

Cas d'utilisation de bases de données vectorielles
 Suggérer des modifications
Suggérer des modifications
Cette section fournit un aperçu des cas d’utilisation de la solution de base de données vectorielle NetApp .
Cas d'utilisation de bases de données vectorielles
Dans cette section, nous discutons de deux cas d'utilisation tels que la récupération augmentée avec de grands modèles de langage et le chatbot informatique NetApp .
Génération augmentée de récupération (RAG) avec de grands modèles de langage (LLM)
Retrieval-augmented generation, or RAG, is a technique for enhancing the accuracy and reliability of Large Language Models, or LLMs, by augmenting prompts with facts fetched from external sources. In a traditional RAG deployment, vector embeddings are generated from an existing dataset and then stored in a vector database, often referred to as a knowledgebase. Whenever a user submits a prompt to the LLM, a vector embedding representation of the prompt is generated, and the vector database is searched using that embedding as the search query. This search operation returns similar vectors from the knowledgebase, which are then fed to the LLM as context alongside the original user prompt. In this way, an LLM can be augmented with additional information that was not part of its original training dataset.
L'opérateur NVIDIA Enterprise RAG LLM est un outil utile pour la mise en œuvre de RAG dans l'entreprise. Cet opérateur peut être utilisé pour déployer un pipeline RAG complet. Le pipeline RAG peut être personnalisé pour utiliser Milvus ou pgvecto comme base de données vectorielle pour stocker les intégrations de la base de connaissances. Reportez-vous à la documentation pour plus de détails.
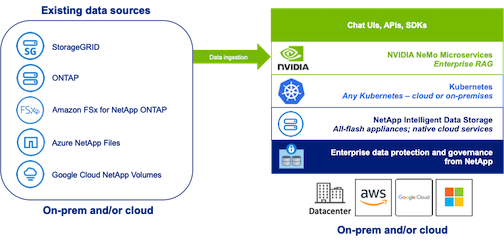
NetApp has validated an enterprise RAG architecture powered by the NVIDIA Enterprise RAG LLM Operator alongside NetApp storage. Refer to our blog post for more information and to see a demo. Figure 1 provides an overview of this architecture.
Figure 1) Enterprise RAG optimisé par NVIDIA NeMo Microservices et NetApp
Cas d'utilisation du chatbot informatique NetApp
Le chatbot de NetApp sert d’autre cas d’utilisation en temps réel pour la base de données vectorielle. Dans ce cas, NetApp Private OpenAI Sandbox fournit une plate-forme efficace, sécurisée et efficiente pour gérer les requêtes des utilisateurs internes de NetApp. En intégrant des protocoles de sécurité rigoureux, des systèmes de gestion de données efficaces et des capacités de traitement d'IA sophistiquées, il garantit des réponses précises et de haute qualité aux utilisateurs en fonction de leurs rôles et responsabilités au sein de l'organisation via l'authentification SSO. Cette architecture met en évidence le potentiel de fusion de technologies avancées pour créer des systèmes intelligents axés sur l’utilisateur.
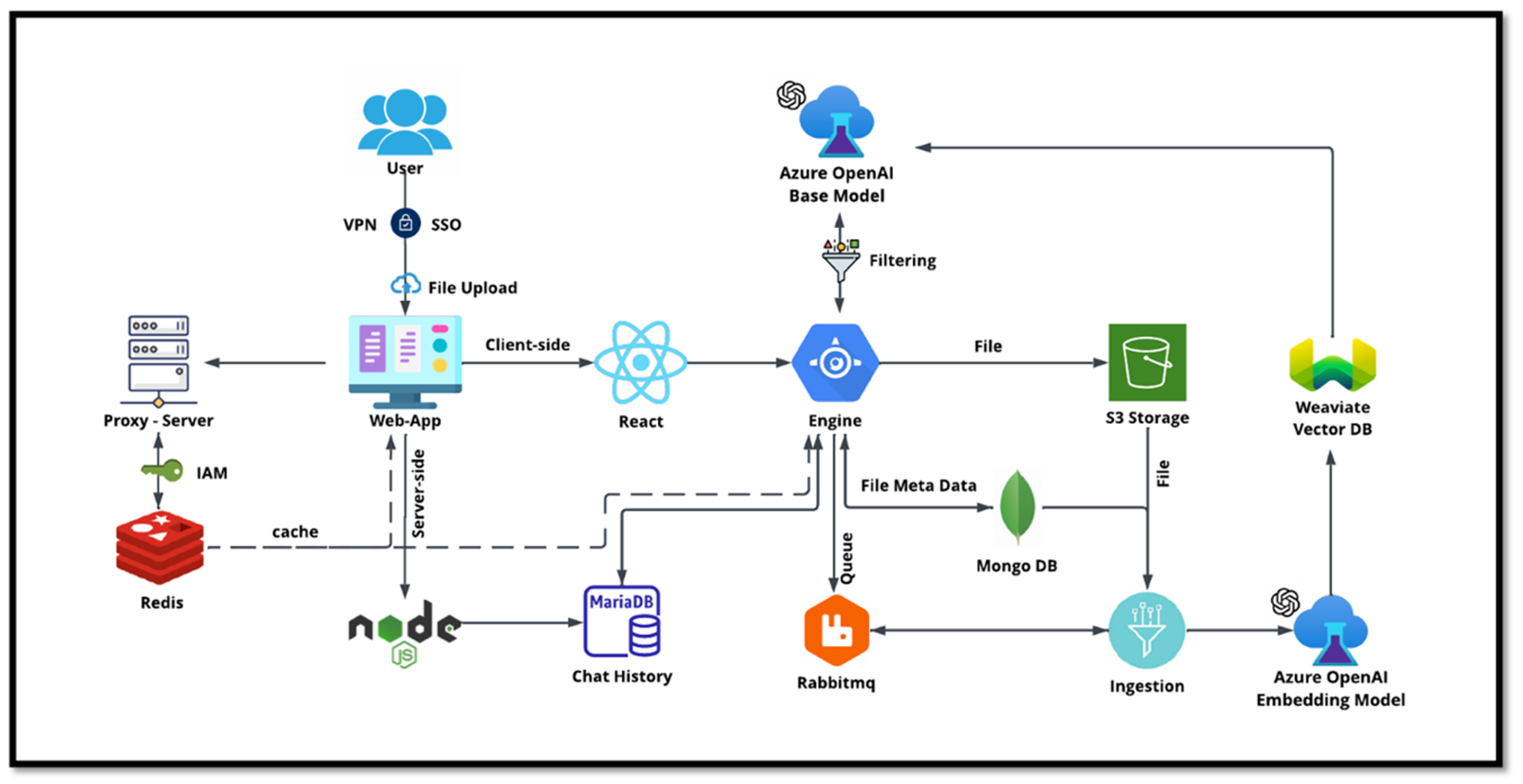
Le cas d’utilisation peut être divisé en quatre sections principales.
Authentification et vérification de l'utilisateur :
-
Les requêtes des utilisateurs passent d'abord par le processus NetApp Single Sign-On (SSO) pour confirmer l'identité de l'utilisateur.
-
Après une authentification réussie, le système vérifie la connexion VPN pour garantir une transmission de données sécurisée.
Transmission et traitement des données :
-
Une fois le VPN validé, les données sont envoyées à MariaDB via les applications Web NetAIChat ou NetAICreate. MariaDB est un système de base de données rapide et efficace utilisé pour gérer et stocker les données des utilisateurs.
-
MariaDB envoie ensuite les informations à l’instance NetApp Azure, qui connecte les données utilisateur à l’unité de traitement de l’IA.
Interaction avec OpenAI et filtrage de contenu :
-
L’instance Azure envoie les questions de l’utilisateur à un système de filtrage de contenu. Ce système nettoie la requête et la prépare pour le traitement.
-
L’entrée nettoyée est ensuite envoyée au modèle de base Azure OpenAI, qui génère une réponse basée sur l’entrée.
Génération et modération des réponses :
-
La réponse du modèle de base est d’abord vérifiée pour garantir qu’elle est exacte et qu’elle répond aux normes de contenu.
-
Après avoir passé le contrôle, la réponse est renvoyée à l'utilisateur. Ce processus garantit que l’utilisateur reçoit une réponse claire, précise et appropriée à sa requête.