

Installation et configuration de l'opérateur de surveillance Kubernetes
 Suggérer des modifications
Suggérer des modifications
Data Infrastructure Insights propose l'opérateur de surveillance Kubernetes pour la collection Kubernetes. Accédez à Kubernetes > Collecteurs > +Kubernetes Collector pour déployer un nouvel opérateur.
Avant d'installer Kubernetes Monitoring Operator
Voir le"Prérequis" documentation avant d'installer ou de mettre à niveau Kubernetes Monitoring Operator.
Installation de l'opérateur de surveillance Kubernetes
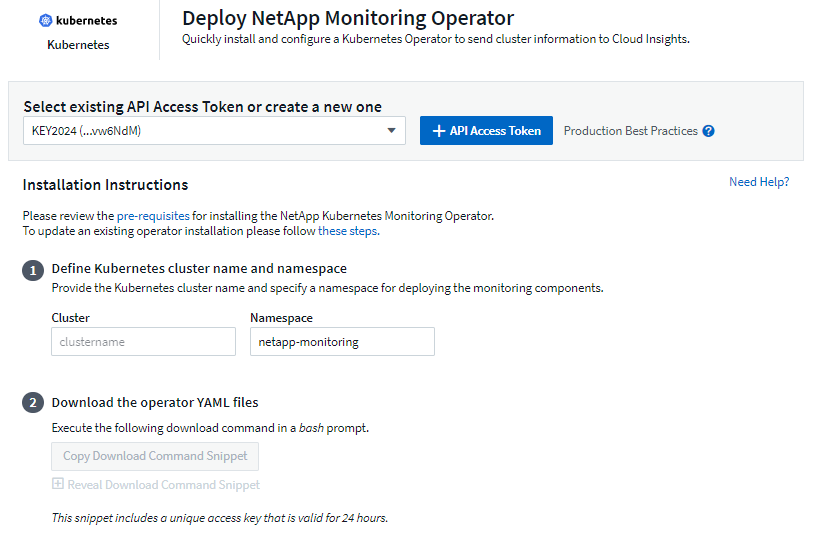

-
Saisissez un nom de cluster et un espace de noms uniques. Si vous êtesmise à niveau à partir d'un opérateur Kubernetes précédent, utilisez le même nom de cluster et le même espace de noms.
-
Une fois ces informations saisies, vous pouvez copier l'extrait de commande de téléchargement dans le presse-papiers.
-
Collez l'extrait dans une fenêtre bash et exécutez-le. Les fichiers d’installation de l’opérateur seront téléchargés. Notez que l'extrait possède une clé unique et est valable 24 heures.
-
Si vous disposez d'un référentiel personnalisé ou privé, copiez l'extrait d'image facultatif, collez-le dans un shell bash et exécutez-le. Une fois les images extraites, copiez-les dans votre référentiel privé. Assurez-vous de conserver les mêmes balises et la même structure de dossiers. Mettez à jour les chemins dans operator-deployment.yaml ainsi que les paramètres du référentiel Docker dans operator-config.yaml.
-
Si vous le souhaitez, examinez les options de configuration disponibles telles que les paramètres de proxy ou de référentiel privé. Vous pouvez en savoir plus sur"options de configuration" .
-
Lorsque vous êtes prêt, déployez l'opérateur en copiant l'extrait kubectl Apply, en le téléchargeant et en l'exécutant.
-
L'installation se déroule automatiquement. Une fois terminé, cliquez sur le bouton Suivant.
-
Une fois l’installation terminée, cliquez sur le bouton Suivant. Assurez-vous également de supprimer ou de stocker en toute sécurité le fichier operator-secrets.yaml.
Si vous disposez d'un référentiel personnalisé, lisez à proposen utilisant un référentiel Docker personnalisé/privé .
Composants de surveillance Kubernetes
Data Infrastructure Insights Kubernetes Monitoring comprend quatre composants de surveillance :
-
Mesures de cluster
-
Performances et carte du réseau (facultatif)
-
Journaux d'événements (facultatif)
-
Analyse des changements (facultatif)
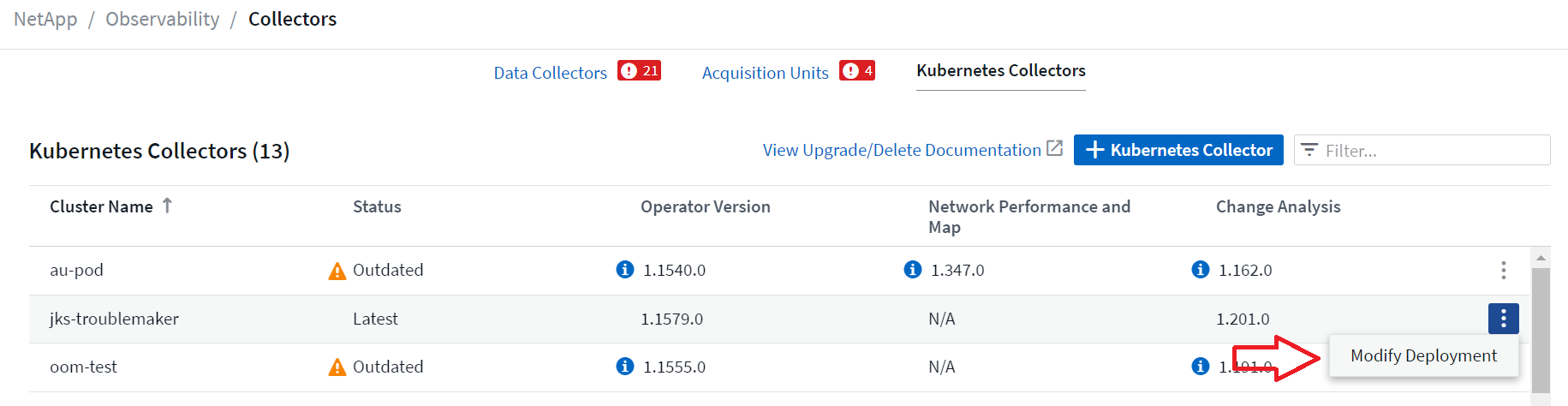
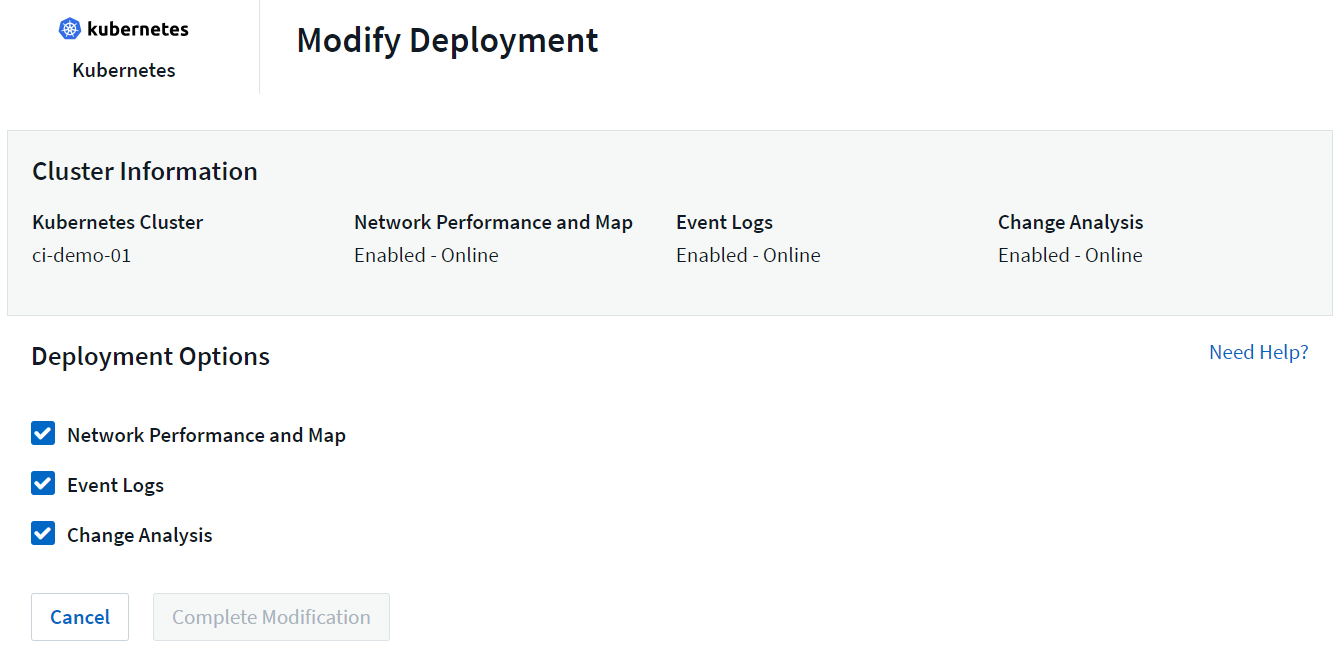
Les composants facultatifs ci-dessus sont activés par défaut pour chaque collecteur Kubernetes ; si vous décidez que vous n'avez pas besoin d'un composant pour un collecteur particulier, vous pouvez le désactiver en accédant à Kubernetes > Collecteurs et en sélectionnant Modifier le déploiement dans le menu « trois points » du collecteur à droite de l'écran.
L'écran affiche l'état actuel de chaque composant et vous permet de désactiver ou d'activer les composants de ce collecteur selon vos besoins.
Mise à niveau vers la dernière version de Kubernetes Monitoring Operator
Mises à niveau du bouton-poussoir DII
Vous pouvez mettre à niveau l'opérateur de surveillance Kubernetes via la page Collecteurs Kubernetes DII. Cliquez sur le menu à côté du cluster que vous souhaitez mettre à niveau et sélectionnez Mettre à niveau. L'opérateur vérifiera les signatures d'image, effectuera un instantané de votre installation actuelle et effectuera la mise à niveau. Dans quelques minutes, vous devriez voir l'état de l'opérateur progresser de « Mise à niveau en cours » à « Dernière mise à jour ». Si vous rencontrez une erreur, vous pouvez sélectionner le statut d'erreur pour plus de détails et vous référer au tableau de dépannage des mises à niveau par bouton-poussoir ci-dessous.
Mises à niveau par simple pression d'un bouton avec des référentiels privés
Si votre opérateur est configuré pour utiliser un référentiel privé, assurez-vous que toutes les images requises pour exécuter l'opérateur et leurs signatures sont disponibles dans votre référentiel. Si vous rencontrez une erreur pendant le processus de mise à niveau pour des images manquantes, ajoutez-les simplement à votre référentiel et réessayez la mise à niveau. Pour télécharger les signatures d'image dans votre référentiel, veuillez utiliser l'outil de cosignature comme suit, en veillant à télécharger les signatures pour toutes les images spécifiées sous 3 Facultatif : Télécharger les images de l'opérateur dans votre référentiel privé > Extrait d'image
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
Revenir à une version précédemment exécutée
Si vous avez effectué une mise à niveau à l'aide de la fonction de mise à niveau par simple pression sur un bouton et que vous rencontrez des difficultés avec la version actuelle de l'opérateur dans les sept jours suivant la mise à niveau, vous pouvez rétrograder vers la version précédemment exécutée à l'aide de l'instantané créé pendant le processus de mise à niveau. Cliquez sur le menu à côté du cluster que vous souhaitez restaurer et sélectionnez Restaurer.
Mises à niveau manuelles
Déterminez si une AgentConfiguration existe avec l'opérateur existant (si votre espace de noms n'est pas le netapp-monitoring par défaut, remplacez-le par l'espace de noms approprié) :
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration Si une AgentConfiguration existe :
-
Installationle dernier opérateur sur l'opérateur existant.
-
Assurez-vous que vous êtesextraire les dernières images de conteneurs si vous utilisez un référentiel personnalisé.
-
Si AgentConfiguration n'existe pas :
-
Notez le nom de votre cluster tel qu'il est reconnu par Data Infrastructure Insights (si votre espace de noms n'est pas le netapp-monitoring par défaut, remplacez-le par l'espace de noms approprié) :
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * Créez une sauvegarde de l'opérateur existant (si votre espace de noms n'est pas le netapp-monitoring par défaut, remplacez-le par l'espace de noms approprié) :kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,Désinstaller>>l'opérateur existant. * <<installing-the-kubernetes-monitoring-operator,Installation>>le dernier opérateur.
-
Utilisez le même nom de cluster.
-
Après avoir téléchargé les derniers fichiers Operator YAML, portez toutes les personnalisations trouvées dans agent_backup.yaml vers le fichier operator-config.yaml téléchargé avant le déploiement.
-
Assurez-vous que vous êtesextraire les dernières images de conteneurs si vous utilisez un référentiel personnalisé.
-
Arrêt et démarrage de l'opérateur de surveillance Kubernetes
Pour arrêter l’opérateur de surveillance Kubernetes :
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 Pour démarrer l’opérateur de surveillance Kubernetes :
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
Désinstallation
Pour supprimer l'opérateur de surveillance Kubernetes
Notez que l'espace de noms par défaut pour l'opérateur de surveillance Kubernetes est « netapp-monitoring ». Si vous avez défini votre propre espace de noms, remplacez cet espace de noms dans ces commandes et fichiers et dans tous les suivants.
Les versions plus récentes de l'opérateur de surveillance peuvent être désinstallées avec les commandes suivantes :
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
Si l'opérateur de surveillance a été déployé dans son propre espace de noms dédié, supprimez l'espace de noms :
kubectl delete ns <NAMESPACE> Remarque : si la première commande renvoie « Aucune ressource trouvée », utilisez les instructions suivantes pour désinstaller les anciennes versions de l’opérateur de surveillance.
Exécutez chacune des commandes suivantes dans l’ordre. Selon votre installation actuelle, certaines de ces commandes peuvent renvoyer des messages « objet non trouvé ». Ces messages peuvent être ignorés en toute sécurité.
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
Si une contrainte de contexte de sécurité a été créée précédemment :
kubectl delete scc telegraf-hostaccess
À propos de Kube-state-metrics
L'opérateur de surveillance NetApp Kubernetes installe ses propres métriques d'état Kube pour éviter tout conflit avec d'autres instances.
Pour plus d'informations sur Kube-State-Metrics, voir"cette page" .
Configuration/Personnalisation de l'opérateur
Ces sections contiennent des informations sur la personnalisation de la configuration de votre opérateur, l'utilisation d'un proxy, l'utilisation d'un référentiel Docker personnalisé ou privé ou l'utilisation d'OpenShift.
Options de configuration
Les paramètres les plus fréquemment modifiés peuvent être configurés dans la ressource personnalisée AgentConfiguration. Vous pouvez modifier cette ressource avant de déployer l'opérateur en modifiant le fichier operator-config.yaml. Ce fichier comprend des exemples de paramètres commentés. Voir la liste des"paramètres disponibles" pour la version la plus récente de l'opérateur.
Vous pouvez également modifier cette ressource après le déploiement de l'opérateur à l'aide de la commande suivante :
kubectl -n netapp-monitoring edit AgentConfiguration Pour déterminer si votre version déployée de l'opérateur prend en charge AgentConfiguration, exécutez la commande suivante :
kubectl get crd agentconfigurations.monitoring.netapp.com Si vous voyez un message « Erreur du serveur (NotFound) », votre opérateur doit être mis à niveau avant de pouvoir utiliser AgentConfiguration.
Configuration de la prise en charge du proxy
Il existe deux endroits où vous pouvez utiliser un proxy sur votre locataire afin d'installer Kubernetes Monitoring Operator. Il peut s'agir des mêmes systèmes proxy ou de systèmes proxy distincts :
-
Proxy nécessaire lors de l'exécution de l'extrait de code d'installation (à l'aide de « curl ») pour connecter le système où l'extrait est exécuté à votre environnement Data Infrastructure Insights
-
Proxy requis par le cluster Kubernetes cible pour communiquer avec votre environnement Data Infrastructure Insights
Si vous utilisez un proxy pour l'un ou les deux, afin d'installer Kubernetes Operating Monitor, vous devez d'abord vous assurer que votre proxy est configuré pour permettre une bonne communication avec votre environnement Data Infrastructure Insights . Si vous disposez d'un proxy et pouvez accéder à Data Infrastructure Insights à partir du serveur/de la machine virtuelle à partir duquel vous souhaitez installer l'opérateur, votre proxy est probablement configuré correctement.
Pour le proxy utilisé pour installer Kubernetes Operating Monitor, avant d'installer l'opérateur, définissez les variables d'environnement http_proxy/https_proxy. Pour certains environnements proxy, vous devrez peut-être également définir la variable d'environnement no_proxy.
Pour définir la ou les variables, effectuez les étapes suivantes sur votre système avant d'installer Kubernetes Monitoring Operator :
-
Définissez les variables d'environnement https_proxy et/ou http_proxy pour l'utilisateur actuel :
-
Si le proxy en cours de configuration ne dispose pas d'authentification (nom d'utilisateur/mot de passe), exécutez la commande suivante :
export https_proxy=<proxy_server>:<proxy_port> .. Si le proxy en cours de configuration dispose d'une authentification (nom d'utilisateur/mot de passe), exécutez cette commande :
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Pour que le proxy utilisé pour votre cluster Kubernetes communique avec votre environnement Data Infrastructure Insights , installez Kubernetes Monitoring Operator après avoir lu toutes ces instructions.
Configurez la section proxy d’AgentConfiguration dans operator-config.yaml avant de déployer l’opérateur de surveillance Kubernetes.
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
Utiliser un référentiel Docker personnalisé ou privé
Par défaut, l'opérateur de surveillance Kubernetes extrait les images de conteneur du référentiel Data Infrastructure Insights . Si vous disposez d'un cluster Kubernetes utilisé comme cible pour la surveillance et que ce cluster est configuré pour extraire uniquement des images de conteneur à partir d'un référentiel Docker personnalisé ou privé ou d'un registre de conteneurs, vous devez configurer l'accès aux conteneurs nécessaires à l'opérateur de surveillance Kubernetes.
Exécutez « Image Pull Snippet » à partir de la mosaïque d’installation de NetApp Monitoring Operator. Cette commande se connectera au référentiel Data Infrastructure Insights , extraira toutes les dépendances d'image pour l'opérateur et se déconnectera du référentiel Data Infrastructure Insights . Lorsque vous y êtes invité, saisissez le mot de passe temporaire du référentiel fourni. Cette commande télécharge toutes les images utilisées par l'opérateur, y compris pour les fonctionnalités optionnelles. Voir ci-dessous pour les fonctionnalités pour lesquelles ces images sont utilisées.
Fonctionnalités de l'opérateur principal et surveillance de Kubernetes
-
surveillance netapp
-
proxy ci-kube-rbac
-
ci-ksm
-
ci-telegraf
-
utilisateur root sans distribution
Journal des événements
-
ci-fluent-bit
-
exportateur d'événements ci-kubernetes
Performances et carte du réseau
-
ci-net-observer
Poussez l'image Docker de l'opérateur vers votre référentiel Docker privé/local/d'entreprise conformément à vos politiques d'entreprise. Assurez-vous que les balises d’image et les chemins d’accès aux répertoires de ces images dans votre référentiel sont cohérents avec ceux du référentiel Data Infrastructure Insights .
Modifiez le déploiement de l'opérateur de surveillance dans operator-deployment.yaml et modifiez toutes les références d'image pour utiliser votre référentiel Docker privé.
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
Modifiez AgentConfiguration dans operator-config.yaml pour refléter le nouvel emplacement du référentiel Docker. Créez un nouveau imagePullSecret pour votre référentiel privé, pour plus de détails, consultez https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
Instructions OpenShift
Si vous utilisez OpenShift 4.6 ou une version ultérieure, vous devez modifier AgentConfiguration dans operator-config.yaml pour activer le paramètre runPrivileged :
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift peut implémenter un niveau de sécurité supplémentaire qui peut bloquer l'accès à certains composants Kubernetes.
Tolérances et souillures
Les DaemonSets netapp-ci-telegraf-ds, netapp-ci-fluent-bit-ds et netapp-ci-net-observer-l4-ds doivent planifier un pod sur chaque nœud de votre cluster afin de collecter correctement les données sur tous les nœuds. L'opérateur a été configuré pour tolérer certaines souillures bien connues. Si vous avez configuré des taches personnalisées sur vos nœuds, empêchant ainsi les pods de s'exécuter sur chaque nœud, vous pouvez créer une tolérance pour ces taches"dans AgentConfiguration" . Si vous avez appliqué des taches personnalisées à tous les nœuds de votre cluster, vous devez également ajouter les tolérances nécessaires au déploiement de l'opérateur pour permettre la planification et l'exécution du pod de l'opérateur.
En savoir plus sur Kubernetes"Souillures et tolérances" .
Une note sur les secrets
Pour supprimer l'autorisation permettant à l'opérateur de surveillance Kubernetes d'afficher les secrets à l'échelle du cluster, supprimez les ressources suivantes du fichier operator-setup.yaml avant l'installation :
ClusterRole/netapp-ci<namespace>-agent-secret ClusterRoleBinding/netapp-ci<namespace>-agent-secret
S'il s'agit d'une mise à niveau, supprimez également les ressources de votre cluster :
kubectl delete ClusterRole/netapp-ci-<namespace>-agent-secret-clusterrole kubectl delete ClusterRoleBinding/netapp-ci-<namespace>-agent-secret-clusterrolebinding
Si l'analyse des changements est activée, modifiez AgentConfiguration ou operator-config.yaml pour supprimer le commentaire de la section de gestion des changements et inclure kindsToIgnoreFromWatch: '"secrets"' sous la section de gestion des changements. Notez la présence et la position des guillemets simples et doubles dans cette ligne.
change-management: ... # # A comma separated list of kinds to ignore from watching from the default set of kinds watched by the collector # # Each kind will have to be prefixed by its apigroup # # Example: '"networking.k8s.io.networkpolicies,batch.jobs", "authorization.k8s.io.subjectaccessreviews"' kindsToIgnoreFromWatch: '"secrets"' ...
Vérification des signatures d'image de l'opérateur de surveillance Kubernetes
L'image de l'opérateur et toutes les images associées qu'il déploie sont signées par NetApp. Vous pouvez vérifier manuellement les images avant l'installation à l'aide de l'outil de cosignature ou configurer un contrôleur d'admission Kubernetes. Pour plus de détails, veuillez consulter le"Documentation Kubernetes" .
La clé publique utilisée pour vérifier les signatures d'image est disponible dans la mosaïque d'installation de l'opérateur de surveillance sous Facultatif : téléchargez les images de l'opérateur dans votre référentiel privé > Clé publique de signature d'image
Pour vérifier manuellement une signature d’image, procédez comme suit :
-
Copiez et exécutez l'extrait d'image
-
Copiez et saisissez le mot de passe du référentiel lorsque vous y êtes invité
-
Stocker la clé publique de signature d'image (dii-image-signing.pub dans l'exemple)
-
Vérifiez les images à l'aide de cosign. Reportez-vous à l'exemple suivant d'utilisation de cosignature
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
Dépannage
Quelques éléments à essayer si vous rencontrez des problèmes lors de la configuration de l'opérateur de surveillance Kubernetes :
| Problème: | Essayez ceci: |
|---|---|
Je ne vois pas d'hyperlien/connexion entre mon volume persistant Kubernetes et le périphérique de stockage back-end correspondant. Mon volume persistant Kubernetes est configuré à l’aide du nom d’hôte du serveur de stockage. |
Suivez les étapes pour désinstaller l’agent Telegraf existant, puis réinstaller le dernier agent Telegraf. Vous devez utiliser Telegraf version 2.0 ou ultérieure et votre stockage de cluster Kubernetes doit être activement surveillé par Data Infrastructure Insights. |
Je vois des messages dans les journaux ressemblant à ce qui suit : E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: Failed to list *v1.MutatingWebhookConfiguration: the server could not find the requested resource E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: Failed to list *v1.Lease: the server could not find the requested resource (get leases.coordination.k8s.io) etc. |
Ces messages peuvent se produire si vous exécutez kube-state-metrics version 2.0.0 ou supérieure avec des versions de Kubernetes inférieures à 1.20. Pour obtenir la version de Kubernetes : kubectl version Pour obtenir la version de kube-state-metrics : kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' Pour éviter que ces messages ne se produisent, les utilisateurs peuvent modifier leur déploiement kube-state-metrics pour désactiver les baux suivants : mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources Plus précisément, ils peuvent utiliser l'argument CLI suivant : resources=certificatesigningrequests,configmaps,cronjobs,daemonsets, deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges, namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes, poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas, La liste de ressources par défaut est : « certificatesigningrequests,configmaps,cronjobs,daemonsets,deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,leases,limitranges,mutatingwebhookconfigurations,namespaces,networkpolicies,nodes, persistentvolumeclaims,persistentvolumes,poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas,secrets,services,statefulsets,storageclasses,validatingwebhookconfigurations,volumeattachments » |
Je vois des messages d'erreur de Telegraf ressemblant à ce qui suit, mais Telegraf démarre et s'exécute : 11 oct. 14:23:41 ip-172-31-39-47 systemd[1] : Démarré L'agent serveur piloté par plug-in pour la création de rapports de métriques dans InfluxDB. 11 oct. 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="échec de la création du répertoire de cache. /etc/telegraf/.cache/snowflake, err : mkdir /etc/telegraf/.ca che : permission refusée. ignoré\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" Oct 11 14:23:41 ip-172-31-39-47 telegraf[1827] : time="2021-10-11T14:23:41Z" level=error msg="échec d'ouverture. Ignoré. ouvrez /etc/telegraf/.cache/snowflake/ocsp_response_cache.json : aucun fichier ou répertoire de ce type\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 oct. 14:23:41 ip-172-31-39-47 telegraf[1827] : 2021-10-11T14:23:41Z Je ! Démarrage de Telegraf 1.19.3 |
Il s'agit d'un problème connu. Se référer à"Cet article GitHub" pour plus de détails. Tant que Telegraf est opérationnel, les utilisateurs peuvent ignorer ces messages d'erreur. |
Sur Kubernetes, mes pods Telegraf signalent l'erreur suivante : « Erreur lors du traitement des informations mountstats : échec d'ouverture du fichier mountstats : /hostfs/proc/1/mountstats, erreur : ouverture de /hostfs/proc/1/mountstats : autorisation refusée » |
Si SELinux est activé et appliqué, il empêche probablement les pods Telegraf d'accéder au fichier /proc/1/mountstats sur le nœud Kubernetes. Pour surmonter cette restriction, modifiez la configuration de l'agent et activez le paramètre runPrivileged. Pour plus de détails, reportez-vous aux instructions OpenShift. |
Sur Kubernetes, mon pod Telegraf ReplicaSet signale l'erreur suivante : [inputs.prometheus] Erreur dans le plugin : impossible de charger la paire de clés /etc/kubernetes/pki/etcd/server.crt:/etc/kubernetes/pki/etcd/server.key : ouvrir /etc/kubernetes/pki/etcd/server.crt : aucun fichier ou répertoire de ce type |
Le pod Telegraf ReplicaSet est destiné à s'exécuter sur un nœud désigné comme maître ou pour etcd. Si le pod ReplicaSet n’est pas en cours d’exécution sur l’un de ces nœuds, vous obtiendrez ces erreurs. Vérifiez si vos nœuds maître/etcd sont contaminés. Si c'est le cas, ajoutez les tolérances nécessaires au Telegraf ReplicaSet, telegraf-rs. Par exemple, modifiez le ReplicaSet… kubectl edit rs telegraf-rs …et ajoutez les tolérances appropriées à la spécification. Ensuite, redémarrez le pod ReplicaSet. |
J'ai un environnement PSP/PSA. Cela affecte-t-il mon opérateur de surveillance ? |
Si votre cluster Kubernetes s'exécute avec la stratégie de sécurité des pods (PSP) ou l'admission de sécurité des pods (PSA) en place, vous devez effectuer une mise à niveau vers la dernière version de Kubernetes Monitoring Operator. Suivez ces étapes pour mettre à niveau vers l’opérateur actuel avec prise en charge de PSP/PSA : 1. Désinstaller l'opérateur de surveillance précédent : kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2. Installation la dernière version de l'opérateur de surveillance. |
J'ai rencontré des problèmes lors du déploiement de l'opérateur et j'utilise PSP/PSA. |
1. Modifiez l'agent à l'aide de la commande suivante : kubectl -n <name-space> edit agent 2. Marquer « security-policy-enabled » comme « faux ». Cela désactivera les politiques de sécurité des pods et l'admission de sécurité des pods et permettra à l'opérateur de se déployer. Confirmez en utilisant les commandes suivantes : kubectl get psp (devrait indiquer que la politique de sécurité du pod a été supprimée) kubectl get all -n <namespace> |
grep -i psp (devrait indiquer que rien n'est trouvé) |
Erreurs « ImagePullBackoff » observées |
Ces erreurs peuvent être observées si vous disposez d’un référentiel Docker personnalisé ou privé et que vous n’avez pas encore configuré l’opérateur de surveillance Kubernetes pour le reconnaître correctement. En savoir plus à propos de la configuration pour un référentiel personnalisé/privé. |
J'ai un problème avec mon déploiement d'opérateur de surveillance et la documentation actuelle ne m'aide pas à le résoudre. |
Capturez ou notez autrement la sortie des commandes suivantes et contactez l'équipe de support technique. kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Les pods net-observer (Workload Map) dans l'espace de noms Operator sont dans CrashLoopBackOff |
Ces pods correspondent au collecteur de données Workload Map pour l'observabilité du réseau. Essayez ceci : • Vérifiez les journaux de l’un des pods pour confirmer la version minimale du noyau. Par exemple : ---- {"ci-tenant-id":"votre-id-de-tenant","collector-cluster":"votre-nom-de-cluster-k8s","environment":"prod","level":"error","msg":"échec de validation. Raison : la version du noyau 3.10.0 est inférieure à la version minimale du noyau 4.18.0","time":"2022-11-09T08:23:08Z"} ---- • Les pods Net-observer nécessitent que la version du noyau Linux soit au moins 4.18.0. Vérifiez la version du noyau à l’aide de la commande « uname -r » et assurez-vous qu’elle est >= 4.18.0 |
Les pods s'exécutent dans l'espace de noms de l'opérateur (par défaut : netapp-monitoring), mais aucune donnée n'est affichée dans l'interface utilisateur pour la carte de charge de travail ou les métriques Kubernetes dans les requêtes. |
Vérifiez le réglage de l'heure sur les nœuds du cluster K8S. Pour un audit et des rapports de données précis, il est fortement recommandé de synchroniser l'heure sur la machine Agent à l'aide du protocole Network Time Protocol (NTP) ou du protocole Simple Network Time Protocol (SNTP). |
Certains des pods d'observateur réseau dans l'espace de noms Operator sont en état d'attente |
Net-observer est un DaemonSet et exécute un pod dans chaque nœud du cluster k8s. • Notez le pod qui est en état d’attente et vérifiez s’il rencontre un problème de ressources pour le processeur ou la mémoire. Assurez-vous que la mémoire et le processeur requis sont disponibles dans le nœud. |
Je vois ce qui suit dans mes journaux immédiatement après l'installation de Kubernetes Monitoring Operator : [inputs.prometheus] Erreur dans le plugin : erreur lors de la requête HTTP vers http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics : obtenir http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics : numérotation TCP : recherche kube-state-metrics.<namespace>.svc.cluster.local : aucun hôte de ce type |
Ce message n'apparaît généralement que lorsqu'un nouvel opérateur est installé et que le pod telegraf-rs est opérationnel avant le pod ksm. Ces messages devraient cesser une fois que tous les pods sont en cours d’exécution. |
Je ne vois aucune métrique collectée pour les CronJobs Kubernetes qui existent dans mon cluster. |
Vérifiez votre version de Kubernetes (c'est-à-dire |
Après l'installation de l'opérateur, les pods telegraf-ds entrent dans CrashLoopBackOff et les journaux des pods indiquent « su : échec d'authentification ». |
Modifiez la section Telegraf dans AgentConfiguration et définissez dockerMetricCollectionEnabled sur false. Pour plus de détails, reportez-vous au manuel de l'opérateur."options de configuration" . … spec: … telegraf: … - nom : docker mode d'exécution : - substitutions DaemonSet : - clé : DOCKER_UNIX_SOCK_PLACEHOLDER valeur : unix:///run/docker.sock … … |
Je vois des messages d'erreur répétés ressemblant à ce qui suit dans mes journaux Telegraf : E! [agent] Erreur lors de l'écriture dans outputs.http : Post "https://<tenant_url>/rest/v1/lake/ingest/influxdb" : délai de contexte dépassé (Client.Timeout dépassé lors de l'attente des en-têtes) |
Modifiez la section Telegraf dans AgentConfiguration et augmentez outputTimeout à 10 s. Pour plus de détails, reportez-vous au manuel de l'opérateur."options de configuration" . |
Il me manque des données involvedobject pour certains journaux d'événements. |
Assurez-vous d'avoir suivi les étapes décrites dans la"Autorisations" section ci-dessus. |
Pourquoi est-ce que je vois deux pods d’opérateurs de surveillance en cours d’exécution, l’un nommé netapp-ci-monitoring-operator-<pod> et l’autre nommé monitoring-operator-<pod> ? |
À compter du 12 octobre 2023, Data Infrastructure Insights a remanié l'opérateur pour mieux servir nos utilisateurs ; pour que ces changements soient pleinement adoptés, vous devezsupprimer l'ancien opérateur etinstaller le nouveau . |
Mes événements Kubernetes ont cessé de manière inattendue d'être signalés à Data Infrastructure Insights. |
Récupérer le nom du pod exportateur d'événements : `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Je vois que des pods déployés par l'opérateur de surveillance Kubernetes se bloquent en raison de ressources insuffisantes. |
Consultez l'opérateur de surveillance Kubernetes"options de configuration" pour augmenter les limites du processeur et/ou de la mémoire selon les besoins. |
Une image manquante ou une configuration non valide a entraîné l'échec du démarrage ou de la préparation des pods netapp-ci-kube-state-metrics. Désormais, le StatefulSet est bloqué et les modifications de configuration ne sont pas appliquées aux pods netapp-ci-kube-state-metrics. |
Le StatefulSet est dans un"cassé" État. Après avoir résolu les problèmes de configuration, faites rebondir les pods netapp-ci-kube-state-metrics. |
Les pods netapp-ci-kube-state-metrics ne parviennent pas à démarrer après l'exécution d'une mise à niveau de l'opérateur Kubernetes, générant ErrImagePull (échec de l'extraction de l'image). |
Essayez de réinitialiser les pods manuellement. |
Les messages « Événement rejeté car plus ancien que maxEventAgeSeconds » sont observés pour mon cluster Kubernetes sous Analyse des journaux. |
Modifiez l'opérateur agentconfiguration et augmentez event-exporter-maxEventAgeSeconds (c'est-à-dire à 60 s), event-exporter-kubeQPS (c'est-à-dire à 100) et event-exporter-kubeBurst (c'est-à-dire à 500). Pour plus de détails sur ces options de configuration, consultez le"options de configuration" page. |
Telegraf avertit ou plante à cause d'une mémoire verrouillable insuffisante. |
Essayez d'augmenter la limite de mémoire verrouillable pour Telegraf dans le système d'exploitation/nœud sous-jacent. Si l’augmentation de la limite n’est pas une option, modifiez la configuration de l’agent NKMO et définissez unprotected sur true. Cela indiquera à Telegraf de ne pas tenter de réserver des pages de mémoire verrouillées. Bien que cela puisse présenter un risque de sécurité, car les secrets déchiffrés peuvent être échangés sur le disque, cela permet l'exécution dans des environnements où la réservation de mémoire verrouillée n'est pas possible. Pour plus de détails sur les options de configuration non protégées, reportez-vous à la"options de configuration" page. |
Je vois des messages d'avertissement de Telegraf ressemblant à ce qui suit : W! [inputs.diskio] Impossible de récupérer le nom du disque pour « vdc » : erreur de lecture de /dev/vdc : aucun fichier ou répertoire de ce type |
Pour l'opérateur de surveillance Kubernetes, ces messages d'avertissement sont bénins et peuvent être ignorés en toute sécurité. Vous pouvez également modifier la section Telegraf dans AgentConfiguration et définir runDsPrivileged sur true. Pour plus de détails, reportez-vous à la"options de configuration de l'opérateur" . |
Mon pod Fluent-bit échoue avec les erreurs suivantes : [2024/10/16 14:16:23] [error] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] Trop de fichiers ouverts [2024/10/16 14:16:23] [error] échec d'initialisation de l'entrée tail.0 [2024/10/16 14:16:23] [error] [engine] échec d'initialisation de l'entrée |
Essayez de modifier vos paramètres fsnotify dans votre cluster : sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Redémarrez Fluent-bit. Remarque : pour que ces paramètres soient persistants après chaque redémarrage du nœud, vous devez placer les lignes suivantes dans /etc/sysctl.conf fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
Les pods DS de Telegraf signalent des erreurs liées au fait que le plug-in d'entrée Kubernetes ne parvient pas à effectuer des requêtes HTTP en raison de l'impossibilité de valider le certificat TLS. Par exemple : E! [inputs.kubernetes] Erreur dans le plugin : erreur lors de la requête HTTP vers"https://<kubelet_IP>:10250/stats/summary": Obtenir"https://<kubelet_IP>:10250/stats/summary": tls : échec de vérification du certificat : x509 : impossible de valider le certificat pour <kubelet_IP> car il ne contient aucun SAN IP |
Cela se produit si le kubelet utilise des certificats auto-signés et/ou si le certificat spécifié n'inclut pas le <kubelet_IP> dans la liste Subject Alternative Name des certificats. Pour résoudre ce problème, l'utilisateur peut modifier le"configuration de l'agent" , et définissez telegraf:insecureK8sSkipVerify sur true. Cela configurera le plugin d'entrée Telegraf pour ignorer la vérification. Alternativement, l'utilisateur peut configurer le kubelet pour"serveurTLSBootstrap" , ce qui déclenchera une demande de certificat à partir de l'API « certificates.k8s.io ». |
Des informations complémentaires peuvent être trouvées à partir du"Support" page ou dans le"Matrice de support du collecteur de données" .