

Réglage Hadoop S3A
 Suggérer des modifications
Suggérer des modifications
Par Angela Cheng
Le connecteur Hadoop S3A facilite l'interaction transparente entre les applications Hadoop et le stockage objet S3. Le réglage du connecteur Hadoop S3A est essentiel pour optimiser les performances lorsque vous travaillez avec le stockage objet S3. Avant d'entrer dans les détails d'ajustement, analysons très bien Hadoop et ses composants.
Qu'est-ce que Hadoop ?
Hadoop est une structure open source puissante conçue pour gérer le traitement et le stockage de données à grande échelle. Il permet le stockage distribué et le traitement parallèle sur des clusters d'ordinateurs.
Ces trois composants sont les suivants :
-
Hadoop HDFS (Hadoop Distributed File System) : gère le stockage, décode les données en blocs et les distribue entre les nœuds.
-
Hadoop MapReduce : responsable du traitement des données en divisant les tâches en petits blocs et en les exécutant en parallèle.
-
FIL Hadoop (encore un autre négociateur de ressources): "Gère les ressources et planifie les tâches de manière efficace"
Connecteur HDFS et S3A Hadoop
HDFS est un composant essentiel de l'écosystème Hadoop, qui joue un rôle essentiel dans l'efficacité du traitement des Big Data. HDFS assure un stockage et une gestion fiables. Elle assure un traitement parallèle et un stockage des données optimisé, ce qui accélère l'accès aux données et leur analyse.
Dans le traitement du Big Data, HDFS se distingue par son excellente tolérance aux pannes pour le stockage de datasets volumineux. Pour cela, il s'agit de la réplication des données. Il peut stocker et gérer d'importants volumes de données structurées et non structurées dans un environnement de data warehouse. De plus, il s'intègre en toute transparence aux principales structures de traitement des Big Data, comme Apache Spark, Hive, Pig et Flink, pour un traitement des données évolutif et efficace. Il est compatible avec les systèmes d'exploitation Unix (Linux), ce qui en fait un choix idéal pour les entreprises qui préfèrent utiliser des environnements Linux pour leur traitement Big Data.
Comme le volume de données s'est accru au fil du temps, l'approche consistant à ajouter de nouvelles machines au cluster Hadoop avec leurs propres ressources de calcul et de stockage s'avère inefficace. L'évolutivité linéaire engendre des défis pour utiliser les ressources efficacement et gérer l'infrastructure.
Pour relever ces défis, le connecteur Hadoop S3A offre des E/S haute performance par rapport au stockage objet S3. L'implémentation d'un workflow Hadoop avec S3A vous permet d'exploiter le stockage objet en tant que référentiel de données et de séparer les ressources de calcul et de stockage. Vous pouvez ainsi faire évoluer indépendamment les ressources de calcul et de stockage. Grâce à la dissociation du calcul et du stockage, vous pouvez également dédier la bonne quantité de ressources pour vos tâches de calcul et fournir la capacité requise en fonction de la taille de votre jeu de données. Par conséquent, vous pouvez réduire votre TCO global pour les workflows Hadoop.
Réglage du connecteur S3A Hadoop
S3 se comporte différemment de HDFS et certaines tentatives de préservation de l'apparence d'un système de fichiers ne sont pas totalement optimales. Des ajustements/tests/tests rigoureux sont nécessaires pour optimiser l'utilisation des ressources S3.
Les options Hadoop présentées dans ce document sont basées sur Hadoop 3.3.5, voir "Hadoop 3.3.5 core-site.xml" pour toutes les options disponibles.
Remarque – la valeur par défaut de certains paramètres Hadoop fs.s3a est différente dans chaque version de Hadoop. Vérifiez la valeur par défaut spécifique à votre version Hadoop actuelle. Si ces paramètres ne sont pas spécifiés dans Hadoop core-site.xml, la valeur par défaut sera utilisée. Vous pouvez remplacer la valeur au moment de l'exécution à l'aide des options de configuration Spark ou Hive.
Vous devez accéder à cette page "Page Apache Hadoop" pour comprendre chaque option fs.s3a. Si possible, testez-les dans un cluster Hadoop non productif pour trouver les valeurs optimales.
Vous devriez lire "Optimisation des performances lors de l'utilisation du connecteur S3A" pour obtenir d'autres recommandations de réglage.
Examinons quelques points clés à prendre en compte :
1. Compression des données
N'activez pas la compression StorageGRID. La plupart des systèmes Big Data utilisent l'option GET de plage d'octets au lieu de récupérer l'objet entier. L'utilisation de la plage d'octets GET avec des objets compressés dégrade considérablement les performances GET.
2. S3A committers
En général, le Comitter Magic s3a est recommandé. Se reporter à ceci "Page des options de renvoi S3A courantes" pour mieux comprendre le comitter magique et ses paramètres s3a associés.
Magic Committer :
Le Magic Committer s'appuie spécifiquement sur S3Guard pour offrir des listes de répertoires cohérentes sur le magasin d'objets S3.
Avec S3 cohérent (ce qui est désormais le cas), le Magic Committer peut être utilisé en toute sécurité avec n'importe quel compartiment S3.
Choix et expérimentation :
Selon votre cas d'utilisation, vous pouvez choisir entre la variable de transfert (qui s'appuie sur un système de fichiers HDFS de cluster) et la variable Magic Committer.
Testez les deux pour déterminer celle qui convient le mieux à votre workload et à vos besoins.
En résumé, les committers S3A constituent une solution au défi fondamental de l'engagement de sortie cohérent, haute performance et fiable pour S3. Leur conception interne garantit un transfert de données efficace tout en préservant l'intégrité des données.
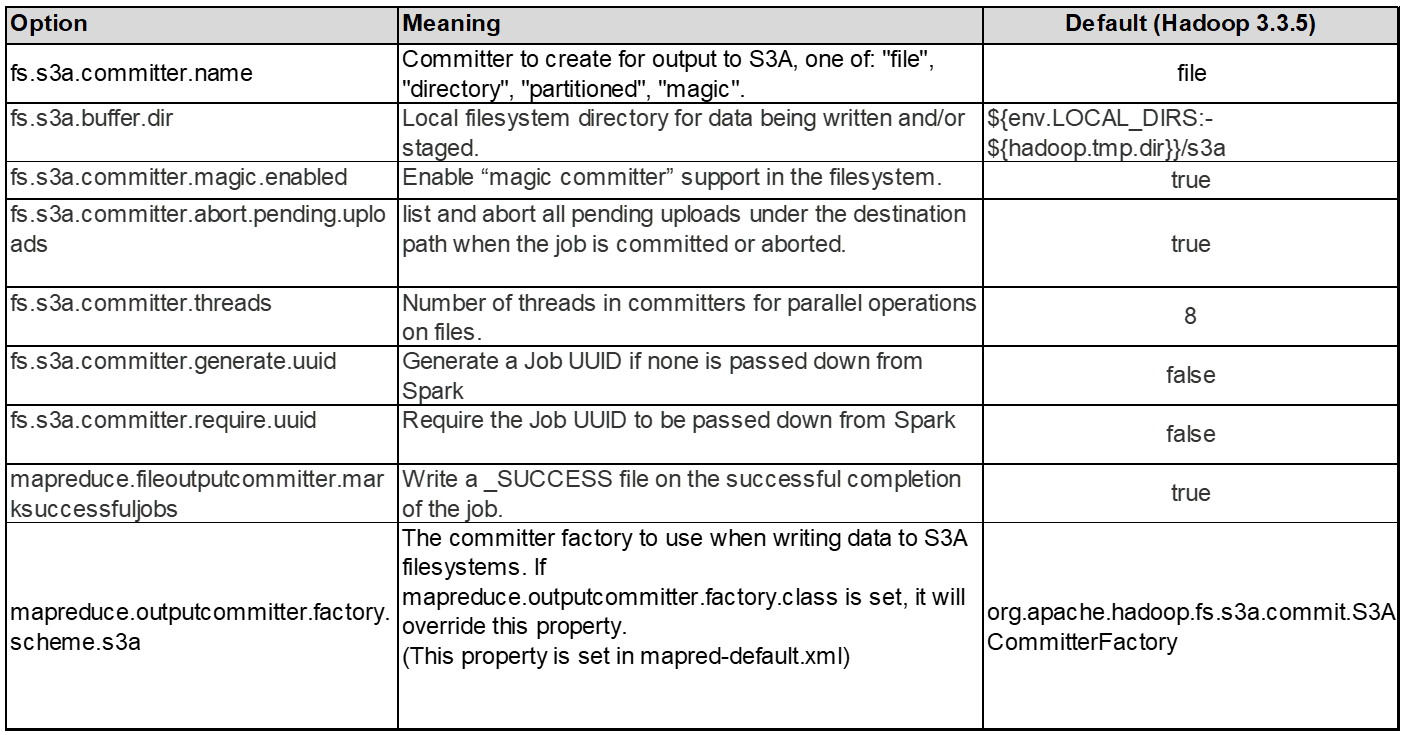
3. Threads, tailles de pool de connexions et taille de bloc
-
Chaque client S3A interagissant avec un seul compartiment dispose de son propre pool dédié de connexions HTTP 1.1 ouvertes et de threads pour les opérations de téléchargement et de copie.
-
Lors du téléchargement de données vers S3, elles sont divisées en blocs. La taille de bloc par défaut est de 32 Mo. Vous pouvez personnaliser cette valeur en définissant la propriété fs.s3a.block.size.
-
Des blocs plus volumineux peuvent améliorer les performances lors du chargement de données volumineuses en réduisant la surcharge liée à la gestion des pièces à part multiple lors du téléchargement. La valeur recommandée est de 256 Mo ou plus pour les jeux de données volumineux.
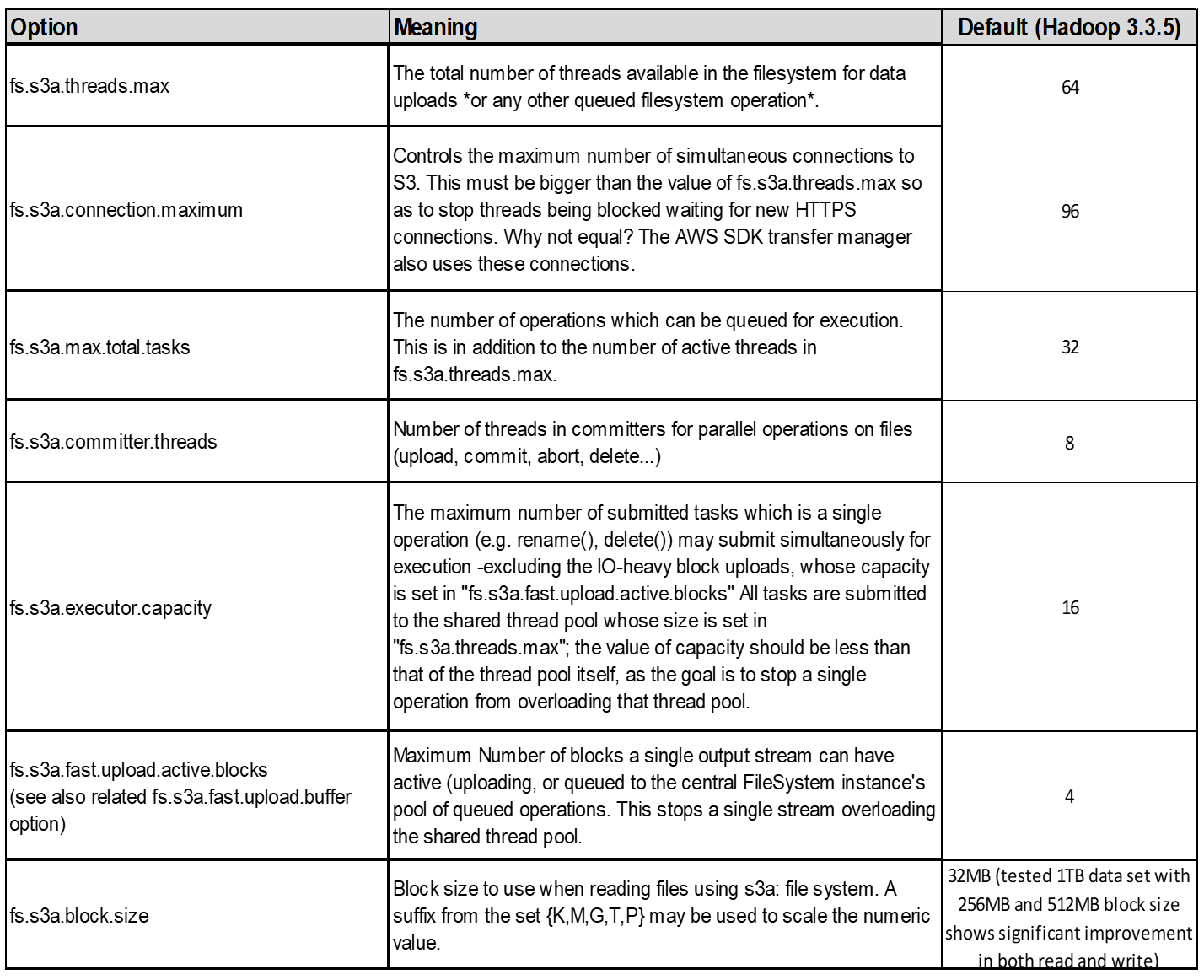
4. Téléchargement partitionné
s3a committers toujours utiliser MPU (téléchargement partitionné) pour charger des données dans le compartiment s3. Ceci est nécessaire pour permettre : l'échec de tâche, l'exécution spéculative des tâches et les abandons de travail avant la validation. Voici quelques spécifications clés relatives aux téléchargements partitionnés :
-
Taille maximale des objets : 5 Tio (téraoctets).
-
Nombre maximum de pièces par téléchargement: 10,000.
-
Numéros de pièce : compris entre 1 et 10,000 (inclus).
-
Taille de la pièce : entre 5 Mio et 5 Gio. En particulier, il n'existe pas de limite de taille minimale pour la dernière partie de votre téléchargement partitionné.
L'utilisation d'une taille de pièce plus petite pour les téléchargements partitionnés S3 présente à la fois des avantages et des inconvénients.
Avantages :
-
Récupération rapide à partir des problèmes réseau : lorsque vous chargez des pièces plus petites, l'impact du redémarrage d'un téléchargement échoué en raison d'une erreur réseau est réduit. Si une pièce échoue, il vous suffit de télécharger à nouveau cette pièce spécifique plutôt que l'objet entier.
-
Meilleure parallélisation : plus de pièces peuvent être téléchargées en parallèle, ce qui permet de tirer parti du multithreading ou des connexions simultanées. Cette parallélisation améliore les performances, en particulier pour les fichiers volumineux.
Désavantage :
-
Surcharge réseau : une taille de pièce plus petite signifie plus de parties à télécharger, chaque partie nécessite sa propre requête HTTP. Le nombre de requêtes HTTP augmente la charge de lancement et de traitement des requêtes individuelles. La gestion d'un grand nombre de petites pièces peut avoir un impact sur les performances.
-
Complexité : la gestion de la commande, le suivi des pièces et la garantie de la réussite des téléchargements peuvent s'avérer fastidieux. Si le téléchargement doit être abandonné, tous les articles déjà téléchargés doivent être suivis et purgés.
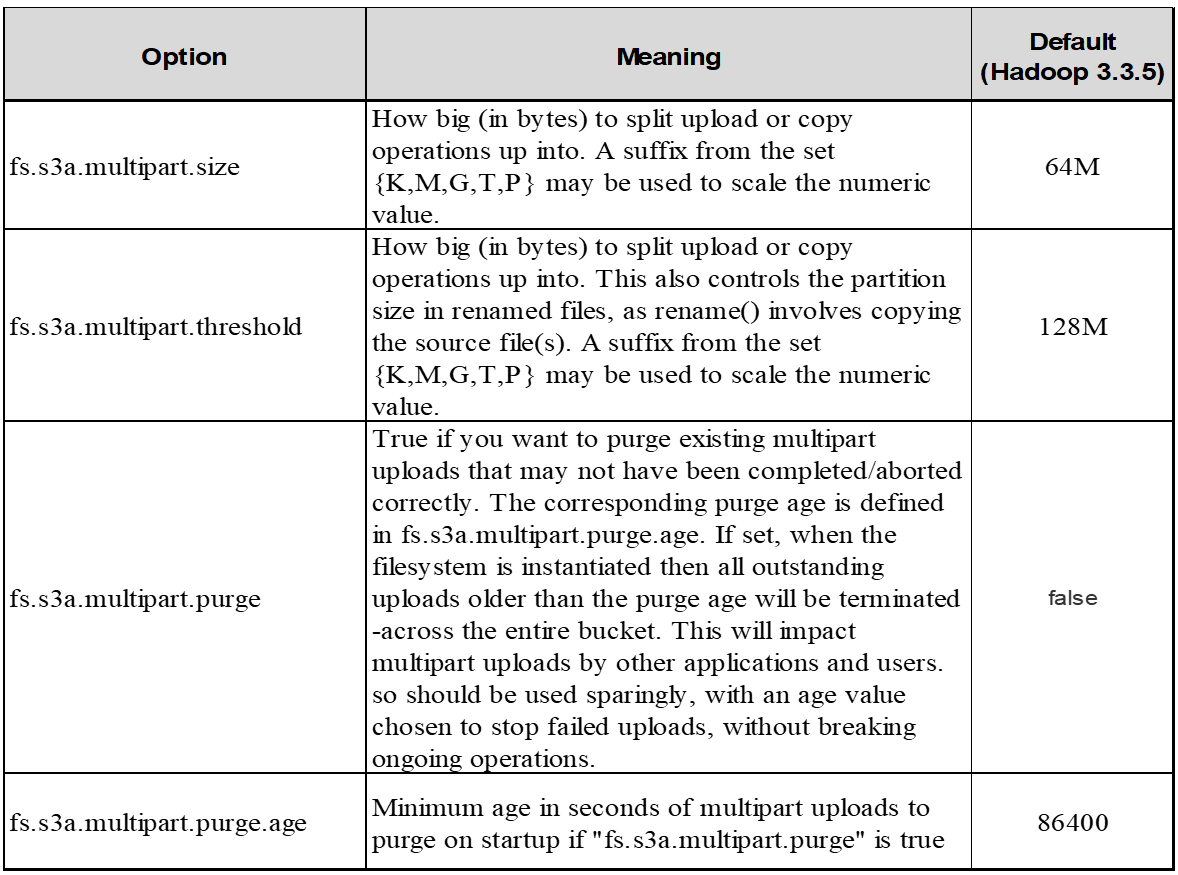
Pour Hadoop, la taille de pièce de 256 Mo ou plus est recommandée pour fs.s3a.multipart.size. Définissez toujours la valeur fs.s3a.mutipart.threshold sur 2 x fs.s3a.multipart.size. Par exemple, si fs.s3a.multipart.size = 256M, fs.s3a.mutlipart.threshold doit être de 512M.
Utiliser une taille de pièce plus grande pour un jeu de données volumineux. Il est important de choisir une taille de pièce qui équilibre ces facteurs en fonction de votre cas d'utilisation et des conditions réseau spécifiques.
Un téléchargement partitionné est un "processus en trois étapes":
-
Le téléchargement est lancé, StorageGRID renvoie un ID de téléchargement
-
Les parties d'objet sont chargées à l'aide de l'ID de téléchargement
-
Une fois toutes les parties d'objet chargées, envoie une demande de téléchargement partitionné complète avec upload-ID StorageGRID construit l'objet à partir des pièces téléchargées, et le client peut accéder à l'objet.
Si la demande complète de téléchargement partitionné n'est pas envoyée correctement, les pièces restent dans StorageGRID et ne créeront aucun objet. Cela se produit lorsque les travaux sont interrompus, en échec ou abandonnés. Les pièces restent dans la grille jusqu'à ce que le téléchargement partitionné soit terminé ou abandonné ou que StorageGRID purge ces pièces si 15 jours se sont écoulés depuis le lancement du téléchargement. S'il y a beaucoup (quelques centaines de milliers à plusieurs millions) de téléchargements partitionnés en cours dans un compartiment, lorsque Hadoop envoie des « téléchargements partiaux-listes » (cette requête ne filtre pas par identifiant de téléchargement), la demande peut prendre un certain temps ou finir par se terminer. Vous pouvez envisager de définir fs.s3a.mutipart.purge sur TRUE avec une valeur fs.s3a.multipart.purge.age appropriée (par exemple, 5 à 7 jours, n'utilisez pas la valeur par défaut de 86400, c'est-à-dire 1 jour). Ou faites appel au support NetApp pour étudier la situation.
5. Mémoire tampon pour écrire les données en mémoire
Pour améliorer les performances, vous pouvez mettre en mémoire tampon l'écriture des données en mémoire avant de les télécharger dans S3. Cela permet de réduire le nombre d'écritures de petite taille et d'améliorer l'efficacité.

N'oubliez pas que S3 et HDFS fonctionnent différemment. Des ajustements/tests/expériences minutieux sont nécessaires pour utiliser de manière optimale les ressources S3.