

Risoluzione dei problemi di ritardo
 Suggerisci modifiche
Suggerisci modifiche
Questo flusso di lavoro fornisce un esempio di come è possibile risolvere un problema di ritardo. In questo scenario, sei un amministratore o un operatore che accede alla pagina Unified ManagerDashboard per vedere se ci sono problemi con le tue relazioni di protezione e, se esistono, per trovare soluzioni.
Cosa ti serve
È necessario disporre del ruolo di amministratore dell'applicazione o di amministratore dello storage.
Nella pagina Dashboard, viene visualizzata l'area Incidents and Risks non risolti e viene visualizzato un errore di SnapMirror Lag nel pannello Protection (protezione) sotto Protection Risks (rischi di protezione).
-
Nel riquadro Protection della pagina Dashboard, individuare l'errore di ritardo della relazione SnapMirror e fare clic su di esso.
Viene visualizzata la pagina dei dettagli dell'evento relativo all'errore di ritardo.
-
Dalla pagina dei dettagli evento è possibile eseguire una o più delle seguenti attività:
-
Esaminare il messaggio di errore nel campo cause dell'area Summary (Riepilogo) per determinare se sono presenti azioni correttive suggerite.
-
Fare clic sul nome dell'oggetto, in questo caso un volume, nel campo Source (origine) dell'area Summary (Riepilogo) per visualizzare i dettagli sul volume.
-
Cercare le note che potrebbero essere state aggiunte a questo evento.
-
Aggiungere una nota all'evento.
-
Assegnare l'evento a un utente specifico.
-
Riconoscere o risolvere l'evento.
-
-
In questo scenario, fare clic sul nome dell'oggetto (in questo caso, un volume) nel campo Source (origine) dell'area Summary (Riepilogo) per ottenere i dettagli sul volume.
Viene visualizzata la scheda Protection (protezione) della pagina Volume / Health details (Dettagli volume/salute).
-
Nella scheda protezione, viene illustrato il diagramma della topologia.
Si noti che il volume con l'errore di ritardo è l'ultimo volume in una cascata SnapMirror a tre volumi. Il volume selezionato viene evidenziato in grigio scuro e una doppia linea arancione dal volume di origine indica un errore di relazione di SnapMirror.
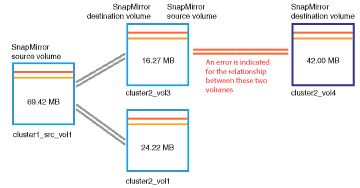
-
Fare clic su ciascuno dei volumi nella cascata di SnapMirror.
Quando si seleziona ciascun volume, le informazioni di protezione in Riepilogo, topologia, Cronologia, Eventi, dispositivi correlati, E le aree degli avvisi correlati vengono modificate per visualizzare i dettagli relativi al volume selezionato.
-
Esaminare l'area Summary e posizionare il cursore sull'icona delle informazioni nel campo Update Schedule per ciascun volume.
In questo scenario, si nota che il criterio SnapMirror è DPDefault e la pianificazione di SnapMirror viene aggiornata ogni ora cinque minuti dopo l'ora. Ti renderai conto che tutti i volumi della relazione stanno tentando di completare un trasferimento SnapMirror contemporaneamente.
-
Per risolvere il problema del ritardo, modificare le pianificazioni per due dei volumi a cascata in modo che ciascuna destinazione inizi un trasferimento SnapMirror dopo che l'origine ha completato un trasferimento.