

Identification du problème et exécution d'actions correctives pour une tâche de protection ayant échoué
 Suggérer des modifications
Suggérer des modifications
Vous examinez le message d'erreur d'échec du travail dans le champ cause de la page Détails de l'événement et déterminez que le travail a échoué en raison d'une erreur de copie Snapshot. Vous allez ensuite à la page Volume / Health details pour recueillir plus d'informations.
Avant de commencer
Vous devez avoir le rôle Administrateur d'applications.
Description de la tâche
Le message d'erreur fourni dans le champ cause de la page Détails de l'événement contient le texte suivant concernant le travail en échec :
Protection Job Failed. Reason: (Transfer operation for relationship 'cluster2_src_svm:cluster2_src_vol2->cluster3_dst_svm: managed_svc2_vol3' ended unsuccessfully. Last error reported by Data ONTAP: Failed to create Snapshot copy 0426cluster2_src_vol2snap on volume cluster2_src_svm:cluster2_src_vol2. (CSM: An operation failed due to an ONC RPC failure.).) *Job Details*
Ce message fournit les informations suivantes :
-
Une tâche de sauvegarde ou de miroir ne s'est pas terminée avec succès.
Le travail impliquait une relation de protection entre le volume source
cluster2_src_vol2sur le serveur virtuelcluster2_src_svmet le volume de destinationmanaged_svc2_vol3sur le serveur virtuel nommécluster3_dst_svm. -
Échec d'une tâche de copie Snapshot pour
0426cluster2_src_vol2snapsur le volume sourcecluster2_src_svm:/cluster2_src_vol2.
Dans ce scénario, vous pouvez identifier la cause et les actions correctives potentielles de l'échec du travail. Toutefois, pour résoudre ce problème, vous devez accéder à l'interface utilisateur Web de System Manager ou aux commandes de l'interface de ligne de commande de ONTAP.
Étapes
-
Vous passez en revue le message d'erreur et déterminez qu'une tâche de copie Snapshot a échoué sur le volume source, ce qui indique qu'il y a probablement un problème avec le volume source.
Vous pouvez également cliquer sur le lien Détails du travail à la fin du message d'erreur, mais pour ce scénario, vous choisissez de ne pas le faire.
-
Vous décidez que vous voulez essayer de résoudre l'événement, vous devez donc procéder comme suit :
-
Cliquez sur le bouton affecter à et sélectionnez Me dans le menu.
-
Cliquez sur le bouton Acknowledge pour ne pas continuer à recevoir de notifications d'alerte répétées si des alertes ont été définies pour l'événement.
-
Vous pouvez également ajouter des remarques à propos de l'événement.
-
-
Cliquez sur le champ Source dans le volet Résumé pour afficher les détails du volume source.
Le champ Source contient le nom de l'objet source : dans ce cas, le volume sur lequel le travail de copie Snapshot a été planifié.
La page Volume / Détails de l'intégrité s'affiche pour
cluster2_src_vol2, Montrant le contenu de l'onglet protection. -
Sur le graphique de topologie de protection, une icône d'erreur s'affiche, associée au premier volume de la topologie, qui correspond au volume source de la relation SnapMirror.
Vous voyez également les barres horizontales dans l'icône du volume source, indiquant les seuils d'avertissement et d'erreur définis pour ce volume.
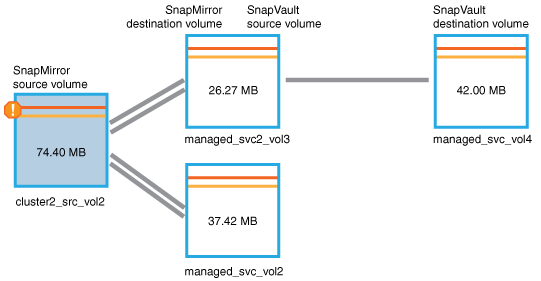
-
Placez le curseur sur l'icône d'erreur pour afficher la boîte de dialogue contextuelle qui affiche les paramètres de seuil et voir que le volume a dépassé le seuil d'erreur, ce qui indique un problème de capacité.
-
Cliquez sur l'onglet capacité.
Informations de capacité relatives au volume
cluster2_src_vol2s'affiche. -
Dans le panneau Capacity, une icône d'erreur s'affiche dans le graphique à barres, indiquant que la capacité de volume a dépassé le niveau de seuil défini pour le volume.
-
Sous le graphique capacité, vous constatez que la croissance automatique du volume a été désactivée et qu'une garantie d'espace volume a été définie.
Vous pourriez décider d'activer la croissance automatique, mais dans le cadre de ce scénario, vous décidez d'en approfondir avant de prendre une décision sur la manière de résoudre le problème de capacité.
-
Vous faites défiler la liste Events et voyez que les événements protection Job failed, Volume Days jusqu'à Full et Volume Space Full ont été générés.
-
Dans la liste Evénements, vous cliquez sur l'événement Volume Space Full pour obtenir plus d'informations, ayant décidé que cet événement semble le plus pertinent pour votre problème de capacité.
La page Détails de l'événement affiche l'événement Volume Space Full pour le volume source.
-
Dans la zone Résumé, vous lisez le champ cause de l'événement :
The full threshold set at 90% is breached. 45.38 MB (95.54%) of 47.50 MB is used. -
Sous la zone Résumé, vous voyez suggestions d'actions correctives.

Les actions correctives suggérées s'affichent uniquement pour certains événements. Vous ne voyez donc pas cette zone pour tous les types d'événements.
Vous pouvez cliquer sur la liste des actions suggérées pour résoudre l'événement Volume Space Full :
-
Activer la croissance automatique sur ce volume.
-
Redimensionner le volume.
-
Activer et exécuter la déduplication sur ce volume.
-
Activer et exécuter la compression sur ce volume.
-
-
Vous décidez d'activer la croissance automatique sur le volume. Pour ce faire, vous devez déterminer l'espace libre disponible sur l'agrégat parent et le taux de croissance actuel du volume :
-
Examiner l'agrégat parent,
cluster2_src_aggr1, Dans le volet périphériques connexes*.
Vous pouvez cliquer sur le nom de l'agrégat pour obtenir plus de détails sur celui-ci.
Vous avez établi que l'agrégat dispose d'un espace suffisant pour activer la croissance automatique de volumes.
-
En haut de la page, regardez l'icône indiquant un incident critique et passez en revue le texte au-dessous de l'icône.
Vous déterminez que « jours complets : moins d'une journée | taux de croissance quotidien : 5.4 % ».
-
-
Accédez à System Manager ou à l'interface de ligne de commandes de ONTAP pour activer le
volume autogrowoption.
Notez les noms du volume et de l'agrégat pour qu'ils soient disponibles en cas d'activation de la croissance automatique.
-
Après avoir résolu le problème de capacité, revenez à la page Détails de l'événement Unified Manager** et marquez l'événement comme résolu.