

Présentation de la solution VMware vSphere
 Suggérer des modifications
Suggérer des modifications
Le vCenter Server Appliance (VCSA) est un système de gestion centralisé puissant et une interface unique pour vSphere qui permet aux administrateurs d'exploiter efficacement les clusters ESXi. Il facilite des fonctions clés telles que le provisionnement de machines virtuelles, le fonctionnement de vMotion, la haute disponibilité (HA), le planificateur de ressources distribuées (DRS), VMware vSphere Kubernetes Service (VKS), et bien plus encore. Il s'agit d'un composant essentiel des environnements cloud VMware et sa conception doit tenir compte de la disponibilité du service.
Haute disponibilité vSphere
La technologie de cluster de VMware regroupe les serveurs ESXi en pools de ressources partagées pour les machines virtuelles et fournit la haute disponibilité vSphere (HA). VSphere HA offre une haute disponibilité facile à utiliser pour les applications exécutées sur les machines virtuelles. Lorsque la fonction de haute disponibilité est activée sur le cluster, chaque serveur ESXi maintient la communication avec les autres hôtes de sorte que si un hôte ESXi ne répond plus ou est isolé, le cluster de haute disponibilité peut négocier la restauration des machines virtuelles qui s'exécutaient sur cet hôte ESXi parmi les hôtes survivants du cluster. En cas de panne du système d'exploitation invité, vSphere HA peut redémarrer l'ordinateur virtuel affecté sur le même serveur physique. VSphere HA permet de réduire les temps d'indisponibilité planifiés, d'éviter les temps d'indisponibilité non planifiés et de restaurer rapidement les données en cas de panne.
Cluster vSphere HA récupérant des machines virtuelles à partir d'un serveur défaillant.
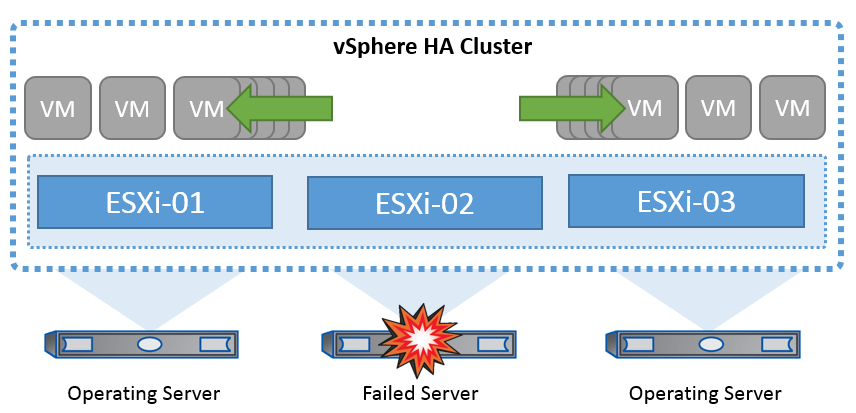
Il est important de comprendre que VMware vSphere ne connaît pas la synchronisation active NetApp MetroCluster ou SnapMirror et que tous les hôtes ESXi du cluster vSphere sont des hôtes éligibles pour les opérations de cluster haute disponibilité selon les configurations d'affinité des groupes de machines virtuelles et des hôtes.
Détection de défaillance de l'hôte
Dès la création du cluster HA, tous les hôtes du cluster participent à une élection, et l'un d'eux devient maître. Chaque esclave envoie un signal de présence au maître, et le maître, à son tour, envoie un signal de présence à tous les hôtes esclaves. L'hôte maître d'un cluster vSphere HA est responsable de la détection des pannes des hôtes esclaves.
En fonction du type de défaillance détecté, les machines virtuelles exécutées sur les hôtes peuvent avoir besoin d'être basculées.
Dans un cluster vSphere HA, trois types de défaillance d'hôte sont détectés :
-
Défaillance - Un hôte cesse de fonctionner.
-
Isolation - Un hôte devient isolé du réseau.
-
Partition : Un hôte perd la connectivité réseau avec l'hôte maître.
L'hôte maître surveille les hôtes esclaves du cluster. Cette communication s'effectue par échange de battements de cœur réseau toutes les secondes. Lorsque l'hôte maître cesse de recevoir ces battements de cœur d'un hôte esclave, il vérifie la livenité de l'hôte avant de déclarer l'échec de l'hôte. La vérification de la livenité effectuée par l'hôte maître consiste à déterminer si l'hôte esclave échange des pulsations avec l'un des datastores. En outre, l'hôte maître vérifie si l'hôte répond aux requêtes ping ICMP envoyées à ses adresses IP de gestion pour détecter s'il est simplement isolé de son nœud maître ou complètement isolé du réseau. Pour ce faire, il exécute une commande ping sur la passerelle par défaut. Une ou plusieurs adresses d'isolement peuvent être spécifiées manuellement pour améliorer la fiabilité de la validation de l'isolement.

|
NetApp recommande de spécifier au moins deux adresses d'isolement supplémentaires, et que chacune de ces adresses soit site-local. Cela améliorera la fiabilité de la validation de l'isolement. |
Réponse d'isolation de l'hôte
La réponse d'isolation est un paramètre de vSphere HA qui détermine l'action déclenchée sur les machines virtuelles lorsqu'un hôte d'un cluster vSphere HA perd ses connexions réseau de gestion mais continue de fonctionner. Il existe trois options pour ce paramètre : « Désactivé », « Arrêter et redémarrer les machines virtuelles » et « Mettre hors tension et redémarrer les machines virtuelles ».
« Éteindre » est préférable à « Mettre hors tension », qui ne sauvegarde pas les modifications les plus récentes sur le disque ni ne valide les transactions. Si les machines virtuelles ne se sont pas arrêtées au bout de 300 secondes, elles sont mises hors tension. Pour modifier le délai d'attente, utilisez l'option avancée das.isolationshutdowntimeout.
Avant que la haute disponibilité ne lance la réponse d'isolation, elle vérifie d'abord si l'agent principal vSphere HA possède le datastore qui contient les fichiers de configuration de la machine virtuelle. Si ce n'est pas le cas, l'hôte ne déclenchera pas la réponse d'isolation, car il n'y a pas de maître pour redémarrer les machines virtuelles. L'hôte vérifie régulièrement l'état du datastore pour déterminer s'il est demandé par un agent vSphere HA qui détient le rôle principal.
|
|
NetApp recommande de définir la « réponse d'isolation de l'hôte » sur Désactivé. |
Une condition de split-brain peut se produire si un hôte est isolé ou partitionné à partir de l'hôte maître vSphere HA et que le maître ne peut pas communiquer via des datastores heartbeat ou par ping. Le maître déclare l'hôte isolé comme étant mort et redémarre les machines virtuelles sur les autres hôtes du cluster. Une condition de split-brain existe maintenant parce qu'il y a deux instances de la machine virtuelle en cours d'exécution, dont une seule peut lire ou écrire les disques virtuels. Il est désormais possible d'éviter les conditions de split-brain en configurant VM Component protection (VMCP).
Protection des composants VM (VMCP)
L'une des améliorations de vSphere 6, concernant la haute disponibilité, est VMCP. VMCP offre une protection améliorée contre les conditions de tous les chemins d'accès (APD) et de perte permanente de périphérique (PDL) pour le stockage bloc (FC, iSCSI, FCoE) et de fichiers (NFS).
Perte permanente de périphérique (PDL)
Une PDL (Perte de Stockage Permanente) est une situation qui se produit lorsqu'un périphérique de stockage tombe définitivement en panne ou est supprimé administrativement et ne devrait pas être remis en service. La baie de stockage NetApp émet un code SCSI Sense vers ESXi, indiquant que le périphérique est définitivement perdu. Dans la section Conditions de défaillance et réponse de la machine virtuelle de vSphere HA, vous pouvez configurer la réponse à apporter après la détection d'une condition PDL.
|
|
NetApp recommande de configurer la « Réponse pour la banque de données avec PDL » sur « Mettre hors tension et redémarrer les machines virtuelles ». Lorsque cette condition est détectée, la machine virtuelle sera redémarrée instantanément sur un hôte sain au sein du cluster vSphere HA. |
Tous les chemins en panne (APD)
L'APD est une condition qui se produit lorsqu'un périphérique de stockage devient inaccessible à l'hôte et qu'aucun chemin d'accès à la baie n'est disponible. ESXi considère qu'il s'agit d'un problème temporaire concernant le périphérique et prévoit qu'il sera de nouveau disponible.
Lorsqu'une condition APD est détectée, une minuterie démarre. Au bout de 140 secondes, la condition APD est officiellement déclarée et le périphérique est marqué comme étant hors délai APD. Lorsque les 140 secondes sont écoulées, la haute disponibilité commence à compter le nombre de minutes spécifié dans le délai d'attente pour le basculement de machine virtuelle. Une fois le délai spécifié écoulé, la haute disponibilité redémarre les machines virtuelles impactées. Vous pouvez configurer VMCP pour qu'il réponde différemment si vous le souhaitez (désactivé, événements de problème ou mise hors tension et redémarrage des machines virtuelles).
|
|
|
Implémentation de VMware DRS pour NetApp SnapMirror Active Sync
VMware DRS est une fonctionnalité qui regroupe les ressources hôtes dans un cluster et est principalement utilisée pour équilibrer la charge au sein d'un cluster dans une infrastructure virtuelle. VMware DRS calcule principalement les ressources CPU et mémoire pour effectuer l'équilibrage de charge dans un cluster. Étant donné que vSphere ne connaît pas la mise en cluster étendue, il prend en compte tous les hôtes des deux sites lors de l'équilibrage de charge.
Implémentation de VMware DRS pour NetApp MetroCluster
To avoid cross-site traffic, NetApp recommends configuring DRS affinity rules to manage a logical separation of VMs. This will ensure that, unless there is a complete site failure, HA and DRS will only use local hosts. Si vous créez une règle d'affinité DRS pour votre cluster, vous pouvez spécifier comment vSphere applique cette règle lors du basculement d'une machine virtuelle.
Vous pouvez spécifier deux types de règles pour le comportement de basculement de vSphere HA :
-
Les règles d'anti-affinité pour les machines virtuelles forcent les machines virtuelles spécifiées à rester séparées pendant les opérations de basculement.
-
Les règles d'affinité des hôtes VM placent les machines virtuelles spécifiées sur un hôte particulier ou un membre d'un groupe défini d'hôtes lors des actions de basculement.
En utilisant les règles d'affinité pour les hôtes de machine virtuelle dans VMware DRS, il est possible d'avoir une séparation logique entre le site A et le site B, de sorte que la machine virtuelle s'exécute sur l'hôte au même site que la baie configurée comme contrôleur de lecture/écriture principal pour un datastore donné. De plus, les règles d'affinité des hôtes de VM permettent aux machines virtuelles de rester locales au stockage, ce qui à son tour ascert la connexion de la machine virtuelle en cas de défaillances réseau entre les sites.
Voici un exemple de groupes d'hôtes de machine virtuelle et de règles d'affinité.
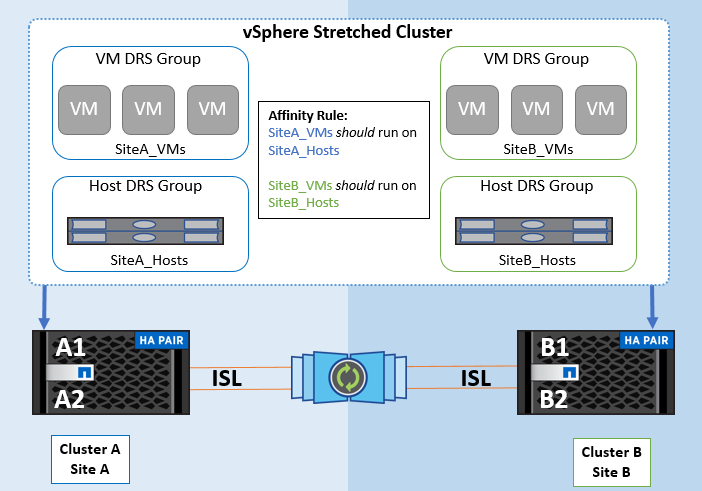
Meilleure pratique
NetApp recommande de mettre en place des règles « à respecter » plutôt que des règles « à respecter », car elles sont violées par vSphere HA en cas de défaillance. L'utilisation de règles « must » peut entraîner des interruptions de service.
La disponibilité des services doit toujours primer sur leur performance. Dans le cas où un centre de données entier tombe en panne, les règles « obligatoires » doivent choisir les hôtes du groupe d'affinité des hôtes de machines virtuelles, et lorsque le centre de données est indisponible, les machines virtuelles ne redémarrent pas.
Implémentation de VMware Storage DRS avec NetApp MetroCluster
La fonctionnalité VMware Storage DRS permet l'agrégation de datastores dans une seule unité et équilibre les disques de machines virtuelles lorsque les seuils de contrôle des E/S du stockage (SIOC) sont dépassés.
Le contrôle des E/S du stockage est activé par défaut sur les clusters DRS compatibles avec Storage DRS. Le contrôle des E/S du stockage permet à un administrateur de contrôler la quantité d'E/S de stockage allouée aux serveurs virtuels pendant les périodes d'encombrement des E/S. Ainsi, les serveurs virtuels plus importants sont préfénables aux serveurs virtuels moins importants pour l'allocation des ressources d'E/S.
Storage DRS utilise Storage vMotion pour migrer les machines virtuelles vers différents datastores au sein d'un cluster de datastores. Dans un environnement NetApp MetroCluster, la migration des machines virtuelles doit être contrôlée dans les datastores de ce site. Par exemple, la machine virtuelle A, qui s'exécute sur un hôte du site A, doit idéalement migrer au sein des datastores du SVM sur le site A. Si ce n'est pas le cas, la machine virtuelle continue à fonctionner mais avec des performances dégradées, puisque la lecture/l'écriture du disque virtuel se fera à partir du site B via des liens inter-sites.
|
|
*Lors de l'utilisation du stockage ONTAP, il est recommandé de désactiver Storage DRS.
|