

Analyse et notification des événements de performance
 Suggérer des modifications
Suggérer des modifications
Les événements de performance vous signalent les problèmes de performances d'E/S concernant une charge de travail générée par des conflits sur un composant de cluster. Unified Manager analyse l'événement pour identifier toutes les charges de travail impliquées, le composant dans les conflits et si l'événement reste un problème à résoudre.
Unified Manager surveille la latence (temps de réponse) et les IOPS (opérations) des volumes d'un cluster. Lorsque d'autres charges de travail surfont un composant de cluster, par exemple, les conflits sont possibles et le composant ne peut pas fonctionner à un niveau optimal pour répondre aux demandes de charge de travail. Les performances des autres charges de travail qui utilisent le même composant peuvent être affectées, ce qui entraîne une augmentation des latences. Si la latence franchit le seuil de performance dynamique, Unified Manager déclenche un événement de performance afin de vous en avertir.
Analyse des événements
Unified Manager effectue les analyses suivantes, en s'appuyant sur les statistiques de performance des 15 derniers jours, pour identifier les workloads victime, les workloads dominants et le composant de cluster impliqué dans un événement :
-
Identifie les charges de travail victimes dont la latence a dépassé le seuil de performance dynamique, qui est la limite supérieure de la prévision de latence :
-
Pour les volumes des agrégats HDD ou Flash Pool (hybride) (niveau local), les événements sont déclenchés uniquement lorsque la latence est supérieure à 5 millisecondes (ms) et que les IOPS représentent plus de 10 opérations par seconde (OPS/s).
-
Pour les volumes situés sur des agrégats 100 % SSD ou des agrégats FabricPool (niveau cloud), les événements sont déclenchés uniquement lorsque la latence est supérieure à 1 ms et que les IOPS sont plus de 100 OPS/s.
-
-
Identifie le composant de cluster dans les conflits.

Si la latence des charges de travail victimes au niveau de l'interconnexion de cluster est supérieure à 1 ms, Unified Manager le traite comme important et déclenche un événement pour l'interconnexion de cluster.
-
Identifie les charges de travail dominantes qui font l'objet d'une surutilisation du composant de cluster et qui l'entraînent des conflits.
-
Classe les charges de travail impliquées, en fonction de leur déviation de l'utilisation ou de l'activité d'un composant du cluster, afin de déterminer les principaux changements d'utilisation du composant du cluster et les victimes les plus affectées.
Un événement peut se produire brièvement et se corriger après le composant qu'il utilise n'est plus en conflit. Un événement continu est un événement qui se produit de nouveau pour le même composant de cluster au cours d'un intervalle de cinq minutes et qui reste à l'état actif. Pour les événements continus, Unified Manager déclenche une alerte après avoir détecté le même événement à deux intervalles d'analyse consécutifs.
Lorsqu'un événement est résolu, il reste disponible dans Unified Manager dans le cadre de l'enregistrement des anciens problèmes de performances d'un volume. Chaque événement possède un ID unique qui identifie le type d'événement et les volumes, le cluster et les composants de cluster impliqués.
|
|
Un seul volume peut être impliqué dans plusieurs événements simultanément. |
État de l'événement
Les événements peuvent être dans l'un des États suivants :
-
Actif
Indique que l'événement de performance est actuellement actif (nouveau ou reconnu). Le problème à l'origine de l'incident n'a pas été corrigé lui-même ou n'a pas été résolu. Le compteur de performances de l'objet de stockage reste au-dessus du seuil de performance.
-
Obsolète
Indique que l'incident n'est plus actif. Le problème à l'origine de l'incident s'est corrigé ou a été résolu. Le compteur de performance de l'objet de stockage n'est plus au-dessus du seuil de performance.
Notification d'événement
Les événements sont affichés sur la page Tableau de bord et sur de nombreuses autres pages de l'interface utilisateur, et les alertes pour ces événements sont envoyées à des adresses e-mail spécifiées. Vous pouvez afficher des informations d'analyse détaillées sur un événement et obtenir des suggestions de résolution de cet événement sur la page Détails de l'événement et sur la page analyse des charges de travail.
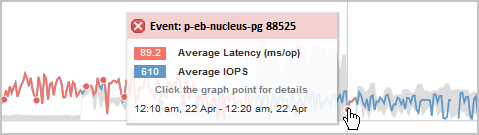
Dans cet exemple, un événement est indiqué par un point rouge (![]() ) Sur le tableau latence. Lorsque vous déplacez le curseur de la souris sur le point rouge, une fenêtre contextuelle contenant plus de détails sur l'événement et les options d'analyse s'affiche.
) Sur le tableau latence. Lorsque vous déplacez le curseur de la souris sur le point rouge, une fenêtre contextuelle contenant plus de détails sur l'événement et les options d'analyse s'affiche.
Interaction d'événement
Sur la page Détails de l'événement et sur la page analyse de la charge de travail, vous pouvez interagir avec les événements de la manière suivante :
-
Le déplacement de la souris sur un événement affiche un message indiquant l'ID de l'événement ainsi que la date et l'heure de détection de l'événement.
S'il y a plusieurs événements pour la même période, le message indique le nombre d'événements.
-
Lorsque vous cliquez sur un seul événement, une boîte de dialogue affiche des informations plus détaillées sur l'événement, notamment les composants de cluster impliqués.
Le composant en conflit est entouré et mis en évidence en rouge. Vous pouvez cliquer sur l'ID d'événement ou sur Afficher l'analyse complète pour afficher l'analyse complète sur la page Détails de l'événement. S'il existe plusieurs événements pour la même période, la boîte de dialogue affiche des détails sur les trois événements les plus récents. Vous pouvez cliquer sur un ID d'événement pour afficher l'analyse d'événement sur la page Détails de l'événement.