

Objectif de point de récupération de zéro avec StorageGRID, Un guide complet de réplication multisite
 Suggérer des modifications
Suggérer des modifications
Ce rapport technique fournit un guide complet sur la mise en œuvre des stratégies de réplication StorageGRID pour atteindre un objectif de point de récupération (RPO) de zéro en cas de défaillance d'un site. Le document détaille différentes options de déploiement pour StorageGRID, notamment la réplication synchrone multisite et la réplication asynchrone multi-grille. Il explique comment les politiques de gestion du cycle de vie des informations (ILM) de StorageGRID peuvent être configurées pour garantir la durabilité et la disponibilité des données sur plusieurs sites. En outre, le rapport aborde les considérations relatives aux performances, les scénarios de défaillance et les processus de récupération afin de maintenir la continuité des opérations des clients. L’objectif de ce document est de fournir des informations permettant de garantir que les données restent accessibles et cohérentes, même en cas de panne complète du site, en tirant parti des techniques de réplication synchrone et asynchrone.
Présentation de StorageGRID
NetApp StorageGRID est un système de stockage objet qui prend en charge l'API Amazon simple Storage Service (Amazon S3) standard.
StorageGRID fournit un espace de noms unique à plusieurs emplacements avec des niveaux de service variables basés sur des règles de gestion du cycle de vie des informations (ILM). Grâce à ces politiques de cycle de vie, vous pouvez optimiser l’emplacement de vos données tout au long de leur cycle de vie.
StorageGRID permet une durabilité et une disponibilité configurables de vos données dans des solutions locales et réparties géographiquement. Que vos données soient sur site ou dans un cloud public, les flux de travail cloud hybrides intégrés permettent à votre entreprise de tirer parti de services cloud tels qu'Amazon Simple Notification Service (Amazon SNS), Google Cloud, Microsoft Azure Blob, Amazon S3 Glacier, Elasticsearch, etc.
StorageGRID Scale
Un déploiement minimal de StorageGRID se compose d'un nœud d'administration et de 3 nœuds de stockage sur un seul site. Une seule grille peut comporter jusqu'à 220 nœuds. StorageGRID peut être déployé sur un seul site ou étendu à 16 sites.
Le nœud Admin contient l'interface de gestion, un point central pour les métriques et la journalisation, et maintient la configuration des composants StorageGRID . Le nœud Admin contient également un équilibreur de charge intégré pour l’accès à l’API S3.
StorageGRID peut être déployé uniquement en tant que logiciel, en tant qu'appliances de machines virtuelles VMware ou en tant qu'appliances spécialement conçues.
Un nœud de stockage peut être déployé comme suit :
-
Un nœud de métadonnées uniquement maximisant le nombre d'objets
-
Un nœud de stockage d'objets uniquement maximisant l'espace objet
-
Un nœud combiné de métadonnées et de stockage d'objets ajoutant à la fois le nombre d'objets et l'espace d'objets
Chaque nœud de stockage peut évoluer vers une capacité de plusieurs pétaoctets pour le stockage d'objets, permettant un espace de noms unique dans les centaines de pétaoctets. StorageGRID fournit également un équilibreur de charge intégré pour les opérations API S3 appelé nœud de passerelle.
StorageGRID se compose d'un ensemble de nœuds placés dans une topologie de site. Un site dans StorageGRID peut être un emplacement physique unique ou résider dans un emplacement physique partagé comme d'autres sites de la grille en tant que construction logique. Un site StorageGRID ne doit pas s'étendre sur plusieurs emplacements physiques. Un site représente une infrastructure de réseau local (LAN) partagée et un domaine de défaillance.
StorageGRID et domaines de défaillance
StorageGRID comprend plusieurs couches de domaines de défaillance à prendre en compte pour décider de l'architecture de votre solution, du mode de stockage des données et de l'emplacement de stockage des données afin de limiter les risques de défaillance.
-
Niveau de la grille : Une grille composée de plusieurs sites peut présenter des pannes de site ou une isolation et le ou les sites accessibles peuvent continuer à fonctionner comme la grille.
-
Au niveau du site : les défaillances au sein d'un site peuvent avoir un impact sur les opérations de ce site, mais elles n'auront pas d'impact sur le reste de la grille.
-
Niveau nœud : Une défaillance de nœud n'a aucun impact sur le fonctionnement du site.
-
Niveau du disque : une défaillance de disque n'a aucun impact sur le fonctionnement du nœud.
Données d'objet et métadonnées
Avec le stockage objet, l'unité de stockage est un objet, et non un fichier ou un bloc. Contrairement à la hiérarchie de type arborescence d'un système de fichiers ou stockage en blocs, le stockage objet organise les données dans une disposition plate et non structurée. Le stockage objet dissocie l'emplacement physique des données de la méthode de stockage et de récupération utilisée.
Chaque objet d'un système de stockage basé sur les objets comporte deux parties : les données d'objet et les métadonnées d'objet.
-
Les données objet représentent les données sous-jacentes réelles, par exemple une photographie, un film ou un dossier médical.
-
Les métadonnées d'objet constituent toutes les informations qui décrivent un objet.
StorageGRID utilise les métadonnées d'objet pour suivre l'emplacement de tous les objets de la grille, et pour gérer le cycle de vie de chaque objet au fil du temps.
Les métadonnées de l'objet incluent les informations suivantes :
-
Métadonnées système, y compris un ID unique pour chaque objet, le nom de l'objet, le nom du compartiment S3, le nom ou l'ID du compte locataire, la taille logique de l'objet, la date et l'heure de la première création de l'objet et la date et l'heure de la dernière modification de l'objet.
-
L'emplacement de stockage actuel de la copie répliquée ou du fragment à codage d'effacement de chaque objet.
-
Toutes les paires de clé-valeur de métadonnées utilisateur personnalisées associées à l'objet.
-
Pour les objets S3, toutes les paires clé-valeur de balise d'objet associées à l'objet
-
Pour les objets segmentés et les objets multiparties, les identifiants de segment et les tailles de données.
Les métadonnées de l'objet sont personnalisables et extensibles, ce qui rend la possibilité d'utiliser les applications. Pour plus d'informations sur la manière et l'emplacement du stockage des métadonnées d'objet par StorageGRID, consultez "Gérer le stockage des métadonnées d'objet" .
Le système de gestion du cycle de vie des informations (ILM) de StorageGRID orchestre le placement, la durée et le comportement d'ingestion de toutes les données d'objet de votre système StorageGRID. Les règles ILM déterminent la façon dont StorageGRID stocke les objets au fil du temps à l'aide de répliques d'objets ou du codage d'effacement de l'objet sur plusieurs nœuds et sites. Ce système ILM est responsable de la cohérence des données en mode objet au sein d'une grille.
Le code d'effacement
StorageGRID offre la possibilité d'effacer les données de code au niveau du nœud et au niveau du lecteur. Avec les appliances StorageGRID, nous effaçons le code des données stockées sur chaque nœud sur tous les lecteurs du nœud, offrant ainsi une protection locale contre les pannes de disque multiples entraînant une perte ou des interruptions de données. Les reconstructions après des pannes de disque sont locales sur le nœud et ne nécessitent pas de réplication de données sur le réseau.
De plus, les appliances StorageGRID utilisent des schémas de codage d'effacement pour stocker les données d'objet sur les nœuds d'un site ou réparties sur 3 sites ou plus dans le système StorageGRID via les règles ILM de StorageGRID protégeant contre les pannes de nœud.
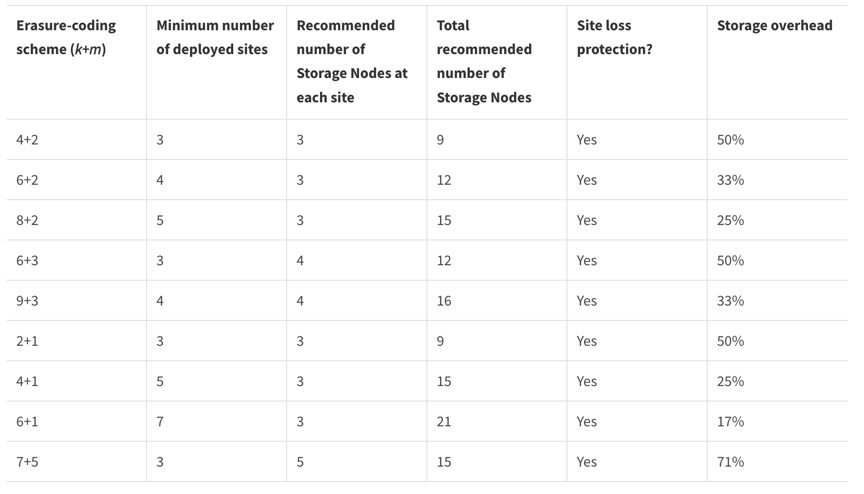
Le codage d'effacement offre une structure de stockage résistante aux pannes de nœuds et de sites, avec une surcharge moindre que la réplication. Tous les schémas de codage d'effacement StorageGRID sont déployables sur un seul site à condition que le nombre minimal de nœuds requis pour stocker les blocs de données soit atteint. Cela signifie que pour un schéma EC de 4+2, il faut un minimum de 6 nœuds disponibles pour recevoir les données.
Cohérence des métadonnées
Dans StorageGRID, les métadonnées sont généralement stockées avec trois réplicas par site pour assurer la cohérence et la disponibilité. Cette redondance permet de préserver l'intégrité et l'accessibilité des données, même en cas de défaillance.
La cohérence par défaut est définie au niveau de la grille. Les utilisateurs peuvent modifier la cohérence à tout moment au niveau du compartiment.
Les options de cohérence des compartiments disponibles dans StorageGRID sont les suivantes :
-
Tous : fournit le plus haut niveau de cohérence. Tous les nœuds de la grille reçoivent les données immédiatement, faute de quoi la demande échoue.
-
Fort-mondial :
-
Legacy Strong Global : Garantit la cohérence de lecture après écriture pour toutes les requêtes client sur tous les sites.
-
Il s'agit du comportement par défaut pour tous les systèmes mis à niveau de la version 11.9 ou antérieure vers la version 12.0 sans modification manuelle du nouveau Quorum Strong Global.
-
-
Quorum Strong-global : garantit la cohérence de lecture après écriture pour toutes les demandes client sur tous les sites. Offre une cohérence pour plusieurs nœuds ou même une panne de site si le quorum de réplication des métadonnées est réalisable.
-
Il s'agit du comportement par défaut pour tous les systèmes nouvellement installés sous la version 12.0 ou supérieure.
-
La cohérence QUORUM est définie comme un quorum de répliques de métadonnées de nœud de stockage, où chaque site dispose de 3 répliques de métadonnées. Il peut être calculé comme suit : 1+((N*3)/2) où N est le nombre total de sites
-
Par exemple, un minimum de 5 répliques doivent être réalisées à partir d'une grille de 3 sites avec un maximum de 3 répliques au sein d'un site.
-
-
-
Strong-site : garantit la cohérence lecture après écriture pour toutes les demandes client au sein d'un site.
-
Read-After-New-write(par défaut) : fournit une cohérence en lecture après écriture pour les nouveaux objets et une cohérence éventuelle pour les mises à jour d'objets. Offre une haute disponibilité et une protection des données garanties. Recommandé dans la plupart des cas.
-
Disponible : assure la cohérence finale pour les nouveaux objets et les mises à jour d'objets. Pour les compartiments S3, utilisez uniquement si nécessaire (par exemple, pour un compartiment qui contient des valeurs de journal rarement lues ou pour les opérations HEAD ou GET sur des clés qui n'existent pas). Non pris en charge pour les compartiments FabricPool S3.
Cohérence des données en mode objet
Tandis que les métadonnées sont automatiquement répliquées dans et entre les sites, les décisions concernant le placement du stockage des données d'objet vous tiennent. Les données d'objet peuvent être stockées en répliques au sein d'un ou plusieurs sites, avec code d'effacement au sein d'un ou entre plusieurs sites, ou encore une combinaison de répliques et de systèmes de stockage avec code d'effacement. Les règles ILM peuvent s'appliquer à tous les objets ou être filtrées pour ne s'appliquer qu'à certains objets, compartiments ou locataires. Les règles ILM définissent le mode de stockage des objets, les réplicas et/ou le code d'effacement, la durée de stockage des objets à ces emplacements si le nombre de répliques ou le schéma de code d'effacement doit changer, ou si les emplacements doivent changer au fil du temps.
Chaque règle ILM sera configurée avec l'un des trois comportements d'ingestion pour la protection des objets : double allocation, équilibre ou stricte.
L'option de double validation effectuera immédiatement deux copies sur deux nœuds de stockage différents de la grille et renverra la requête au client comme ayant réussi. La sélection des nœuds sera effectuée sur le site de la requête, mais pourra, dans certains cas, utiliser des nœuds d'un autre site. L'objet est ajouté à la file d'attente ILM pour être évalué et placé conformément aux règles ILM.
L'option équilibrée évalue immédiatement l'objet par rapport à la politique ILM et le place de manière synchrone avant de renvoyer la requête au client pour confirmer sa réussite. Si la règle ILM ne peut être respectée immédiatement en raison d'une panne ou d'un espace de stockage insuffisant pour répondre aux exigences de placement, alors une double validation sera utilisée à la place. Une fois le problème résolu, ILM placera automatiquement l'objet selon la règle définie.
L'option stricte évalue immédiatement l'objet par rapport à la politique ILM et le place de manière synchrone avant de renvoyer la requête au client pour confirmer sa réussite. Si la règle ILM ne peut être respectée immédiatement en raison d'une panne ou d'un espace de stockage insuffisant pour répondre aux exigences de placement, la requête échouera et le client devra réessayer.
Équilibrage de la charge
StorageGRID peut être déployé avec accès client via les nœuds de passerelle intégrés, un équilibreur de charge externe tiers 3rd, un round Robin DNS ou directement sur un nœud de stockage. Plusieurs nœuds de passerelle peuvent être déployés dans un site et configurés dans des groupes à haute disponibilité. Ils bénéficient ainsi d'un basculement et d'un retour arrière automatisés en cas de panne d'un nœud de passerelle. Vous pouvez combiner des méthodes d'équilibrage de charge dans une solution afin de fournir un point d'accès unique pour tous les sites d'une solution.
Les nœuds passerelles répartiront la charge entre les nœuds de stockage du site où ils résident par défaut. StorageGRID peut être configuré pour permettre aux nœuds de passerelle d'équilibrer la charge en utilisant des nœuds provenant de plusieurs sites. Cette configuration ajouterait la latence entre ces sites à la latence de réponse aux requêtes du client. Cette configuration ne doit être mise en place que si la latence totale est acceptable pour les clients.
Un RTO nul peut être garanti grâce à une combinaison d'équilibrage de charge local et global. Garantir un accès client ininterrompu nécessite un équilibrage de charge des requêtes client. Une solution StorageGRID peut contenir de nombreux nœuds de passerelle et des groupes à haute disponibilité sur chaque site. Pour garantir un accès ininterrompu aux clients sur n'importe quel site, même en cas de panne de site, vous devez configurer une solution d'équilibrage de charge externe en combinaison avec les nœuds StorageGRID Gateway. Configurez des groupes de haute disponibilité pour les nœuds Gateway qui gèrent la charge au sein de chaque site et utilisez l'équilibreur de charge externe pour répartir la charge entre les groupes de haute disponibilité. L'équilibreur de charge externe doit être configuré pour effectuer un contrôle d'intégrité afin de garantir que les requêtes ne soient envoyées qu'aux sites opérationnels. Pour plus d'informations sur l'équilibrage de charge avec StorageGRID, veuillez consulter la documentation. "Rapport technique sur l'équilibreur de charge StorageGRID".
Exigences pour un RPO nul avec StorageGRID
Pour atteindre un objectif de point de récupération de zéro dans un système de stockage objet, il est essentiel qu'au moment de la défaillance :
-
Les métadonnées et le contenu des objets sont synchronisés et sont considérés comme cohérents
-
Le contenu de l'objet reste accessible malgré la défaillance.
Pour un déploiement multisite, Quorum Strong Global est le modèle de cohérence privilégié pour garantir la synchronisation des métadonnées sur tous les sites, ce qui le rend essentiel pour répondre à l'exigence de RPO zéro.
Les objets du système de stockage sont stockés selon les règles de gestion du cycle de vie de l'information (ILM), qui dictent comment et où les données sont stockées tout au long de leur cycle de vie. Pour la réplication synchrone, on peut choisir entre l'exécution stricte et l'exécution équilibrée.
-
L'exécution stricte de ces règles ILM est nécessaire pour RPO nul, car elle garantit que les objets sont placés aux emplacements définis sans délai ni retour arrière, afin d'assurer la disponibilité et la cohérence des données.
-
Le comportement d'ingestion de l'équilibre ILM de StorageGRID offre un équilibre entre haute disponibilité et résilience, permettant aux utilisateurs de continuer à ingérer des données, même en cas de défaillance d'un site.
Déploiements synchrones sur plusieurs sites
Solutions multisites : StorageGRID vous permet de répliquer des objets sur plusieurs sites au sein de la grille de manière synchrone. En configurant des règles de gestion du cycle de vie des informations (ILM) avec un comportement équilibré ou strict, les objets sont placés immédiatement aux emplacements spécifiés. La configuration du niveau de cohérence du bucket sur Quorum Strong Global garantira également la réplication synchrone des métadonnées. StorageGRID utilise un espace de noms global unique, stockant les emplacements de placement des objets sous forme de métadonnées, de sorte que chaque nœud sait où se trouvent toutes les copies ou les éléments codés par effacement. Si un objet ne peut pas être récupéré à partir du site où la demande a été effectuée, il sera automatiquement récupéré à partir d'un site distant sans nécessiter de procédures de basculement.
Une fois la défaillance résolue, aucune opération de restauration manuelle n'est nécessaire. Les performances de réplication dépendent du site avec le débit réseau le plus faible, la latence la plus élevée et les performances les plus faibles. Les performances d'un site dépendent du nombre de nœuds, du nombre de cœurs et de la vitesse du processeur, de la mémoire, de la quantité de disques et des types de disques.
Solutions multi-grilles : StorageGRID peut répliquer des locataires, des utilisateurs et des compartiments entre plusieurs systèmes StorageGRID à l'aide de la réplication multigrille (CGR). CGR peut étendre des données sélectionnées à plus de 16 sites, augmenter la capacité utilisable de votre magasin d'objets et fournir une reprise après sinistre. La réplication des compartiments avec CGR inclut des objets, des versions d'objets et des métadonnées, et peut être bidirectionnelle ou unidirectionnelle. L'objectif de point de récupération dépend de la performance de chaque système StorageGRID et des connexions réseau qui les relient.
Résumé:
-
La réplication intra-grid inclut à la fois la réplication synchrone et asynchrone. Elle peut être configurée à l'aide du comportement d'ingestion ILM et du contrôle de la cohérence des métadonnées.
-
La réplication inter-grid est asynchrone uniquement.
Un déploiement multi-site à grille unique
Dans les scénarios suivants, les solutions StorageGRID sont configurées avec un équilibreur de charge externe optionnel gérant les requêtes vers les groupes de haute disponibilité de l'équilibreur de charge intégré. Cela permettra d'obtenir un RTO nul, en plus d'un RPO nul. ILM est configuré avec une protection d'ingestion équilibrée pour le placement synchrone. Chaque compartiment est configuré avec la version Quorum du modèle de cohérence globale forte pour les grilles de 3 sites ou plus et la version Legacy de la cohérence globale forte pour 2 sites.
Scénario 1 :
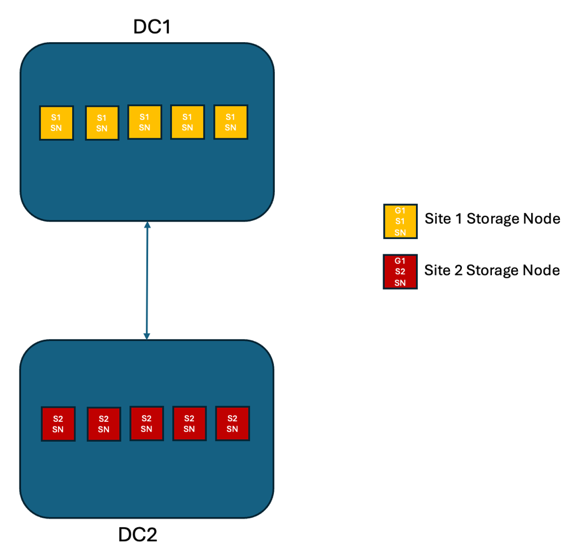
Dans une solution StorageGRID à deux sites, il existe au moins deux répliques de chaque objet et six répliques de toutes les métadonnées. En cas de rétablissement du service, les mises à jour relatives à la panne seront automatiquement synchronisées avec le site/les nœuds rétablis. Avec seulement 2 sites, il est peu probable d'atteindre un RPO nul dans les scénarios de panne autres qu'une perte totale d'un site.
Scénario 2 :
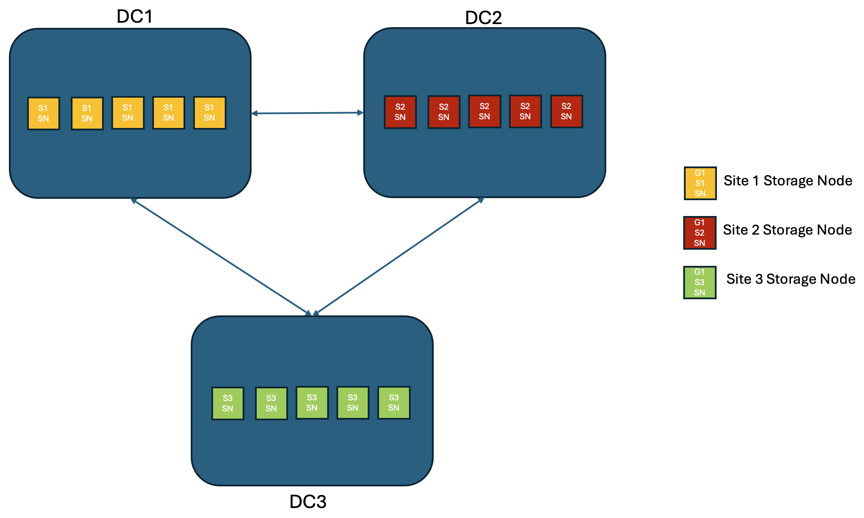
Dans une solution StorageGRID de trois sites ou plus, il existe au moins 3 répliques ou 3 blocs EC de chaque objet et 9 répliques de toutes les métadonnées. En cas de rétablissement du service, les mises à jour relatives à la panne seront automatiquement synchronisées avec le site/les nœuds rétablis. Avec trois sites ou plus, il est possible d'atteindre un RPO nul.
Scénarios de défaillance multisite
| Panne | Résultats sur 2 sites + Héritage solide à l'échelle mondiale | Résultat de 3 sites ou plus + Quorum Strong Global |
|---|---|---|
Panne d'un seul nœud de disque |
Chaque appliance utilise plusieurs groupes de disques et peut supporter au moins 1 disque par groupe en cas de défaillance sans interruption ni perte de données. |
Chaque appliance utilise plusieurs groupes de disques et peut supporter au moins 1 disque par groupe en cas de défaillance sans interruption ni perte de données. |
Panne d'un seul nœud sur un site |
Aucune interruption des opérations ou perte de données. |
Aucune interruption des opérations ou perte de données. |
Défaillance de plusieurs nœuds sur un site |
Interruption des opérations client dirigées vers ce site, mais aucune perte de données. Les opérations dirigées vers l'autre site restent sans interruption et sans perte de données. |
Les opérations sont dirigées vers tous les autres sites, restent sans interruption et sans perte de données. |
Défaillance d'un seul nœud sur plusieurs sites |
Aucune perturbation ou perte de données si :
Activités interrompues et risque de perte de données si :
|
Aucune perturbation ou perte de données si :
Activités interrompues et risque de perte de données si :
|
Panne sur un seul site |
Certaines opérations client seront interrompues jusqu'à ce que la panne soit résolue. Les opérations GET et HEAD se poursuivront sans interruption. Réduisez la cohérence des compartiments à « lecture après nouvelle écriture » ou à un niveau inférieur pour poursuivre les opérations sans interruption dans cet état de défaillance. |
Aucune interruption des opérations ou perte de données. |
Pannes sur un seul site et sur un seul nœud |
Certaines opérations client seront interrompues jusqu'à ce que la panne soit résolue. Les opérations de HEAD se poursuivront sans interruption. Les opérations GET se poursuivront sans interruption s'il existe une copie répliquée ou suffisamment de segments EC. Réduisez la cohérence des compartiments à « lecture après nouvelle écriture » ou à un niveau inférieur pour poursuivre les opérations sans interruption dans cet état de défaillance. |
Aucune interruption des opérations ni perte de données. Risque de perte de données en fonction du nombre de copies répliquées. Le codage d'effacement local permet d'éviter la perte de données. |
Un seul site et un nœud pour chaque site restant |
Il n'existe que deux sites. Voir : Un seul site et un seul nœud. |
Les opérations seront interrompues si le quorum de réplication des métadonnées ne peut être atteint. Réduisez la cohérence des compartiments à « lecture après nouvelle écriture » ou à un niveau inférieur pour poursuivre les opérations sans interruption dans cet état de défaillance. Risque de perte de données en cas de panne permanente, en fonction du nombre de copies répliquées. Le codage d'effacement local permet d'éviter la perte de données. |
Panne multisite |
Il ne reste plus aucun site opérationnel. Des données seront perdues si au moins un site ne peut être récupéré dans son intégralité. |
Les opérations seront interrompues si le quorum de réplication des métadonnées ne peut être atteint. Réduisez la cohérence des compartiments à « lecture après nouvelle écriture » ou à un niveau inférieur pour poursuivre les opérations sans interruption dans cet état de défaillance. Risque de perte de données en cas de panne permanente si le nombre de blocs de données à codage d'effacement est insuffisant. Le codage d'effacement local ou les copies répliquées peuvent empêcher la perte de données. |
Isolation réseau d'un site |
Les opérations client seront interrompues jusqu'à ce que la panne soit résolue. Réduisez la cohérence des compartiments à « lecture après nouvelle écriture » ou à un niveau inférieur pour poursuivre les opérations sans interruption dans cet état de défaillance. Aucune perte de données |
Les opérations seront perturbées sur le site isolé, mais aucune perte de données ne sera à prévoir. Réduisez la cohérence des compartiments à « lecture après nouvelle écriture » ou à un niveau inférieur pour poursuivre les opérations sans interruption dans cet état de défaillance. Aucune interruption des opérations sur les autres sites et aucune perte de données. |
Un déploiement multi-sites à plusieurs grilles
Pour ajouter une couche supplémentaire de redondance, ce scénario utilisera deux clusters StorageGRID et utilisera la réplication inter-grille pour les maintenir synchronisés. Pour cette solution, chaque cluster StorageGRID aura trois sites. Deux sites seront utilisés pour le stockage d'objets et les métadonnées tandis que le troisième site sera utilisé uniquement pour les métadonnées. Les deux systèmes seront configurés avec une règle ILM équilibrée pour stocker de manière synchrone les objets à l'aide du codage d'effacement dans chacun des deux sites de données. Les buckets seront configurés avec le modèle de cohérence global Quorum Strong. Chaque grille sera configurée avec une réplication bidirectionnelle entre grilles sur chaque bucket. Cela fournit la réplication asynchrone entre les régions. En option, un équilibreur de charge global peut être implémenté pour gérer les demandes adressées aux groupes de haute disponibilité de l'équilibreur de charge intégré des deux systèmes StorageGRID afin d'atteindre un RPO nul.
La solution utilisera quatre sites répartis de manière égale en deux régions. La région 1 contiendra les 2 sites de stockage de la grille 1 comme grille principale de la région et le site de métadonnées de la grille 2. La région 2 contiendra les 2 sites de stockage de la grille 2 comme grille principale de la région et le site de métadonnées de la grille 1. Dans chaque région, le même emplacement peut héberger le site de stockage de la grille primaire de la région, ainsi que le site de métadonnées uniquement de la grille des autres régions. L'utilisation de nœuds de métadonnées uniquement comme troisième site permet d'assurer la cohérence requise pour les métadonnées et non de dupliquer le stockage des objets à cet emplacement.
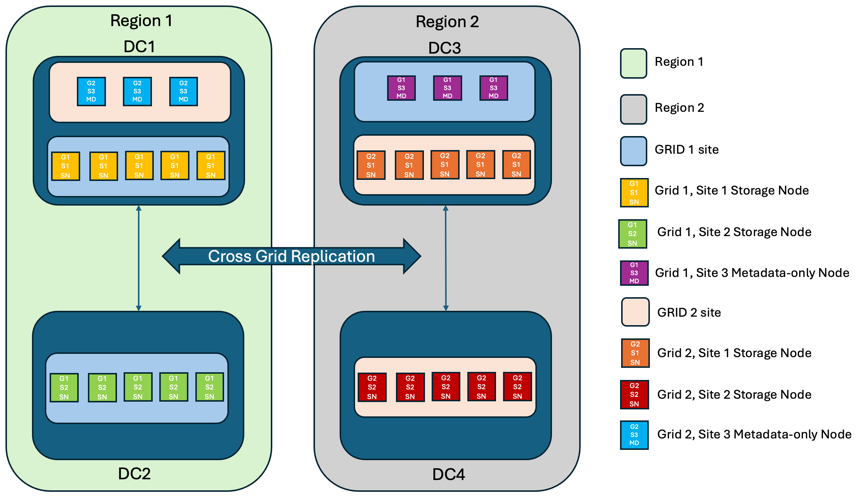
Cette solution avec quatre emplacements distincts assure la redondance complète de deux systèmes StorageGRID distincts qui maintiennent un RPO de 0. Elle utilise à la fois la réplication synchrone multisite et la réplication asynchrone multigrille. Un seul site peut tomber en panne tout en assurant la continuité des opérations client sur les deux systèmes StorageGRID.
Dans cette solution, il existe quatre copies avec code d'effacement de chaque objet et 18 réplicas de toutes les métadonnées. Cela permet de réaliser plusieurs scénarios de défaillance sans impact sur les opérations du client. En cas de panne, les mises à jour de reprise se synchronisent automatiquement avec le ou les sites défaillants.
Scénarios de défaillance multigrille et multisite
| Panne | Résultat |
|---|---|
Panne d'un seul nœud de disque |
Chaque appliance utilise plusieurs groupes de disques et peut supporter au moins 1 disque par groupe en cas de défaillance sans interruption ni perte de données. |
Panne d'un seul nœud sur un site d'un grid |
Aucune interruption des opérations ou perte de données. |
Panne d'un seul nœud sur un site de chaque grid |
Aucune interruption des opérations ou perte de données. |
Défaillance de plusieurs nœuds dans un site d'une grille |
Aucune interruption des opérations ou perte de données. |
Défaillance de plusieurs nœuds sur un site de chaque grid |
Aucune interruption des opérations ou perte de données. |
Défaillance d'un seul nœud sur plusieurs sites d'un grid |
Aucune interruption des opérations ou perte de données. |
Défaillance d'un seul nœud sur plusieurs sites de chaque grid |
Aucune interruption des opérations ou perte de données. |
Panne sur un seul site dans une grille |
Aucune interruption des opérations ou perte de données. |
Panne sur un seul site dans chaque grid |
Aucune interruption des opérations ou perte de données. |
Pannes sur un seul site et sur un seul nœud dans un grid |
Aucune interruption des opérations ou perte de données. |
Un seul site et un nœud pour chaque site restant dans une seule grille |
Aucune interruption des opérations ou perte de données. |
Panne sur un seul emplacement |
Aucune interruption des opérations ou perte de données. |
Défaillance d'emplacement unique dans chaque grille DC1 et DC3 |
Les opérations seront interrompues jusqu'à ce que la défaillance soit résolue ou que la cohérence des compartiments soit réduite ; chaque grille a perdu 2 sites Toutes les données existent toujours à 2 emplacements |
Défaillance d'emplacement unique dans chaque grille DC1 et DC4 ou DC2 et DC3 |
Aucune interruption des opérations ou perte de données. |
Panne d'emplacement unique dans chaque grille DC2 et DC4 |
Aucune interruption des opérations ou perte de données. |
Isolation réseau d'un site |
Les opérations seront interrompues pour le site isolé, mais aucune donnée ne sera perdue Aucune interruption des opérations sur les sites restants et aucune perte de données. |
Conclusion
En cas de défaillance sur un site, StorageGRID vise à assurer la durabilité et la disponibilité des données, ainsi que leur disponibilité. Grâce aux stratégies de réplication robustes de StorageGRID, notamment la réplication synchrone multisite et la réplication asynchrone multigrille, les entreprises peuvent assurer la continuité des opérations client et la cohérence des données sur plusieurs sites. La mise en œuvre de règles de gestion du cycle de vie de l'information (ILM) et l'utilisation de nœuds de métadonnées uniquement améliorent encore la résilience et les performances du système. Avec StorageGRID, les entreprises peuvent gérer leurs données en toute confiance et en sachant qu'elles restent accessibles et cohérentes même en cas de défaillance complexe. Cette approche complète de la gestion et de la réplication des données souligne l'importance d'une planification et d'une exécution méticuleuses pour atteindre un objectif de point de récupération nul et protéger les informations précieuses.