Qu'est-ce qu'un objet
 Suggérer des modifications
Suggérer des modifications
Avec le stockage objet, l'unité de stockage est un objet, et non un fichier ou un bloc. Contrairement à la hiérarchie de type arborescence d'un système de fichiers ou stockage en blocs, le stockage objet organise les données dans une disposition plate et non structurée.
Le stockage objet dissocie l'emplacement physique des données de la méthode de stockage et de récupération utilisée.
Chaque objet d'un système de stockage basé sur les objets comporte deux parties : les données d'objet et les métadonnées d'objet.
Qu'est-ce que les données d'objet ?
Les données d'objet peuvent être quoi que ce soit ; par exemple, une photographie, un film ou un dossier médical.
Qu'est-ce que les métadonnées d'objet ?
Les métadonnées d'objet constituent toutes les informations qui décrivent un objet. StorageGRID utilise les métadonnées d'objet pour suivre l'emplacement de tous les objets de la grille, et pour gérer le cycle de vie de chaque objet au fil du temps.
Les métadonnées de l'objet incluent les informations suivantes :
-
Les métadonnées du système, y compris un ID unique pour chaque objet (UUID), le nom de l'objet, le nom du compartiment S3 ou du conteneur Swift, le nom ou l'ID du compte du locataire, la taille logique de l'objet, la date et l'heure de la première création de l'objet, et la date et l'heure de la dernière modification de l'objet.
-
Emplacement de stockage actuel de chaque copie d'objet ou fragment codé d'effacement.
-
Toutes les métadonnées utilisateur associées à l'objet.
Les métadonnées de l'objet sont personnalisables et extensibles, ce qui rend la possibilité d'utiliser les applications.
Pour plus d'informations sur la façon et l'emplacement StorageGRID de stockage des métadonnées d'objet, accédez à "Gérer le stockage des métadonnées d'objet".
Comment les données d'objet sont-elles protégées ?
Le système StorageGRID propose deux mécanismes de protection des données d'objet contre la perte : la réplication et le codage d'effacement.
La réplication
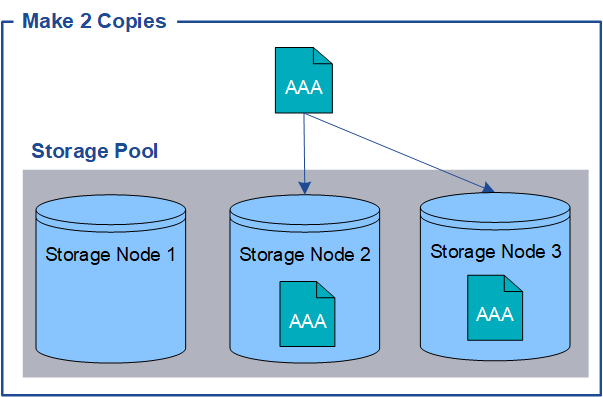
Lorsque StorageGRID mappe les objets sur une règle de gestion du cycle de vie des informations (ILM) configurée pour créer des copies répliquées, le système crée des copies exactes des données d'objet et les stocke sur des nœuds de stockage, des nœuds d'archivage ou des pools de stockage cloud. Les règles ILM déterminent le nombre de copies effectuées, l'emplacement de stockage de ces copies et la durée pendant laquelle elles sont conservées par le système. Par exemple, en cas de perte d'une copie suite à la perte d'un nœud de stockage, l'objet est toujours disponible si une copie de celui-ci existe ailleurs dans le système StorageGRID.
Dans l'exemple suivant, la règle Make 2 copies spécifie que deux copies répliquées de chaque objet sont placées dans un pool de stockage contenant trois nœuds de stockage.
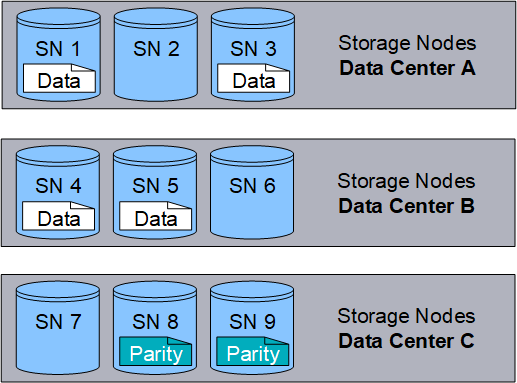
Le code d'effacement
Lorsque StorageGRID mappe les objets sur une règle ILM configurée pour créer des copies avec code d'effacement, elle coupe les données d'objet en fragments de données, calcule des fragments de parité supplémentaires et stocke chaque fragment sur un autre nœud de stockage. Lorsqu'un objet est accédé, il est réassemblé à l'aide des fragments stockés. En cas de corruption ou de perte d'un fragment de parité, l'algorithme de codage d'effacement peut recréer ce fragment à l'aide d'un sous-ensemble des données restantes et des fragments de parité. Les règles ILM et les profils de code d'effacement déterminent le schéma de code d'effacement utilisé.
L'exemple suivant illustre l'utilisation du code d'effacement sur les données d'un objet. Dans cet exemple, la règle ILM utilise un schéma de code d'effacement 4+2. Chaque objet est tranché en quatre fragments de données égaux et deux fragments de parité sont calculés à partir des données d'objet. Chacun des six fragments est stocké sur un nœud de stockage différent dans trois data centers pour assurer la protection des données en cas de défaillance d'un nœud ou de perte d'un site.