

Validation des performances de la base de données vectorielle
 Suggérer des modifications
Suggérer des modifications
Cette section met en évidence la validation des performances qui a été effectuée sur la base de données vectorielles.
Validation des performances
La validation des performances joue un rôle essentiel dans les bases de données vectorielles et les systèmes de stockage, servant de facteur clé pour garantir un fonctionnement optimal et une utilisation efficace des ressources. Les bases de données vectorielles, connues pour gérer des données de grande dimension et exécuter des recherches de similarité, doivent maintenir des niveaux de performances élevés pour traiter des requêtes complexes rapidement et avec précision. La validation des performances permet d’identifier les goulots d’étranglement, d’affiner les configurations et de garantir que le système peut gérer les charges attendues sans dégradation du service. De même, dans les systèmes de stockage, la validation des performances est essentielle pour garantir que les données sont stockées et récupérées efficacement, sans problèmes de latence ni goulots d’étranglement susceptibles d’avoir un impact sur les performances globales du système. Il permet également de prendre des décisions éclairées sur les mises à niveau ou les modifications nécessaires à l’infrastructure de stockage. Par conséquent, la validation des performances est un aspect crucial de la gestion du système, contribuant de manière significative au maintien d’une qualité de service élevée, de l’efficacité opérationnelle et de la fiabilité globale du système.
Dans cette section, nous visons à approfondir la validation des performances des bases de données vectorielles, telles que Milvus et pgvecto.rs, en nous concentrant sur leurs caractéristiques de performances de stockage telles que le profil d'E/S et le comportement du contrôleur de stockage NetApp à la prise en charge des charges de travail RAG et d'inférence au sein du cycle de vie LLM. Nous évaluerons et identifierons les différenciateurs de performances lorsque ces bases de données seront combinées avec la solution de stockage ONTAP . Notre analyse sera basée sur des indicateurs de performance clés, tels que le nombre de requêtes traitées par seconde (QPS).
Veuillez consulter la méthodologie utilisée pour milvus et les progrès ci-dessous.
Détails |
Milvus (autonome et cluster) |
Postgres(pgvecto.rs) # |
version |
2.3.2 |
0.2.0 |
Système de fichiers |
XFS sur les LUN iSCSI |
|
Générateur de charge de travail |
"VectorDB-Bench"– v0.0.5 |
|
Ensembles de données |
Ensemble de données LAION * 10 millions d'intégrations * 768 dimensions * Taille de l'ensemble de données d'environ 300 Go |
|
Contrôleur de stockage |
AFF 800 * Version – 9.14.1 * 4 x 100GbE – pour milvus et 2x 100GbE pour postgres * iscsi |
VectorDB-Bench avec cluster autonome Milvus
nous avons effectué la validation des performances suivante sur le cluster autonome milvus avec vectorDB-Bench. La connectivité réseau et serveur du cluster autonome milvus est ci-dessous.
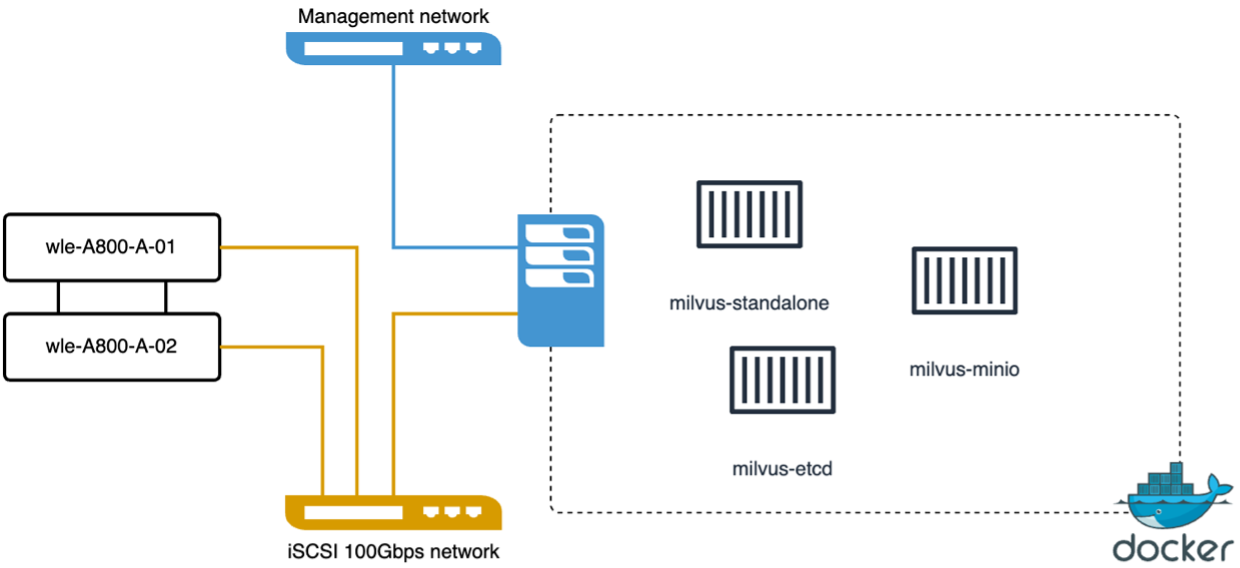
Dans cette section, nous partageons nos observations et résultats des tests de la base de données autonome Milvus. . Nous avons sélectionné DiskANN comme type d’index pour ces tests. . L'ingestion, l'optimisation et la création d'index pour un ensemble de données d'environ 100 Go ont pris environ 5 heures. Pendant la majeure partie de cette durée, le serveur Milvus, équipé de 20 cœurs (ce qui équivaut à 40 vcpu lorsque Hyper-Threading est activé), fonctionnait à sa capacité CPU maximale de 100 %. Nous avons constaté que DiskANN est particulièrement important pour les grands ensembles de données qui dépassent la taille de la mémoire système. . Dans la phase de requête, nous avons observé un taux de requêtes par seconde (QPS) de 10,93 avec un rappel de 0,9987. La latence du 99e percentile pour les requêtes a été mesurée à 708,2 millisecondes.
Du point de vue du stockage, la base de données a émis environ 1 000 opérations/s pendant les phases d’ingestion, d’optimisation post-insertion et de création d’index. Dans la phase de requête, il a demandé 32 000 opérations/sec.
La section suivante présente les mesures de performances de stockage.
| Phase de charge de travail | Métrique | Valeur |
|---|---|---|
Ingestion de données et optimisation post-insertion |
Op E/S par sec |
< 1 000 |
Latence |
< 400 unités d'utilisation |
|
Charge de travail |
Mix lecture/écriture, principalement écriture |
|
Taille des E/S |
64 Ko |
|
Requête |
Op E/S par sec |
Pic à 32 000 |
Latence |
< 400 unités d'utilisation |
|
Charge de travail |
Lecture à 100 % en cache |
|
Taille des E/S |
Principalement 8 Ko |
Le résultat de vectorDB-bench est ci-dessous.
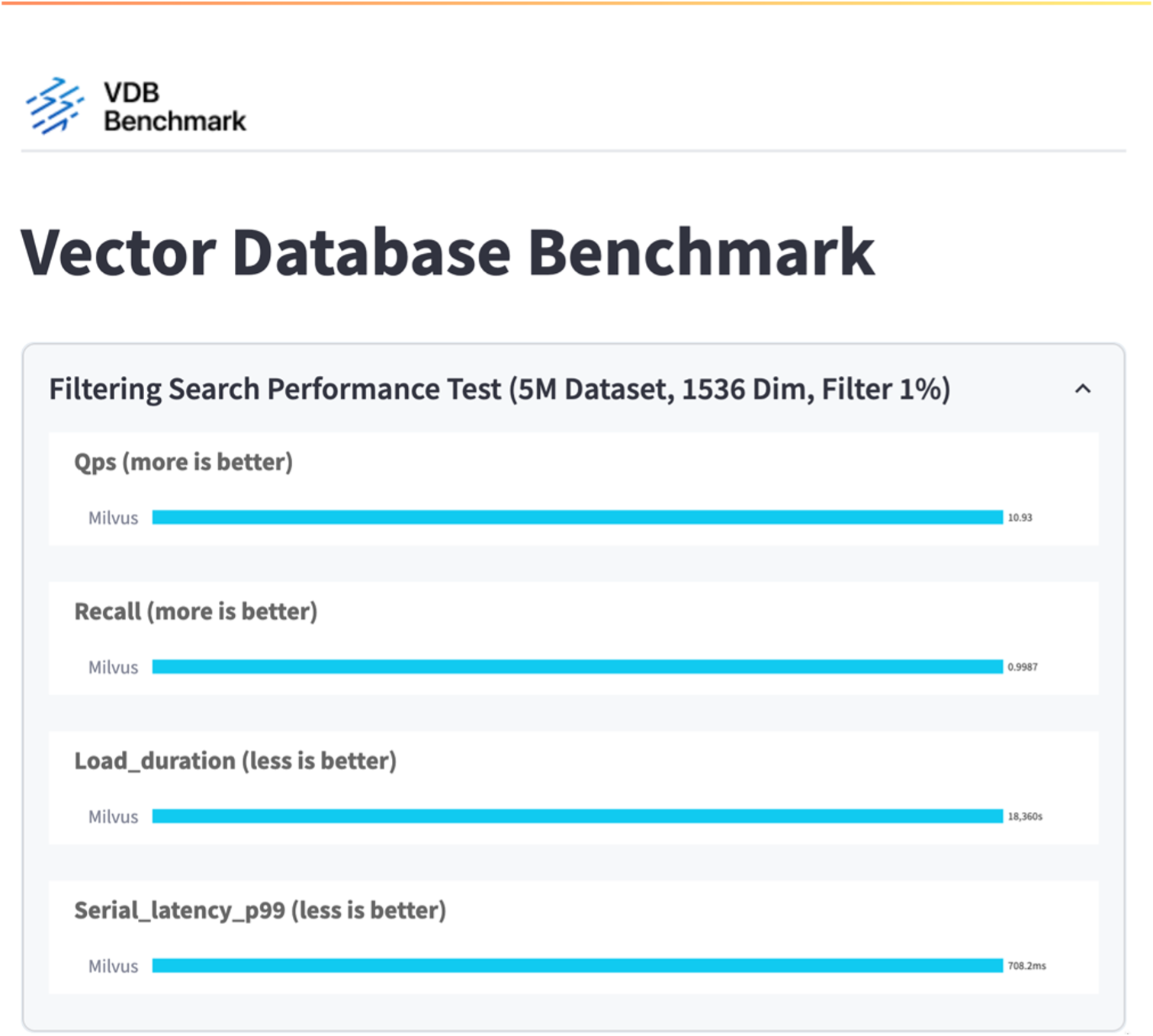
D'après la validation des performances de l'instance autonome Milvus, il est évident que la configuration actuelle est insuffisante pour prendre en charge un ensemble de données de 5 millions de vecteurs avec une dimensionnalité de 1536. Nous avons déterminé que le stockage possède des ressources adéquates et ne constitue pas un goulot d'étranglement dans le système.
VectorDB-Bench avec cluster Milvus
Dans cette section, nous discutons du déploiement d’un cluster Milvus dans un environnement Kubernetes. Cette configuration Kubernetes a été construite sur un déploiement VMware vSphere, qui hébergeait les nœuds maître et de travail Kubernetes.
Les détails des déploiements VMware vSphere et Kubernetes sont présentés dans les sections suivantes.
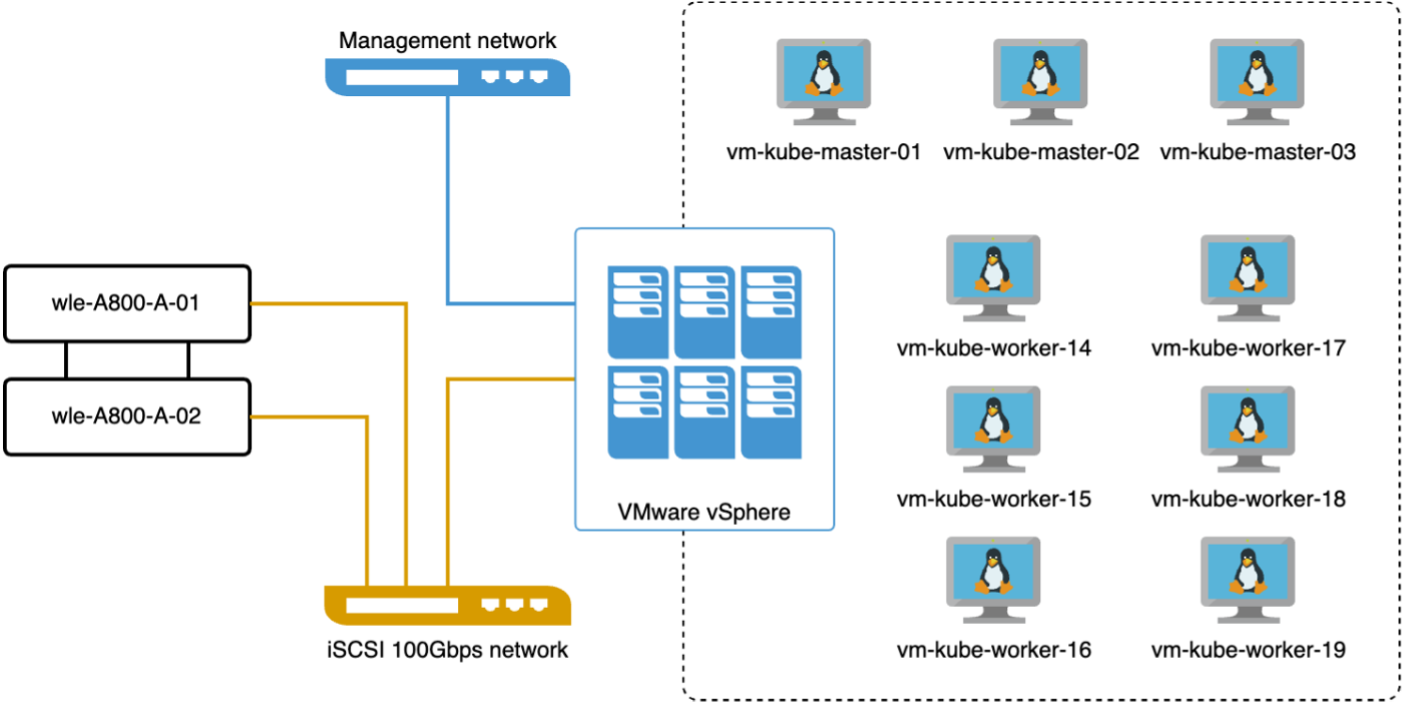
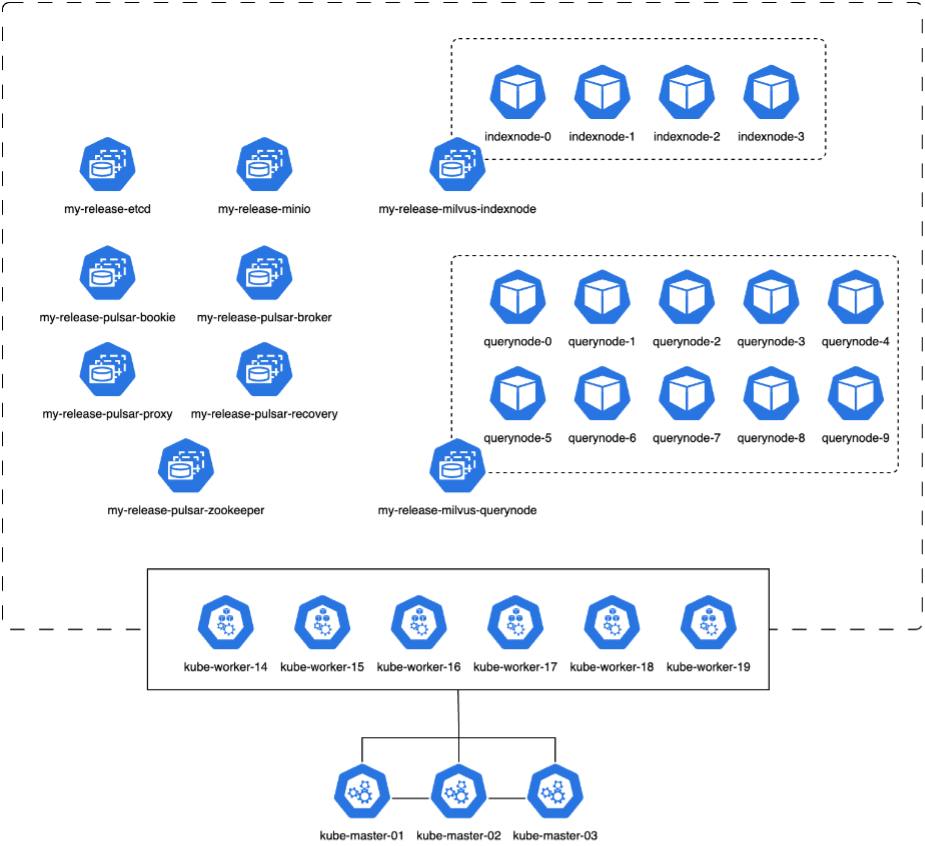
Dans cette section, nous présentons nos observations et résultats issus des tests de la base de données Milvus. * Le type d'index utilisé était DiskANN. * Le tableau ci-dessous fournit une comparaison entre les déploiements autonomes et en cluster lorsque l'on travaille avec 5 millions de vecteurs à une dimensionnalité de 1536. Nous avons observé que le temps nécessaire à l’ingestion des données et à l’optimisation post-insertion était plus faible dans le déploiement en cluster. La latence du 99e percentile pour les requêtes a été réduite de six fois dans le déploiement du cluster par rapport à la configuration autonome. * Bien que le taux de requêtes par seconde (QPS) soit plus élevé dans le déploiement du cluster, il n'était pas au niveau souhaité.

Les images ci-dessous fournissent une vue de diverses mesures de stockage, notamment la latence du cluster de stockage et le nombre total d'IOPS (opérations d'entrée/sortie par seconde).
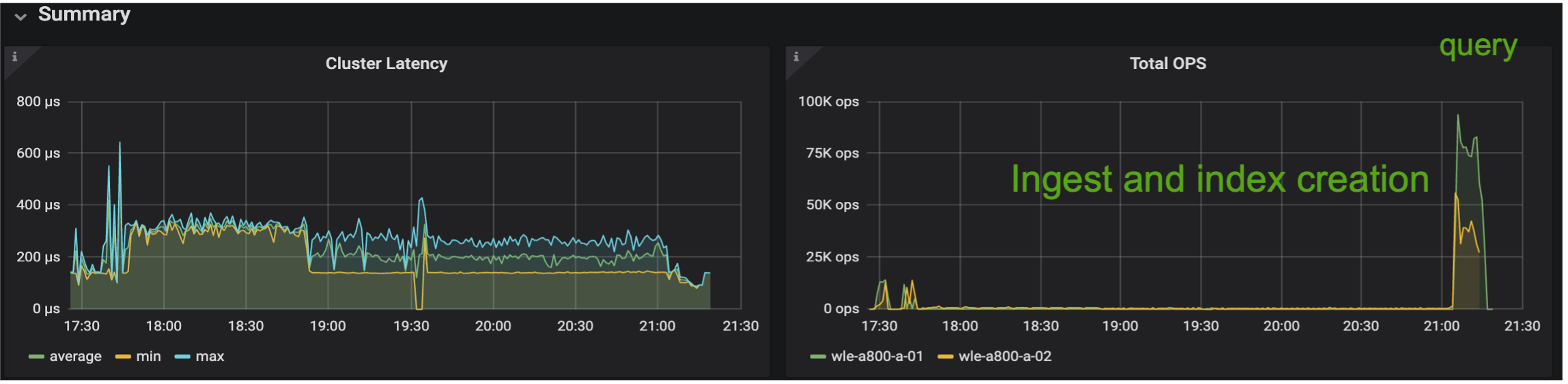
La section suivante présente les principales mesures de performances de stockage.
| Phase de charge de travail | Métrique | Valeur |
|---|---|---|
Ingestion de données et optimisation post-insertion |
Op E/S par sec |
< 1 000 |
Latence |
< 400 unités d'utilisation |
|
Charge de travail |
Mix lecture/écriture, principalement écriture |
|
Taille des E/S |
64 Ko |
|
Requête |
Op E/S par sec |
Pic à 147 000 |
Latence |
< 400 unités d'utilisation |
|
Charge de travail |
Lecture à 100 % en cache |
|
Taille des E/S |
Principalement 8 Ko |
Sur la base de la validation des performances du Milvus autonome et du cluster Milvus, nous présentons les détails du profil d'E/S de stockage. * Nous avons observé que le profil d’E/S reste cohérent dans les déploiements autonomes et en cluster. * La différence observée dans les IOPS de pointe peut être attribuée au plus grand nombre de clients dans le déploiement du cluster.
vectorDB-Bench avec Postgres (pgvecto.rs)
Nous avons effectué les actions suivantes sur PostgreSQL (pgvecto.rs) en utilisant VectorDB-Bench : Les détails concernant la connectivité réseau et serveur de PostgreSQL (en particulier, pgvecto.rs) sont les suivants :
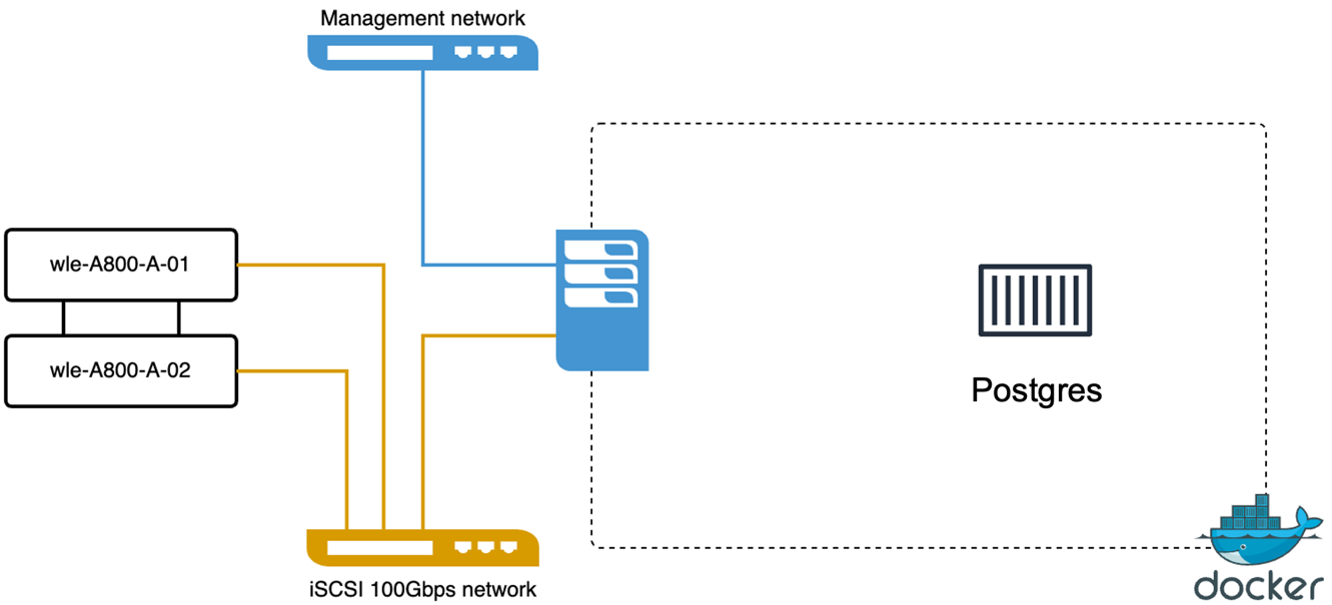
Dans cette section, nous partageons nos observations et résultats des tests de la base de données PostgreSQL, en particulier à l'aide de pgvecto.rs. * Nous avons sélectionné HNSW comme type d'index pour ces tests car au moment des tests, DiskANN n'était pas disponible pour pgvecto.rs. * Au cours de la phase d’ingestion des données, nous avons chargé l’ensemble de données Cohere, qui se compose de 10 millions de vecteurs d’une dimensionnalité de 768. Ce processus a pris environ 4,5 heures. * Dans la phase de requête, nous avons observé un taux de requêtes par seconde (QPS) de 1 068 avec un rappel de 0,6344. La latence du 99e percentile pour les requêtes a été mesurée à 20 millisecondes. Pendant la majeure partie de l’exécution, le processeur client fonctionnait à 100 % de sa capacité.
Les images ci-dessous fournissent une vue de diverses mesures de stockage, notamment la latence du cluster de stockage et le nombre total d'IOPS (opérations d'entrée/sortie par seconde).

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["Figure montrant une boîte de dialogue d'entrée/sortie ou représentant un contenu écrit"]
Comparaison des performances entre Milvus et Postgres sur Vector DB Bench
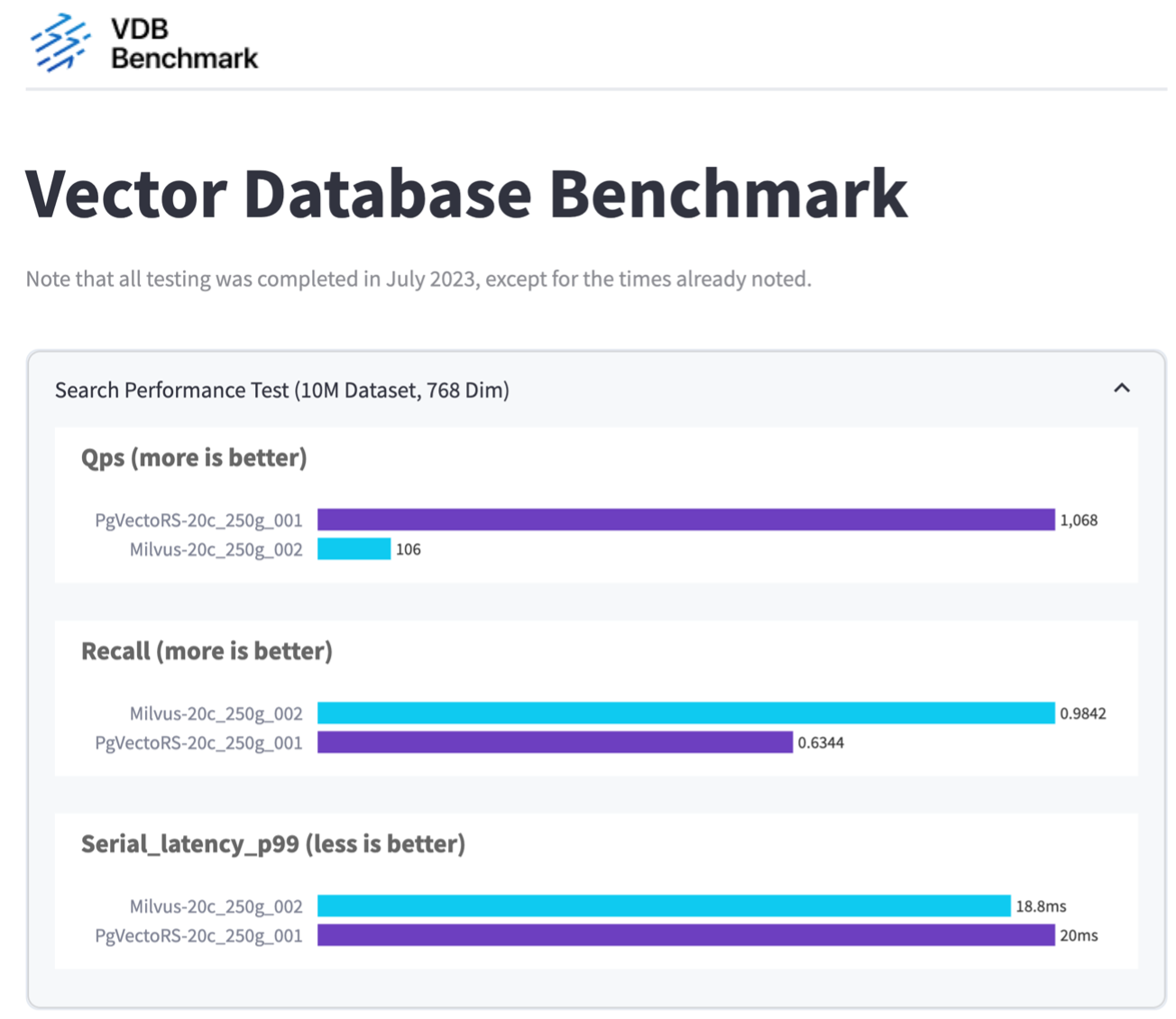
Sur la base de notre validation des performances de Milvus et PostgreSQL à l'aide de VectorDBBench, nous avons observé ce qui suit :
-
Type d'indice : HNSW
-
Ensemble de données : Cohere avec 10 millions de vecteurs à 768 dimensions
Nous avons constaté que pgvecto.rs atteignait un taux de requêtes par seconde (QPS) de 1 068 avec un rappel de 0,6344, tandis que Milvus atteignait un taux de QPS de 106 avec un rappel de 0,9842.
Si la haute précision dans vos requêtes est une priorité, Milvus surpasse pgvecto.rs car il récupère une proportion plus élevée d'éléments pertinents par requête. Cependant, si le nombre de requêtes par seconde est un facteur plus crucial, pgvecto.rs dépasse Milvus. Il est important de noter, cependant, que la qualité des données récupérées via pgvecto.rs est inférieure, avec environ 37 % des résultats de recherche étant des éléments non pertinents.
Observation basée sur nos validations de performance :
Sur la base de nos validations de performances, nous avons fait les observations suivantes :
Dans Milvus, le profil d'E/S ressemble beaucoup à une charge de travail OLTP, telle que celle observée avec Oracle SLOB. Le benchmark se compose de trois phases : l'ingestion des données, la post-optimisation et la requête. Les étapes initiales sont principalement caractérisées par des opérations d'écriture de 64 Ko, tandis que la phase de requête implique principalement des lectures de 8 Ko. Nous nous attendons à ce ONTAP gère efficacement la charge d'E/S Milvus.
Le profil d’E/S PostgreSQL ne présente pas de charge de travail de stockage difficile. Étant donné l'implémentation en mémoire actuellement en cours, nous n'avons observé aucune E/S disque pendant la phase de requête.
DiskANN apparaît comme une technologie cruciale pour la différenciation du stockage. Il permet une mise à l'échelle efficace de la recherche de base de données vectorielle au-delà de la limite de la mémoire système. Cependant, il est peu probable d'établir une différenciation des performances de stockage avec des indices de base de données vectoriels en mémoire tels que HNSW.
Il convient également de noter que le stockage ne joue pas un rôle critique pendant la phase de requête lorsque le type d'index est HSNW, qui est la phase de fonctionnement la plus importante pour les bases de données vectorielles prenant en charge les applications RAG. L’implication ici est que les performances de stockage n’ont pas d’impact significatif sur les performances globales de ces applications.