

TR-4988 : Sauvegarde, récupération et clonage de bases de données Oracle sur ANF avec SnapCenter
 Suggérer des modifications
Suggérer des modifications
Allen Cao, Niyaz Mohamed, NetApp
Cette solution fournit une vue d'ensemble et des détails pour le déploiement automatisé d'Oracle dans Microsoft Azure NetApp Files en tant que stockage de base de données principal avec le protocole NFS et la base de données Oracle est déployée en tant que base de données de conteneur avec dNFS activé. La base de données déployée dans Azure est protégée à l’aide de l’outil d’interface utilisateur SnapCenter pour une gestion simplifiée de la base de données.
But
Le logiciel NetApp SnapCenter software est une plate-forme d'entreprise facile à utiliser pour coordonner et gérer en toute sécurité la protection des données entre les applications, les bases de données et les systèmes de fichiers. Il simplifie la gestion du cycle de vie de la sauvegarde, de la restauration et du clonage en déchargeant ces tâches sur les propriétaires d'applications sans sacrifier la capacité de superviser et de réguler l'activité sur les systèmes de stockage. En exploitant la gestion des données basée sur le stockage, elle permet d’augmenter les performances et la disponibilité, ainsi que de réduire les temps de test et de développement.
Dans TR-4987,"Déploiement Oracle simplifié et automatisé sur Azure NetApp Files avec NFS" , nous démontrons le déploiement automatisé d'Oracle sur Azure NetApp Files (ANF) dans le cloud Azure. Dans cette documentation, nous présentons la protection et la gestion de la base de données Oracle sur ANF dans le cloud Azure avec un outil d'interface utilisateur SnapCenter très convivial.
Cette solution répond aux cas d’utilisation suivants :
-
Sauvegarde et récupération de la base de données Oracle déployée sur ANF dans le cloud Azure avec SnapCenter.
-
Gérez les instantanés de base de données et les copies clonées pour accélérer le développement des applications et améliorer la gestion du cycle de vie des données.
Public
Cette solution est destinée aux personnes suivantes :
-
Un administrateur de base de données qui souhaite déployer des bases de données Oracle sur Azure NetApp Files.
-
Un architecte de solutions de base de données qui souhaite tester les charges de travail Oracle sur Azure NetApp Files.
-
Un administrateur de stockage qui souhaite déployer et gérer des bases de données Oracle sur Azure NetApp Files.
-
Un propriétaire d’application qui souhaite mettre en place une base de données Oracle sur Azure NetApp Files.
Environnement de test et de validation de solutions
Les tests et la validation de cette solution ont été réalisés dans un environnement de laboratoire qui pourrait ne pas correspondre à l’environnement de déploiement final. Voir la sectionFacteurs clés à prendre en compte lors du déploiement pour plus d'informations.
Architecture
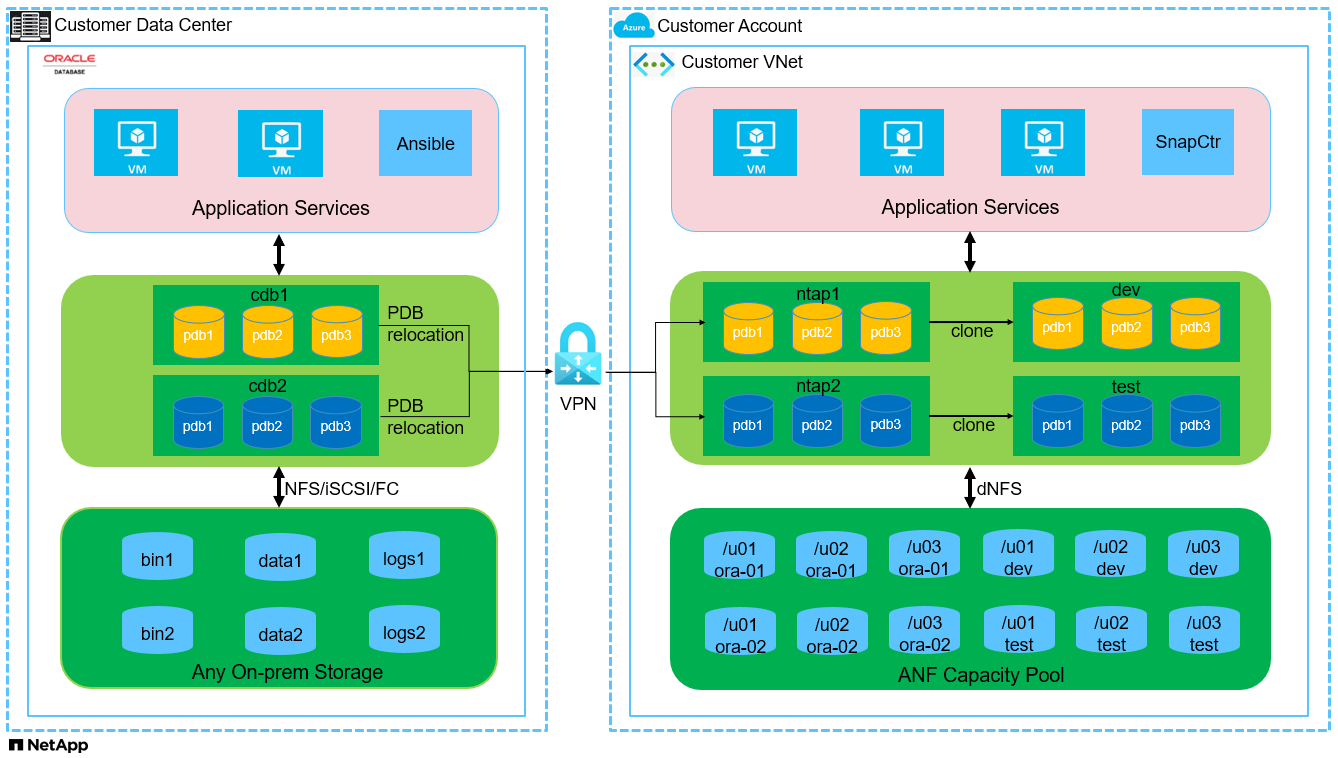
Composants matériels et logiciels
Matériel |
||
Azure NetApp Files |
Offre actuelle dans Azure par Microsoft |
Un pool de capacité avec un niveau de service Premium |
Machine virtuelle Azure pour serveur de base de données |
Standard_B4ms - 4 vCPU, 16 Gio |
Deux instances de machine virtuelle Linux |
Machine virtuelle Azure pour SnapCenter |
Standard_B4ms - 4 vCPU, 16 Gio |
Une instance de machine virtuelle Windows |
Logiciel |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Abonnement RedHat déployé pour les tests |
Windows Server |
Centre de données 2022 ; Hotpatch AE – x64 Gen2 |
Hébergement du serveur SnapCenter |
Base de données Oracle |
Version 19.18 |
Patch p34765931_190000_Linux-x86-64.zip |
Oracle OPatch |
Version 12.2.0.1.36 |
Patch p6880880_190000_Linux-x86-64.zip |
Serveur SnapCenter |
Version 5.0 |
Déploiement de groupe de travail |
Ouvrir le JDK |
Version java-11-openjdk |
Exigence du plug-in SnapCenter sur les machines virtuelles de base de données |
NFS |
Version 3.0 |
Oracle dNFS activé |
Ansible |
noyau 2.16.2 |
Python 3.6.8 |
Configuration de la base de données Oracle dans l'environnement de laboratoire
Serveur |
Base de données |
Stockage de base de données |
ora-01 |
NTAP1(NTAP1_PDB1,NTAP1_PDB2,NTAP1_PDB3) |
/u01, /u02, /u03 Montages NFS sur le pool de capacité ANF |
ora-02 |
NTAP2(NTAP2_PDB1,NTAP2_PDB2,NTAP2_PDB3) |
/u01, /u02, /u03 Montages NFS sur le pool de capacité ANF |
Facteurs clés à prendre en compte lors du déploiement
-
* Déploiement de SnapCenter .* SnapCenter peut être déployé dans un domaine Windows ou un environnement de groupe de travail. Pour un déploiement basé sur un domaine, le compte d'utilisateur de domaine doit être un compte d'administrateur de domaine ou l'utilisateur de domaine doit appartenir au groupe de l'administrateur local sur le serveur d'hébergement SnapCenter .
-
Résolution de nom. Le serveur SnapCenter doit résoudre le nom en adresse IP pour chaque hôte de serveur de base de données cible géré. Chaque hôte de serveur de base de données cible doit résoudre le nom du serveur SnapCenter en adresse IP. Si un serveur DNS n'est pas disponible, ajoutez un nom aux fichiers hôtes locaux pour la résolution.
-
Configuration du groupe de ressources. Le groupe de ressources dans SnapCenter est un regroupement logique de ressources similaires qui peuvent être sauvegardées ensemble. Ainsi, cela simplifie et réduit le nombre de tâches de sauvegarde dans un environnement de base de données volumineux.
-
Sauvegarde complète séparée de la base de données et du journal d'archive. La sauvegarde complète de la base de données inclut des volumes de données et des instantanés de groupe cohérents avec les volumes de journaux. Un instantané complet et fréquent de la base de données entraîne une consommation de stockage plus élevée, mais améliore le RTO. Une alternative consiste à effectuer des instantanés de base de données complets moins fréquents et des sauvegardes de journaux d'archives plus fréquentes, ce qui consomme moins de stockage et améliore le RPO mais peut étendre le RTO. Tenez compte de vos objectifs RTO et RPO lors de la configuration du schéma de sauvegarde. Il existe également une limite (1023) du nombre de sauvegardes instantanées sur un volume.
-
* Délégation de Privileges .* Tirez parti du contrôle d'accès basé sur les rôles intégré à l'interface utilisateur de SnapCenter pour déléguer des privilèges aux équipes d'application et de base de données si vous le souhaitez.
Déploiement de la solution
Les sections suivantes fournissent des procédures étape par étape pour le déploiement, la configuration et la sauvegarde, la récupération et le clonage de la base de données Oracle de SnapCenter sur Azure NetApp Files dans le cloud Azure.
Prérequis pour le déploiement
Details
Le déploiement nécessite des bases de données Oracle existantes exécutées sur ANF dans Azure. Sinon, suivez les étapes ci-dessous pour créer deux bases de données Oracle pour la validation de la solution. Pour plus de détails sur le déploiement de la base de données Oracle sur ANF dans le cloud Azure avec automatisation, reportez-vous à TR-4987 :"Déploiement Oracle simplifié et automatisé sur Azure NetApp Files avec NFS"
-
Un compte Azure a été configuré et les segments de réseau et de réseau virtuel nécessaires ont été créés dans votre compte Azure.
-
À partir du portail cloud Azure, déployez des machines virtuelles Azure Linux en tant que serveurs de base de données Oracle. Créez un pool de capacité Azure NetApp Files et des volumes de base de données pour la base de données Oracle. Activez l’authentification par clé privée/publique SSH de la machine virtuelle pour Azureuser sur les serveurs de base de données. Consultez le diagramme d’architecture dans la section précédente pour plus de détails sur la configuration de l’environnement. Également appelé"Procédures de déploiement Oracle étape par étape sur Azure VM et Azure NetApp Files" pour des informations détaillées.

Pour les machines virtuelles Azure déployées avec redondance de disque local, assurez-vous d’avoir alloué au moins 128 Go sur le disque racine de la machine virtuelle afin de disposer de suffisamment d’espace pour préparer les fichiers d’installation Oracle et ajouter le fichier d’échange du système d’exploitation. Développez les partitions du système d'exploitation /tmplv et /rootlv en conséquence. Assurez-vous que la dénomination du volume de base de données respecte les conventions VMname-u01, VMname-u02 et VMname-u03. sudo lvresize -r -L +20G /dev/mapper/rootvg-rootlvsudo lvresize -r -L +10G /dev/mapper/rootvg-tmplv -
Depuis le portail cloud Azure, provisionnez un serveur Windows pour exécuter l’outil d’interface utilisateur NetApp SnapCenter avec la dernière version. Consultez le lien suivant pour plus de détails :"Installer le serveur SnapCenter" .
-
Provisionnez une machine virtuelle Linux en tant que nœud de contrôleur Ansible avec la dernière version d'Ansible et de Git installée. Consultez le lien suivant pour plus de détails :"Premiers pas avec l'automatisation des solutions NetApp " dans la section -
Setup the Ansible Control Node for CLI deployments on RHEL / CentOSou
Setup the Ansible Control Node for CLI deployments on Ubuntu / Debian.
Le nœud du contrôleur Ansible peut être localisé sur site ou dans le cloud Azure dans la mesure où il peut atteindre les machines virtuelles Azure DB via le port SSH. -
Clonez une copie de la boîte à outils d’automatisation du déploiement NetApp Oracle pour NFS. Suivez les instructions dans"TR-4887" pour exécuter les manuels.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_oracle_deploy_nfs.git -
Étape suivant les fichiers d’installation d’Oracle 19c sur le répertoire Azure DB VM /tmp/archive avec l’autorisation 777.
installer_archives: - "LINUX.X64_193000_db_home.zip" - "p34765931_190000_Linux-x86-64.zip" - "p6880880_190000_Linux-x86-64.zip"
-
Regardez la vidéo suivante :
Sauvegarde, récupération et clonage de bases de données Oracle sur ANF avec SnapCenter -
Passez en revue le
Get Startedmenu en ligne.
Installation et configuration de SnapCenter
Details
Nous vous recommandons de passer par en ligne"Documentation du logiciel SnapCenter" avant de procéder à l'installation et à la configuration de SnapCenter : . Ce qui suit fournit un résumé de haut niveau des étapes d’installation et de configuration du SnapCenter software pour Oracle sur Azure ANF.
-
Depuis le serveur Windows SnapCenter , téléchargez et installez le dernier JDK Java à partir de"Obtenez Java pour les applications de bureau" .
-
À partir du serveur Windows SnapCenter , téléchargez et installez la dernière version (actuellement 5.0) de l'exécutable d'installation de SnapCenter à partir du site de support NetApp :"NetApp | Assistance" .
-
Après l'installation du serveur SnapCenter , lancez le navigateur pour vous connecter à SnapCenter avec les informations d'identification de l'utilisateur administrateur local Windows ou de l'utilisateur de domaine via le port 8146.
-
Revoir
Get Startedmenu en ligne.
-
Dans
Settings-Global Settings, vérifierHypervisor Settingset cliquez sur Mettre à jour.
-
Si nécessaire, ajustez
Session Timeoutpour l'interface utilisateur SnapCenter à l'intervalle souhaité.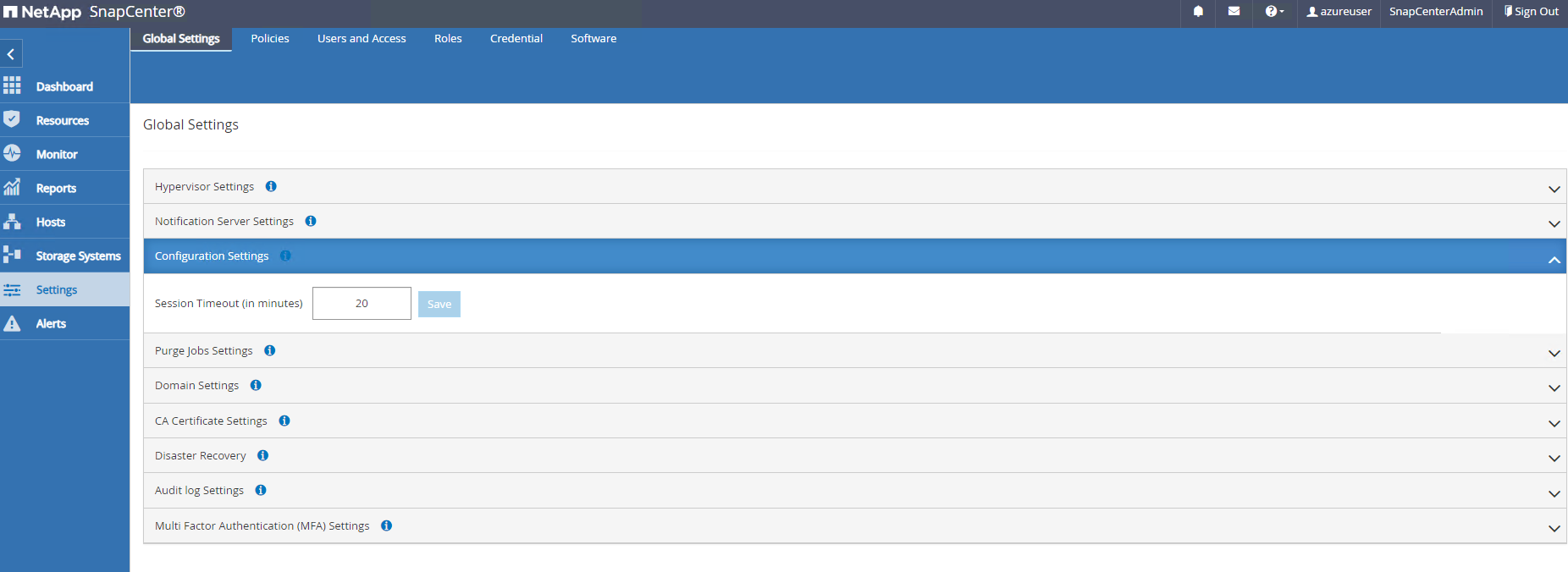
-
Ajoutez des utilisateurs supplémentaires à SnapCenter si nécessaire.
-
Le
RolesL'onglet répertorie les rôles intégrés qui peuvent être attribués à différents utilisateurs de SnapCenter . Des rôles personnalisés peuvent également être créés par l'utilisateur administrateur avec les privilèges souhaités.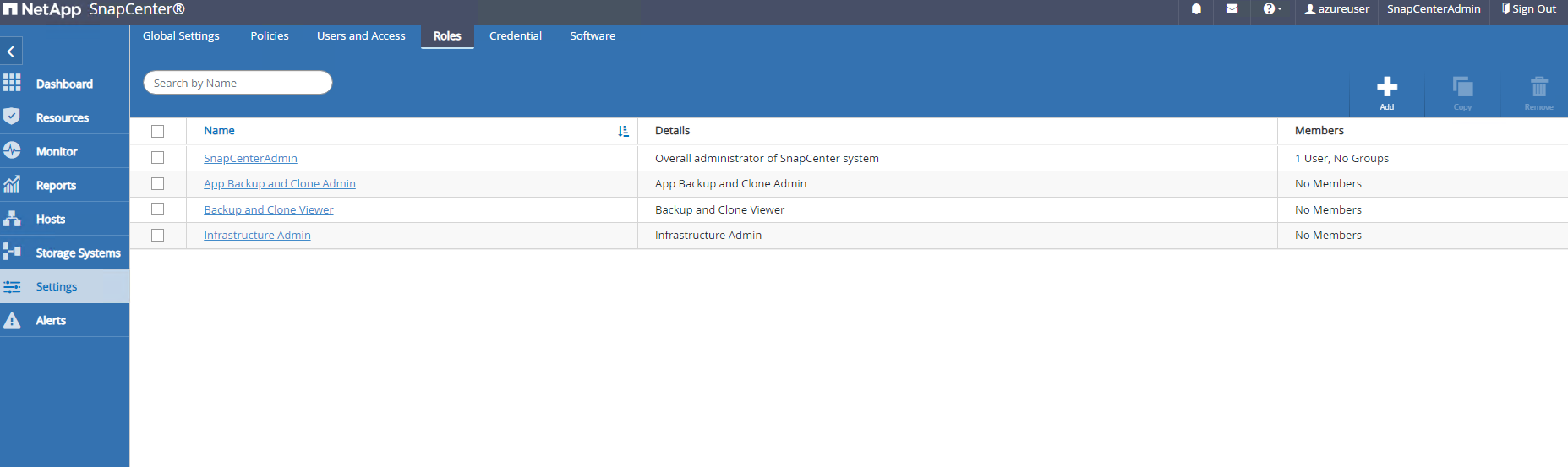
-
Depuis
Settings-Credential, créez des informations d'identification pour les cibles de gestion SnapCenter . Dans ce cas d’utilisation de démonstration, il s’agit d’un utilisateur Linux pour la connexion à la machine virtuelle Azure et d’informations d’identification ANF pour l’accès au pool de capacité.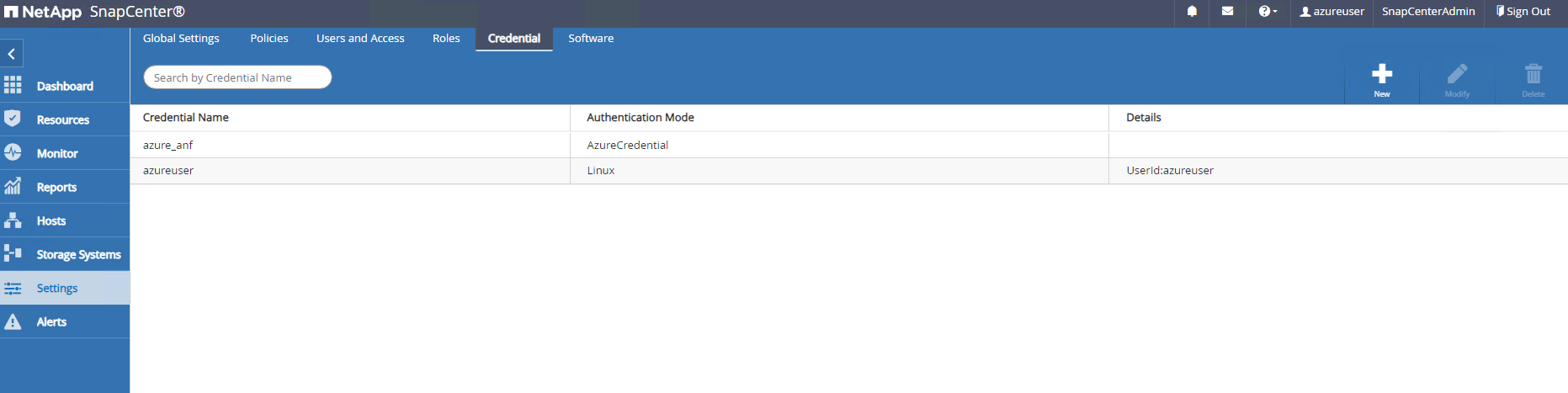
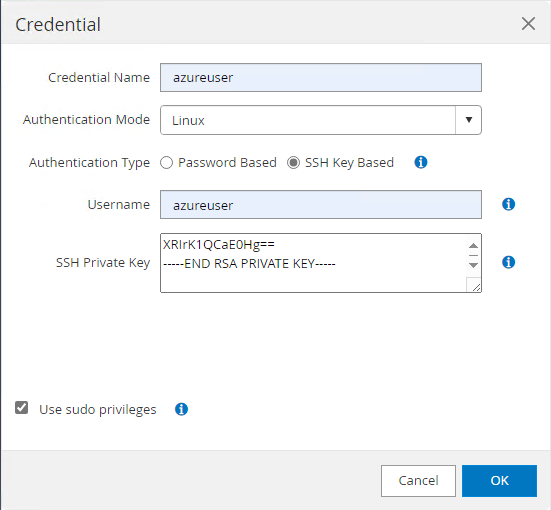
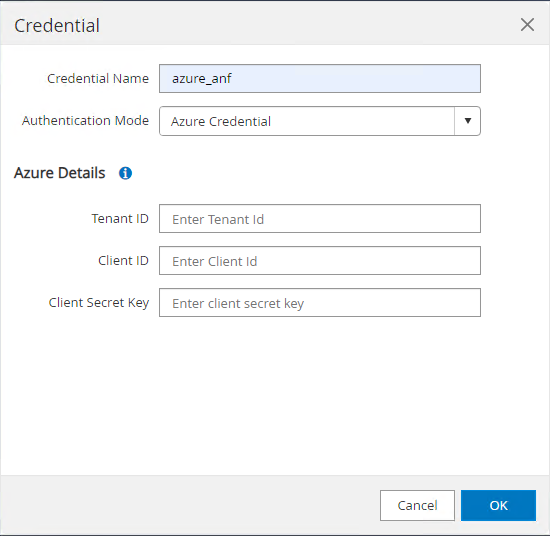
-
Depuis
Storage Systemsonglet, ajouterAzure NetApp Filesavec les informations d'identification créées ci-dessus.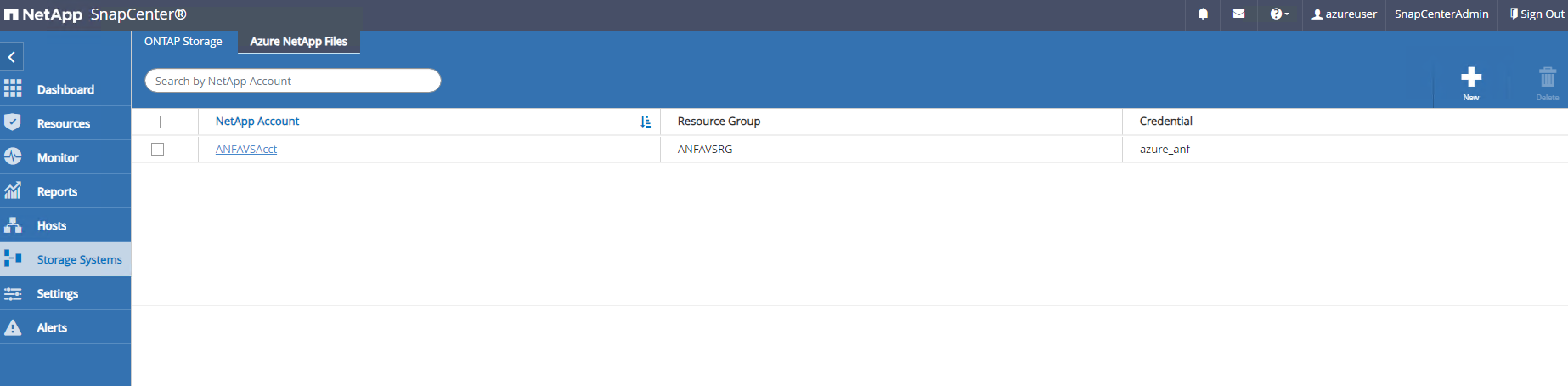

-
Depuis
Hostsonglet, ajoutez les machines virtuelles Azure DB, qui installent le plug-in SnapCenter pour Oracle sur Linux.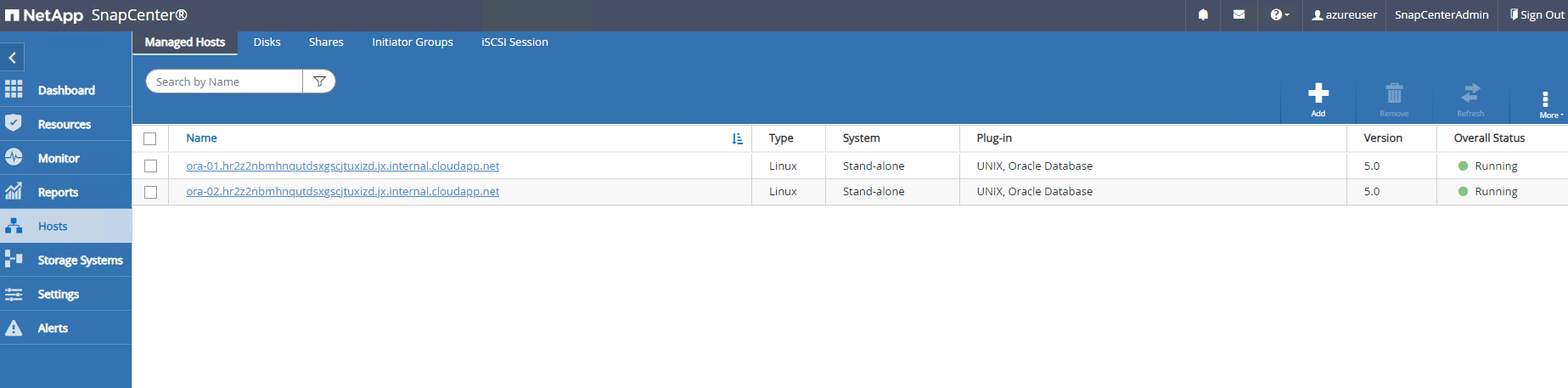
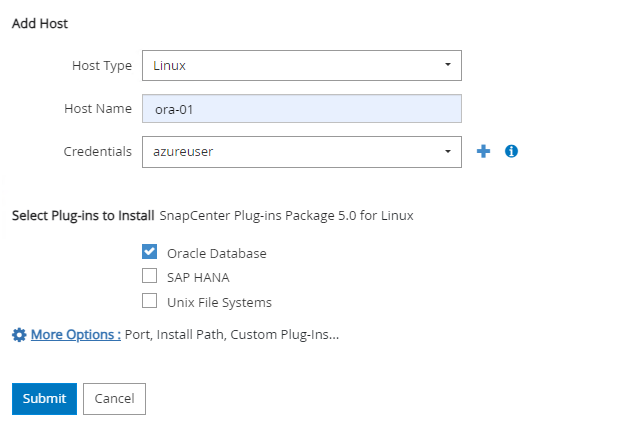
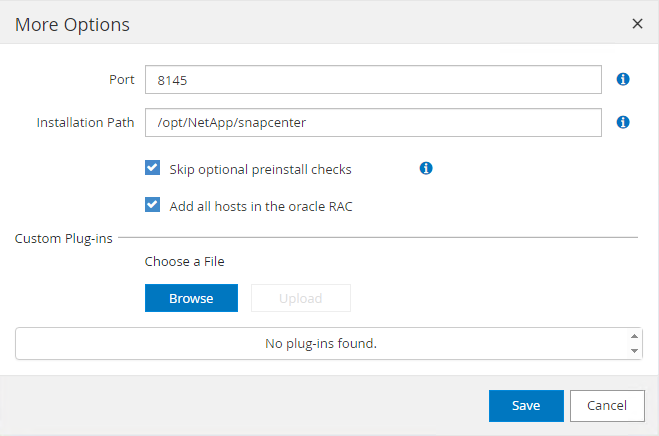
-
Une fois le plugin hôte installé sur la machine virtuelle du serveur de base de données, les bases de données sur l'hôte sont automatiquement découvertes et visibles dans
Resourceslanguette. Retour àSettings-Polices, créez des politiques de sauvegarde pour la sauvegarde complète en ligne de la base de données Oracle et la sauvegarde des journaux d'archivage uniquement. Se référer à ce document"Créer des politiques de sauvegarde pour les bases de données Oracle" pour des procédures détaillées étape par étape.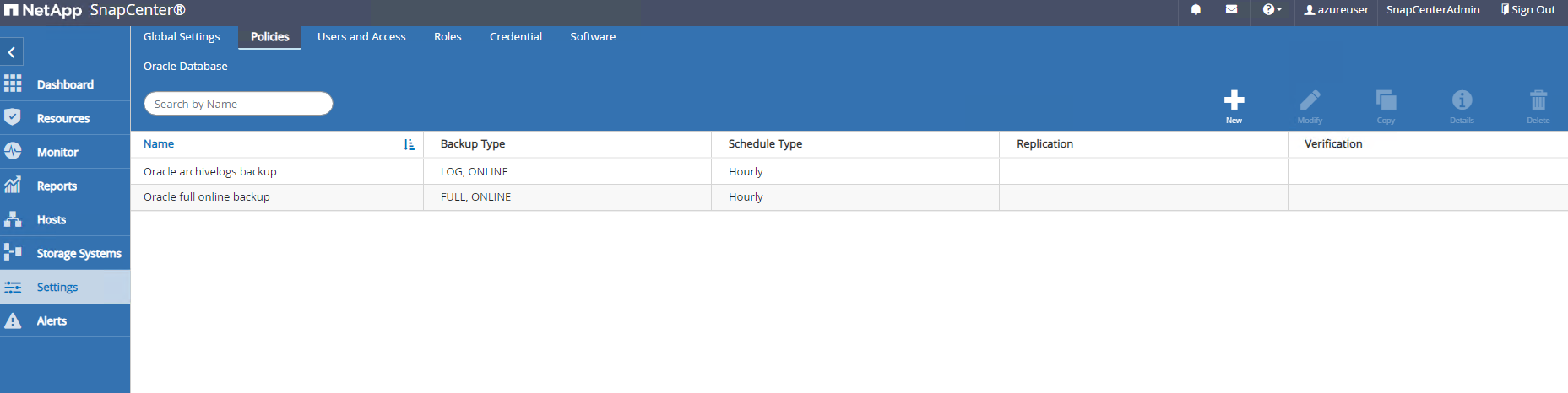
Sauvegarde de la base de données
Details
Une sauvegarde instantanée NetApp crée une image ponctuelle des volumes de base de données que vous pouvez utiliser pour restaurer en cas de panne du système ou de perte de données. Les sauvegardes instantanées prennent très peu de temps, généralement moins d’une minute. L'image de sauvegarde consomme un espace de stockage minimal et entraîne une surcharge de performances négligeable, car elle enregistre uniquement les modifications apportées aux fichiers depuis la dernière copie instantanée. La section suivante illustre l'implémentation des instantanés pour la sauvegarde de la base de données Oracle dans SnapCenter.
-
Navigation vers
Resourcesonglet, qui répertorie les bases de données découvertes une fois le plugin SnapCenter installé sur la machine virtuelle de base de données. Au départ, leOverall Statusde la base de données montre commeNot protected.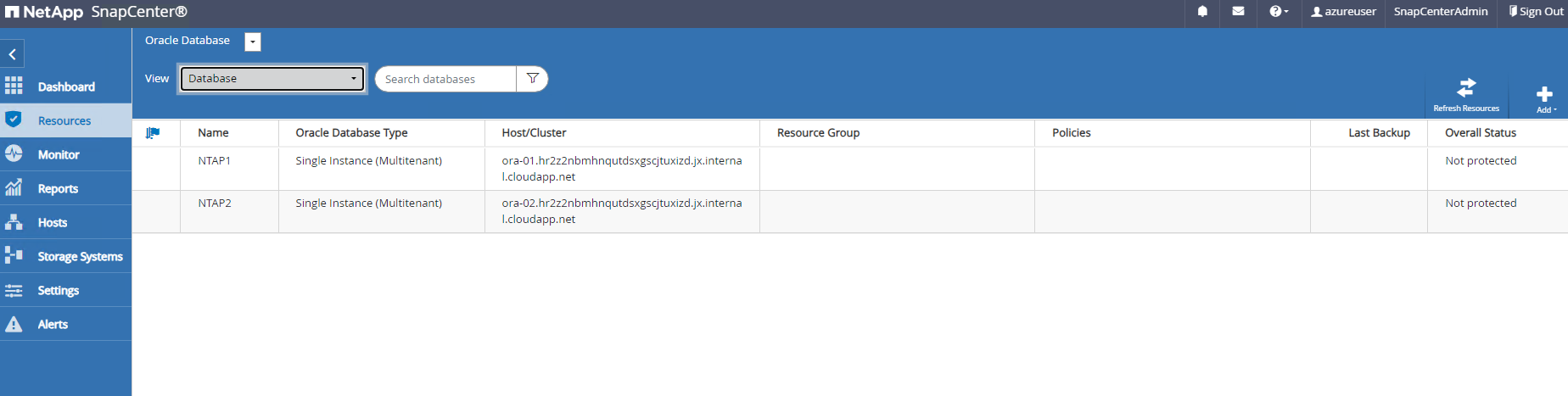
-
Cliquez sur
Viewmenu déroulant pour passer àResource Group. Cliquez surAddsigne à droite pour ajouter un groupe de ressources.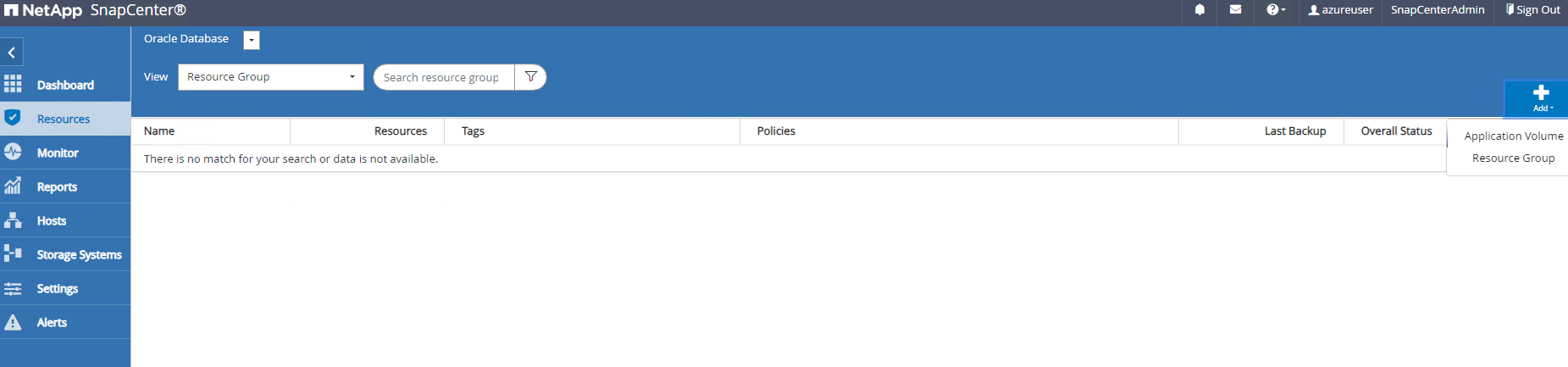
-
Nommez votre groupe de ressources, vos balises et tout nom personnalisé.
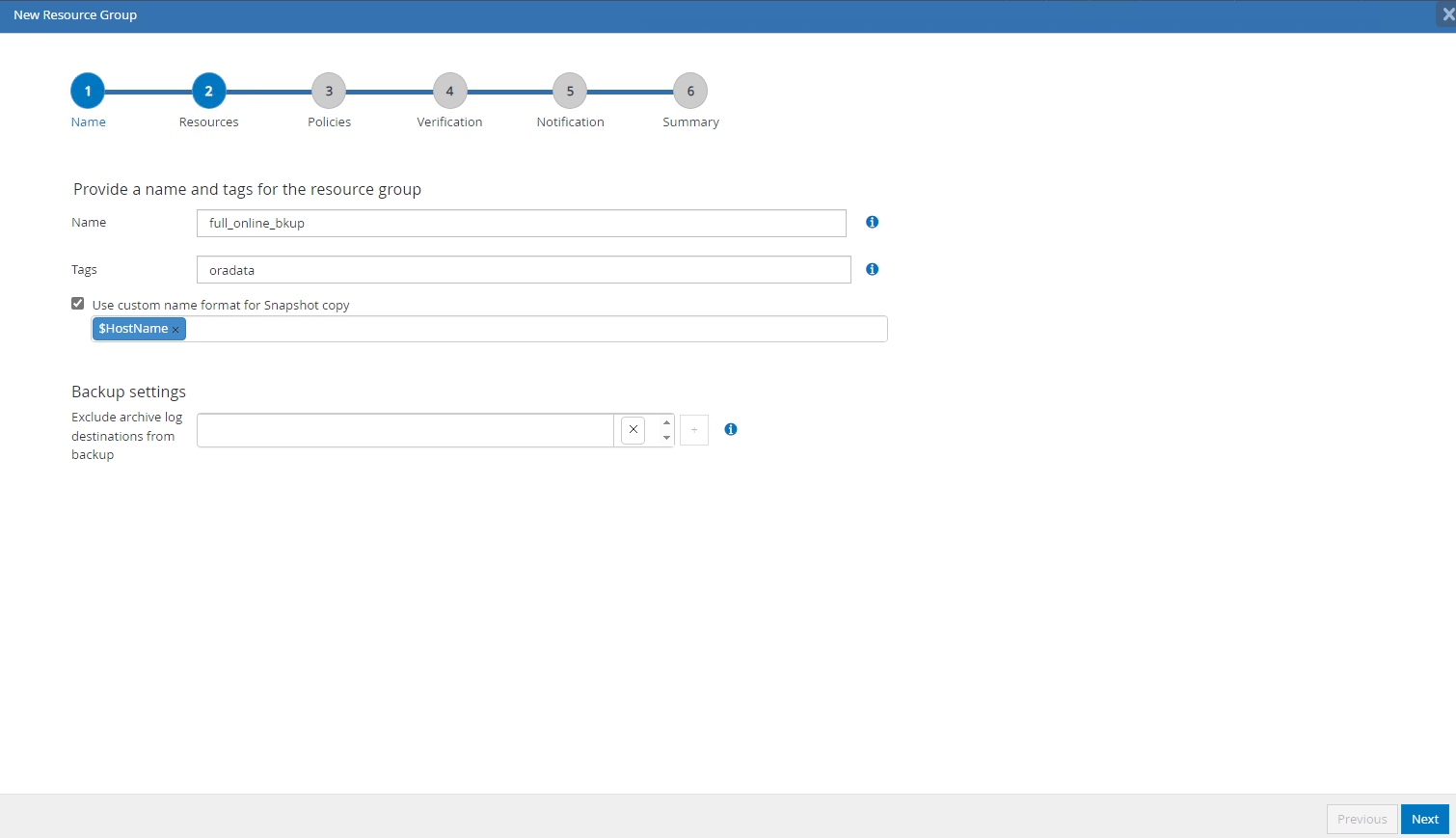
-
Ajoutez des ressources à votre
Resource Group. Le regroupement de ressources similaires peut simplifier la gestion de la base de données dans un environnement de grande taille.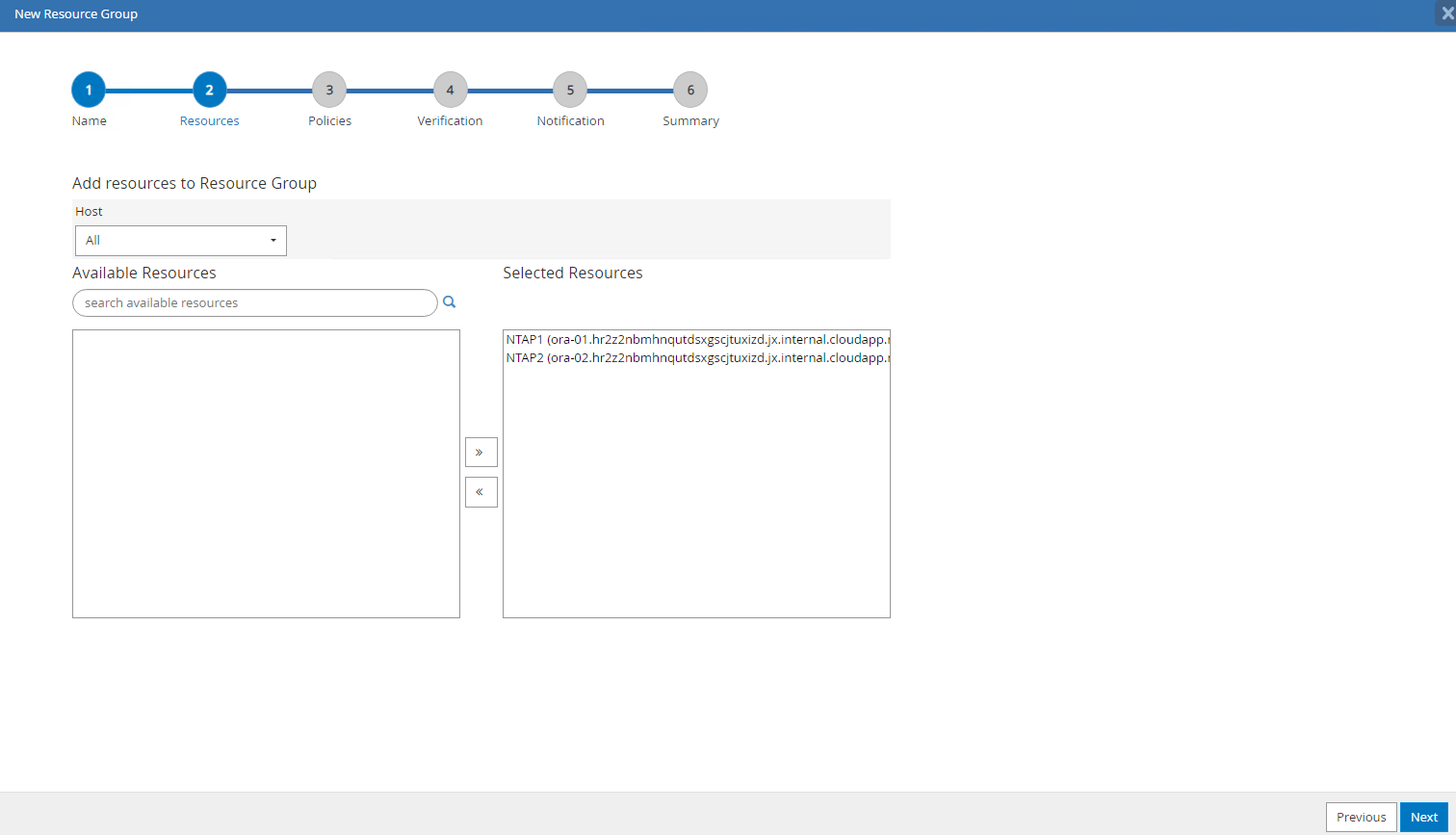
-
Sélectionnez la politique de sauvegarde et définissez une planification en cliquant sur le signe « + » sous
Configure Schedules.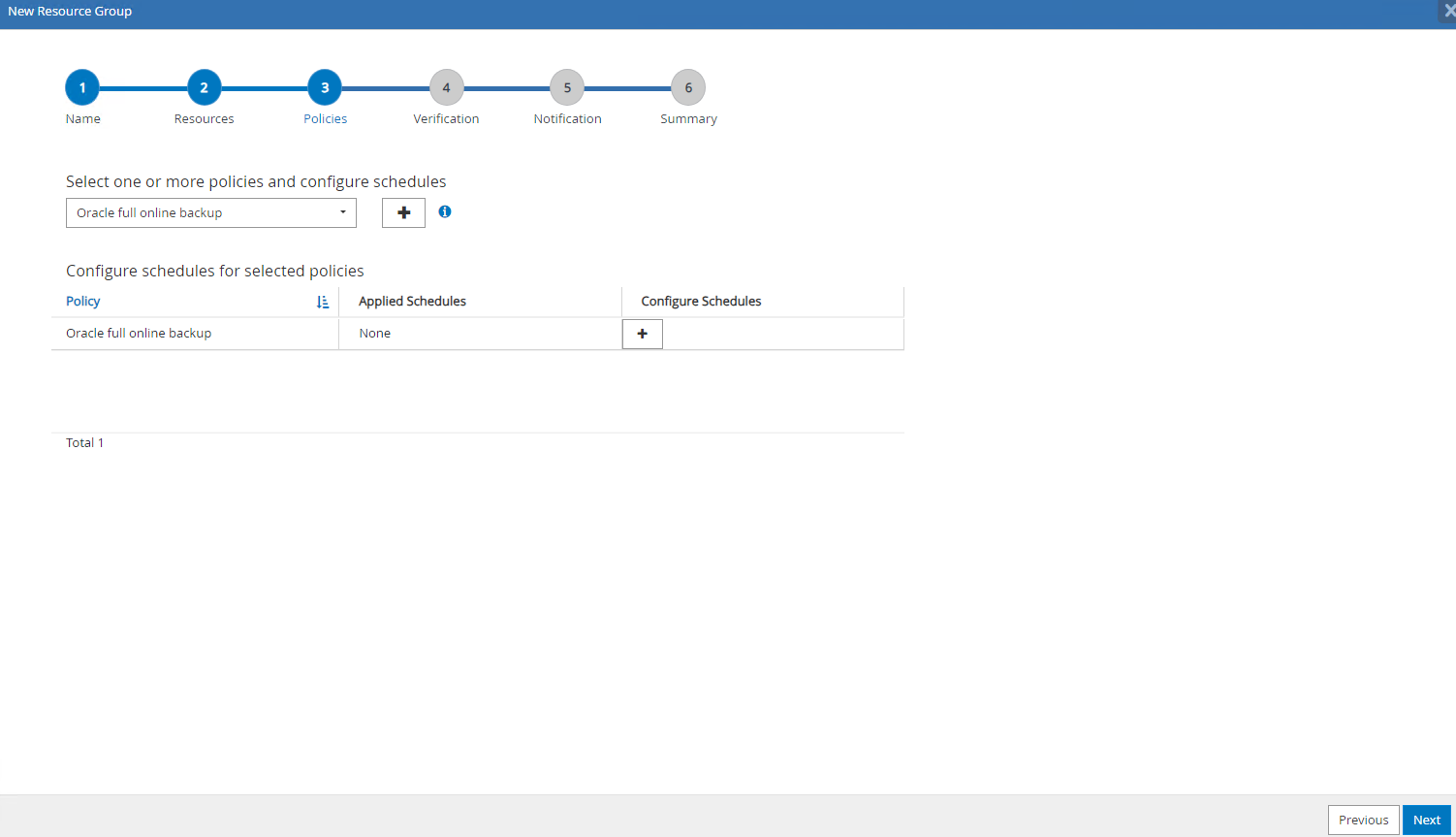
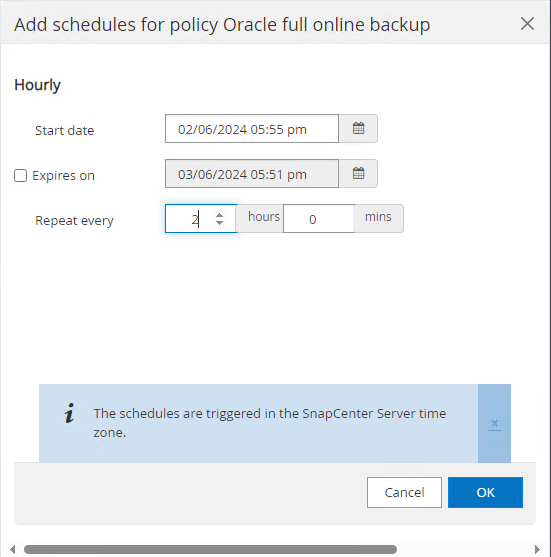
-
Si la vérification de sauvegarde n'est pas configurée dans la politique, laissez la page de vérification telle quelle.
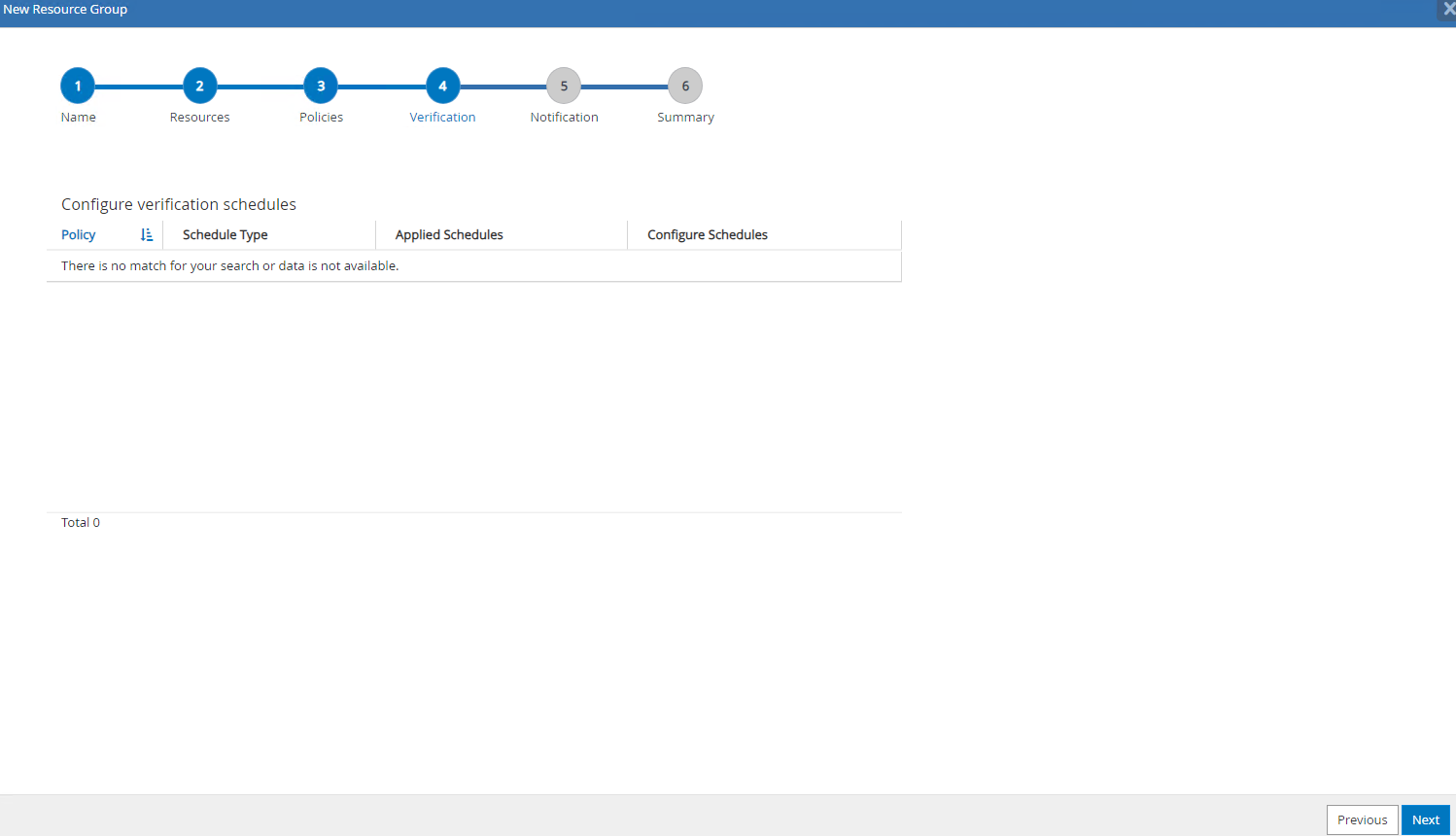
-
Afin d'envoyer par courrier électronique un rapport de sauvegarde et une notification, un serveur de messagerie SMTP est nécessaire dans l'environnement. Ou laissez-le noir si aucun serveur de messagerie n'est configuré.
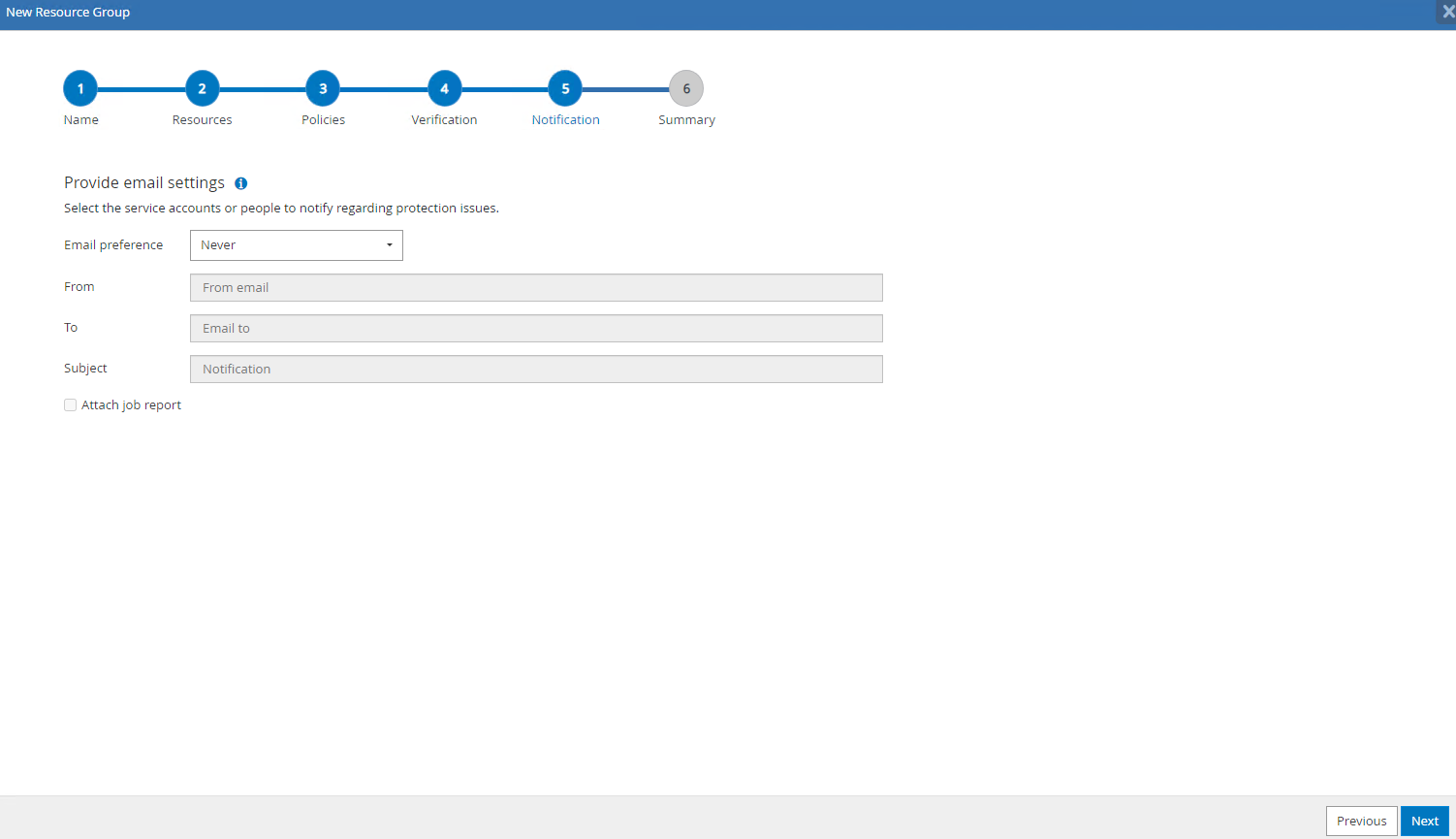
-
Résumé du nouveau groupe de ressources.
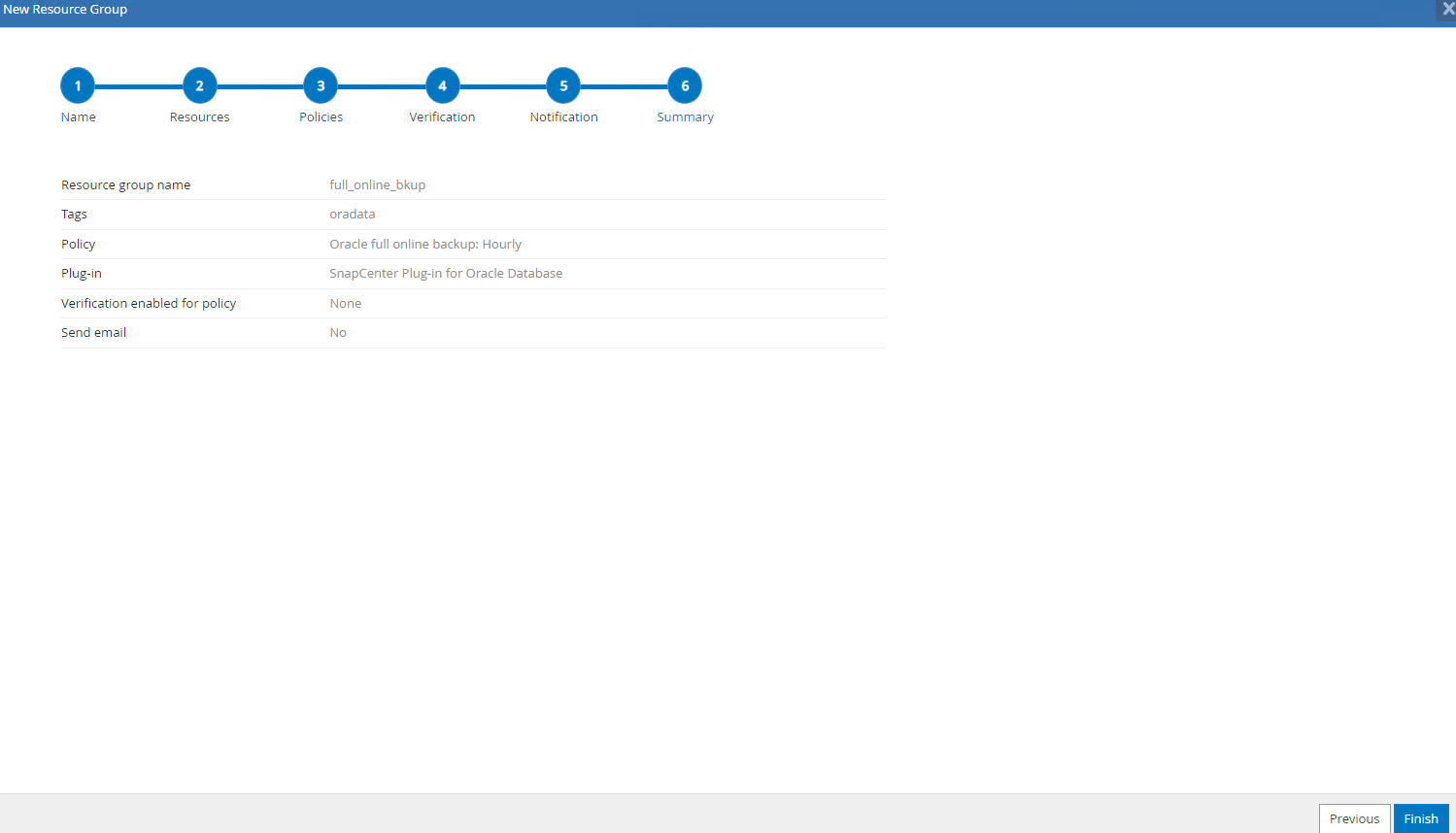
-
Répétez les procédures ci-dessus pour créer une sauvegarde du journal d'archive de base de données uniquement avec la politique de sauvegarde correspondante.
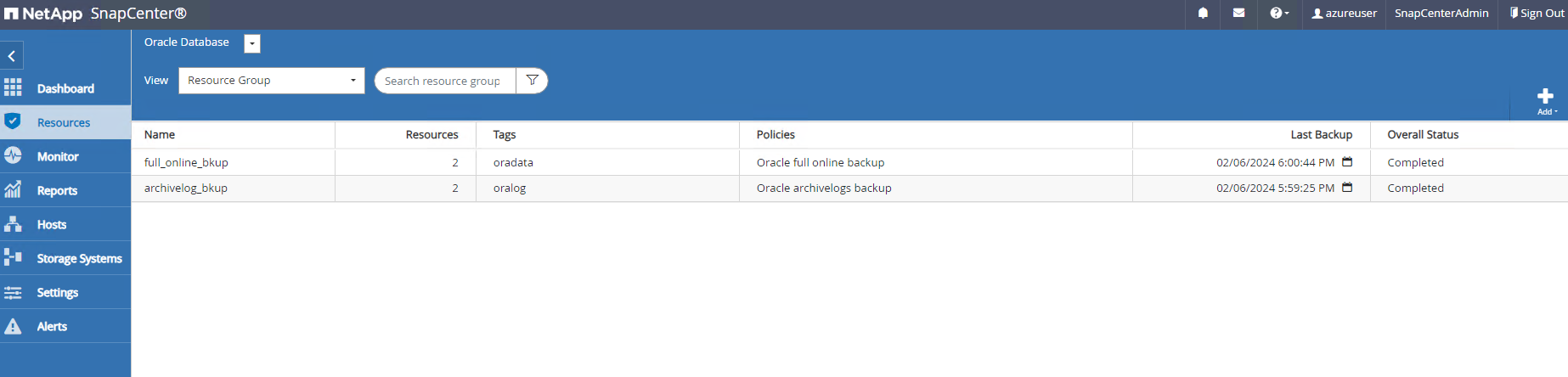
-
Cliquez sur un groupe de ressources pour révéler les ressources qu’il comprend. Outre la tâche de sauvegarde planifiée, une sauvegarde ponctuelle peut être déclenchée en cliquant sur
Backup Now.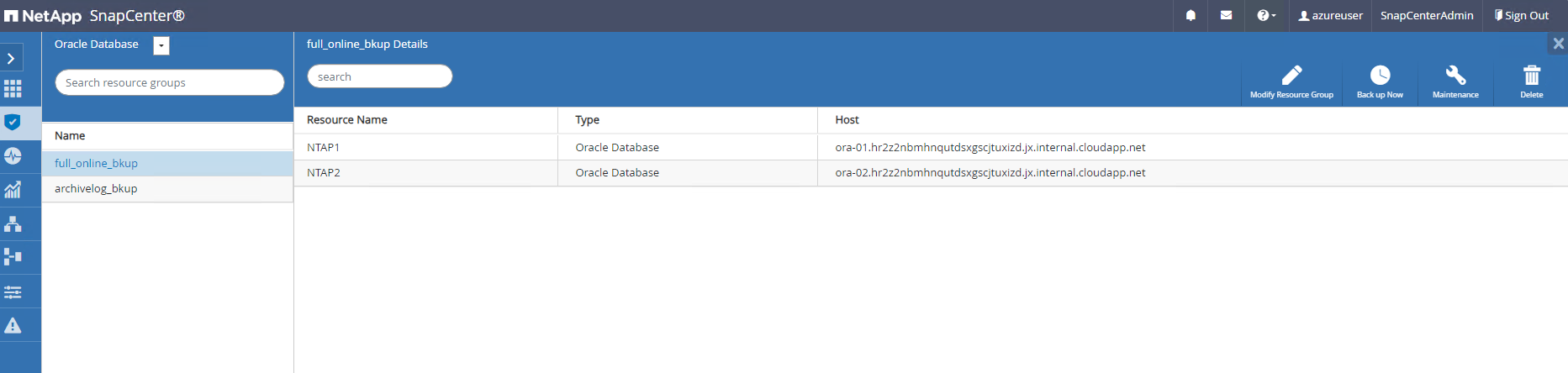
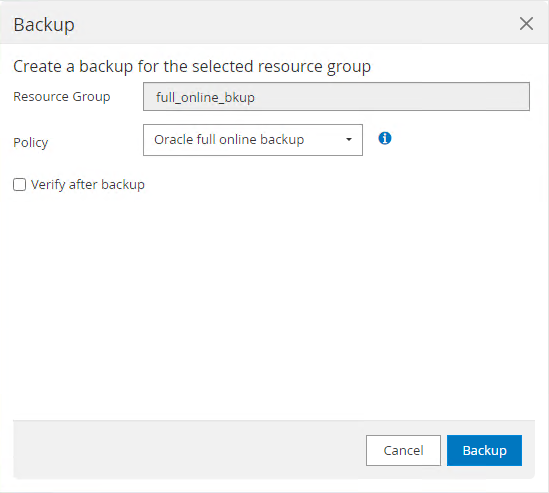
-
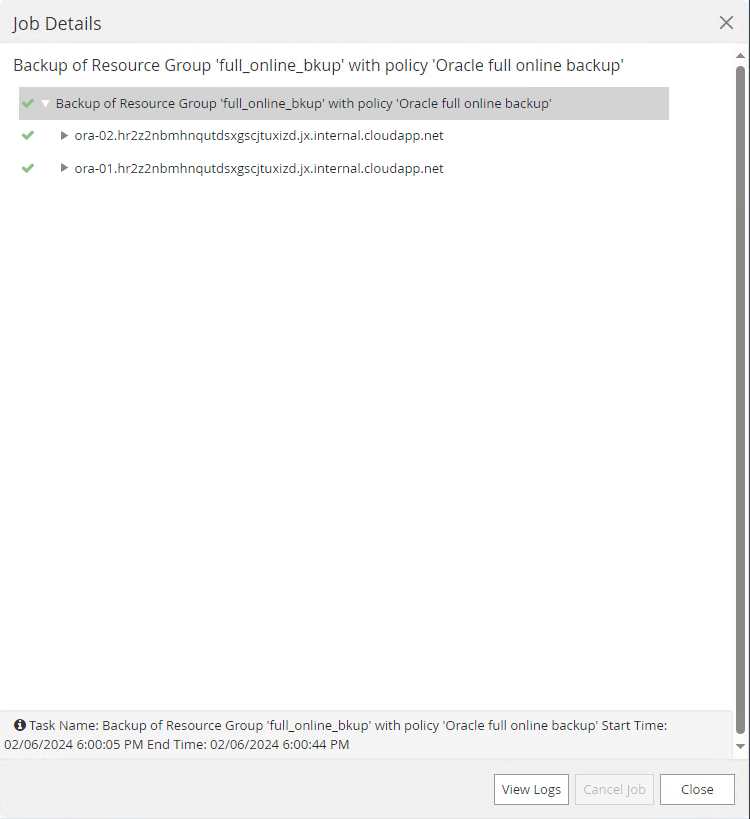
Cliquez sur la tâche en cours pour ouvrir une fenêtre de surveillance, qui permet à l'opérateur de suivre la progression de la tâche en temps réel.
-
Un ensemble de sauvegarde instantanée apparaît sous la topologie de la base de données une fois qu'une tâche de sauvegarde réussie est terminée. Un ensemble de sauvegarde de base de données complet comprend un instantané des volumes de données de la base de données et un instantané des volumes de journaux de la base de données. Une sauvegarde de journal uniquement contient uniquement un instantané des volumes de journal de la base de données.
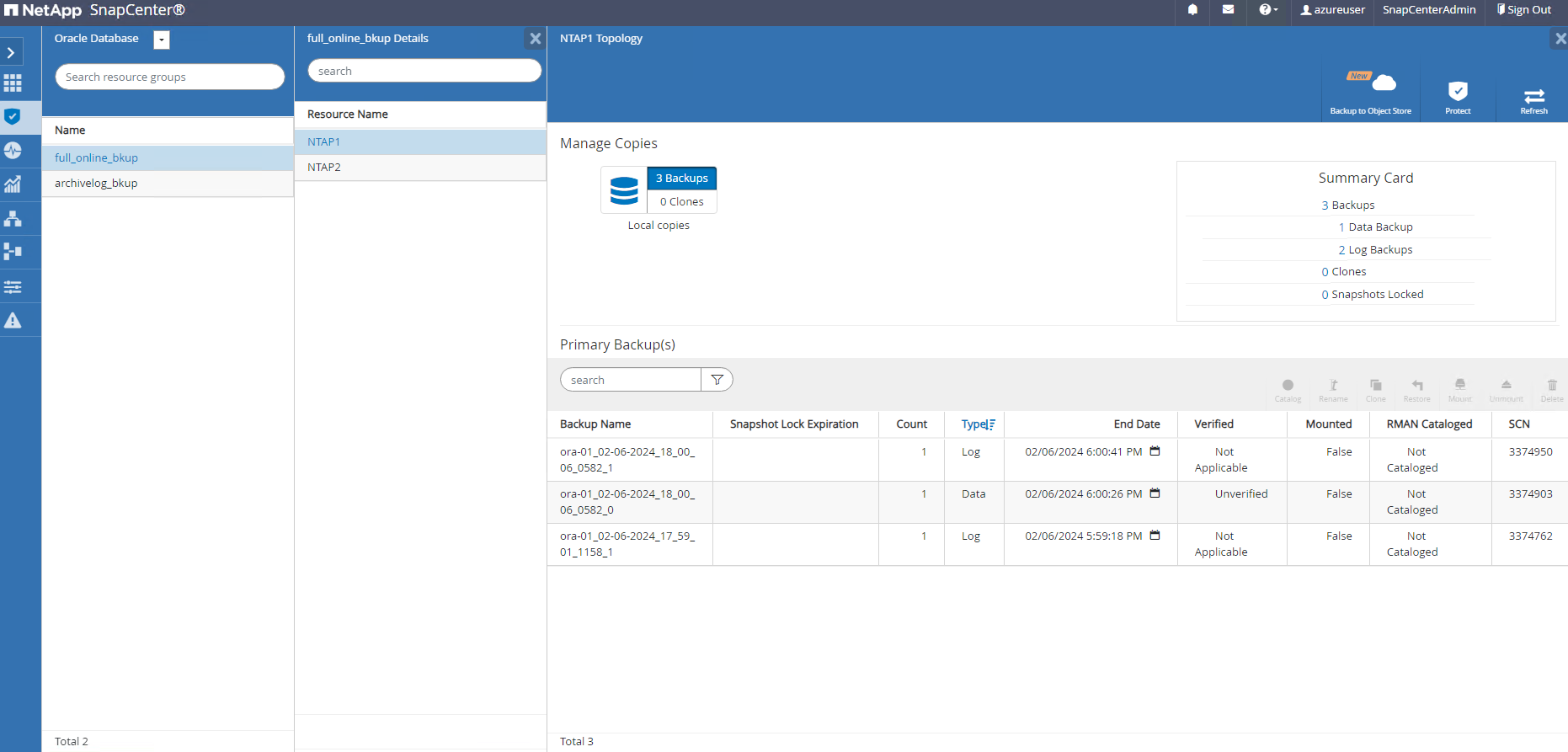
Récupération de base de données
Details
La récupération de base de données via SnapCenter restaure une copie instantanée de l'image du volume de base de données à un moment donné. La base de données est ensuite transférée vers un point souhaité par SCN/horodatage ou un point autorisé par les journaux d'archives disponibles dans le jeu de sauvegarde. La section suivante illustre le flux de travail de récupération de base de données avec l'interface utilisateur SnapCenter .
-
Depuis
Resourcesonglet, ouvrir la base de donnéesPrimary Backup(s)page. Choisissez l'instantané du volume de données de la base de données, puis cliquez surRestorebouton pour lancer le flux de travail de récupération de la base de données. Notez le numéro SCN ou l'horodatage dans les jeux de sauvegarde si vous souhaitez exécuter la récupération par Oracle SCN ou l'horodatage.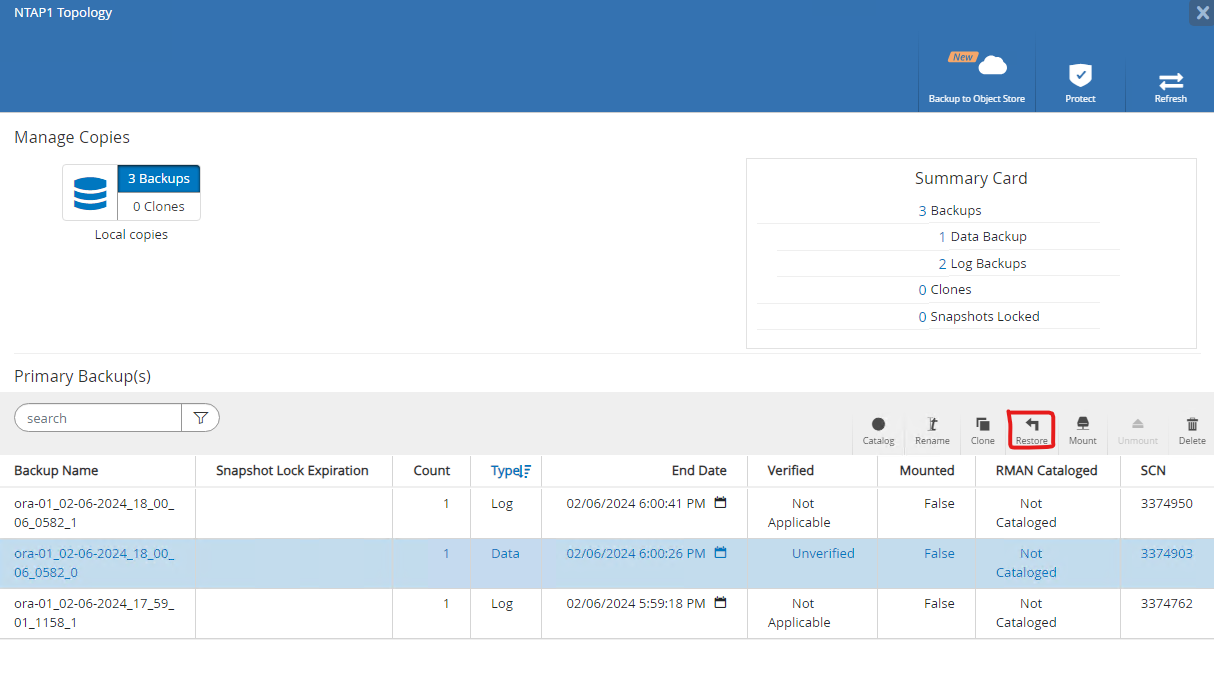
-
Sélectionner
Restore Scope. Pour une base de données de conteneur, SnapCenter est flexible pour effectuer une restauration complète de base de données de conteneur (tous les fichiers de données), de bases de données enfichables ou de niveau tablespaces.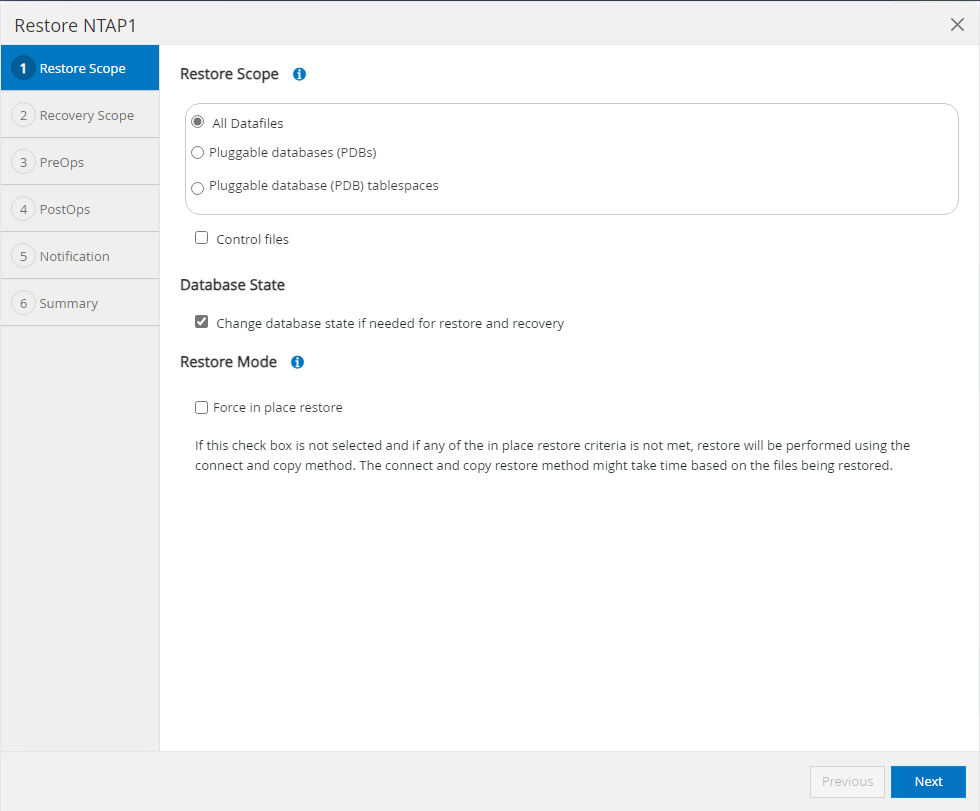
-
Sélectionner
Recovery Scope.All logssignifie appliquer tous les journaux d'archives disponibles dans le jeu de sauvegarde. La récupération ponctuelle par SCN ou horodatage est également disponible.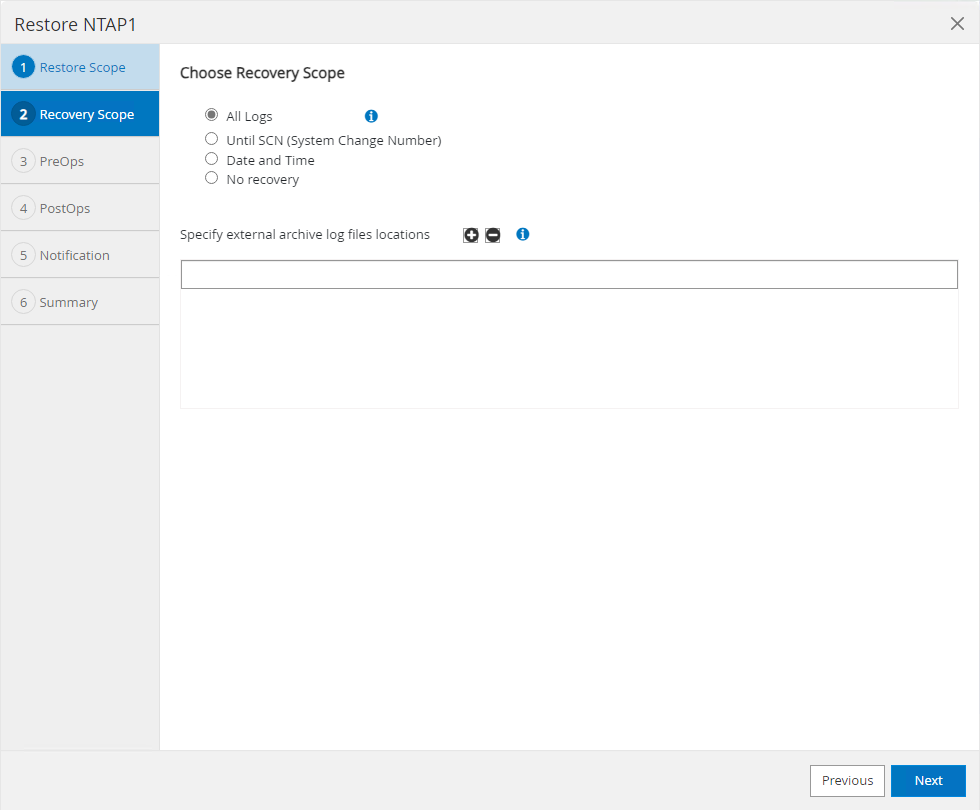
-
Le
PreOpspermet l'exécution de scripts sur la base de données avant l'opération de restauration/récupération.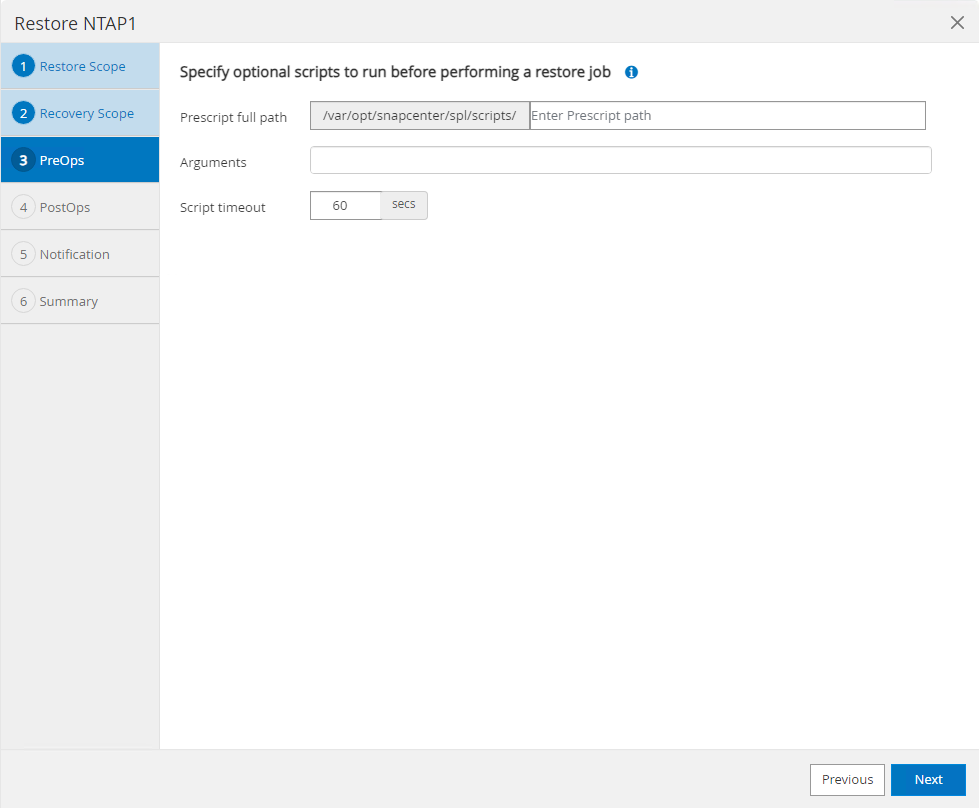
-
Le
PostOpspermet l'exécution de scripts sur la base de données après une opération de restauration/récupération.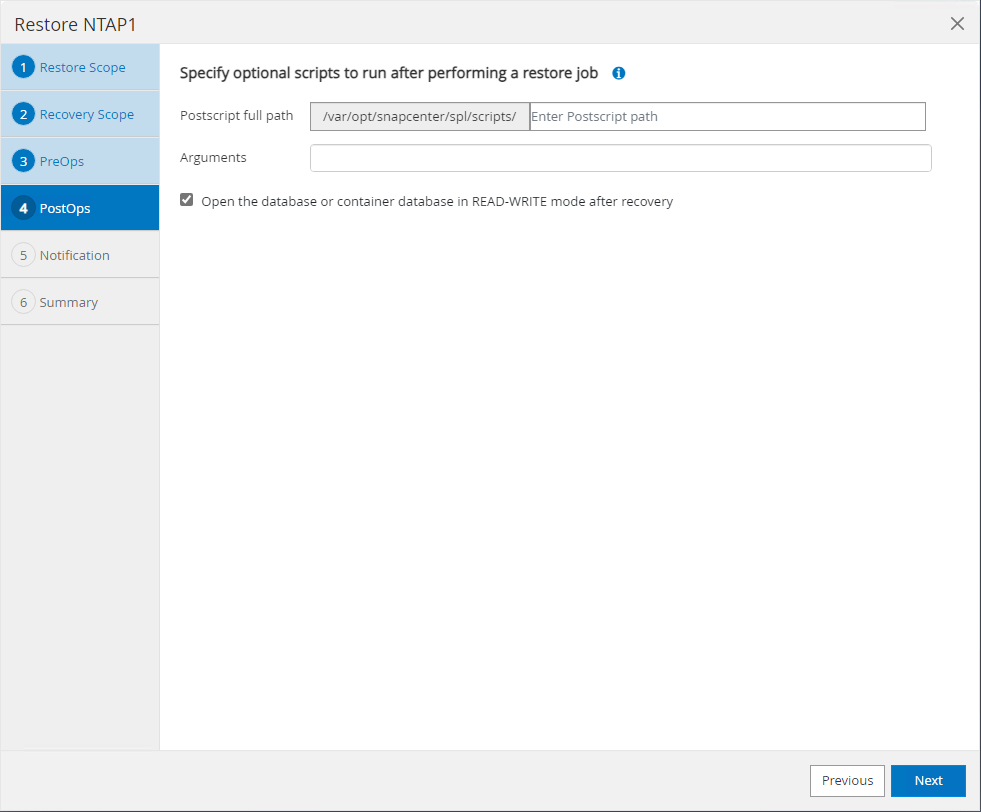
-
Notification par email si vous le souhaitez.
-
Restaurer le résumé du travail
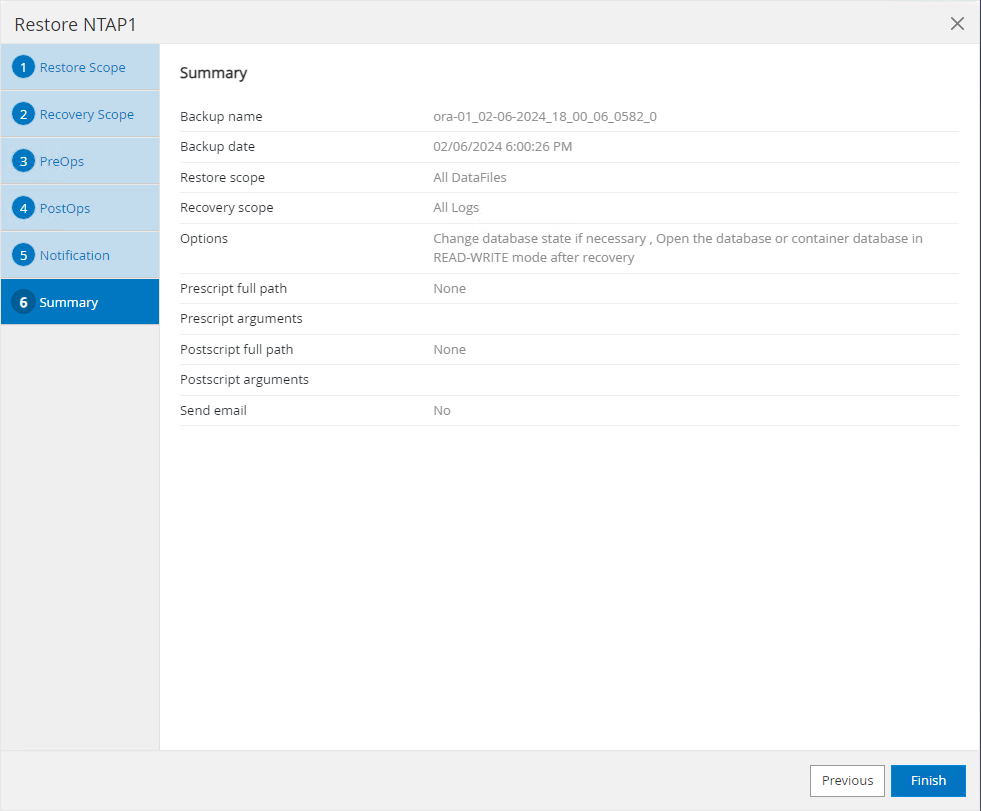
-
Cliquez sur la tâche en cours d'exécution pour l'ouvrir
Job Detailsfenêtre. Le statut du travail peut également être ouvert et visualisé à partir duMonitorlanguette.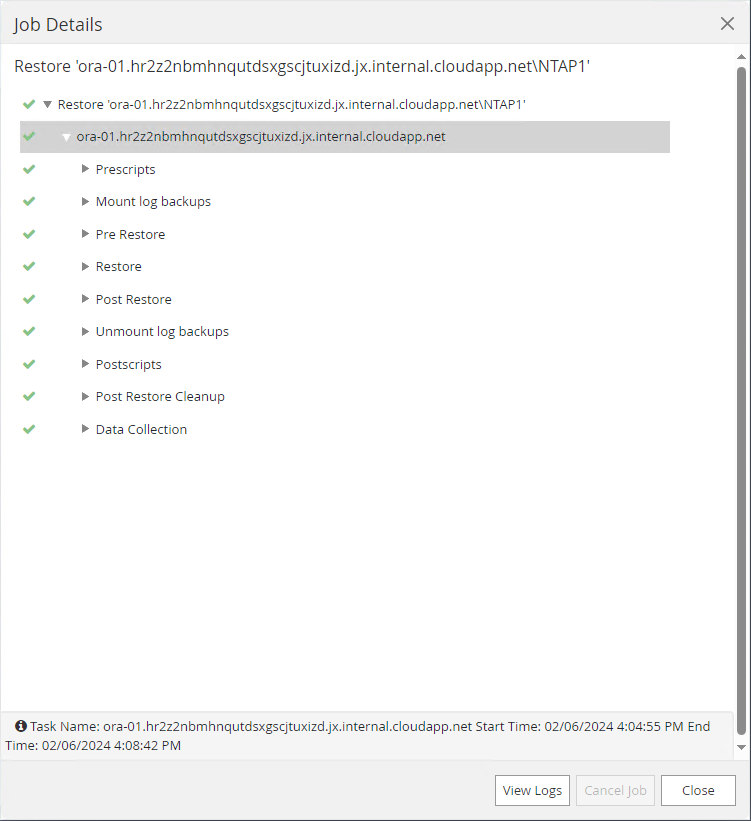
Clonage de base de données
Details
Le clonage de base de données via SnapCenter s'effectue en créant un nouveau volume à partir d'un instantané d'un volume. Le système utilise les informations de capture instantanée pour cloner un nouveau volume à l'aide des données présentes sur le volume lorsque la capture instantanée a été prise. Plus important encore, c'est rapide (quelques minutes) et efficace par rapport à d'autres méthodes pour créer une copie clonée de la base de données de production pour prendre en charge le développement ou les tests. Améliorez ainsi considérablement la gestion du cycle de vie de votre application de base de données. La section suivante illustre le flux de travail du clonage de base de données avec l'interface utilisateur SnapCenter .
-
Depuis
Resourcesonglet, ouvrir la base de donnéesPrimary Backup(s)page. Choisissez l'instantané du volume de données de la base de données, puis cliquez surclonebouton pour lancer le workflow de clonage de la base de données.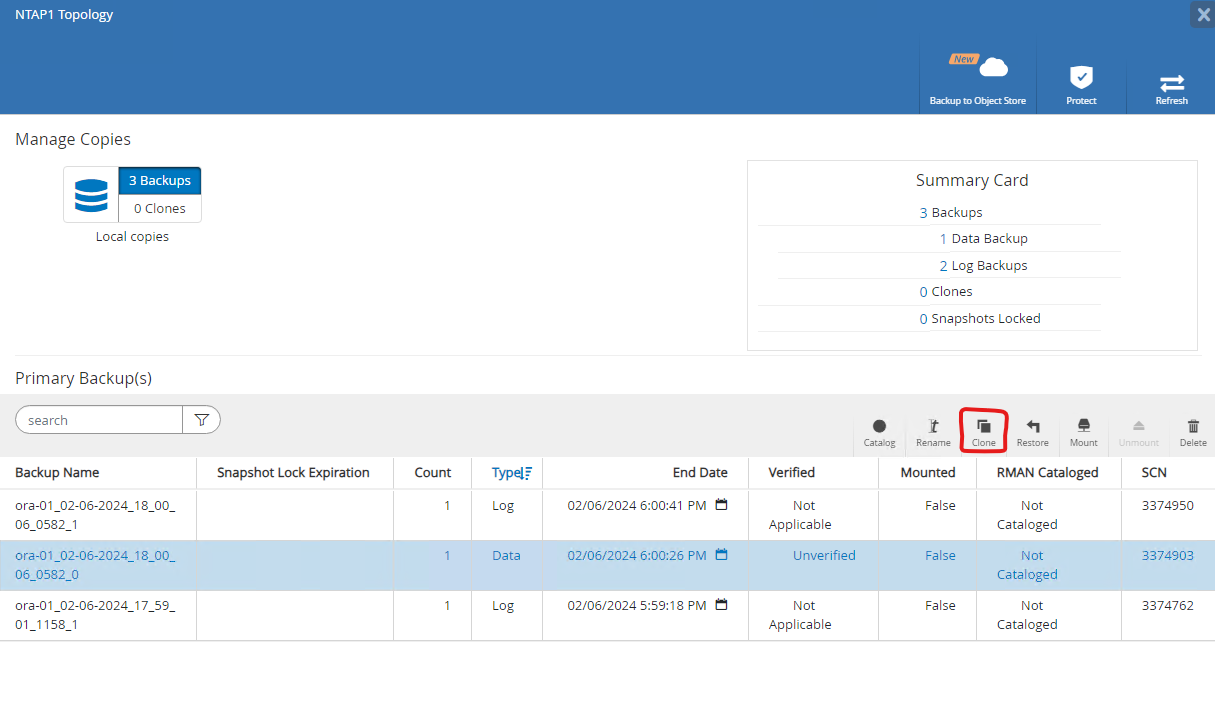
-
Nommez la base de données clone SID. En option, pour une base de données conteneur, le clonage peut également être effectué au niveau PDB.
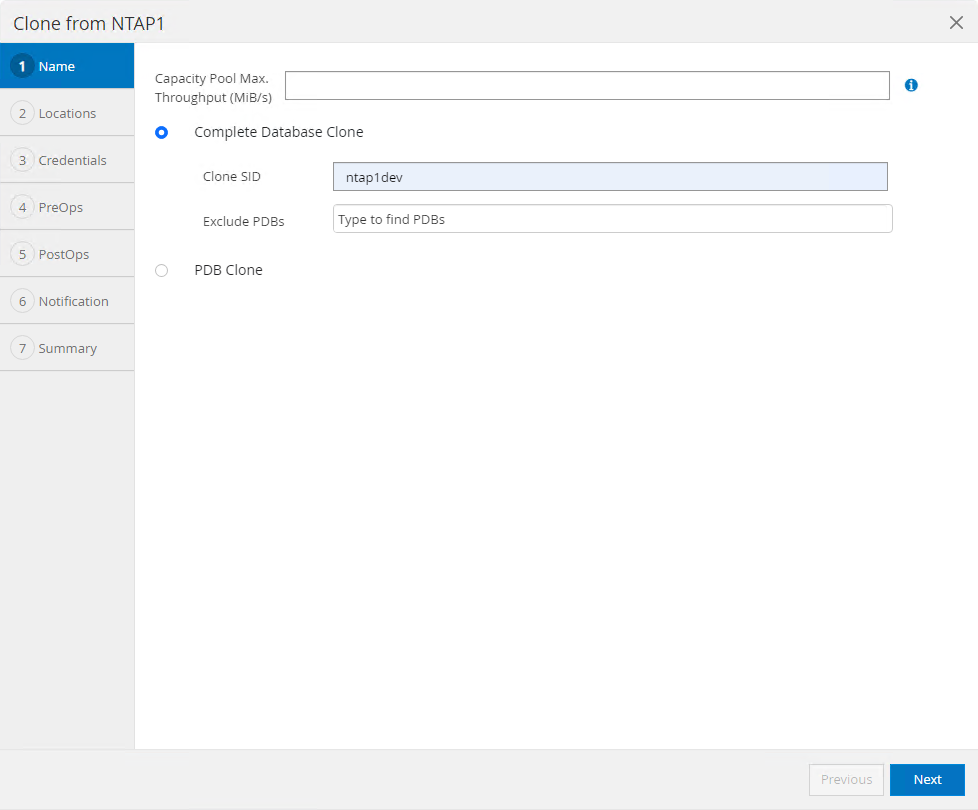
-
Sélectionnez le serveur de base de données sur lequel vous souhaitez placer votre copie de base de données clonée. Conservez les emplacements de fichiers par défaut, sauf si vous souhaitez les nommer différemment.
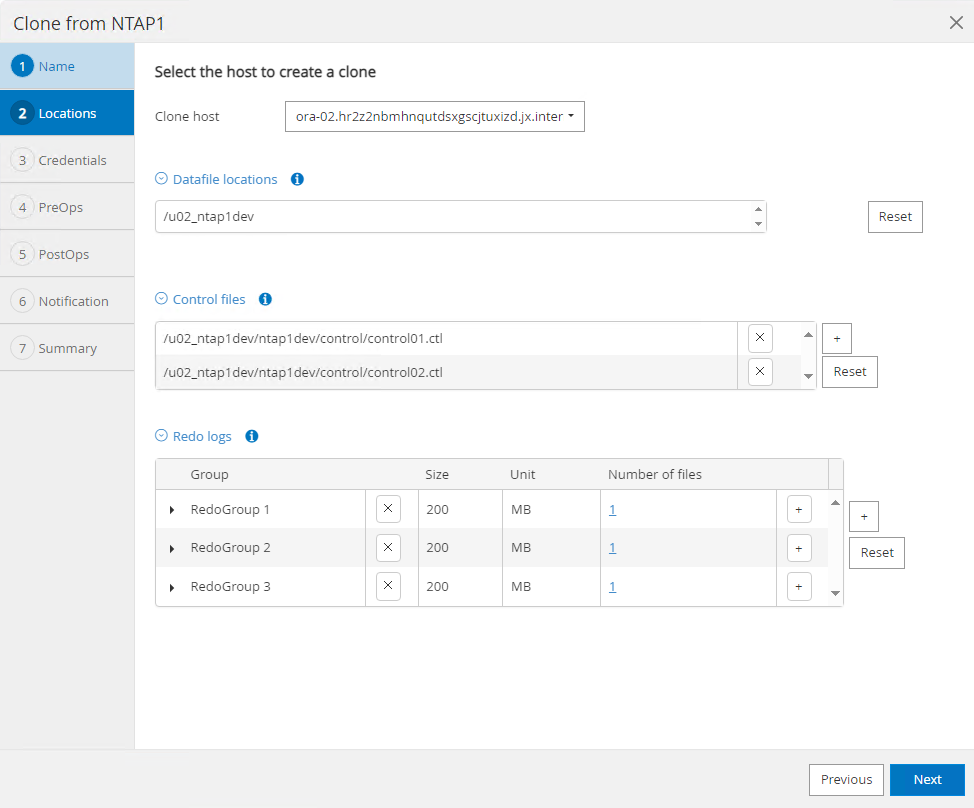
-
La même pile logicielle Oracle que dans la base de données source doit avoir été installée et configurée sur l'hôte de la base de données clonée. Conserver les informations d'identification par défaut mais les modifier
Oracle Home Settingspour correspondre aux paramètres sur l'hôte de la base de données clonée.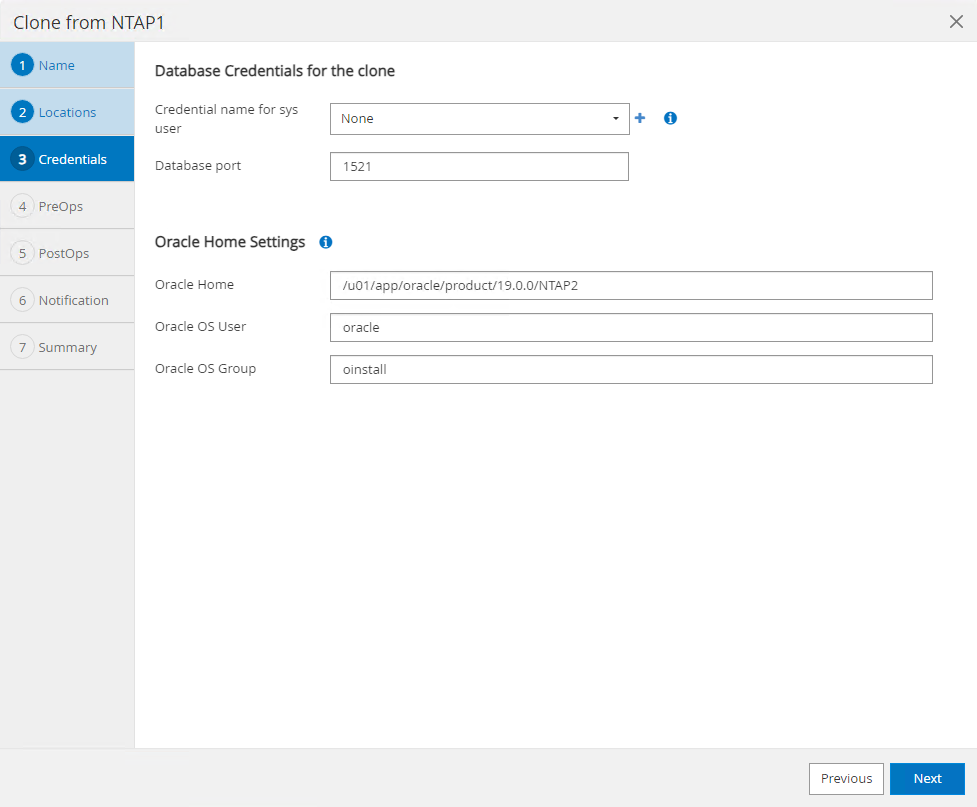
-
Le
PreOpspermet l'exécution de scripts avant l'opération de clonage. Les paramètres de la base de données peuvent être ajustés pour répondre aux besoins d'une base de données clonée par rapport à une base de données de production, comme une cible SGA réduite.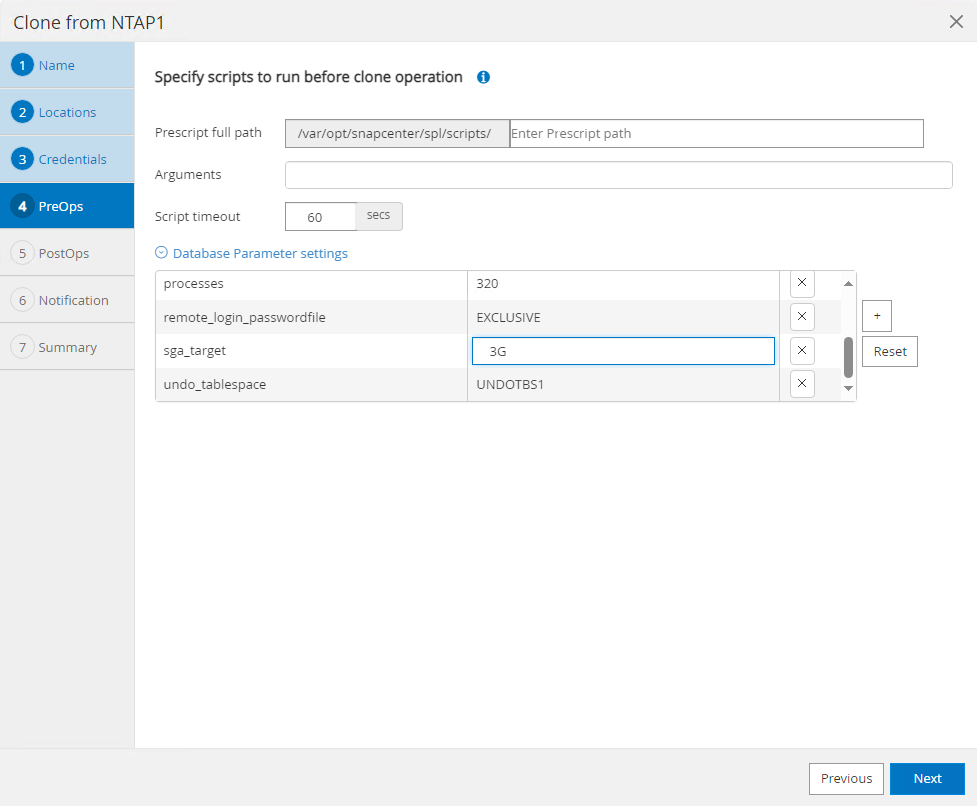
-
Le
PostOpspermet l'exécution de scripts sur la base de données après l'opération de clonage. La récupération de la base de données clonée peut être basée sur le SCN, l'horodatage ou jusqu'à l'annulation (reprise de la base de données jusqu'au dernier journal archivé dans le jeu de sauvegarde).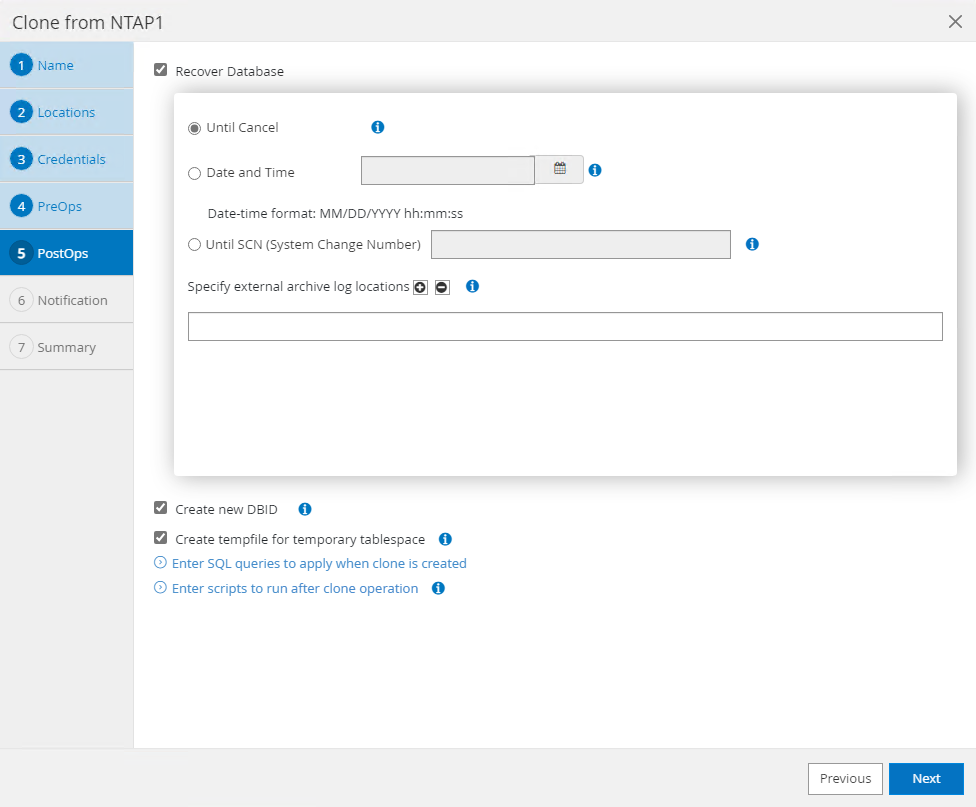
-
Notification par email si vous le souhaitez.
-
Résumé du travail de clonage.
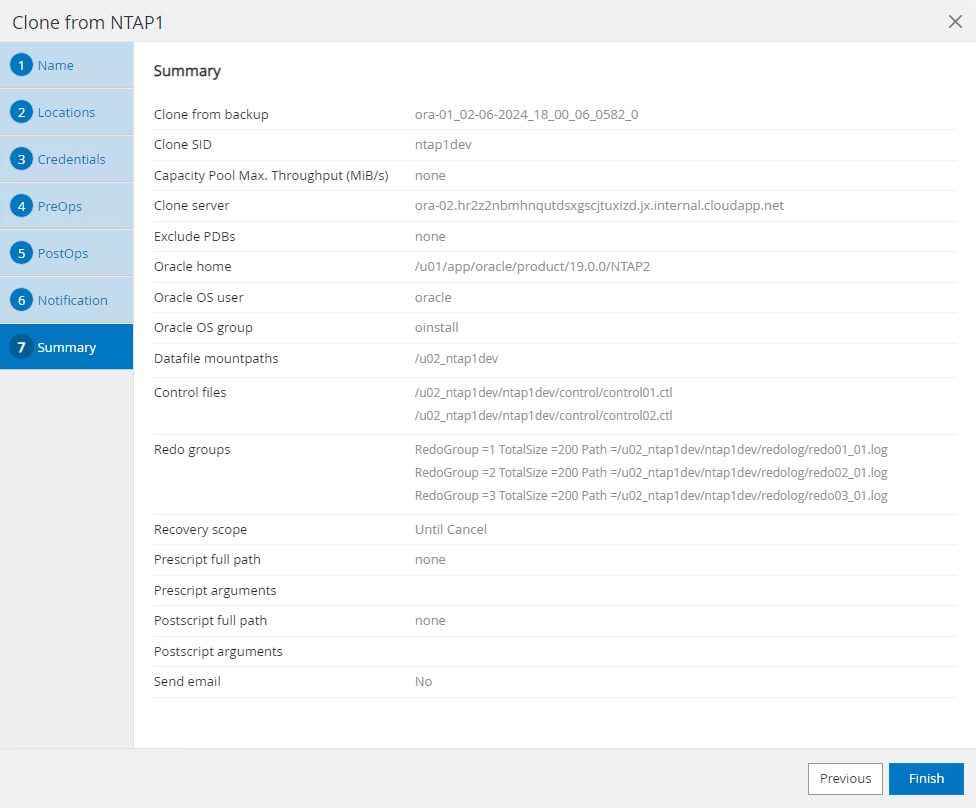
-
Cliquez sur la tâche en cours d'exécution pour l'ouvrir
Job Detailsfenêtre. Le statut du travail peut également être ouvert et visualisé à partir duMonitorlanguette.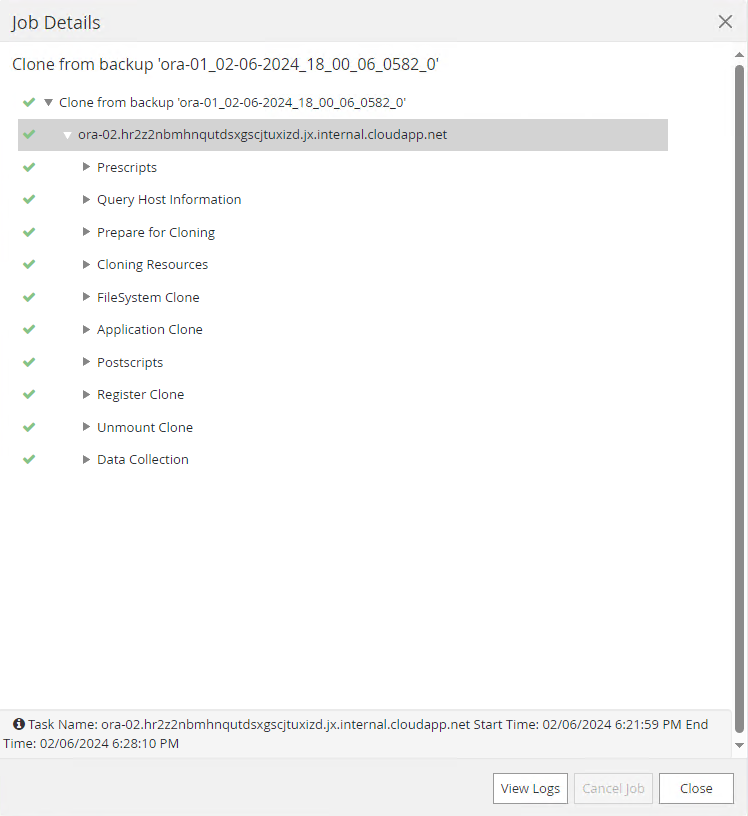
-
La base de données clonée s'enregistre immédiatement auprès de SnapCenter .
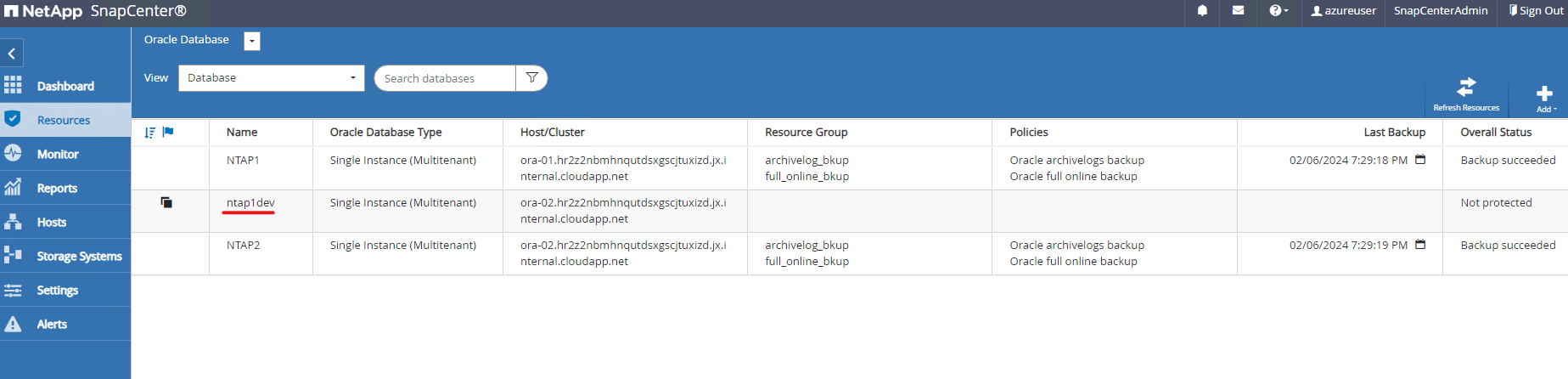
-
Valider la base de données clonée sur l'hôte du serveur DB. Pour une base de données de développement clonée, le mode d'archivage de la base de données doit être désactivé.
[azureuser@ora-02 ~]$ sudo su [root@ora-02 azureuser]# su - oracle Last login: Tue Feb 6 16:26:28 UTC 2024 on pts/0 [oracle@ora-02 ~]$ uname -a Linux ora-02 4.18.0-372.9.1.el8.x86_64 #1 SMP Fri Apr 15 22:12:19 EDT 2022 x86_64 x86_64 x86_64 GNU/Linux [oracle@ora-02 ~]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 49M 7.7G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/mapper/rootvg-rootlv 22G 17G 5.6G 75% / /dev/mapper/rootvg-usrlv 10G 2.0G 8.1G 20% /usr /dev/mapper/rootvg-homelv 1014M 40M 975M 4% /home /dev/sda1 496M 106M 390M 22% /boot /dev/mapper/rootvg-varlv 8.0G 958M 7.1G 12% /var /dev/sda15 495M 5.9M 489M 2% /boot/efi /dev/mapper/rootvg-tmplv 12G 8.4G 3.7G 70% /tmp tmpfs 1.6G 0 1.6G 0% /run/user/54321 172.30.136.68:/ora-02-u03 250G 2.1G 248G 1% /u03 172.30.136.68:/ora-02-u01 100G 10G 91G 10% /u01 172.30.136.68:/ora-02-u02 250G 7.5G 243G 3% /u02 tmpfs 1.6G 0 1.6G 0% /run/user/1000 tmpfs 1.6G 0 1.6G 0% /run/user/0 172.30.136.68:/ora-01-u02-Clone-020624161543077 250G 8.2G 242G 4% /u02_ntap1dev [oracle@ora-02 ~]$ cat /etc/oratab # # This file is used by ORACLE utilities. It is created by root.sh # and updated by either Database Configuration Assistant while creating # a database or ASM Configuration Assistant while creating ASM instance. # A colon, ':', is used as the field terminator. A new line terminates # the entry. Lines beginning with a pound sign, '#', are comments. # # Entries are of the form: # $ORACLE_SID:$ORACLE_HOME:<N|Y>: # # The first and second fields are the system identifier and home # directory of the database respectively. The third field indicates # to the dbstart utility that the database should , "Y", or should not, # "N", be brought up at system boot time. # # Multiple entries with the same $ORACLE_SID are not allowed. # # NTAP2:/u01/app/oracle/product/19.0.0/NTAP2:Y # SnapCenter Plug-in for Oracle Database generated entry (DO NOT REMOVE THIS LINE) ntap1dev:/u01/app/oracle/product/19.0.0/NTAP2:N [oracle@ora-02 ~]$ export ORACLE_SID=ntap1dev [oracle@ora-02 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Tue Feb 6 16:29:02 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select name, open_mode, log_mode from v$database; NAME OPEN_MODE LOG_MODE --------- -------------------- ------------ NTAP1DEV READ WRITE ARCHIVELOG SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount; ORACLE instance started. Total System Global Area 3221223168 bytes Fixed Size 9168640 bytes Variable Size 654311424 bytes Database Buffers 2550136832 bytes Redo Buffers 7606272 bytes Database mounted. SQL> alter database noarchivelog; Database altered. SQL> alter database open; Database altered. SQL> select name, open_mode, log_mode from v$database; NAME OPEN_MODE LOG_MODE --------- -------------------- ------------ NTAP1DEV READ WRITE NOARCHIVELOG SQL> show pdbs CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY NO 3 NTAP1_PDB1 MOUNTED 4 NTAP1_PDB2 MOUNTED 5 NTAP1_PDB3 MOUNTED SQL> alter pluggable database all open;
Où trouver des informations supplémentaires
Pour en savoir plus sur les informations décrites dans ce document, consultez les documents et/ou sites Web suivants :
-
Azure NetApp Files
-
Documentation du logiciel SnapCenter
-
TR-4987 : Déploiement Oracle simplifié et automatisé sur Azure NetApp Files avec NFS