

Supprimer un groupe DR d'une configuration MetroCluster
 Suggérer des modifications
Suggérer des modifications
À partir d' ONTAP 9.8, vous pouvez supprimer un groupe de reprise après sinistre (DR) d'une configuration MetroCluster à huit nœuds pour créer une configuration MetroCluster à quatre nœuds.

|
Vous utilisez ces étapes lors des flux de travail de transition et de mise à jour du système. Il est possible que vous ayez déjà effectué certaines étapes de cette procédure dans le cadre de ces flux de travail. |
Activer la journalisation de la console
NetApp vous recommande vivement d'activer la journalisation de la console sur les périphériques que vous utilisez et d'effectuer les actions suivantes lors de l'exécution de cette procédure :
-
Laissez AutoSupport activé pendant la maintenance.
-
Déclencher un message AutoSupport de maintenance avant et après la maintenance pour désactiver la création de dossiers pendant la durée de l'activité de maintenance.
Consultez l'article de la base de connaissances "Comment supprimer la création automatique de dossier pendant les fenêtres de maintenance planifiées".
-
Activer la journalisation de session pour toute session CLI. Pour obtenir des instructions sur l'activation de la journalisation des sessions, consultez la section « consignation des sorties de session » de l'article de la base de connaissances "Comment configurer PuTTY pour une connectivité optimale aux systèmes ONTAP".
Supprimez les nœuds du groupe DR de chaque cluster
Cette procédure est prise en charge à partir d' ONTAP 9.8. Pour les systèmes exécutant ONTAP 9.7 ou une version antérieure, consultez l'article de la base de connaissances :"Comment supprimer un groupe de reprise sur incident d'une configuration MetroCluster" .
-
Vous devez effectuer cette tâche sur les deux clusters.
-
Une configuration à huit nœuds comprend huit nœuds organisés sous forme de deux groupes de reprise après incident à quatre nœuds.
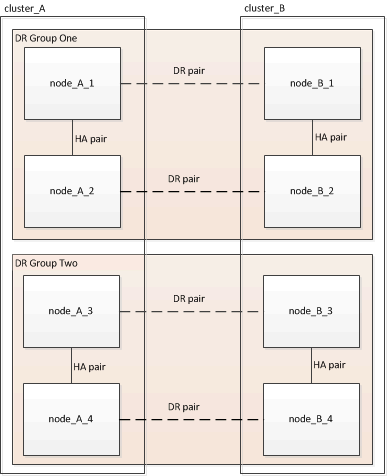
Lorsque vous supprimez un groupe DR, quatre nœuds restent dans la configuration.
-
Préparez-vous à supprimer le groupe DR si vous ne l’avez pas déjà fait.
-
Déplacez tous les volumes de données vers un autre groupe de reprise après incident.
-
Si le groupe DR à supprimer comporte des volumes miroirs de partage de charge, recréez tous les volumes miroirs de partage de charge dans un autre groupe DR et supprimez-les du groupe DR à supprimer.
-
Déplacez tous les volumes de métadonnées MDV_CRS vers un autre groupe DR en suivant la procédure "Déplacement d'un volume de métadonnées dans les configurations MetroCluster" procédure.
-
Supprimez tous les volumes de métadonnées MDV_aud qui peuvent exister dans le groupe DR à supprimer.
-
Supprimer tous les agrégats de données du groupe DR à supprimer :
ClusterA::> storage aggregate show -node ClusterA-01, ClusterA-02 -fields aggregate ,node ClusterA::> aggr delete -aggregate aggregate_name ClusterB::> storage aggregate show -node ClusterB-01, ClusterB-02 -fields aggregate ,node ClusterB::> aggr delete -aggregate aggregate_name
Les agrégats racine ne sont pas supprimés. -
Migrez tous les LIF de données NAS que vous utilisez pour NFS et CIFS (SMB) vers des nœuds domestiques dans un autre groupe DR.
network interface show -home-node <old_node>network interface migrate -vserver <svm_name> -lif <data_lif> -destination-node <new_node> -destination-port <port> -
Déplacez les LIF de données vers le nouveau nœud d’accueil dans un autre groupe DR.
network interface modify -vserver <svm-name> -lif <data-lif> -home-node <new_node> -home-port <port> -
Migrez la LIF de gestion de cluster vers un nœud de rattachement situé dans un autre groupe de reprise après incident.
network interface show -role cluster-mgmtnetwork interface modify -vserver <svm-name> -lif <cluster_mgmt> -home-node <new_node> -home-port <port-id>
-
La gestion des nœuds et les LIF inter-clusters ne sont pas migrés. Créez de nouveaux LIF de gestion de nœuds et inter-clusters sur les nœuds du groupe DR selon les besoins.
-
Vous ne pouvez pas migrer ou déplacer les interfaces FCP utilisées pour l'accès aux blocs (SAN) entre les nœuds. Créez de nouvelles interfaces FCP selon vos besoins.
-
Les LIF iSCSI SAN doivent être arrêtés avant que le nœud et le port d'origine puissent être mis à jour.
-
Transférer epsilon vers un nœud dans un autre groupe de reprise après incident si nécessaire.
ClusterA::> set advanced -prompt-timestamp above ClusterA::*> cluster show Move epsilon if needed ClusterA::*> cluster modify -node nodename -epsilon false ClusterA::*> cluster modify -node nodename -epsilon true ClusterB::> set advanced -prompt-timestamp above ClusterB::*> cluster show ClusterB::*> cluster modify -node nodename -epsilon false ClusterB::*> cluster modify -node nodename -epsilon true ClusterB::*> set admin
-
-
Identifier et supprimer le groupe de reprise sur incident.
-
Identifiez le groupe DR approprié pour la suppression :
metrocluster node show -
Supprimer les nœuds du groupe DR :
metrocluster remove-dr-group -dr-group-id 1
Le metrocluster remove-dr-groupLa commande n'est prise en charge que sur ONTAP 9.8 et les versions ultérieures.L'exemple suivant montre la suppression de la configuration du groupe de reprise sur incident sur cluster_A.
Exemple
cluster_A::*> Warning: Nodes in the DR group that are removed from the MetroCluster configuration will lose their disaster recovery protection. Local nodes "node_A_1-FC, node_A_2-FC"will be removed from the MetroCluster configuration. You must repeat the operation on the partner cluster "cluster_B"to remove the remote nodes in the DR group. Do you want to continue? {y|n}: y Info: The following preparation steps must be completed on the local and partner clusters before removing a DR group. 1. Move all data volumes to another DR group. 2. Move all MDV_CRS metadata volumes to another DR group. 3. Delete all MDV_aud metadata volumes that may exist in the DR group to be removed. 4. Delete all data aggregates in the DR group to be removed. Root aggregates are not deleted. 5. Migrate all data LIFs to home nodes in another DR group. 6. Migrate the cluster management LIF to a home node in another DR group. Node management and inter-cluster LIFs are not migrated. 7. Transfer epsilon to a node in another DR group. The command is vetoed if the preparation steps are not completed on the local and partner clusters. Do you want to continue? {y|n}: y [Job 513] Job succeeded: Remove DR Group is successful. cluster_A::*> -
-
Répétez l'étape précédente sur le cluster partenaire.
-
Désactiver le basculement de stockage sur les nœuds de l’ancien groupe DR :
storage failover modify -node <node-name> -enable false -
Si vous êtes dans une configuration IP MetroCluster , procédez comme suit pour supprimer les plex distants des agrégats racines et supprimer la propriété du disque sur les nœuds de l'ancien groupe DR.
Dans une configuration FC MetroCluster, passez à l’étape pour suppression des anciens nœuds du groupe DR.
Ces étapes doivent être effectuées pour les deux nœuds de la paire HA sur chaque site.
-
Afficher les plex distants des agrégats racines sur les nœuds du groupe DR à supprimer :
storage aggregate plex show -aggregate <root_aggr_name> -pool 1 -
Supprimer les plex distants :
storage aggregate plex delete -aggregate <root_aggr_name> -plex <plex_from_previous_step> -
Identifiez les disques distants appartenant aux nœuds du groupe DR.
Les commandes que vous utilisez dépendent du fait que vous utilisez des disques partitionnés/partagés ou des disques entiers :
Utilisez une liste séparée par des virgules dans le -owner <node_names>champ permettant de spécifier les noms de nœuds dans le groupe DR à supprimer.Disques partitionnés/partagés :-
Définissez le niveau de privilège sur avancé :
set advanced -prompt-timestamp above -
Afficher les disques distants :
storage disk show -pool Pool1 -owner <node_names> -partition-ownership
Disques entiers :-
Définissez le niveau de privilège sur avancé :
set advanced -prompt-timestamp above -
Afficher les disques distants :
storage disk show -pool Pool1 -owner <node_names>
-
-
Désactiver l'attribution automatique du disque :
disk option modify -node <node_names_in_the_DR_group_to_be_deleted> -autoassign off -
Supprimez la propriété des disques de pool1 sur chaque nœud du groupe DR à supprimer. Effectuez ces étapes sur chaque nœud à supprimer. Dans les exemples utilisés dans cette étape, node_A_1 est supprimé.
-
Accédez au nodeshell :
run -node <node_name> -
Identifiez les disques pool1 :
disk showTous les disques sont affichés, y compris les disques Pool1 appartenant au nœud. L'exemple suivant présente un affichage tronqué où le disque 0n.4 et ses partitions sont affectés à Pool1. L'affichage peut varier selon votre configuration.
DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- 0n.4 node_A1(537102267) Pool1 S3N9NX0J500267 node_A1(537102267) 0n.4P1 node_A1(537102267) Pool1 S3N9NX0J500267NP001 node_A1(537102267) 0n.4P2 node_A1(537102267) Pool1 S3N9NX0J500267NP002 node_A1(537102267) 0n.4P3 node_A1(537102267) Pool1 S3N9NX0J500267NP003 node_A1(537102267)
-
Définissez le niveau de privilège sur avancé :
set -privilege advanced -prompt-timestamp above -
Supprimer la propriété du disque pour chaque disque du pool1 :
Si votre configuration contient des disques partitionnés, vous devez d'abord supprimer la propriété de chaque disque partitionné, puis supprimer la propriété du disque conteneur :
disk remove_ownership <disk_name>
Dans l'exemple suivant, la propriété des disques partitionnés est supprimée avant la propriété du disque conteneur
0n.4est supprimée : -
*> disk remove_ownership 0n.4P1 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y Removing the ownership of aggregate disks may lead to partition of aggregates between high-availability pair. Do you want to continue(y/n)? y *> disk remove_ownership 0n.4P2 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y Removing the ownership of aggregate disks may lead to partition of aggregates between high-availability pair. Do you want to continue(y/n)? y *> disk remove_ownership 0n.4P3 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y Removing the ownership of aggregate disks may lead to partition of aggregates between high-availability pair. Do you want to continue(y/n)? y *> disk remove_ownership 0n.4 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y *>
-
-
Si vous êtes dans une configuration IP MetroCluster , supprimez les connexions MetroCluster sur les nœuds de l'ancien groupe DR.
Dans une configuration FC MetroCluster, passez à l’étape pour suppression des anciens nœuds du groupe DR.
Ces commandes peuvent être émises à partir de l’un ou l’autre cluster et s’appliquent à l’ensemble du groupe DR couvrant les deux clusters.
-
Débrancher les connexions :
metrocluster configuration-settings connection disconnect -dr-group-id <dr_group_id>Exemple
cluster_A::*> metrocluster configuration-settings connection disconnect -dr-group-id 1 Warning: For the nodes in the DR group 1, this command will remove the existing connections that are used to mirror NV logs and access remote storage. Do you want to continue? {y|n}: y Warning: Before proceeding with disconnect, you must verify the following: 1. Unmirrored aggregates do not have disks in remote plexes. 2. Aggregates are not mirrored. 3. No disks are assigned in Pool1. 4. Storage failover is not enabled. Follow the "MetroCluster Installation and Configuration guide" for detailed instructions to verify this. Do you want to continue? {y|n}: y -
Supprimez les interfaces MetroCluster sur les nœuds de l'ancien groupe DR :
Cette étape doit être répétée sur chaque nœud du groupe DR.
metrocluster configuration-settings interface delete-
Supprimez l'ancienne configuration du groupe DR.
metrocluster configuration-settings dr-group delete
-
-
Supprimez les nœuds de l'ancien groupe DR.
Effectuez cette étape sur chaque cluster.
-
Définissez le niveau de privilège avancé :
set -privilege advanced -prompt-timestamp above -
Supprimer le nœud :
cluster remove-node -node <node-name>Répétez cette étape pour l'autre nœud local de l'ancien groupe DR.
-
Définir le niveau de privilège administrateur :
set -privilege admin
-
-
Vérifiez que le cluster HA est activé dans le nouveau groupe DR. Si nécessaire, réactivez le cluster HA :
cluster ha modify -configured trueEffectuez cette étape sur chaque cluster.
-
Arrêtez, mettez hors tension et retirez les anciens modules de contrôleur et tiroirs de stockage.
En savoir plus sur les commandes utilisées dans cette procédure dans le "Référence des commandes ONTAP".