

Identifiez et démontez les volumes de stockage défectueux
 Suggérer des modifications
Suggérer des modifications
Lors de la restauration d'un nœud de stockage dont les volumes de stockage sont en panne, vous devez identifier et démonter les volumes en panne. Vous devez vérifier que seuls les volumes de stockage défaillants sont reformatés dans le cadre de la procédure de restauration.
Vous êtes connecté au Grid Manager à l'aide d'un "navigateur web pris en charge".
Vous devriez récupérer les volumes de stockage défaillants dès que possible.
La première étape du processus de restauration consiste à détecter les volumes qui se sont détachés, qui doivent être démontés ou qui présentent des erreurs d'E/S. Si les volumes défaillants sont toujours attachés mais qu'un système de fichiers est corrompu de façon aléatoire, le système risque de ne pas détecter de corruption dans les pièces non utilisées ou non attribuées du disque.

|
Vous devez terminer cette procédure avant d'effectuer manuellement les étapes de restauration des volumes, telles que l'ajout ou la reconfiguration des disques, l'arrêt du nœud, le démarrage du nœud ou le redémarrage. Sinon, lorsque vous exécutez le reformat_storage_block_devices.rb script, vous pouvez rencontrer une erreur du système de fichiers qui entraîne l'arrêt ou l'échec du script.
|
|
|
Réparez le matériel et fixez correctement les disques avant de faire fonctionner le reboot commande.
|

|
Identifiez minutieusement les volumes de stockage défaillants. Ces informations vous permettront de vérifier quels volumes doivent être reformatés. Une fois qu'un volume a été reformaté, les données du volume ne peuvent pas être récupérées. |
Pour récupérer correctement les volumes de stockage défectueux, vous devez connaître à la fois les noms des périphériques des volumes de stockage défaillants et leurs ID de volume.
Lors de l'installation, un identifiant unique universel du système de fichiers (UUID) est attribué à chaque périphérique de stockage et il est monté dans un répertoire rangedb du nœud de stockage à l'aide de l'UUID attribué au système de fichiers. L'UUID du système de fichiers et le répertoire rangedb sont répertoriés dans le /etc/fstab fichier. Le nom du périphérique, le répertoire rangedb et la taille du volume monté sont affichés dans le Gestionnaire de grille.
Dans l'exemple suivant, périphérique /dev/sdc A une taille de volume de 4 To, est monté sur /var/local/rangedb/0, en utilisant le nom du périphérique /dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba dans le /etc/fstab fichier :
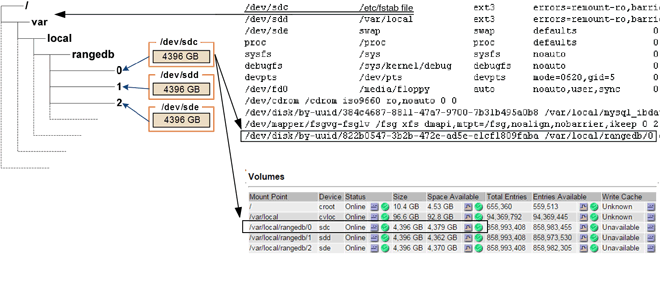
-
Procédez comme suit pour enregistrer les volumes de stockage défaillants et leurs noms de périphériques :
-
Sélectionnez SUPPORT > Outils > topologie de grille.
-
Sélectionnez site > noeud de stockage défaillant > LDR > Storage > Présentation > main et recherchez des magasins d'objets avec alarmes.

-
Sélectionnez site > noeud de stockage défaillant > SSM > Ressources > Présentation > main. Déterminez la taille du point de montage et du volume de chaque volume de stockage défectueux identifié à l'étape précédente.
Les magasins d'objets sont numérotés en notation hexadécimale. Par exemple, 0000 est le premier volume et 000F est le seizième volume. Dans l'exemple, le magasin d'objets avec un ID de 0000 correspond à
/var/local/rangedb/0Avec le nom de périphérique sdc et une taille de 107 Go.
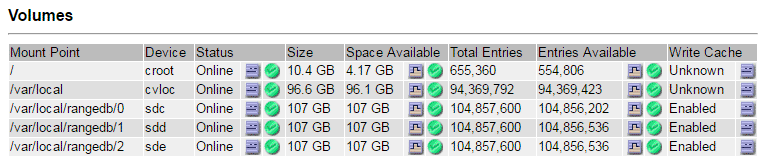
-
-
Connectez-vous au noeud de stockage défaillant :
-
Saisissez la commande suivante :
ssh admin@grid_node_IP -
Entrez le mot de passe indiqué dans le
Passwords.txtfichier. -
Entrez la commande suivante pour passer à la racine :
su - -
Entrez le mot de passe indiqué dans le
Passwords.txtfichier.
Lorsque vous êtes connecté en tant que root, l'invite passe de
$à#. -
-
Exécutez le script suivant pour démonter un volume de stockage défaillant :
sn-unmount-volume object_store_IDLe
object_store_IDEst l'ID du volume de stockage défaillant. Par exemple, spécifiez0Dans la commande pour un magasin d'objets avec l'ID 0000. -
Si vous y êtes invité, appuyez sur y pour arrêter le service Cassandra en fonction du volume de stockage 0.
Si le service Cassandra est déjà arrêté, vous n'êtes pas invité à le faire. Le service Cassandra est arrêté uniquement pour le volume 0. root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
Le volume est démonté en quelques secondes. Des messages s'affichent indiquant chaque étape du processus. Le dernier message indique que le volume est démonté.
-
Si le démontage échoue parce que le volume est occupé, vous pouvez forcer le démontage à l'aide du
--use-umountofoption :
Forcer un démontage à l'aide du --use-umountofpeut provoquer un comportement inattendu ou une panne des processus ou services utilisant le volume.root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes