

Identificar y desmontar volúmenes de almacenamiento fallidos
 Sugerir cambios
Sugerir cambios
Al recuperar un nodo de almacenamiento con volúmenes de almacenamiento fallidos, debe identificar y desmontar los volúmenes fallidos. Debe verificar que solo se reformateen los volúmenes de almacenamiento fallidos como parte del procedimiento de recuperación.
Ha iniciado sesión en Grid Manager mediante un"navegador web compatible" .
Debe recuperar los volúmenes de almacenamiento fallidos lo antes posible.
El primer paso del proceso de recuperación es detectar volúmenes que se han desconectado, necesitan desmontarse o tienen errores de E/S. Si los volúmenes fallidos aún están conectados pero tienen un sistema de archivos dañado aleatoriamente, es posible que el sistema no detecte ninguna corrupción en partes no utilizadas o no asignadas del disco.

|
Debe finalizar este procedimiento antes de realizar pasos manuales para recuperar los volúmenes, como agregar o volver a conectar los discos, detener el nodo, iniciar el nodo o reiniciar. De lo contrario, cuando se ejecuta el reformat_storage_block_devices.rb script, es posible que se produzca un error en el sistema de archivos que provoque que el script se bloquee o falle.
|
|
|
Repare el hardware y coloque correctamente los discos antes de ejecutar el reboot dominio.
|

|
Identifique cuidadosamente los volúmenes de almacenamiento fallidos. Utilizará esta información para verificar qué volúmenes deben reformatearse. Una vez reformateado un volumen, no se pueden recuperar los datos del volumen. |
Para recuperar correctamente los volúmenes de almacenamiento fallidos, debe conocer los nombres de los dispositivos de los volúmenes de almacenamiento fallidos y sus identificadores de volumen.
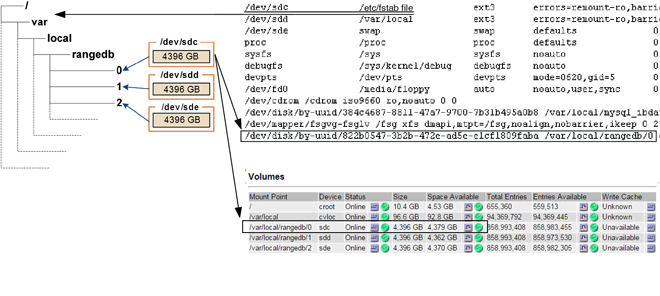
Durante la instalación, a cada dispositivo de almacenamiento se le asigna un identificador único universal (UUID) de sistema de archivos y se monta en un directorio rangedb en el nodo de almacenamiento utilizando ese UUID de sistema de archivos asignado. El UUID del sistema de archivos y el directorio rangedb se enumeran en el /etc/fstab archivo. El nombre del dispositivo, el directorio rangedb y el tamaño del volumen montado se muestran en el Administrador de Grid.
En el siguiente ejemplo, el dispositivo /dev/sdc tiene un tamaño de volumen de 4 TB, está montado en /var/local/rangedb/0 , utilizando el nombre del dispositivo /dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba en el/etc/fstab archivo:
-
Complete los siguientes pasos para registrar los volúmenes de almacenamiento fallidos y los nombres de sus dispositivos:
-
Seleccione SOPORTE > Herramientas > Topología de cuadrícula.
-
Seleccione sitio > Nodo de almacenamiento fallido > LDR > Almacenamiento > Descripción general > Principal y busque almacenes de objetos con alarmas.

-
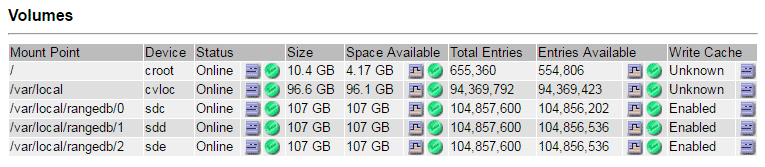
Seleccione sitio > Nodo de almacenamiento fallido > SSM > Recursos > Descripción general > Principal. Determine el punto de montaje y el tamaño del volumen de cada volumen de almacenamiento fallido identificado en el paso anterior.
Los almacenes de objetos están numerados en notación hexadecimal. Por ejemplo, 0000 es el primer volumen y 000F es el decimosexto volumen. En el ejemplo, el almacén de objetos con un ID de 0000 corresponde a
/var/local/rangedb/0con nombre de dispositivo sdc y un tamaño de 107 GB.
-
-
Inicie sesión en el nodo de almacenamiento fallido:
-
Introduzca el siguiente comando:
ssh admin@grid_node_IP -
Introduzca la contraseña que aparece en el
Passwords.txtarchivo. -
Introduzca el siguiente comando para cambiar a root:
su - -
Introduzca la contraseña que aparece en el
Passwords.txtarchivo.
Cuando inicia sesión como root, el mensaje cambia de
$a#. -
-
Ejecute el siguiente script para desmontar un volumen de almacenamiento fallido:
sn-unmount-volume object_store_IDEl
object_store_IDes el ID del volumen de almacenamiento fallido. Por ejemplo, especifique0en el comando para un almacén de objetos con ID 0000. -
Si se le solicita, presione y para detener el servicio Cassandra dependiendo del volumen de almacenamiento 0.
Si el servicio Cassandra ya está detenido, no se le preguntará nada. El servicio Cassandra se detiene solo para el volumen 0. root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
En unos segundos, el volumen se desmontará. Aparecen mensajes indicando cada paso del proceso. El mensaje final indica que el volumen está desmontado.
-
Si el desmontaje falla porque el volumen está ocupado, puede forzar un desmontaje usando el
--use-umountofopción:
Forzar un desmontaje utilizando el --use-umountofEsta opción podría provocar que los procesos o servicios que utilizan el volumen se comporten de manera inesperada o se bloqueen.root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes