Principaux cas d'utilisation et architectures de l'IA, du ML et du DL
 Suggérer des modifications
Suggérer des modifications
Les principaux cas d’utilisation et méthodologies de l’IA, du ML et du DL peuvent être divisés dans les sections suivantes :
Pipelines Spark NLP et inférence distribuée TensorFlow
La liste suivante contient les bibliothèques NLP open source les plus populaires qui ont été adoptées par la communauté des sciences des données à différents niveaux de développement :
-
"Boîte à outils en langage naturel (NLTK)" . La boîte à outils complète pour toutes les techniques PNL. Il est maintenu depuis le début des années 2000.
-
"TextBlob" . Une API Python d'outils NLP facile à utiliser construite sur NLTK et Pattern.
-
"Stanford Core PNL" . Services et packages NLP en Java développés par le Stanford NLP Group.
-
"Gensim" . Topic Modelling for Humans a commencé comme une collection de scripts Python pour le projet de bibliothèque numérique de mathématiques tchèque.
-
"SpaCy" . Workflows NLP industriels de bout en bout avec Python et Cython avec accélération GPU pour les transformateurs.
-
"Texte rapide" . Une bibliothèque NLP gratuite, légère et open source pour l'apprentissage des intégrations de mots et la classification des phrases créée par le laboratoire de recherche en IA (FAIR) de Facebook.
Spark NLP est une solution unique et unifiée pour toutes les tâches et exigences NLP qui permet de disposer de logiciels NLP évolutifs, hautes performances et haute précision pour des cas d'utilisation de production réels. Il s’appuie sur l’apprentissage par transfert et met en œuvre les algorithmes et modèles de pointe les plus récents dans la recherche et dans tous les secteurs. En raison du manque de support complet par Spark pour les bibliothèques ci-dessus, Spark NLP a été construit sur "Spark ML" pour tirer parti du moteur de traitement de données distribué en mémoire à usage général de Spark en tant que bibliothèque NLP de niveau entreprise pour les flux de travail de production critiques. Ses annotateurs utilisent des algorithmes basés sur des règles, l’apprentissage automatique et TensorFlow pour alimenter les implémentations d’apprentissage en profondeur. Cela couvre les tâches courantes de PNL, y compris, mais sans s'y limiter, la tokenisation, la lemmatisation, la dérivation, l'étiquetage des parties du discours, la reconnaissance d'entités nommées, la vérification orthographique et l'analyse des sentiments.
Les représentations d'encodeurs bidirectionnels à partir de transformateurs (BERT) sont une technique d'apprentissage automatique basée sur des transformateurs pour le PNL. Il a popularisé le concept de pré-entraînement et de réglage fin. L'architecture du transformateur dans BERT est issue de la traduction automatique, qui modélise mieux les dépendances à long terme que les modèles de langage basés sur le réseau neuronal récurrent (RNN). Il a également introduit la tâche de modélisation du langage masqué (MLM), où 15 % aléatoires de tous les jetons sont masqués et le modèle les prédit, permettant une véritable bidirectionnalité.
L’analyse du sentiment financier est difficile en raison du langage spécialisé et du manque de données étiquetées dans ce domaine. FinBERT, un modèle de langage basé sur BERT pré-entraîné, a été adapté au domaine "Reuters TRC2" , un corpus financier, et affiné avec des données étiquetées ( "Banque de phrases financières" ) pour la classification du sentiment financier. Les chercheurs ont extrait 4 500 phrases d’articles de presse contenant des termes financiers. Ensuite, 16 experts et étudiants en master ayant une formation en finance ont étiqueté les phrases comme positives, neutres et négatives. Nous avons créé un flux de travail Spark de bout en bout pour analyser le sentiment des 10 premières sociétés du NASDAQ dans leurs transcriptions d'appels sur les résultats de 2016 à 2020, en utilisant FinBERT et deux autres pipelines pré-entraînés. "Expliquer le document DL" ) de Spark NLP.
Le moteur d'apprentissage profond sous-jacent de Spark NLP est TensorFlow, une plate-forme open source de bout en bout pour l'apprentissage automatique qui permet une création de modèles facile, une production ML robuste n'importe où et une expérimentation puissante pour la recherche. Par conséquent, lors de l'exécution de nos pipelines dans Spark yarn cluster En mode, nous exécutions essentiellement TensorFlow distribué avec parallélisation des données et des modèles sur un maître et plusieurs nœuds de travail, ainsi qu'un stockage en réseau monté sur le cluster.
Formation distribuée Horovod
La validation Hadoop principale pour les performances liées à MapReduce est effectuée avec TeraGen, TeraSort, TeraValidate et DFSIO (lecture et écriture). Les résultats de validation de TeraGen et TeraSort sont présentés dans "Solution NetApp E-Series pour Hadoop" et dans la section « Storage Tiering » pour AFF.
Sur la base des demandes des clients, nous considérons la formation distribuée avec Spark comme l’un des cas d’utilisation les plus importants. Dans ce document, nous avons utilisé le "Hovorod sur Spark" pour valider les performances de Spark avec les solutions NetApp sur site, cloud natives et cloud hybrides à l'aide des contrôleurs de stockage NetApp All Flash FAS (AFF), Azure NetApp Files et StorageGRID.
Le package Horovod sur Spark fournit un wrapper pratique autour de Horovod qui simplifie l'exécution de charges de travail de formation distribuées dans les clusters Spark, permettant une boucle de conception de modèle étroite dans laquelle le traitement des données, la formation du modèle et l'évaluation du modèle sont tous effectués dans Spark où résident les données de formation et d'inférence.
Il existe deux API pour exécuter Horovod sur Spark : une API Estimator de haut niveau et une API Run de niveau inférieur. Bien que les deux utilisent le même mécanisme sous-jacent pour lancer Horovod sur les exécuteurs Spark, l'API Estimator fait abstraction du traitement des données, de la boucle de formation du modèle, du point de contrôle du modèle, de la collecte de métriques et de la formation distribuée. Nous avons utilisé Horovod Spark Estimators, TensorFlow et Keras pour une préparation de données de bout en bout et un flux de travail de formation distribué basé sur le "Ventes en magasin Kaggle Rossmann" concours.
Le scénario keras_spark_horovod_rossmann_estimator.py peut être trouvé dans la section"Scripts Python pour chaque cas d'utilisation majeur." Il contient trois parties :
-
La première partie effectue diverses étapes de prétraitement des données sur un ensemble initial de fichiers CSV fournis par Kaggle et collectés par la communauté. Les données d'entrée sont séparées dans un ensemble d'apprentissage avec un
Validationsous-ensemble et un ensemble de données de test. -
La deuxième partie définit un modèle Keras Deep Neural Network (DNN) avec une fonction d'activation sigmoïde logarithmique et un optimiseur Adam, et effectue une formation distribuée du modèle à l'aide d'Horovod sur Spark.
-
La troisième partie effectue une prédiction sur l'ensemble de données de test en utilisant le meilleur modèle qui minimise l'erreur absolue moyenne globale de l'ensemble de validation. Il crée ensuite un fichier CSV de sortie.
Voir la section"Apprentissage automatique" pour divers résultats de comparaison d'exécution.
Apprentissage profond multi-travailleurs utilisant Keras pour la prédiction du CTR
Avec les avancées récentes des plateformes et applications ML, une grande attention est désormais portée à l’apprentissage à grande échelle. Le taux de clics (CTR) est défini comme le nombre moyen de clics pour cent impressions d'annonces en ligne (exprimé en pourcentage). Il est largement adopté comme indicateur clé dans divers secteurs d’activité et cas d’utilisation, notamment le marketing numérique, la vente au détail, le commerce électronique et les fournisseurs de services. Pour plus de détails sur les applications du CTR et les résultats de performance de formation distribuée, consultez le"Modèles d'apprentissage profond pour les performances de prédiction du CTR" section.
Dans ce rapport technique, nous avons utilisé une variante de la "Ensemble de données Criteo Terabyte Click Logs" (voir TR-4904) pour l'apprentissage en profondeur distribué multi-travailleurs utilisant Keras pour créer un flux de travail Spark avec des modèles Deep and Cross Network (DCN), en comparant ses performances en termes de fonction d'erreur de perte de journal avec un modèle de régression logistique Spark ML de base. DCN capture efficacement les interactions de caractéristiques efficaces de degrés limités, apprend les interactions hautement non linéaires, ne nécessite aucune ingénierie de caractéristiques manuelle ni recherche exhaustive et présente un faible coût de calcul.
Les données des systèmes de recommandation à l'échelle du Web sont pour la plupart discrètes et catégoriques, ce qui conduit à un espace de fonctionnalités vaste et clairsemé qui rend difficile l'exploration des fonctionnalités. Cela a limité la plupart des systèmes à grande échelle à des modèles linéaires tels que la régression logistique. Cependant, identifier fréquemment des caractéristiques prédictives et explorer simultanément des caractéristiques croisées invisibles ou rares est la clé pour faire de bonnes prédictions. Les modèles linéaires sont simples, interprétables et faciles à mettre à l’échelle, mais leur pouvoir d’expression est limité.
Les caractéristiques croisées, en revanche, se sont avérées significatives pour améliorer l'expressivité des modèles. Malheureusement, il faut souvent procéder à une ingénierie manuelle des fonctionnalités ou à une recherche exhaustive pour identifier ces fonctionnalités. Il est souvent difficile de généraliser aux interactions entre fonctionnalités invisibles. L'utilisation d'un réseau neuronal croisé comme DCN évite l'ingénierie des fonctionnalités spécifiques à la tâche en appliquant explicitement le croisement des fonctionnalités de manière automatique. Le réseau croisé est constitué de plusieurs couches, où le degré d'interaction le plus élevé est déterminé de manière prouvable par la profondeur de la couche. Chaque couche produit des interactions d’ordre supérieur basées sur celles existantes et conserve les interactions des couches précédentes.
Un réseau neuronal profond (DNN) promet de capturer des interactions très complexes entre les fonctionnalités. Cependant, comparé au DCN, il nécessite près d'un ordre de grandeur de paramètres supplémentaires, est incapable de former explicitement des fonctionnalités croisées et peut ne pas réussir à apprendre efficacement certains types d'interactions de fonctionnalités. Le réseau croisé est efficace en termes de mémoire et facile à mettre en œuvre. L'entraînement conjoint des composants croisés et DNN capture efficacement les interactions des fonctionnalités prédictives et offre des performances de pointe sur l'ensemble de données Criteo CTR.
Un modèle DCN commence par une couche d'intégration et d'empilement, suivie d'un réseau croisé et d'un réseau profond en parallèle. Celles-ci sont à leur tour suivies d'une couche de combinaison finale qui combine les sorties des deux réseaux. Vos données d’entrée peuvent être un vecteur avec des caractéristiques clairsemées et denses. Dans Spark, les bibliothèques contiennent le type SparseVector . Il est donc important pour les utilisateurs de faire la distinction entre les deux et d’être attentifs lorsqu’ils appellent leurs fonctions et méthodes respectives. Dans les systèmes de recommandation à l'échelle du Web tels que la prédiction du CTR, les entrées sont principalement des caractéristiques catégorielles, par exemple 'country=usa' . Ces caractéristiques sont souvent codées sous forme de vecteurs one-hot, par exemple, '[0,1,0, …]' . Encodage à chaud (OHE) avec SparseVector est utile lorsqu'il s'agit de traiter des ensembles de données du monde réel avec des vocabulaires en constante évolution et en croissance. Nous avons modifié des exemples dans "DeepCTR" pour traiter de grands vocabulaires, en créant des vecteurs d'intégration dans la couche d'intégration et d'empilement de notre DCN.
Le "Ensemble de données Criteo Display Ads" prédit le taux de clics des publicités. Il comporte 13 caractéristiques entières et 26 caractéristiques catégorielles dans lesquelles chaque catégorie a une cardinalité élevée. Pour cet ensemble de données, une amélioration de 0,001 de la perte logarithmique est pratiquement significative en raison de la grande taille d’entrée. Une petite amélioration de la précision des prédictions pour une large base d’utilisateurs peut potentiellement conduire à une augmentation importante des revenus d’une entreprise. L'ensemble de données contient 11 Go de journaux d'utilisateurs sur une période de 7 jours, ce qui équivaut à environ 41 millions d'enregistrements. Nous avons utilisé Spark dataFrame.randomSplit()function pour diviser aléatoirement les données pour la formation (80 %), la validation croisée (10 %) et les 10 % restants pour les tests.
DCN a été implémenté sur TensorFlow avec Keras. La mise en œuvre du processus de formation du modèle avec DCN comporte quatre composants principaux :
-
Traitement et intégration des données. Les fonctionnalités à valeur réelle sont normalisées en appliquant une transformation logarithmique. Pour les fonctionnalités catégorielles, nous intégrons les fonctionnalités dans des vecteurs denses de dimension 6×(cardinalité de catégorie)1/4. La concaténation de tous les plongements donne un vecteur de dimension 1026.
-
Optimisation. Nous avons appliqué l’optimisation stochastique par mini-lots avec l’optimiseur Adam. La taille du lot a été définie sur 512. La normalisation par lots a été appliquée au réseau profond et la norme de clip de gradient a été fixée à 100.
-
Régularisation. Nous avons utilisé l'arrêt précoce, car la régularisation ou l'abandon de L2 ne s'est pas avéré efficace.
-
Hyperparamètres. Nous rapportons les résultats basés sur une recherche de grille sur le nombre de couches cachées, la taille de la couche cachée, le taux d'apprentissage initial et le nombre de couches croisées. Le nombre de couches cachées variait de 2 à 5, avec des tailles de couches cachées allant de 32 à 1024. Pour le DCN, le nombre de couches croisées était de 1 à 6. Le taux d’apprentissage initial a été réglé de 0,0001 à 0,001 avec des incréments de 0,0001. Toutes les expériences ont appliqué un arrêt précoce à l'étape d'entraînement 150 000, au-delà de laquelle un surapprentissage a commencé à se produire.
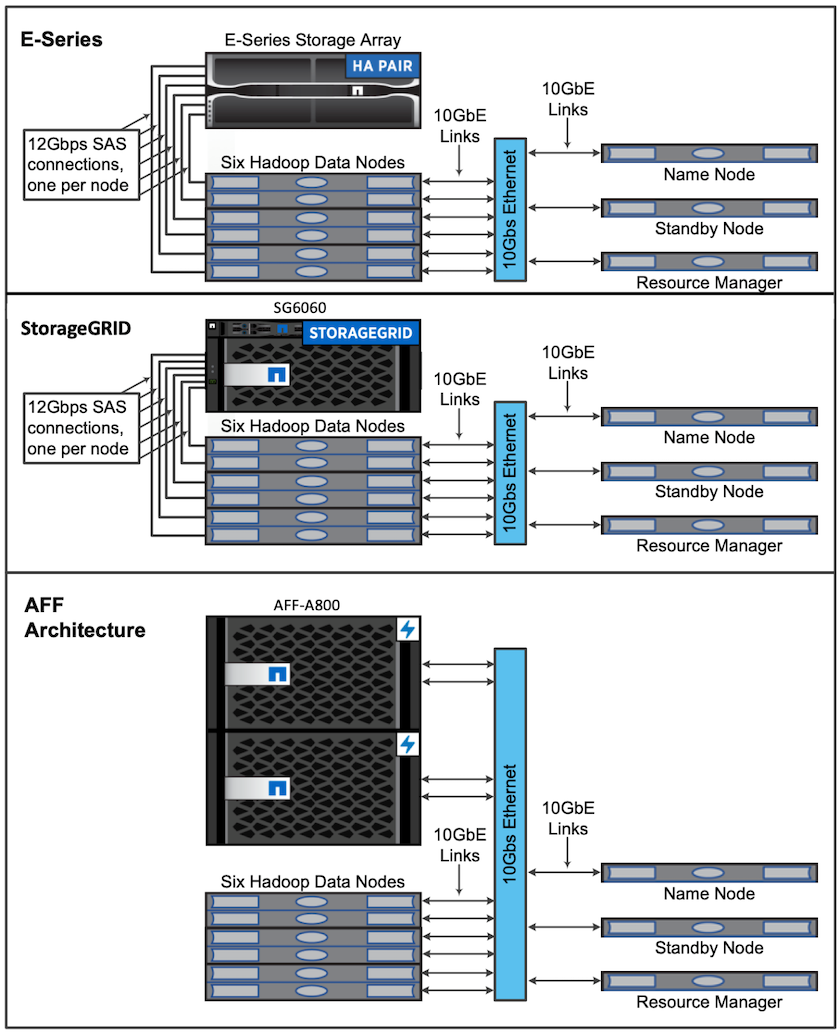
Architectures utilisées pour la validation
Pour cette validation, nous avons utilisé quatre nœuds de travail et un nœud maître avec une paire AFF-A800 HA. Tous les membres du cluster étaient connectés via des commutateurs réseau 10 GbE.
Pour cette validation de solution NetApp Spark, nous avons utilisé trois contrôleurs de stockage différents : le E5760, le E5724 et le AFF-A800. Les contrôleurs de stockage de la série E étaient connectés à cinq nœuds de données avec des connexions SAS 12 Gbit/s. Le contrôleur de stockage AFF HA-pair fournit des volumes NFS exportés via des connexions 10 GbE aux nœuds de travail Hadoop. Les membres du cluster Hadoop étaient connectés via des connexions 10 GbE dans les solutions Hadoop E-Series, AFF et StorageGRID .