

Validation des solutions
 Suggérer des modifications
Suggérer des modifications
Cette section présente quelques cas d'utilisation de solutions.
-
L'une des principales utilisations de SnapMirror est la sauvegarde des données. SnapMirror peut être utilisé en tant qu'outil de sauvegarde principal en répliquant les données au sein d'un même cluster ou vers des cibles distantes.
-
Utilisation de l'environnement de reprise d'activité pour exécuter des tests de développement d'applications (développement/test)
-
Reprise sur incident en cas d'incident en production.
-
Distribution des données et accès aux données à distance.
Toutefois, les rares cas d'utilisation validés dans cette solution ne représentent pas l'intégralité des fonctionnalités de réplication SnapMirror.
Développement et test d'applications (développement/test)
Pour accélérer le développement d'applications, vous pouvez cloner rapidement les données répliquées au niveau du site de reprise après incident et les utiliser pour développer et tester des applications. La colocation des environnements de reprise après incident et de test et développement peut considérablement améliorer l'utilisation des installations de sauvegarde ou de reprise après incident. Les clones à la demande de test et développement fournissent autant de copies que nécessaire pour passer plus rapidement en production.
La technologie NetApp FlexClone permet de créer rapidement une copie en lecture-écriture d'un volume FlexVol de destination SnapMirror si vous souhaitez disposer d'un accès en lecture-écriture à la copie secondaire pour vérifier si toutes les données de production sont disponibles.
Procédez comme suit pour utiliser l'environnement de reprise sur incident afin d'effectuer des opérations de développement/test d'applications :
-
Faire une copie des données de production. Pour ce faire, créez une copie Snapshot d'application d'un volume sur site. La création de snapshots d'applications s'effectue en trois étapes :
Lock,Snap, etUnlock.-
Mettez le système de fichiers en veille afin que les E/S soient suspendues et que les applications conservent leur cohérence. Toute application qui exécute le système de fichiers reste à l'état d'attente jusqu'à ce que la commande unquiesce soit émise à l'étape c. Les étapes a, b et c sont exécutées via un processus ou un workflow transparent qui n'affecte pas le SLA de l'application.
[root@hc-cloud-secure-1 ~]# fsfreeze -f /file1
Cette option demande que le système de fichiers spécifié soit bloqué à partir de nouvelles modifications. Tout processus tentant d'écrire dans le système de fichiers gelé est bloqué jusqu'à ce que le système de fichiers soit débloqué.
-
Créez une copie Snapshot du volume sur site.
A400-G0312::> snapshot create -vserver Healthcare_SVM -volume hc_iscsi_vol -snapshot kamini
-
Annulez la mise en veille du système de fichiers pour redémarrer les E/S.
[root@hc-cloud-secure-1 ~]# fsfreeze -u /file1
Cette option est utilisée pour annuler le gel du système de fichiers et permettre aux opérations de continuer. Toutes les modifications du système de fichiers bloquées par le gel sont débloqués et autorisées à se terminer.
Les copies Snapshot cohérentes au niveau des applications peuvent également être effectuées à l'aide de NetApp SnapCenter, qui dispose de l'orchestration complète du flux de travail décrit ci-dessus dans le cadre de SnapCenter. Pour plus d'informations, reportez-vous à la section "ici".
-
-
Effectuez une opération de mise à jour de SnapMirror pour maintenir la synchronisation des systèmes de production et de reprise après incident.
singlecvoaws::> snapmirror update -destination-path svm_singlecvoaws:hc_iscsi_vol_copy -source-path Healthcare_SVM:hc_iscsi_vol Operation is queued: snapmirror update of destination “svm_singlecvoaws:hc_iscsi_vol_copy”.
Une mise à jour de SnapMirror peut également être effectuée via l'interface graphique de la NetApp Console, sous l'onglet Réplication.
-
Créez une instance FlexClone à partir du snapshot d'application pris précédemment.
singlecvoaws::> volume clone create -flexclone kamini_clone -type RW -parent-vserver svm_singlecvoaws -parent-volume hc_iscsi_vol_copy -junction-active true -foreground true -parent-snapshot kamini [Job 996] Job succeeded: Successful
Pour la tâche précédente, un nouvel instantané peut également être créé, mais vous devez suivre les mêmes étapes que ci-dessus pour assurer la cohérence des applications.
-
Activez un volume FlexClone pour afficher l'instance EHR dans le cloud.
singlecvoaws::> lun mapping create -vserver svm_singlecvoaws -path /vol/kamini_clone/iscsi_lun1 -igroup ehr-igroup -lun-id 0 singlecvoaws::> lun mapping show Vserver Path Igroup LUN ID Protocol ---------- -------------- --------------- ----- -------- ------ --------- svm_singlecvoaws /vol/kamini_clone/iscsi_lun1 ehr-igroup 0 iscsi -
Exécuter les commandes suivantes sur l'instance EHR dans le cloud pour accéder aux données ou au système de fichiers.
-
Découvrez le stockage ONTAP. Vérifiez l'état des chemins d'accès multiples.
sudo rescan-scsi-bus.sh sudo iscsiadm -m discovery -t sendtargets -p <iscsi-lif-ip> sudo iscsiadm -m node -L all sudo sanlun lun show Output: controller(7mode/E-Series)/ device host lun vserver(cDOT/FlashRay) lun-pathname filename adapter protocol size product ----------------------------------------------------------------------------- svm_singlecvoaws /dev/sda host2 iSCSI 200g cDOT /vol/kamini_clone/iscsi_lun1 sudo multipath -ll Output: 3600a09806631755a452b543041313053 dm-0 NETAPP,LUN C-Mode size=200G features='3 queue_if_no_path pg_init_retries 50' hwhandler='1 alua' wp=rw `-+- policy='service-time 0' prio=50 status=active `- 2:0:0:0 sda 8:0 active ready running -
Activer le groupe de volumes.
sudo vgchange -ay datavg Output: 1 logical volume(s) in volume group "datavg" now active
-
Montez le système de fichiers et affichez le résumé des informations du système de fichiers.
sudo mount -t xfs /dev/datavg/datalv /file1 cd /file1 df -k . Output: Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/datavg-datalv 209608708 183987096 25621612 88% /file1
L'environnement de reprise d'activité est valide pour le développement et les tests d'applications. Les opérations de développement/test d'applications sur votre système de stockage de reprise après incident vous permettent d'exploiter davantage les ressources qui restent inactives la plupart du temps.
-
Reprise après incident
La technologie SnapMirror est également utilisée dans le cadre des plans de reprise d'activité. Si les données stratégiques sont répliquées vers un autre emplacement physique, un incident grave n'est pas nécessairement à l'origine de périodes prolongées d'indisponibilité des données pour les applications stratégiques. Les clients peuvent accéder aux données répliquées sur le réseau jusqu'à ce que le site de production soit corrompu, supprimé accidentellement, endommagé, etc.
En cas de restauration sur le site primaire, SnapMirror constitue un moyen efficace de resynchroniser le site de reprise d'activité avec le site primaire, en transférant uniquement les données nouvelles ou modifiées vers le site primaire à partir du site de reprise d'activité, simplement en inversant la relation SnapMirror. Une fois que le site de production principal a repris les opérations normales de l'application, SnapMirror poursuit le transfert vers le site de reprise après incident sans nécessiter un autre transfert de base.
Pour effectuer la validation d'un scénario DR réussi, procédez comme suit :
-
Simuler un incident côté source (production) en arrêtant le SVM qui héberge le volume ONTAP sur site (
hc_iscsi_vol).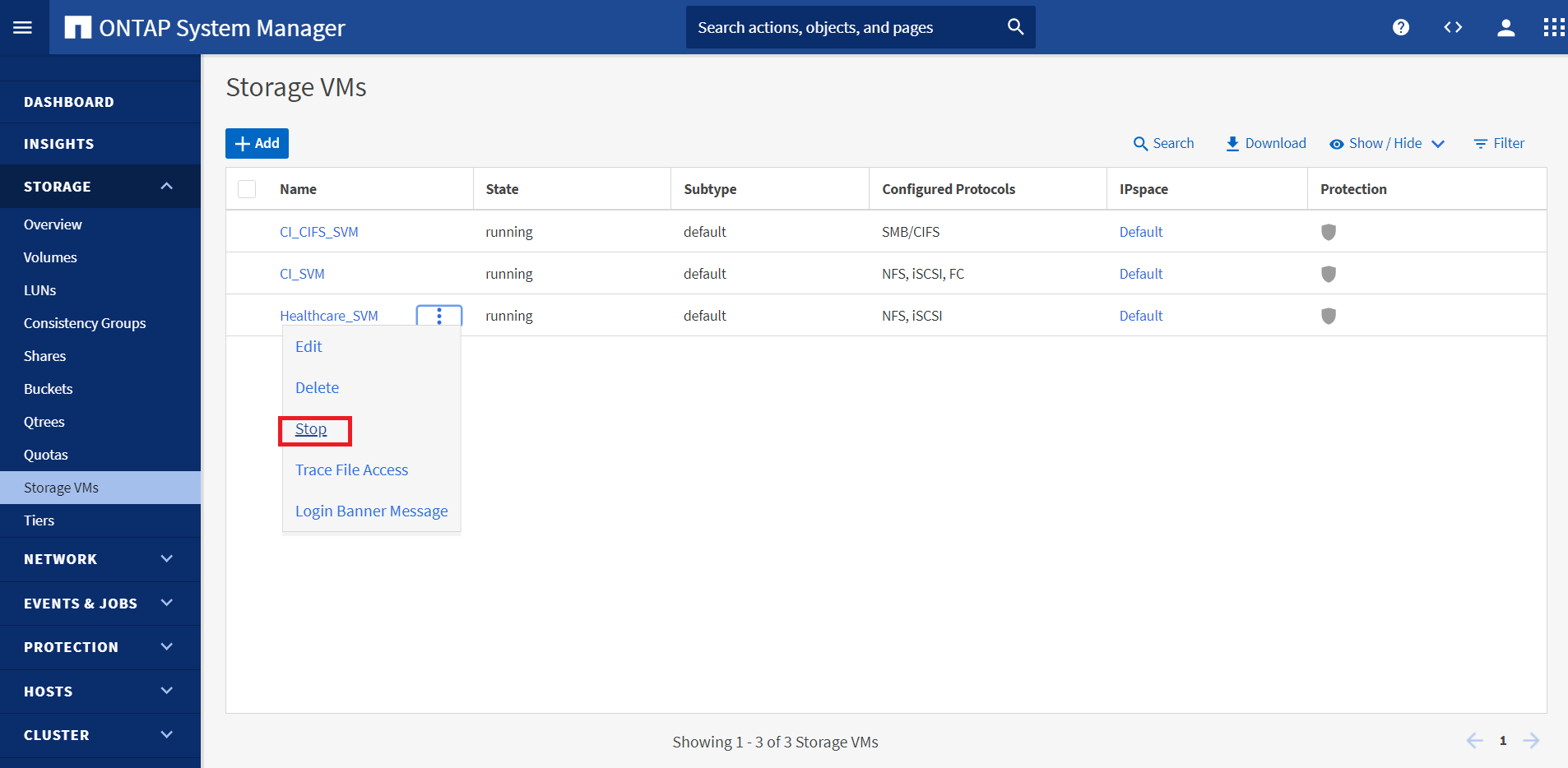
Assurez-vous que la réplication SnapMirror est déjà configurée entre l'ONTAP sur site dans l'instance FlexPod et Cloud Volumes ONTAP dans AWS, afin de pouvoir créer fréquemment des copies Snapshot d'application.
Une fois le SVM arrêté, le
hc_iscsi_volLe volume n'est pas visible dans la console. -
Activer la reprise sur incident dans CVO.
-
Rompez la relation de réplication SnapMirror entre ONTAP sur site et Cloud Volumes ONTAP et gérez le volume de destination CVO (
hc_iscsi_vol_copy) à la production.Une fois la relation SnapMirror rompue, le type de volume de destination passe de la protection des données (DP) à la lecture/écriture (RW).
singlecvoaws::> volume show -volume hc_iscsi_vol_copy -fields typev server volume type ---------------- ----------------- ---- svm_singlecvoaws hc_iscsi_vol_copy RW
-
Activez le volume de destination dans Cloud Volumes ONTAP pour afficher l'instance EHR sur une instance EC2 dans le cloud.
singlecvoaws::> lun mapping create -vserver svm_singlecvoaws -path /vol/hc_iscsi_vol_copy/iscsi_lun1 -igroup ehr-igroup -lun-id 0 singlecvoaws::> lun mapping show Vserver Path Igroup LUN ID Protocol ---------- ---------------------------------- -------- ------ --------- svm_singlecvoaws /vol/hc_iscsi_vol_copy/iscsi_lun1 ehr-igroup 0 iscsi -
Pour accéder aux données et au système de fichiers sur l'instance EHR dans le cloud, commencez par découvrir le stockage ONTAP et vérifiez l'état des chemins d'accès multiples.
sudo rescan-scsi-bus.sh sudo iscsiadm -m discovery -t sendtargets -p <iscsi-lif-ip> sudo iscsiadm -m node -L all sudo sanlun lun show Output: controller(7mode/E-Series)/ device host lun vserver(cDOT/FlashRay) lun-pathname filename adapter protocol size product ----------------------------------------------------------------------------- svm_singlecvoaws /dev/sda host2 iSCSI 200g cDOT /vol/hc_iscsi_vol_copy/iscsi_lun1 sudo multipath -ll Output: 3600a09806631755a452b543041313051 dm-0 NETAPP,LUN C-Mode size=200G features='3 queue_if_no_path pg_init_retries 50' hwhandler='1 alua' wp=rw `-+- policy='service-time 0' prio=50 status=active `- 2:0:0:0 sda 8:0 active ready running -
Activez ensuite le groupe de volumes.
sudo vgchange -ay datavg Output: 1 logical volume(s) in volume group "datavg" now active
-
Enfin, montez le système de fichiers et affichez les informations sur le système de fichiers.
sudo mount -t xfs /dev/datavg/datalv /file1 cd /file1 df -k . Output: Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/datavg-datalv 209608708 183987096 25621612 88% /file1
Ce résultat indique que les utilisateurs peuvent accéder aux données répliquées sur le réseau jusqu'à ce que le site de production soit récupéré après sinistre.
-
Inverser la relation SnapMirror. Cette opération inverse les rôles des volumes source et de destination.
Lorsque cette opération est effectuée, le contenu du volume source d'origine est écrasé par le contenu du volume de destination. Ceci est utile lorsque vous souhaitez réactiver un volume source hors ligne.
Désormais, le volume CVO (
hc_iscsi_vol_copy) devient le volume source et le volume sur site (hc_iscsi_vol) devient le volume de destination.
Toutes les données écrites sur le volume source d'origine entre la dernière réplication de données et l'heure à laquelle le volume source a été désactivé ne sont pas conservées.
-
Pour vérifier l'accès en écriture au volume CVO, créez un nouveau fichier sur l'instance EHR dans le cloud.
cd /file1/ sudo touch newfile
-
Lorsque le site de production est en panne, les clients peuvent toujours accéder aux données et effectuer des écritures sur le volume Cloud Volumes ONTAP, qui est désormais le volume source.
En cas de restauration sur le site primaire, SnapMirror constitue un moyen efficace de resynchroniser le site de reprise d'activité avec le site primaire, en transférant uniquement les données nouvelles ou modifiées vers le site primaire à partir du site de reprise d'activité, simplement en inversant la relation SnapMirror. Une fois que le site de production principal a repris les opérations normales de l'application, SnapMirror poursuit le transfert vers le site de reprise après incident sans nécessiter un autre transfert de base.
Cette section illustre la résolution d'un scénario de reprise après incident lorsque le site de production est touché par un incident. Les données peuvent désormais être consommées en toute sécurité par des applications qui peuvent désormais servir les clients pendant que le site source effectue une restauration.
Vérification des données sur le site de production
Une fois le site de production restauré, vous devez vous assurer que la configuration d'origine est restaurée et que les clients peuvent accéder aux données à partir du site source.
Dans cette section, nous abordons l'accès au site source et la restauration de la relation SnapMirror entre ONTAP sur site et Cloud Volumes ONTAP, puis nous avons enfin effectué un contrôle d'intégrité des données à l'extrémité source
La procédure suivante peut être utilisée pour la vérification des données sur le site de production :
-
Assurez-vous que le site source est maintenant en service. Pour ce faire, démarrer le SVM qui héberge le volume ONTAP sur site (
hc_iscsi_vol).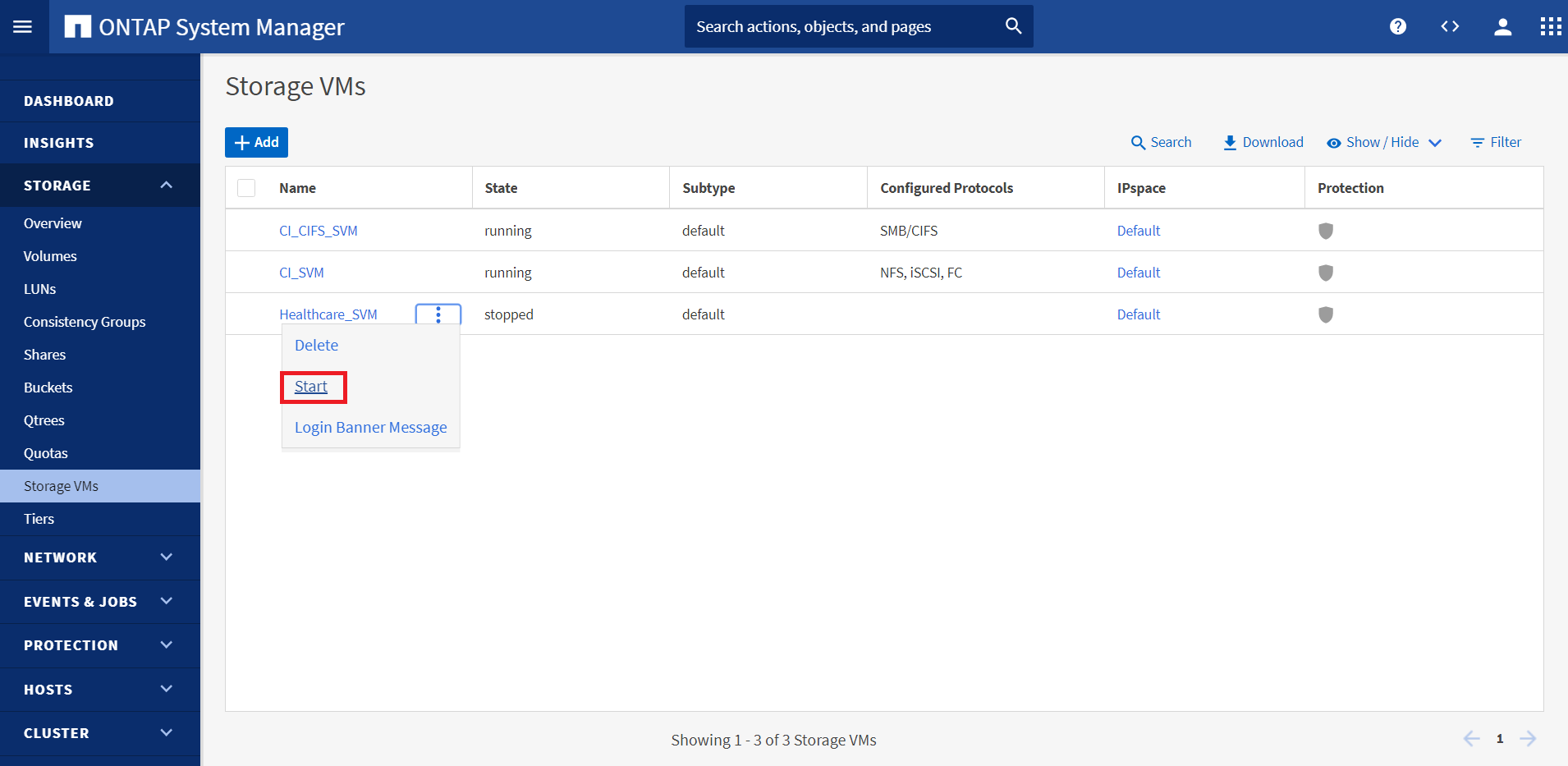
-
Rompre la relation de réplication SnapMirror entre Cloud Volumes ONTAP et ONTAP sur site et promouvoir le volume sur site (
hc_iscsi_vol) de retour à la production.Une fois la relation SnapMirror rompue, le type de volume sur site passe de la protection des données (DP) à la lecture/écriture (RW).
A400-G0312::> volume show -volume hc_iscsi_vol -fields type vserver volume type -------------- ------------ ---- Healthcare_SVM hc_iscsi_vol RW
-
Inverser la relation SnapMirror. Désormais, le volume ONTAP sur site (
hc_iscsi_vol) Devient le volume source tel qu'il était précédemment, et le volume Cloud Volumes ONTAP (hc_iscsi_vol_copy) devient le volume de destination.En suivant ces étapes, nous avons réussi à restaurer la configuration d'origine.
-
Redémarrez l'instance EHR sur site. Montez le système de fichiers et vérifiez que
newfileQue vous avez créé sur l'instance EHR dans le cloud lorsque la production a été hors service existe également dans ce domaine.
Nous pouvons déduire que la réplication des données de la source vers la destination a été effectuée avec succès et que l'intégrité des données a été préservée. La vérification des données sur le site de production est terminée.