

Hiérarchisation intelligente et économies de coûts
 Suggérer des modifications
Suggérer des modifications
À mesure que les clients réalisent la puissance et la facilité d’utilisation de l’analyse de données Splunk, ils souhaitent naturellement indexer une quantité toujours croissante de données. À mesure que la quantité de données augmente, l’infrastructure de calcul et de stockage nécessaire pour les gérer augmente également. Étant donné que les données plus anciennes sont référencées moins fréquemment, engager la même quantité de ressources de calcul et consommer un stockage primaire coûteux devient de plus en plus inefficace. Pour fonctionner à grande échelle, les clients bénéficient du déplacement des données chaudes vers un niveau plus rentable, libérant ainsi du calcul et du stockage principal pour les données chaudes.
Splunk SmartStore avec StorageGRID offre aux organisations une solution évolutive, performante et rentable. Étant donné que SmartStore est sensible aux données, il évalue automatiquement les modèles d'accès aux données pour déterminer quelles données doivent être accessibles pour l'analyse en temps réel (données chaudes) et quelles données doivent résider dans un stockage à long terme à moindre coût (données chaudes). SmartStore utilise l'API AWS S3 standard de l'industrie de manière dynamique et intelligente, en plaçant les données dans le stockage S3 fourni par StorageGRID. L'architecture évolutive flexible de StorageGRID permet au niveau de données chaudes de croître de manière rentable selon les besoins. L'architecture basée sur les nœuds de StorageGRID garantit que les exigences de performances et de coûts sont satisfaites de manière optimale.
L'image suivante illustre la hiérarchisation de Splunk et StorageGRID .
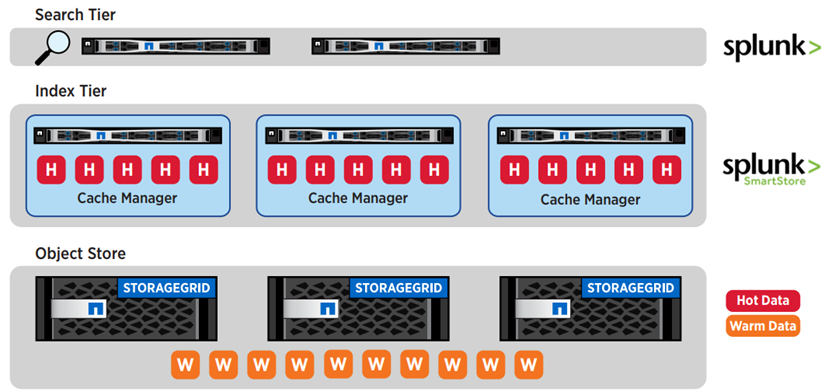
La combinaison leader du secteur de Splunk SmartStore avec NetApp StorageGRID offre les avantages d'une architecture découplée via une solution complète.