Cómo StorageGRID gestiona los datos
 Sugerir cambios
Sugerir cambios
Cuando comience a trabajar con el sistema StorageGRID, es útil entender cómo gestiona los datos el sistema StorageGRID.
Qué es un objeto
Con el almacenamiento de objetos, la unidad de almacenamiento es un objeto, en lugar de un archivo o un bloque. A diferencia de la jerarquía de árbol de un sistema de archivos o almacenamiento basado en bloques, el almacenamiento de objetos organiza los datos en un diseño plano y sin estructura. El almacenamiento de objetos separa la ubicación física de los datos del método utilizado para almacenar y recuperar esos datos.
Cada objeto de un sistema de almacenamiento basado en objetos tiene dos partes: Datos de objetos y metadatos de objetos.
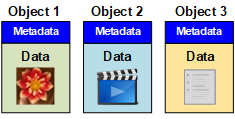
Datos de objetos
Los datos del objeto pueden ser cualquier cosa; por ejemplo, una fotografía, una película o un registro médico.
Metadatos de objetos
Los metadatos de objetos son cualquier información que describa un objeto. StorageGRID utiliza metadatos de objetos para realizar un seguimiento de las ubicaciones de todos los objetos en el grid y gestionar el ciclo de vida de cada objeto a lo largo del tiempo.
Los metadatos de objetos incluyen información como la siguiente:
-
Metadatos del sistema, incluidos un ID único para cada objeto (UUID), el nombre del objeto, el nombre del bloque de S3 o el contenedor Swift, el nombre o el ID de la cuenta de inquilino, el tamaño lógico del objeto, la fecha y la hora en que se creó el objeto por primera vez, y la fecha y hora en que se modificó por última vez el objeto.
-
La ubicación actual de almacenamiento de cada copia de objeto o fragmento con código de borrado.
-
Todos los metadatos de usuario asociados con el objeto.
Los metadatos de objetos son personalizables y ampliables, por lo que es flexible para las aplicaciones.
Para obtener información detallada sobre cómo y dónde almacena StorageGRID metadatos de objetos, vaya a. Gestione el almacenamiento de metadatos de objetos.
Cómo se protegen los datos de objetos
El sistema StorageGRID ofrece dos mecanismos para proteger los datos de objetos contra la pérdida: La replicación y la codificación de borrado.
Replicación
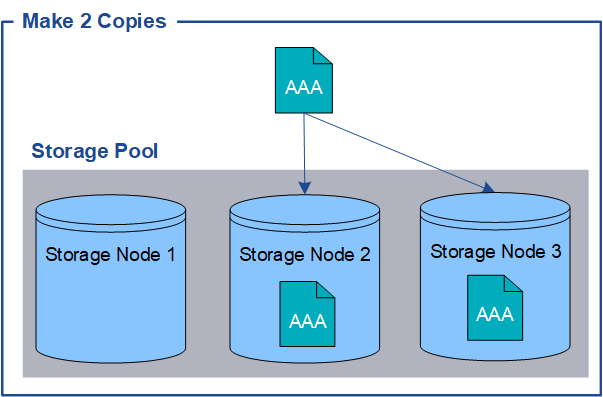
Cuando StorageGRID enlaza objetos con una regla de gestión del ciclo de vida de la información (ILM) que se configura para crear copias replicadas, el sistema crea copias exactas de datos de objetos y los almacena en nodos de almacenamiento, nodos de archivado o pools de almacenamiento en el cloud. Las reglas de ILM determinan el número de copias realizadas, dónde se almacenan esas copias y durante el tiempo que el sistema retiene. Si se pierde una copia, por ejemplo, como resultado de la pérdida de un nodo de almacenamiento, el objeto sigue disponible si existe una copia en otro lugar del sistema StorageGRID.
En el ejemplo siguiente, la regla make 2 copies especifica que se coloquen dos copias replicadas de cada objeto en un pool de almacenamiento que contenga tres nodos de almacenamiento.
Codificación de borrado
Cuando StorageGRID enlaza objetos con una regla de ILM que se configura para crear copias con código de borrado, corta los datos de objetos en fragmentos de datos, calcula fragmentos de paridad adicionales y almacena cada fragmento en un nodo de almacenamiento diferente. Cuando se accede a un objeto, se vuelve a ensamblar utilizando los fragmentos almacenados. Si un dato o un fragmento de paridad se corrompen o se pierden, el algoritmo de codificación de borrado puede recrear ese fragmento con un subconjunto de los datos restantes y fragmentos de paridad. Las reglas de ILM y los perfiles de codificación de borrado determinan el esquema de codificación de borrado utilizado.
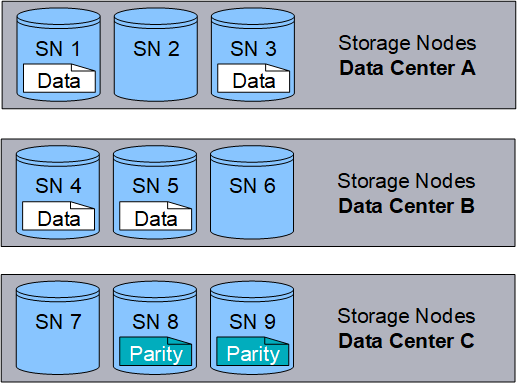
En el siguiente ejemplo, se muestra el uso de códigos de borrado en los datos de un objeto. En este ejemplo, la regla ILM utiliza un esquema de codificación de borrado 4+2. Cada objeto se divide en cuatro fragmentos de datos iguales y dos fragmentos de paridad se calculan a partir de los datos del objeto. Cada uno de los seis fragmentos se almacena en un nodo de almacenamiento diferente en tres centros de datos para proporcionar protección de datos ante fallos de nodos o pérdidas de sitios.