

Considérations relatives à l'utilisation de ONTAP dans une configuration MetroCluster
 Suggérer des modifications
Suggérer des modifications
Lorsque vous utilisez ONTAP dans une configuration MetroCluster, vous devez tenir compte de certaines considérations en matière de licence, de peering vers des clusters en dehors de la configuration MetroCluster, d'exécution des opérations de volume, des opérations NVFAIL et d'autres opérations ONTAP.
-
Les deux sites doivent bénéficier d'une licence pour les mêmes fonctionnalités du site.
-
Tous les nœuds doivent être sous licence pour les mêmes fonctionnalités verrouillées par des nœuds.
-
La reprise après incident de SnapMirror sur les SVM n'est prise en charge que sur les configurations MetroCluster qui exécutent les versions de ONTAP 9.5 ou ultérieures.
Prise en charge de FlexCache dans une configuration MetroCluster
Les volumes FlexCache sont pris en charge sur les configurations MetroCluster depuis ONTAP 9.7. Il est important de connaître les exigences relatives à la dépelage manuel après les opérations de basculement ou de rétablissement.
SVM abroge après le basculement lorsque l'origine et le cache FlexCache se trouvent sur le même site MetroCluster
Après un basculement négocié ou non planifié, toute relation de peering de SVM FlexCache au sein du cluster doit être configurée manuellement.
Par exemple, les SVM « vs1 » (cache) et « vs2 » (origine) se trouvent sur site_A. Ces SVM sont peering.
Après le basculement, les SVM « vs1-mc » et « vs2-mc » sont activés sur le site partenaire (site_B). Elles doivent être abrogés manuellement pour que FlexCache fonctionne avec vserver peer repeer commande.
SVM abroge après le basculement ou le rétablissement lorsqu'une destination FlexCache se trouve sur un troisième cluster et en mode déconnecté
Pour les relations FlexCache sur un cluster en dehors de la configuration MetroCluster, le peering doit toujours être reconfiguré manuellement après un basculement si les clusters concernés sont en mode déconnecté lors du basculement.
Par exemple :
-
L'une des extrémités du FlexCache (cache_1 sur vs1) se trouve sur MetroCluster site_A.
-
L'autre extrémité du FlexCache (origine_1 sur vs2) se trouve sur site_C (pas dans la configuration MetroCluster).
Lorsque le basculement est déclenché et si les sites_A et site_C ne sont pas connectés, vous devez modifier manuellement les SVM sur site_B (le cluster de basculement) et site_C à l'aide du vserver peer repeer commande après le basculement.
Lorsque le rétablissement s'effectue, vous devez à nouveau abroger les SVM du site_A (le cluster d'origine) et du site_C.
"Gestion des volumes FlexCache via l'interface de ligne de commandes"
Prise en charge de FabricPool dans les configurations MetroCluster
Depuis ONTAP 9.7, les configurations MetroCluster prennent en charge les niveaux de stockage FabricPool.
Pour des informations générales sur l'utilisation de FabricPool, voir "Gestion des disques et des niveaux (agrégat)".
Considérations à prendre en compte lors de l'utilisation de FabricPool
-
Les clusters doivent disposer de licences FabricPool correspondant aux limites de capacité.
-
Les clusters doivent disposer d'IPspaces avec des noms correspondant.
Il peut s'agir de l'IPspace par défaut, ou bien d'un IPspace créé par un administrateur. Cet IPspace sera utilisé pour les configurations de magasin d'objets FabricPool.
-
Pour l'IPspace sélectionné, chaque cluster doit avoir une LIF intercluster définie qui peut atteindre le magasin d'objets externe.
-
La migration des SVM n'est pas prise en charge avec FabricPool lorsque la source ou la destination est un cluster MetroCluster.
Configuration d'un agrégat à utiliser dans une FabricPool en miroir

|
Avant de configurer l'agrégat, vous devez configurer les magasins d'objets comme décrit dans "Configurez les magasins d'objets pour FabricPool dans une configuration MetroCluster". |
Pour configurer un agrégat afin de l'utiliser dans une FabricPool :
-
Création de l'agrégat ou sélection d'un agrégat existant.
-
Mettre en miroir l'agrégat en tant qu'agrégat en miroir standard au sein de la configuration MetroCluster.
-
Créer le miroir FabricPool avec l'agrégat, comme décrit dans la "Gestion des disques et des agrégats"
-
Attacher un magasin d'objets primaire.
Ce magasin d'objets est physiquement plus proche du cluster.
-
Ajouter un magasin d'objets symétriques.
Ce magasin d'objets est physiquement plus éloigné du cluster que le magasin d'objets primaire.
-
|
|
Pour optimiser les performances et la disponibilité du stockage, il est recommandé de conserver au moins 20 % d'espace libre pour les agrégats en miroir. Bien que la recommandation soit de 10 % pour les agrégats non mis en miroir, le système de fichiers peut utiliser 10 % d'espace supplémentaire pour absorber les modifications incrémentielles. Les modifications incrémentielles augmentent l'utilisation de l'espace pour les agrégats en miroir grâce à l'architecture Snapshot d'ONTAP basée sur la copie en écriture. Le non-respect de ces meilleures pratiques peut avoir un impact négatif sur les performances. |
Prise en charge de FlexGroup dans les configurations MetroCluster
Depuis la version ONTAP 9.6, les configurations MetroCluster prennent en charge les volumes FlexGroup.
Prise en charge des groupes de cohérence dans les configurations MetroCluster
ONTAP 9.11.1 et "groupes de cohérence" Sont prises en charge dans les configurations MetroCluster.
Planifications de travaux dans une configuration MetroCluster
Dans ONTAP 9.3 et les versions ultérieures, la planification des tâches créées par l'utilisateur est automatiquement répliquée entre les clusters dans une configuration MetroCluster. Si vous créez, modifiez ou supprimez un programme de travaux sur un cluster, le même programme est automatiquement créé sur le cluster partenaire à l'aide du service de réplication de configuration (CRS).
|
|
Les planifications créées par le système ne sont pas répliquées et vous devez effectuer manuellement la même opération sur le cluster partenaire afin que les planifications de tâches sur les deux clusters soient identiques. |
Peering de cluster depuis le site de MetroCluster vers un troisième cluster
Étant donné que la configuration de peering n'est pas répliquée, si vous peer l'un des clusters de la configuration MetroCluster sur un troisième cluster en dehors de cette configuration, vous devez également configurer le peering sur le cluster partenaire MetroCluster. Cela permet de maintenir le peering en cas de basculement.
Le cluster non MetroCluster doit exécuter ONTAP 8.3 ou une version ultérieure. Si ce n'est pas le cas, le peering est perdu en cas de basculement, même si le peering a été configuré sur les deux partenaires de MetroCluster.
Réplication de la configuration du client LDAP dans une configuration MetroCluster
Une configuration client LDAP créée sur un SVM (Storage Virtual machine) sur un cluster local est répliquée vers son SVM de données partenaire sur le cluster distant. Par exemple, si la configuration client LDAP est créée sur le SVM d'administration au sein du cluster local, il est répliqué sur tous les SVM de données d'administration au sein du cluster distant. Cette fonctionnalité de MetroCluster est intentionnelle, ce qui signifie que la configuration du client LDAP est active sur tous les SVM partenaires du cluster distant.
Instructions de création de LIF et de mise en réseau pour les configurations MetroCluster
Il est important de savoir comment les LIF sont créées et répliquées dans une configuration MetroCluster. Vous devez également connaître l'exigence de cohérence afin de pouvoir prendre les bonnes décisions lors de la configuration de votre réseau.
-
Il est important de connaître les exigences relatives à la réplication d'objets IPspace vers le cluster partenaire et à la configuration des sous-réseaux et IPv6 dans une configuration MetroCluster.
-
Lors de la configuration du réseau dans une configuration MetroCluster, il est important de connaître les conditions requises pour la création des LIFs.
-
Il est important de connaître les exigences de réplication de la LIF dans une configuration MetroCluster. Vous devez également savoir comment placer une LIF répliquée sur un cluster partenaire, et vous devez connaître les problèmes qui se produisent en cas de défaillance de la réplication LIF ou du placement de LIF.
Exigences de configuration de sous-réseau et de réplication d'objets IPspace
Il est important de connaître les exigences relatives à la réplication d'objets IPspace vers le cluster partenaire et à la configuration des sous-réseaux et IPv6 dans une configuration MetroCluster.
Réplication IPspace
Lors de la réplication d'objets IPspace vers le cluster partenaire, vous devez prendre en compte les instructions suivantes :
-
Les noms IPspace des deux sites doivent correspondre.
-
Les objets IPspace doivent être répliqués manuellement sur le cluster partenaire.
Toute machine virtuelle de stockage (SVM) créée et attribuée à un IPspace avant la réplication de l'IPspace ne sera pas répliquée au cluster partenaire.
Configuration de sous-réseau
Lors de la configuration des sous-réseaux dans une configuration MetroCluster, vous devez tenir compte des consignes suivantes :
-
Les deux clusters de la configuration MetroCluster doivent avoir un sous-réseau dans le même IPspace avec le même nom de sous-réseau, sous-réseau, domaine de diffusion et passerelle.
-
La plage IP des deux clusters doit être différente.
Dans l'exemple suivant, les plages IP sont différentes :
cluster_A::> network subnet show IPspace: Default Subnet Broadcast Avail/ Name Subnet Domain Gateway Total Ranges --------- ---------------- --------- ------------ ------- --------------- subnet1 192.168.2.0/24 Default 192.168.2.1 10/10 192.168.2.11-192.168.2.20 cluster_B::> network subnet show IPspace: Default Subnet Broadcast Avail/ Name Subnet Domain Gateway Total Ranges --------- ---------------- --------- ------------ -------- --------------- subnet1 192.168.2.0/24 Default 192.168.2.1 10/10 192.168.2.21-192.168.2.30
Configuration IPv6
Si IPv6 est configuré sur un site, IPv6 doit également être configuré sur l'autre site.
-
Lors de la configuration du réseau dans une configuration MetroCluster, il est important de connaître les conditions requises pour la création des LIFs.
-
Il est important de connaître les exigences de réplication de la LIF dans une configuration MetroCluster. Vous devez également savoir comment placer une LIF répliquée sur un cluster partenaire, et vous devez connaître les problèmes qui se produisent en cas de défaillance de la réplication LIF ou du placement de LIF.
Conditions requises pour la création de LIF dans une configuration MetroCluster
Lors de la configuration du réseau dans une configuration MetroCluster, il est important de connaître les conditions requises pour la création des LIFs.
Lors de la création de LIF, vous devez tenir compte des consignes suivantes :
-
Fibre Channel : vous devez utiliser des VSAN étirés ou des fabrics étirés
-
IP/iSCSI : vous devez utiliser un réseau étendu de couche 2
-
Diffusions ARP : vous devez activer les diffusions ARP entre les deux clusters
-
Dupliquer les LIF : vous ne devez pas créer plusieurs LIF avec la même adresse IP (LIFs dupliquées) dans un IPspace
-
Configurations NFS et SAN : vous devez utiliser différents SVM pour les agrégats sans miroir et en miroir
-
Avant de créer une LIF, vous devez créer un objet de sous-réseau. Un objet de sous-réseau permet à ONTAP de déterminer les cibles de basculement sur le cluster de destination, car il possède un broadcast domain associé.
Vérifier la création de LIF
Vous pouvez confirmer le succès de la création d'une LIF dans une configuration MetroCluster en exécutant la metrocluster check lif show commande. En cas de problème lors de la création du LIF, vous pouvez utiliser le metrocluster check lif repair-placement commande permettant de résoudre les problèmes.
-
Il est important de connaître les exigences relatives à la réplication d'objets IPspace vers le cluster partenaire et à la configuration des sous-réseaux et IPv6 dans une configuration MetroCluster.
-
Il est important de connaître les exigences de réplication de la LIF dans une configuration MetroCluster. Vous devez également savoir comment placer une LIF répliquée sur un cluster partenaire, et vous devez connaître les problèmes qui se produisent en cas de défaillance de la réplication LIF ou du placement de LIF.
Exigences et problèmes de réplication et de placement de LIF
Il est important de connaître les exigences de réplication de la LIF dans une configuration MetroCluster. Vous devez également savoir comment placer une LIF répliquée sur un cluster partenaire, et vous devez connaître les problèmes qui se produisent en cas de défaillance de la réplication LIF ou du placement de LIF.
Réplication des LIFs vers le cluster partenaire
Lorsque vous créez une LIF sur un cluster dans une configuration MetroCluster, celle-ci est répliquée sur le cluster partenaire. Les LIF ne sont pas placées sous un nom unique. Pour assurer la disponibilité des LIF après une opération de basculement, le processus de placement de la LIF vérifie que les ports peuvent héberger les LIF en fonction des vérifications d'attributs de port et de accessibilité.
Le système doit remplir les conditions suivantes pour placer les LIF répliquées sur le cluster partenaire :
Condition |
Type de LIF : FC |
Type de LIF : IP/iSCSI |
Identification du nœud |
ONTAP tente de placer la LIF répliquée sur le partenaire de reprise après incident du nœud sur lequel elle a été créée. Si le partenaire DR n'est pas disponible, le partenaire auxiliaire DR est utilisé pour le placement. |
ONTAP tente de placer la LIF répliquée sur le partenaire de reprise après incident du nœud sur lequel elle a été créée. Si le partenaire DR n'est pas disponible, le partenaire auxiliaire DR est utilisé pour le placement. |
Identification des ports |
ONTAP identifie les ports FC target connectés sur le cluster DR. |
Les ports du cluster DR qui se trouvent dans le même IPspace que la LIF source sont sélectionnés pour une vérification de la capacité. Si aucun port n'est présent dans le cluster DR dans le même IPspace, la LIF ne peut pas être placée. Tous les ports du cluster DR qui hébergent déjà une LIF dans le même IPspace et le même sous-réseau sont automatiquement marqués comme accessibles ; et peuvent être utilisés pour le placement. Ces ports ne sont pas inclus dans le contrôle de la capacité d'accessibilité. |
Vérification de l'accessibilité |
La capacité d'accessibilité est déterminée en vérifiant la connectivité du nom WWN de la structure source sur les ports du cluster DR. Si la même structure n'est pas présente sur le site de reprise après incident, la LIF est placée sur un port aléatoire sur le partenaire de reprise après incident. |
La réachbilité est déterminée par la réponse à une diffusion ARP (Address Resolution Protocol) de chaque port précédemment identifié sur le cluster DR à l'adresse IP source de la LIF à placer. Pour que les vérifications de la réaptitude réussissent, les diffusions ARP doivent être autorisées entre les deux groupes. Chaque port qui reçoit une réponse de la LIF source sera marqué comme possible pour le placement. |
Sélection de port |
ONTAP catégorise les ports en fonction d'attributs tels que le type d'adaptateur et la vitesse, puis sélectionne les ports avec des attributs correspondants. Si aucun port avec des attributs correspondants n'est trouvé, la LIF est placée sur un port connecté au hasard sur le partenaire DR. |
Depuis les ports marqués comme accessibles lors du contrôle de ré-accessibilité, ONTAP préfère les ports qui sont dans le broadcast domain associé au sous-réseau de la LIF. S'il n'y a aucun port réseau disponible sur le cluster DR qui se trouve dans le broadcast domain associé au sous-réseau de la LIF, ONTAP sélectionne les ports qui ont la ré-accessibilité vers le LIF source. Si aucun port n'est capable de reachpuisse la LIF source, un port est sélectionné dans le broadcast domain associé au sous-réseau de la LIF source, et s'il n'existe aucun tel broadcast domain, un port aléatoire est sélectionné. ONTAP catégorise les ports en fonction d'attributs tels que le type d'adaptateur, le type d'interface et la vitesse, puis sélectionne les ports avec des attributs correspondants. |
Placement de LIF |
Dans les ports accessibles, ONTAP sélectionne le port le moins chargé pour le placement. |
Dans les ports sélectionnés, ONTAP sélectionne le port le moins chargé pour le placement. |
Placement des LIF répliquées lorsque le nœud partenaire de DR est en panne
Lorsqu'une LIF iSCSI ou FC est créée sur un nœud dont le partenaire de reprise après incident est repris, elle est placée sur le nœud partenaire auxiliaire de reprise après incident. Après une opération de rétablissement ultérieure, les LIF ne sont pas automatiquement déplacées vers le partenaire de reprise après incident. Cela peut entraîner une concentration des LIF sur un seul nœud du cluster partenaire. Lors d'une opération de basculement MetroCluster, les tentatives suivantes de mappage de LUN appartenant à la machine virtuelle de stockage (SVM) échouent.
Vous devez exécuter le metrocluster check lif show Commande après une opération de basculement ou de rétablissement pour vérifier que le placement de LIF est correct. Si des erreurs existent, vous pouvez exécuter le metrocluster check lif repair-placement commande pour résoudre les problèmes.
Erreurs de placement de LIF
Erreurs de placement de LIF affichées par le metrocluster check lif show la commande est conservée après une opération de basculement. Si le network interface modify, network interface rename, ou network interface delete La commande est émise pour une LIF avec une erreur de placement, l'erreur est supprimée et n'apparaît pas dans la sortie du metrocluster check lif show commande.
Échec de réplication de LIF
Vous pouvez également vérifier si la réplication LIF a réussi à l'aide de metrocluster check lif show commande. Un message EMS est affiché en cas d'échec de la réplication de la LIF.
Vous pouvez corriger un échec de réplication en exécutant le metrocluster check lif repair-placement Commande de tout LIF qui ne parvient pas à trouver le port correct. Vous devez résoudre toutes les défaillances liées à la réplication de la LIF dès que possible afin de vérifier la disponibilité de cette LIF lors d'une opération de basculement de la MetroCluster.
|
|
Même si le SVM source est en panne, le placement de la LIF peut se poursuivre normalement si une LIF appartient à un autre SVM dans un port avec le même IPspace et le même réseau dans le SVM de destination. |
Les LIF inaccessibles après le basculement
Si une modification est apportée à la structure de commutation FC sur laquelle les ports cibles FC des nœuds source et de reprise après incident sont connectés, les LIF FC qui sont placées sur le partenaire de reprise après incident risquent de devenir inaccessibles aux hôtes après un basculement.
Vous devez exécuter le metrocluster check lif repair-placement Une commande sur la source, ainsi que sur les nœuds de reprise après incident après une modification dans la structure du commutateur FC, afin de vérifier la connectivité hôte des LIF. Les modifications au niveau de la structure du switch peuvent entraîner l'placement des LIF dans différents ports FC cibles sur le nœud partenaire DR.
-
Il est important de connaître les exigences relatives à la réplication d'objets IPspace vers le cluster partenaire et à la configuration des sous-réseaux et IPv6 dans une configuration MetroCluster.
-
Lors de la configuration du réseau dans une configuration MetroCluster, il est important de connaître les conditions requises pour la création des LIFs.
Création du volume sur un agrégat root
Le système n'autorise pas la création de nouveaux volumes sur l'agrégat racine (un agrégat avec une politique de haute disponibilité de CFO) d'un nœud d'une configuration MetroCluster.
Du fait de cette restriction, les agrégats root ne peuvent pas être ajoutés à un SVM via le vserver add-aggregates commande.
Reprise après incident de SVM dans une configuration MetroCluster
Depuis ONTAP 9.5, des serveurs virtuels de stockage actifs dans une configuration MetroCluster peuvent être utilisés en tant que sources au sein de la fonctionnalité de reprise après incident de SVM SnapMirror. Le SVM destination doit être sur le troisième cluster en dehors de la configuration MetroCluster.
Depuis ONTAP 9.11.1, les deux sites d'une configuration MetroCluster peuvent être à la source d'une relation SVM DR avec un cluster FAS ou AFF de destination, comme illustré dans l'image suivante.
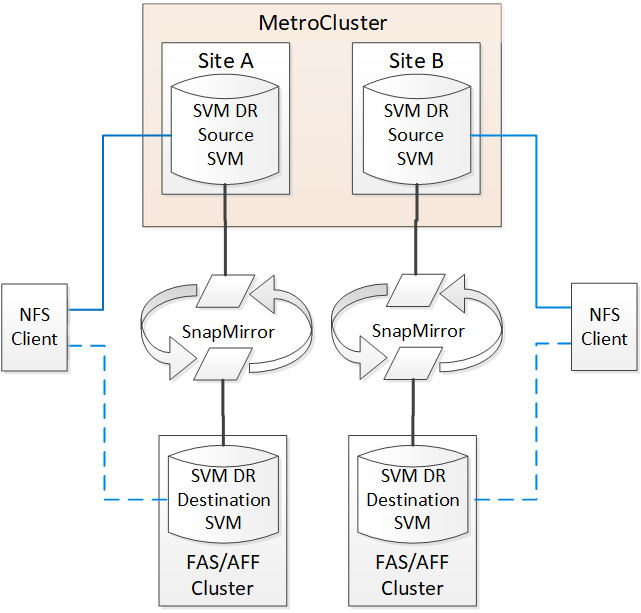
La reprise sur incident SnapMirror doit être consciente des exigences et limitations suivantes, liées à l'utilisation de SVM :
-
Seul un SVM actif au sein d'une configuration MetroCluster peut être à l'origine d'une relation de reprise d'activité de SVM.
Une source peut être un SVM source synchrone avant le basculement ou un SVM de destination synchrone après le basculement.
-
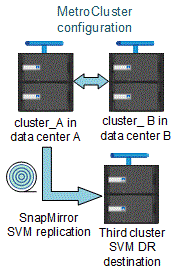
Lorsqu'une configuration MetroCluster est dans un état stable, le SVM MetroCluster destination ne peut pas être à l'origine d'une relation de reprise d'activité SVM, car les volumes ne sont pas en ligne.
L'image suivante montre le comportement de reprise après incident du SVM dans un état stable :
-
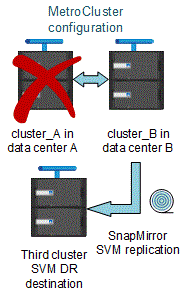
Lorsque le SVM source synchrone est la source d'une relation de SVM DR, les informations de la relation de SVM DR source sont répliquées vers le partenaire MetroCluster.
Les mises à jour de reprise après incident du SVM peuvent ainsi se poursuivre après un basculement, comme illustré dans l'image suivante :
-
Lors des processus de basculement et de rétablissement, la réplication vers la destination SVM DR peut échouer.
Toutefois, une fois le processus de basculement ou de rétablissement terminé, les mises à jour planifiées de reprise sur incident du SVM suivantes seront appliquées.
Voir la section « réplication de la configuration SVM » dans le "Protection des données via l'interface de ligne de commandes" Pour plus d'informations sur la configuration d'une relation de SVM DR.
Resynchronisation des SVM au niveau d'un site de reprise d'activité
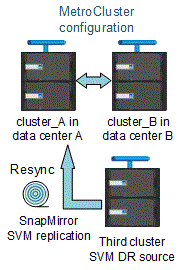
Pendant la resynchronisation, la source de reprise d'activité des machines virtuelles de stockage (SVM) sur la configuration MetroCluster est restaurée à partir du SVM de destination sur le site non MetroCluster.
Pendant la resynchronisation, le SVM source (cluster_A) agit temporairement comme un SVM de destination, comme illustré dans l'image suivante :
En cas de basculement non planifié lors de la resynchronisation
Les mélangeurs non planifiés qui se produisent pendant la resynchronisation stoppent le transfert de resynchronisation. En cas de basculement non planifié, les conditions suivantes sont vraies :
-
Le SVM de destination sur le site MetroCluster (qui était un SVM source avant resynchronisation) reste comme un SVM de destination. Le SVM au cluster partenaire continuera de conserver son sous-type et reste inactif.
-
La relation SnapMirror doit être recrécréée manuellement avec la SVM de destination du système Sync.
-
La relation SnapMirror n'apparaît pas dans le résultat SnapMirror après un basculement sur le site survivant sauf si une opération SnapMirror create est exécutée.
Rétablissement après un basculement non planifié lors de la resynchronisation
Pour réussir le processus de rétablissement, la relation de resynchronisation doit être interrompue et supprimée. Le rétablissement n'est pas autorisé en cas de SVM de destination SnapMirror DR dans la configuration MetroCluster ou si le cluster dispose d'un SVM de sous-type « `dp-destination' ».
La sortie de la commande « Storage Aggregate plex show » est indéterminée après un basculement MetroCluster
Lorsque vous exécutez le storage aggregate plex show Commande après un basculement MetroCluster, l'état du plex0 de l'agrégat racine commuté est déterminé pour une période indéterminée et s'affiche comme « FAILED ». Pendant ce temps, la racine de commutation n'est pas mise à jour. L'état réel de ce plex ne peut être déterminé qu'après la phase de guérison MetroCluster.
Modification des volumes pour définir l'indicateur NVFAIL en cas de basculement
Vous pouvez modifier un volume de sorte que l'indicateur NVFAIL soit défini sur le volume en cas de basculement MetroCluster. L'indicateur NVFAIL empêche le volume d'être clôturé de toute modification. Cela est nécessaire pour les volumes qui doivent être traités comme si des écritures validées sur le volume étaient perdues après le basculement.
|
|
Dans les versions ONTAP antérieures à 9.0, l'indicateur NVFAIL est utilisé pour chaque basculement. Dans ONTAP 9.0 et versions ultérieures, le basculement non planifié (USO) est utilisé. |
-
Activez la configuration MetroCluster pour déclencher NVFAIL lors du basculement en réglant le
vol -dr-force-nvfailparamètre sur « on » :vol modify -vserver vserver-name -volume volume-name -dr-force-nvfail on