

Protection de la base de données vectorielle à l'aide de SnapCenter
 Suggérer des modifications
Suggérer des modifications
Cette section décrit comment assurer la protection des données pour la base de données vectorielle à l'aide de NetApp SnapCenter.
Protection de base de données vectorielle à l'aide de NetApp SnapCenter.
Par exemple, dans l’industrie de la production cinématographique, les clients possèdent souvent des données intégrées critiques telles que des fichiers vidéo et audio. La perte de ces données, due à des problèmes tels que des pannes de disque dur, peut avoir un impact significatif sur leurs opérations, mettant potentiellement en péril des entreprises de plusieurs millions de dollars. Nous avons rencontré des cas où un contenu inestimable a été perdu, entraînant des perturbations et des pertes financières importantes. Assurer la sécurité et l’intégrité de ces données essentielles est donc d’une importance primordiale dans ce secteur. Dans cette section, nous examinons comment SnapCenter protège les données de la base de données vectorielle et les données Milvus résidant dans ONTAP. Pour cet exemple, nous avons utilisé un bucket NAS (milvusdbvol1) dérivé d'un volume NFS ONTAP (vol1) pour les données client et un volume NFS distinct (vectordbpv) pour les données de configuration du cluster Milvus. Veuillez vérifier le"ici" pour le flux de travail de sauvegarde Snapcenter
-
Configurez l’hôte qui sera utilisé pour exécuter les commandes SnapCenter .
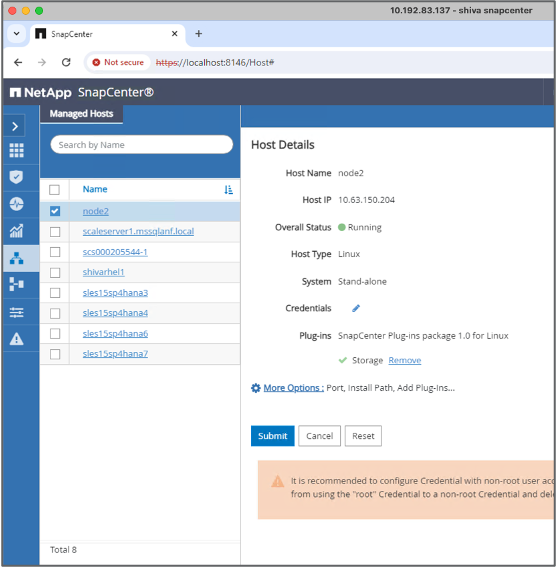
-
Installez et configurez le plugin de stockage. À partir de l'hôte ajouté, sélectionnez « Plus d'options ». Accédez au plugin de stockage téléchargé et sélectionnez-le dans le"Boutique d'automatisation NetApp" . Installez le plugin et enregistrez la configuration.
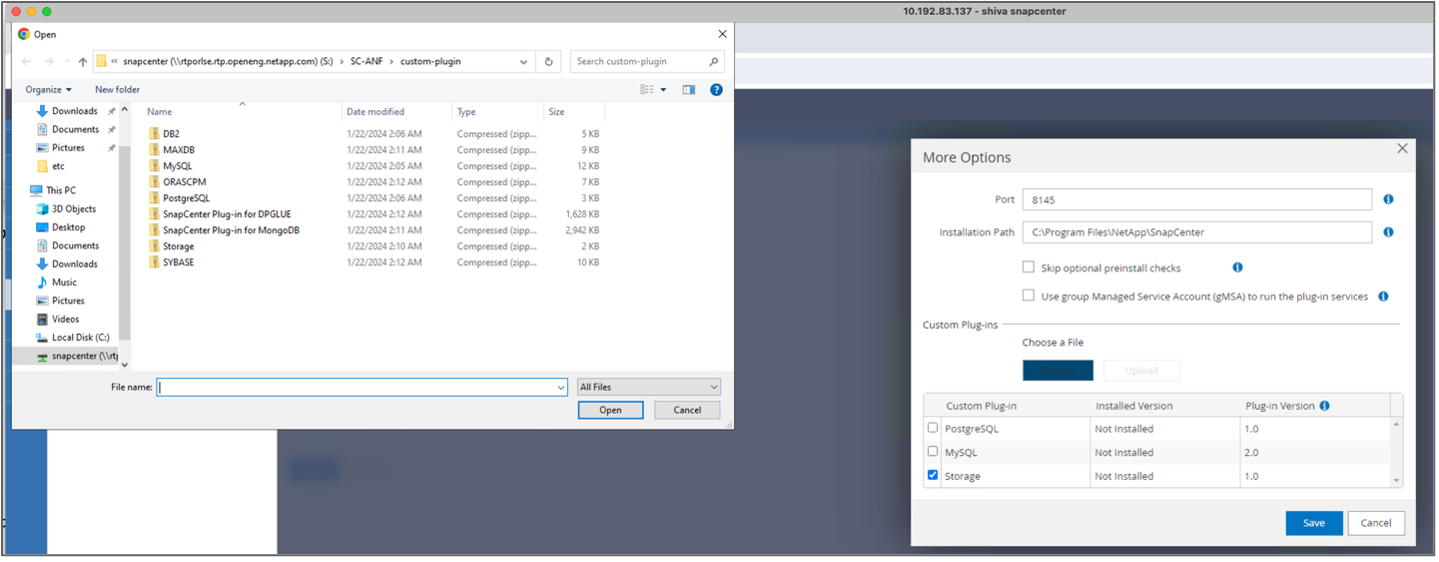
-
Configurer le système de stockage et le volume : ajoutez le système de stockage sous « Système de stockage » et sélectionnez la SVM (machine virtuelle de stockage). Dans cet exemple, nous avons choisi « vs_nvidia ».
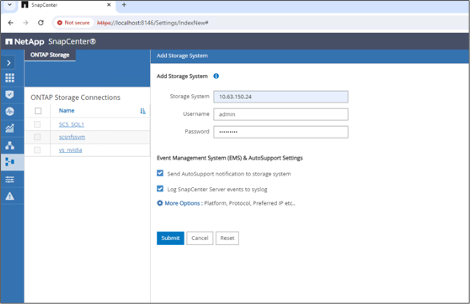
-
Établissez une ressource pour la base de données vectorielle, en intégrant une politique de sauvegarde et un nom d’instantané personnalisé.
-
Activez la sauvegarde du groupe de cohérence avec les valeurs par défaut et activez SnapCenter sans cohérence du système de fichiers.
-
Dans la section Empreinte de stockage, sélectionnez les volumes associés aux données client de la base de données vectorielle et aux données du cluster Milvus. Dans notre exemple, il s'agit de « vol1 » et « vectordbpv ».
-
Créez une politique de protection de la base de données vectorielle et protégez les ressources de la base de données vectorielle à l'aide de la politique.
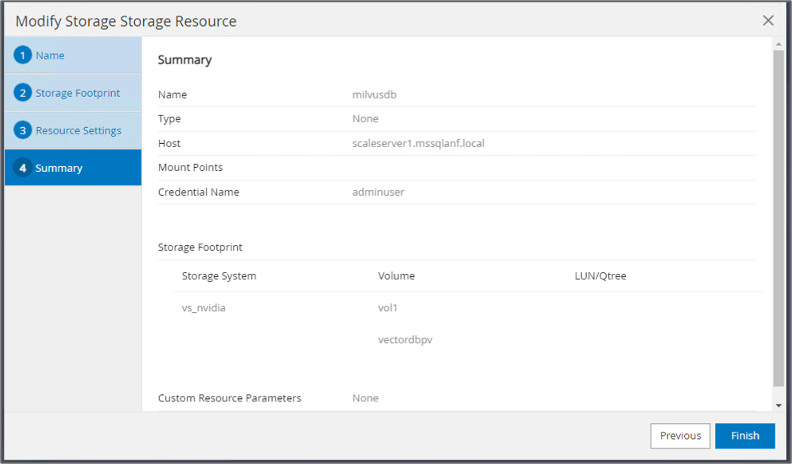
-
-
Insérez des données dans le bucket NAS S3 à l’aide d’un script Python. Dans notre cas, nous avons modifié le script de sauvegarde fourni par Milvus, à savoir « prepare_data_netapp.py », et exécuté la commande « sync » pour vider les données du système d'exploitation.
root@node2:~# python3 prepare_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_test exist in Milvus: False === Create collection `hello_milvus_netapp_sc_test` === === Start inserting entities === Number of entities in hello_milvus_netapp_sc_test: 3000 === Create collection `hello_milvus_netapp_sc_test2` === Number of entities in hello_milvus_netapp_sc_test2: 6000 root@node2:~# for i in 2 3 4 5 6 ; do ssh node$i "hostname; sync; echo 'sync executed';" ; done node2 sync executed node3 sync executed node4 sync executed node5 sync executed node6 sync executed root@node2:~# -
Vérifiez les données dans le bucket NAS S3. Dans notre exemple, les fichiers avec l'horodatage « 2024-04-08 21:22 » ont été créés par le script « prepare_data_netapp.py ».
root@node2:~# aws s3 ls --profile ontaps3 s3://milvusdbvol1/ --recursive | grep '2024-04-08' <output content removed to save page space> 2024-04-08 21:18:14 5656 stats_log/448950615991000809/448950615991000810/448950615991001854/100/1 2024-04-08 21:18:12 5654 stats_log/448950615991000809/448950615991000810/448950615991001854/100/448950615990800869 2024-04-08 21:18:17 5656 stats_log/448950615991000809/448950615991000810/448950615991001872/100/1 2024-04-08 21:18:15 5654 stats_log/448950615991000809/448950615991000810/448950615991001872/100/448950615990800876 2024-04-08 21:22:46 5625 stats_log/448950615991003377/448950615991003378/448950615991003385/100/1 2024-04-08 21:22:45 5623 stats_log/448950615991003377/448950615991003378/448950615991003385/100/448950615990800899 2024-04-08 21:22:49 5656 stats_log/448950615991003408/448950615991003409/448950615991003416/100/1 2024-04-08 21:22:47 5654 stats_log/448950615991003408/448950615991003409/448950615991003416/100/448950615990800906 2024-04-08 21:22:52 5656 stats_log/448950615991003408/448950615991003409/448950615991003434/100/1 2024-04-08 21:22:50 5654 stats_log/448950615991003408/448950615991003409/448950615991003434/100/448950615990800913 root@node2:~# -
Lancer une sauvegarde à l'aide de l'instantané du groupe de cohérence (CG) à partir de la ressource « milvusdb »
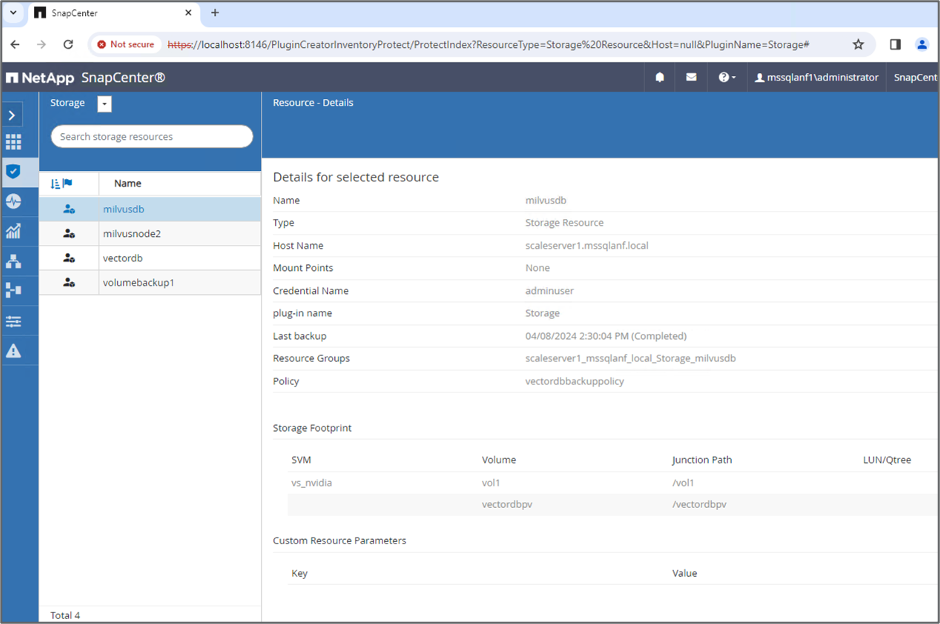
-
Pour tester la fonctionnalité de sauvegarde, nous avons soit ajouté une nouvelle table après le processus de sauvegarde, soit supprimé certaines données du NFS (bucket NAS S3).
Pour ce test, imaginez un scénario dans lequel quelqu’un a créé une nouvelle collection inutile ou inappropriée après la sauvegarde. Dans un tel cas, nous devrions rétablir la base de données vectorielle à son état antérieur à l’ajout de la nouvelle collection. Par exemple, de nouvelles collections telles que « hello_milvus_netapp_sc_testnew » et « hello_milvus_netapp_sc_testnew2 » ont été insérées.
root@node2:~# python3 prepare_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_testnew exist in Milvus: False === Create collection `hello_milvus_netapp_sc_testnew` === === Start inserting entities === Number of entities in hello_milvus_netapp_sc_testnew: 3000 === Create collection `hello_milvus_netapp_sc_testnew2` === Number of entities in hello_milvus_netapp_sc_testnew2: 6000 root@node2:~# -
Exécutez une restauration complète du bucket NAS S3 à partir de l’instantané précédent.
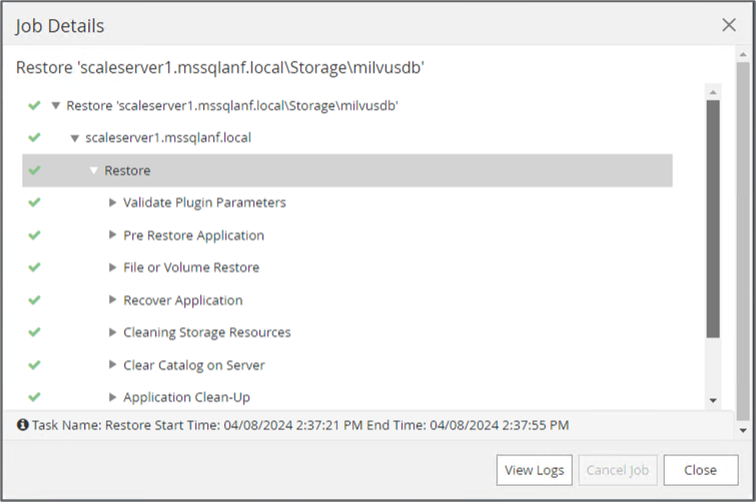
-
Utilisez un script Python pour vérifier les données des collections « hello_milvus_netapp_sc_test » et « hello_milvus_netapp_sc_test2 ».
root@node2:~# python3 verify_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_test exist in Milvus: True {'auto_id': False, 'description': 'hello_milvus_netapp_sc_test', 'fields': [{'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': False}, {'name': 'random', 'description': '', 'type': <DataType.DOUBLE: 11>}, {'name': 'var', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}, {'name': 'embeddings', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 8}}]} Number of entities in Milvus: hello_milvus_netapp_sc_test : 3000 === Start Creating index IVF_FLAT === === Start loading === === Start searching based on vector similarity === hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911 hit: id: 1262, distance: 0.08883658051490784, entity: {'random': 0.2978858685751561}, random field: 0.2978858685751561 hit: id: 1265, distance: 0.09590047597885132, entity: {'random': 0.3042039939240304}, random field: 0.3042039939240304 hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482 hit: id: 1580, distance: 0.05628091096878052, entity: {'random': 0.3855988746044062}, random field: 0.3855988746044062 hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368 search latency = 0.2832s === Start querying with `random > 0.5` === query result: -{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': 0} search latency = 0.2257s === Start hybrid searching with `random > 0.5` === hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911 hit: id: 747, distance: 0.14606499671936035, entity: {'random': 0.5648774800635661}, random field: 0.5648774800635661 hit: id: 2527, distance: 0.1530652642250061, entity: {'random': 0.8928974315571507}, random field: 0.8928974315571507 hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368 hit: id: 2034, distance: 0.20354536175727844, entity: {'random': 0.5526117606328499}, random field: 0.5526117606328499 hit: id: 958, distance: 0.21908017992973328, entity: {'random': 0.6647383716417955}, random field: 0.6647383716417955 search latency = 0.5480s Does collection hello_milvus_netapp_sc_test2 exist in Milvus: True {'auto_id': True, 'description': 'hello_milvus_netapp_sc_test2', 'fields': [{'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'random', 'description': '', 'type': <DataType.DOUBLE: 11>}, {'name': 'var', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}, {'name': 'embeddings', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 8}}]} Number of entities in Milvus: hello_milvus_netapp_sc_test2 : 6000 === Start Creating index IVF_FLAT === === Start loading === === Start searching based on vector similarity === hit: id: 448950615990642008, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990645009, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990640618, distance: 0.13562293350696564, entity: {'random': 0.7864676926688837}, random field: 0.7864676926688837 hit: id: 448950615990642314, distance: 0.10414951294660568, entity: {'random': 0.2209597460821181}, random field: 0.2209597460821181 hit: id: 448950615990645315, distance: 0.10414951294660568, entity: {'random': 0.2209597460821181}, random field: 0.2209597460821181 hit: id: 448950615990640004, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 search latency = 0.2381s === Start querying with `random > 0.5` === query result: -{'embeddings': [0.15983285, 0.72214717, 0.7414838, 0.44471496, 0.50356466, 0.8750043, 0.316556, 0.7871702], 'pk': 448950615990639798, 'random': 0.7820620141382767} search latency = 0.3106s === Start hybrid searching with `random > 0.5` === hit: id: 448950615990642008, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990645009, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990640618, distance: 0.13562293350696564, entity: {'random': 0.7864676926688837}, random field: 0.7864676926688837 hit: id: 448950615990640004, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 hit: id: 448950615990643005, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 hit: id: 448950615990640402, distance: 0.13665105402469635, entity: {'random': 0.9742541034109935}, random field: 0.9742541034109935 search latency = 0.4906s root@node2:~# -
Vérifiez que la collection inutile ou inappropriée n'est plus présente dans la base de données.
root@node2:~# python3 verify_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_testnew exist in Milvus: False Traceback (most recent call last): File "/root/verify_data_netapp.py", line 37, in <module> recover_collection = Collection(recover_collection_name) File "/usr/local/lib/python3.10/dist-packages/pymilvus/orm/collection.py", line 137, in __init__ raise SchemaNotReadyException( pymilvus.exceptions.SchemaNotReadyException: <SchemaNotReadyException: (code=1, message=Collection 'hello_milvus_netapp_sc_testnew' not exist, or you can pass in schema to create one.)> root@node2:~#
En conclusion, l'utilisation de SnapCenter de NetApp pour protéger les données de bases de données vectorielles et les données Milvus résidant dans ONTAP offre des avantages significatifs aux clients, en particulier dans les secteurs où l'intégrité des données est primordiale, comme la production cinématographique. La capacité de SnapCenter à créer des sauvegardes cohérentes et à effectuer des restaurations complètes des données garantit que les données critiques, telles que les fichiers vidéo et audio intégrés, sont protégées contre les pertes dues à des pannes de disque dur ou à d'autres problèmes. Cela permet non seulement d’éviter les perturbations opérationnelles, mais également de se prémunir contre des pertes financières importantes.
Dans cette section, nous avons démontré comment SnapCenter peut être configuré pour protéger les données résidant dans ONTAP, y compris la configuration des hôtes, l'installation et la configuration des plugins de stockage et la création d'une ressource pour la base de données vectorielle avec un nom d'instantané personnalisé. Nous avons également montré comment effectuer une sauvegarde à l’aide de l’instantané du groupe de cohérence et vérifier les données dans le bucket NAS S3.
De plus, nous avons simulé un scénario dans lequel une collection inutile ou inappropriée a été créée après la sauvegarde. Dans de tels cas, la capacité de SnapCenter à effectuer une restauration complète à partir d'un instantané précédent garantit que la base de données vectorielle peut être rétablie à son état avant l'ajout de la nouvelle collection, préservant ainsi l'intégrité de la base de données. Cette capacité à restaurer des données à un moment précis est inestimable pour les clients, leur offrant l’assurance que leurs données sont non seulement sécurisées mais également correctement conservées. Ainsi, le produit SnapCenter de NetApp offre aux clients une solution robuste et fiable pour la protection et la gestion des données.