza ciertos umbrales, se activa la alerta almacenamiento de metadatos bajo.
-
Menor: Los metadatos de objetos utilizan un 70% o más del espacio de metadatos permitido. Debe añadir nuevos nodos de almacenamiento Lo antes posible..
-
Major: Los metadatos de objetos utilizan un 90% o más del espacio de metadatos permitido. Debe añadir nodos de almacenamiento nuevos inmediatamente.

Cuando los metadatos de objetos utilizan un 90 % o más del espacio de metadatos permitido, se muestra una advertencia en la consola. Si se muestra esta advertencia, debe añadir nodos de almacenamiento nuevos inmediatamente. Nunca debe permitir que los metadatos de objetos utilicen más de un 100 % del espacio permitido. -
Crítico: Los metadatos de objetos utilizan un 100% o más del espacio de metadatos permitido y están empezando a consumir el espacio necesario para las operaciones esenciales de la base de datos. Debe detener la ingesta de objetos nuevos y, inmediatamente, añadir nodos de almacenamiento nuevos.
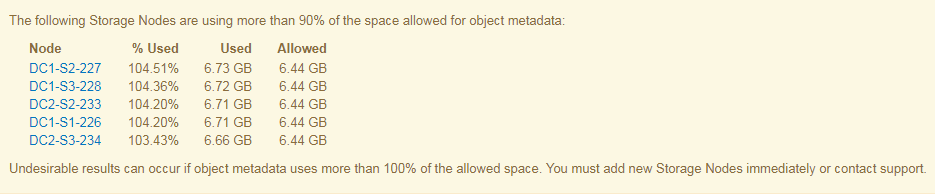
En el ejemplo siguiente, los metadatos de objetos usan más del 100% del espacio de metadatos permitido. Ésta es una situación crítica, que dará como resultado errores y operaciones de la base de datos ineficientes.
|
|
Si el tamaño del volumen 0 es menor que la opción de almacenamiento de espacio reservado de metadatos (por ejemplo, en un entorno que no es de producción), el cálculo de la alerta almacenamiento de metadatos bajo podría ser inexacto. |
-
Seleccione ALERTS > Current.
-
En la tabla de alertas, expanda el grupo de alertas almacenamiento de metadatos bajo, si es necesario, y seleccione la alerta específica que desea ver.
-
Revise los detalles en el cuadro de diálogo de alertas.
-
Si se ha activado una alerta de almacenamiento de metadatos bajo importante o crítica, realice una ampliación para añadir nodos de almacenamiento inmediatamente.

Dado que StorageGRID mantiene copias completas de todos los metadatos de objetos en cada sitio, la capacidad de metadatos del grid completo está limitada por la capacidad de metadatos del sitio más pequeño. Si necesita agregar capacidad de metadatos a un sitio, también debe hacerlo expanda cualquier otro sitio Con la misma cantidad de nodos de almacenamiento. Después de realizar la ampliación, StorageGRID redistribuye los metadatos de objetos existentes a los nodos nuevos, lo que aumenta la capacidad de metadatos general del grid. No se requiere ninguna acción del usuario. Se borra la alerta almacenamiento de metadatos bajo.
Solucione los problemas de la alarma Servicios: Estado - Cassandra (SVST)
La alarma Servicios: Status - Cassandra (SVST) indica que es posible que deba reconstruir la base de datos de Cassandra para un nodo de almacenamiento. Cassandra se usa como almacén de metadatos para StorageGRID.
-
Debe iniciar sesión en Grid Manager mediante un navegador web compatible.
-
Debe tener permisos de acceso específicos.
-
Debe tener la
Passwords.txtarchivo.
Si Cassandra se detiene durante más de 15 días (por ejemplo, el nodo de almacenamiento está apagado), Cassandra no se iniciará cuando el nodo se vuelva a conectar. Debe reconstruir la base de datos de Cassandra para el servicio DDS afectado.
Puede hacerlo ejecutar diagnóstico para obtener información adicional sobre el estado actual de la cuadrícula.
|
|
Si dos o más de los servicios de base de datos de Cassandra están inactivos durante más de 15 días, póngase en contacto con el soporte técnico y no continúe con los pasos a continuación. |
-
Seleccione SUPPORT > Tools > Topología de cuadrícula.
-
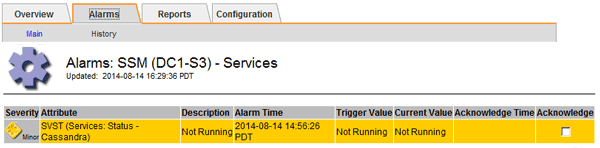
Seleccione Site > Storage Node > SSM > Servicios > Alarmas > Principal para mostrar alarmas.
Este ejemplo muestra que se ha activado la alarma SVST.
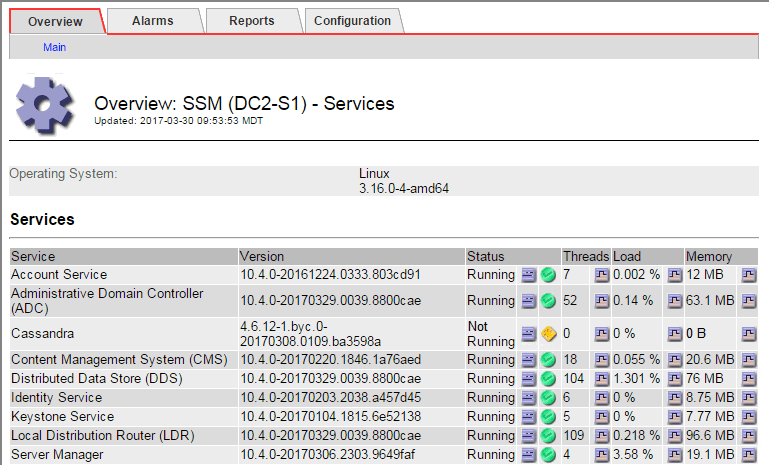
La página principal de los servicios de SSM también indica que Cassandra no se está ejecutando.
-
intente reiniciar Cassandra desde el nodo de almacenamiento:
-
Inicie sesión en el nodo de grid:
-
Introduzca el siguiente comando:
ssh admin@grid_node_IP -
Introduzca la contraseña que aparece en
Passwords.txtarchivo. -
Introduzca el siguiente comando para cambiar a la raíz:
su - -
Introduzca la contraseña que aparece en
Passwords.txtarchivo. Cuando ha iniciado sesión como root, el símbolo del sistema cambia de$para#.
-
-
Introduzca:
/etc/init.d/cassandra status -
Si Cassandra no se está ejecutando, reinicie:
/etc/init.d/cassandra restart
-
-
Si Cassandra no se reinicia, determine cuánto tiempo ha estado inactivo Cassandra. Si Cassandra ha estado inactiva durante más de 15 días, debe reconstruir la base de datos de Cassandra.
Si dos o más de los servicios de base de datos de Cassandra están inactivos, póngase en contacto con el soporte técnico y no continúe con los pasos que se indican a continuación. Puede determinar cuánto tiempo ha estado inactivo Cassandra trazando una entrada de datos o revisando el archivo servermanager.log.
-
Para crear un gráfico en Cassandra:
-
Seleccione SUPPORT > Tools > Topología de cuadrícula. A continuación, seleccione Site > Storage Node > SSM > Servicios > Informes > Cartas.
-
Seleccione atributo > Servicio: Estado - Cassandra.
-
Para Fecha de inicio, introduzca una fecha que tenga al menos 16 días antes de la fecha actual. Para Fecha de finalización, introduzca la fecha actual.
-
Haga clic en Actualizar.
-
Si el gráfico muestra que Cassandra está inactiva durante más de 15 días, vuelva a generar la base de datos de Cassandra.
-
El siguiente ejemplo de gráfico muestra que Cassandra ha estado inactiva durante al menos 17 días.
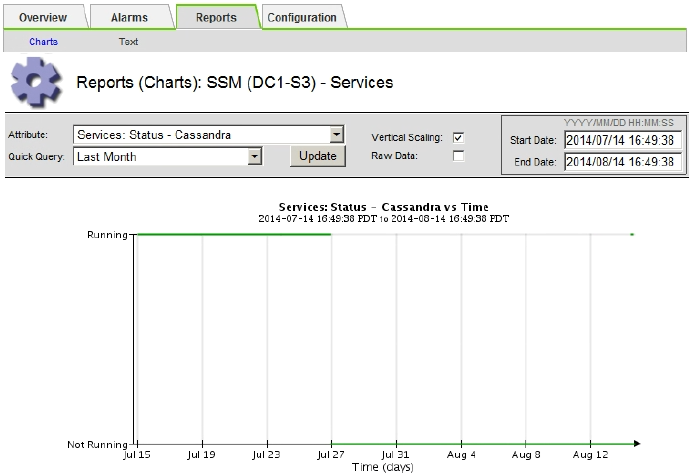
-
Para revisar el archivo servermanager.log en el nodo de almacenamiento:
-
Inicie sesión en el nodo de grid:
-
Introduzca el siguiente comando:
ssh admin@grid_node_IP -
Introduzca la contraseña que aparece en
Passwords.txtarchivo. -
Introduzca el siguiente comando para cambiar a la raíz:
su - -
Introduzca la contraseña que aparece en
Passwords.txtarchivo. Cuando ha iniciado sesión como root, el símbolo del sistema cambia de$para#.
-
-
Introduzca:
cat /var/local/log/servermanager.logSe muestra el contenido del archivo servermanager.log.
Si Cassandra ha estado inactiva durante más de 15 días, se muestra el siguiente mensaje en el archivo servermanager.log:
"2014-08-14 21:01:35 +0000 | cassandra | cassandra not started because it has been offline for longer than its 15 day grace period - rebuild cassandra
-
Asegúrese de que la Marca de hora de este mensaje sea la hora a la que intentó reiniciar Cassandra como se indica en el paso Reinicie Cassandra desde el nodo de almacenamiento.
Puede haber más de una entrada para Cassandra; debe encontrar la entrada más reciente.
-
Si Cassandra ha estado inactiva durante más de 15 días, debe reconstruir la base de datos de Cassandra.
Para ver instrucciones, consulte Recupere el nodo de almacenamiento en más de 15 días.
-
Póngase en contacto con el soporte técnico si las alarmas no se borran después de reconstruir Cassandra.
-
Solucionar errores de Cassandra fuera de memoria (alarma SMTT)
Se activa una alarma total Events (SMTT) cuando la base de datos de Cassandra tiene un error de falta de memoria. Si se produce este error, póngase en contacto con el soporte técnico para solucionar el problema.
Si se produce un error de falta de memoria en la base de datos de Cassandra, se crea un volcado de pila, se activa una alarma Eventos totales (SMTT) y el recuento de errores de memoria de Cassandra se incrementa en uno.
-
Para ver el evento, seleccione SUPPORT > Tools > Topología de cuadrícula > Configuración.
-
Compruebe que el número de errores de memoria de salida de Cassandra sea 1 o superior.
Puede hacerlo ejecutar diagnóstico para obtener información adicional sobre el estado actual de la cuadrícula.
-
Vaya a.
/var/local/core/, comprima elCassandra.hprofy envíelo al soporte técnico. -
Haga una copia de seguridad del
Cassandra.hprofy elimínelo del/var/local/core/ directory.Este archivo puede tener un tamaño de hasta 24 GB, por lo que debe eliminarlo para liberar espacio.
-
Una vez resuelto el problema, active la casilla de verificación Restablecer para el recuento de errores de memoria de Cassandra. A continuación, seleccione aplicar cambios.
Para restablecer los recuentos de eventos, debe tener el permiso Configuración de página de topología de cuadrícula.